Hdfs:
hdfs写流程:
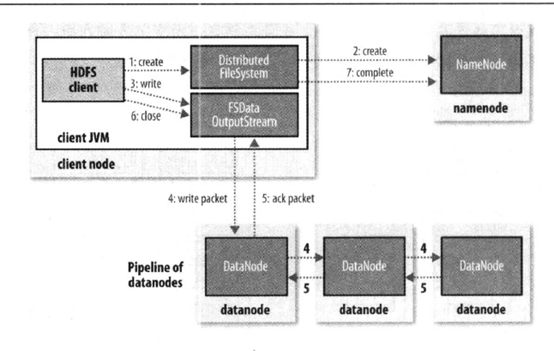
- 客户端通过DistributedFileSystem请求namenode上传文件
- Namenode进行检查,比如父路径 文件本身,是否允许上传
- Namenode相应信息给client 是否允许上传
- 请求上传第一个block块
- Namenode根据元数据信息判断,需要在哪些datanode上上传,返回datanode列表,根据复本数返回datanode节点数。
- 客户端通过FSDataOutputStream建立通道,客户端先与datanode1建立通道,data1与data2,data2与data3建立通道
- 响应通道的应答消息
- 上传block块,在客户端会形成数据队列(block以pachage为单位进行划分),以pakage为单位(默认大小为64k)进行上传
- 客户端先传给data1,先存储在data1的内存中,然后再写入磁盘。Data1将package传给data2 ,data2传给data3
- 10.响应pachage应答消息,响应给客户端,从数据队列中删除package
block上传完成当上传其他的block块的时候 从4步开始执行
11.最后客户端通知namenode上传完成了
hdfs 读流程:

- 客户端通过DistributedFileSystem与namenode进行通信,请求下载文件
- Namenode通过查找自己的元数据信息,获得文件对应的block块及其位置信息,响应给客户端
- 客户端通过网络拓扑,选择一台datanode(就近原则),进行请求读取,请求读取的时候通过FSDataInputStream
- 客户端以package为单位进行读取,先写入到客户单的本地的缓存中(内存中),然后同步到磁盘。
Yarn:
resourcemanager的基本职能概括:
- 与客户端进行交互,处理来自于客户端的请求,如查询应用的运行情况
- 启动和管理各个应用的ApplicationMaster,并且为ApplicationMaster申请第一个Container用于启动和运行失败时将它重新启动
- 管理NodeManager,接受来自NodeManager的资源和节点健康情况汇报,并向NodeManager下达管理资源命令,例如kill掉某个container
- 资源管理和调度,接受来自ApplicationMaster的资源申请,并且为其进行分配。这个是他的最重要的只能。
| MapReduce1 | Yarn |
| Jobtrack | 资源管理器(Resourcemanager)、applicationMaster、时间轴服务器 |
| Tasktrack | 节点管理器(nodemanager) |
| slot | 容器(container) |