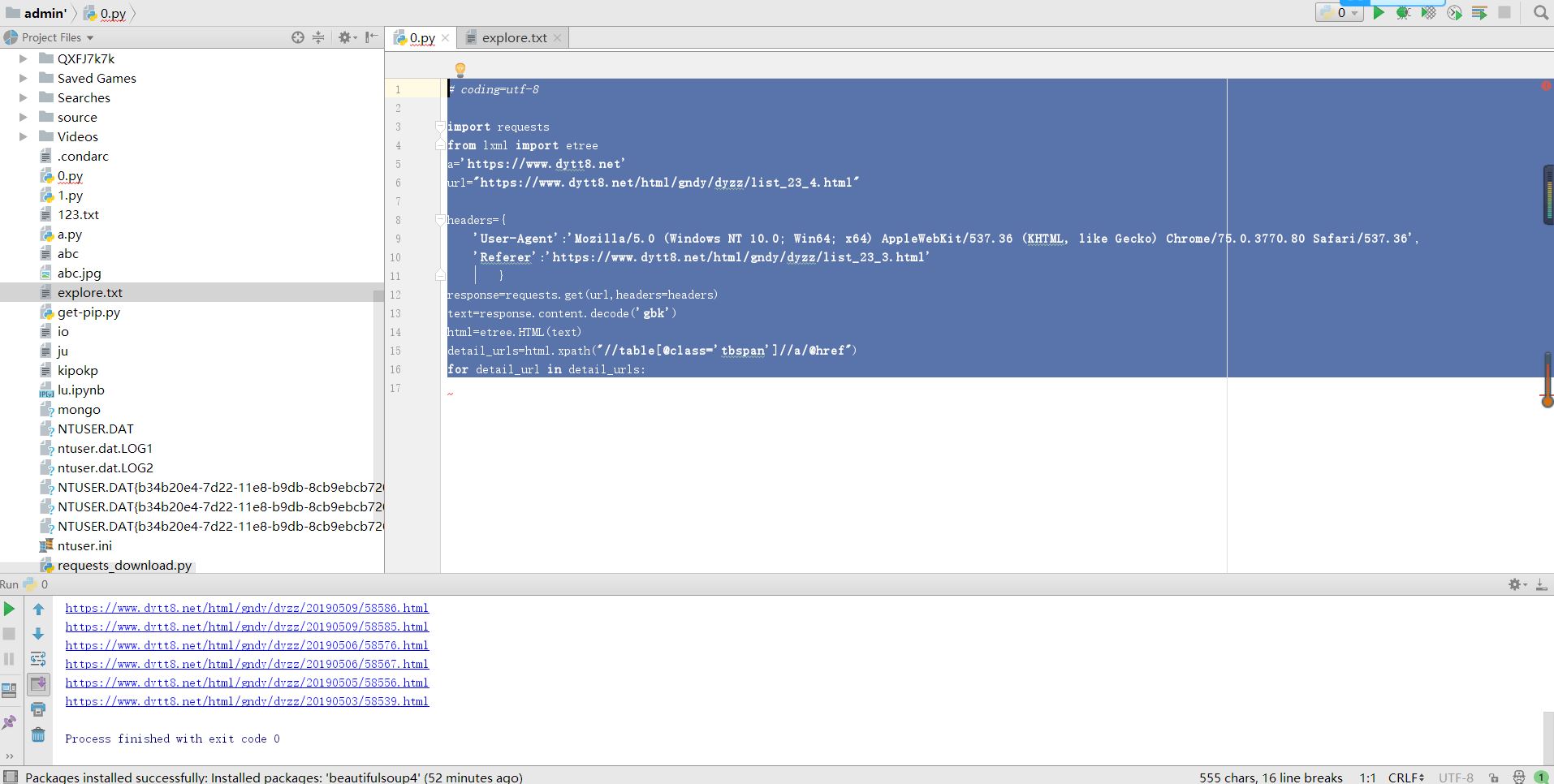
import requests
from lxml import etree
a='https://www.dytt8.net'
url="https://www.dytt8.net/html/gndy/dyzz/list_23_4.html"
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36',
'Referer':'https://www.dytt8.net/html/gndy/dyzz/list_23_3.html'
}
response=requests.get(url,headers=headers)
text=response.content.decode('gbk')
html=etree.HTML(text)
detail_urls=html.xpath("//table[@class='tbspan']//a/@href")
for detail_url in detail_urls:
print(a+detail_url)