自从Google在2006年之前的几篇论文奠定云计算领域基础,尤其是GFS、Map-Reduce、 Bigtable被称为云计算底层技术三大基石。GFS、Map-Reduce技术直接支持了Apache Hadoop项目的诞生。Bigtable和Amazon Dynamo直接催生了NoSQL这个崭新的数据库领域,撼动了RDBMS在商用数据库和数据仓库方面几十年的统治性地位。FaceBook的Hive项目是建立在Hadoop上的数据仓库基础构架,提供了一系列用于存储、查询和分析大规模数据的工具。当我们还浸淫在GFS、Map-Reduce、 Bigtable等Google技术中,并进行理解、掌握、模仿时,Google在2009年之后,连续推出多项新技术,包括:Dremel、 Pregel、Percolator、Spanner和F1。其中,Dremel促使了实时计算系统的兴起,Pregel开辟了图数据计算这个新方向,Percolator使分布式增量索引更新成为文本检索领域的新标准,Spanner和F1向我们展现了跨数据中心数据库的可能。在Google的第二波技术浪潮中,基于Hive和Dremel,新兴的大数据公司Cloudera开源了大数据查询分析引擎Impala,Hortonworks开源了 Stinger,Fackbook开源了Presto。类似Pregel,UC Berkeley AMPLAB实验室开发了Spark图计算框架,并以Spark为核心开源了大数据查询分析引擎Shark。由于某电信运营商项目中大数据查询引擎选型需求,本文将会对Hive、Impala和Presto这三类主流的开源大数据查询分析引擎进行简要介绍以及性能比较。
按照查询类型划分,一般分为即席查询和固化查询:
即席查询:通过手写sql完成一些临时的数据分析需求,这类sql形式多变、逻辑复杂,对查询时间没有严格要求
固化查询:指的是一些固化下来的取数、看数需求,通过数据产品的形式提供给用户,从而提高数据分析和运营的效率。这类的sql固定模式,对响应时间有较高要求。
按照计算引擎主要分为:
1、mapreduce计算模型(hive/pig等)。披着SQL外衣的Map-Reduce,为方便用户使用,编码门槛底,就有了应用性更好的hive,它的应用场景比Map-Reduce更窄,有些计算SQL难以表达,比如一些数据挖掘算法,推荐算法、图像识别算法等,这些仍只能通过编写Map-Reduce完成。
2、MPP架构系统(Presto/Impala/SparkSQL/Drill等)。这种架构主要还是从查询引擎入手,使用分布式查询引擎,而不是使用hive+mapreduce架构,提高查询效率。
搜索引擎架构的系统(es,solr等),在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型,牺牲了灵活性换取很好的性能,在搜索类查询上能做到亚秒级响应。但是对于扫描聚合为主的查询,随着处理数据量的增加,响应时间也会退化到分钟级。
3、预计算系统(Druid/Kylin等)则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。
4、基于lucene外部索引的,比如ElasticSearch和Solr,能够满足的的查询场景远多于传统的数据库存储,但对于日志、行为类时序数据,所有的搜索请求都也必须搜索所有的分片,另外,对于聚合分析场景的支持也是软肋
Hive架构
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为 Map-Reduce任务进行运行,十分适合数据仓库的统计分析。其架构如图1所示,Hadoop和Map-Reduce是Hive架构的根基。Hive 架构包括如下组件:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、Meta Store和Driver(Complier、Optimizer和Executor)。正因使用Map-Reduce计算模型,将一个算法抽象成Map和Reduce两个阶段进行处理,非常适合数据密集型计算。虽然非常稳定,冗余的mr模型和中间结果写入hdfs减慢了计算查询的效率,后来Apache开源的支持DAG作业的计算框架,它直接源于MapReduce框架,核心思想是将Map和Reduce两个操作进一步拆分,即Map被拆分成Input、Processor、Sort、Merge和Output, Reduce被拆分成Input、Shuffle、Sort、Merge、Processor和Output等,这样,这些分解后的元操作可以任意灵活组合,产生新的操作,这些操作经过一些控制程序组装后,可形成一个大的DAG作业。

总结起来,Tez有以下特点(图二所示)
(1)Apache二级开源项目
(2)运行在YARN之上
(3) 适用于DAG(有向图)应用(同Impala、Dremel和Drill一样,可用于替换Hive/Pig等)
Hadoop是基础,其中的HDFS提供文件存储,Yarn进行资源管理。在这上面可以运行MapReduce、Spark、Tez等计算框架。
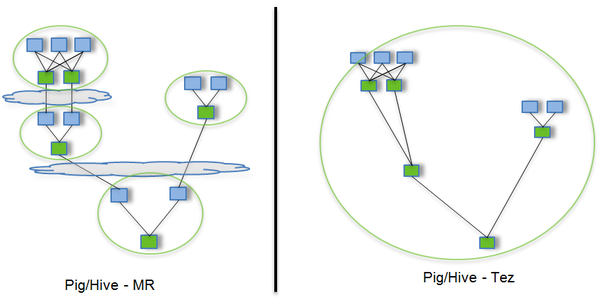
传统的MR(包括Hive,Pig和直接编写MR程序)。假设有四个有依赖关系的MR作业(1个较为复杂的Hive SQL语句或者Pig脚本可能被翻译成4个有依赖关系的MR作业)或者用Oozie描述的4个有依赖关系的作业,运行过程如下(其中,绿色是Reduce Task,需要写HDFS):
云状表示写屏蔽(write barrier,一种内核机制,持久写)
Tez可以将多个有依赖的作业转换为一个作业(这样只需写一次HDFS,且中间节点较少),从而大大提升DAG作业的性能
Impala架构
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,它可以看成是Google Dremel架构和MPP (Massively Parallel Processing)结构的结合体。Impala没有再使用缓慢的Hive&Map-Reduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟,其架构如图4所示,Impala主要由Impalad,State Store和CLI组成。Impalad与DataNode运行在同一节点上,由Impalad进程表示,它接收客户端的查询请求(接收查询请求的 Impalad为Coordinator,Coordinator通过JNI调用java前端解释SQL查询语句,生成查询计划树,再通过调度器把执行计划分发给具有相应数据的其它Impalad进行执行),读写数据,并行执行查询,并把结果通过网络流式的传送回给Coordinator,由 Coordinator返回给客户端。同时Impalad也与State Store保持连接,用于确定哪个Impalad是健康和可以接受新的工作。Impala State Store跟踪集群中的Impalad的健康状态及位置信息,由state-stored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后,因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。 CLI提供给用户查询使用的命令行工具,同时Impala还提供了Hue,JDBC,ODBC,Thrift使用接口。

Presto架构
2013年11月Facebook开源了一个分布式SQL查询引擎Presto,它被设计为用来专门进行高速、实时的数据分析。它支持标准的 ANSI SQL子集,包括复杂查询、聚合、连接和窗口函数。其简化的架构如图8所示,客户端将SQL查询发送到Presto的协调器。协调器会进行语法检查、分析和规划查询计划。调度器将执行的管道组合在一起,将任务分配给那些里数据最近的节点,然后监控执行过程。客户端从输出段中将数据取出,这些数据是从更底层的处理段中依次取出的。Presto的运行模型与Hive有着本质的区别。Hive将查询翻译成多阶段的Map-Reduce任务,一个接着一个地运行。每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然而Presto引擎没有使用Map-Reduce。它使用了一个定制的查询执行引擎和响应操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的时候就会将数据从一个处理段传入到下一个处理段。这样的方式会大大的减少各种查询的端到端响应时间。同时,Presto设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可以使用SQL进行查询。存储连接器目前支持除Hive/HDFS外,还支持HBase、Scribe和定制开发的系统。

总结:数仓架构的选型需要从以下三个方面考虑:数据存储和构建、安装搭建、开发成本。各组件hive/presto/Druid各有优缺点,都有相应的应用场景,比如hive更适合大数据量,密集型计算,有较好的稳定性与扩展,而presto这种mpp计算模型交互性更好,响应时间可以达到秒级,更适合实时查询分析,最后是Druid/Kylin则在入库时对数据进行预聚合,进一步牺牲灵活性换取性能,以实现对超大数据集的秒级响应。最后基于这些组件构建公司级数据中台,并能够稳定/有序/高效的运转,是建立数仓重要的第一步