1 用法
docker swarm init [OPTIONS]
在manager0节点操作
192.168.7.102
[root@manager01 testswarm]# docker swarm init --advertise-addr 192.168.7.102
Swarm initialized: current node (v1ld63hqjtm8bx9z10bbhig5x) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1znl7nt91ucwz5doyuh53k6bhwihw7ked01804r60zfz8egg5c-5ej7hfjrflos3i4d4d49lfo4h 192.168.7.102:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
将 192.168.7.102 作为管理节点
添加其他管理节点,用docker swarm join-token manager 命令获得
[root@manager01 testswarm]# docker swarm join-token manager To add a manager to this swarm, run the following command: docker swarm join --token SWMTKN-1-1znl7nt91ucwz5doyuh53k6bhwihw7ked01804r60zfz8egg5c-7kr2iheffncoz6fqcj49n4fql 192.168.7.102:2377
在其他管理节点上执行 这个节点则作为管理节点添加进来
[root@node01 ~]# docker swarm join --token SWMTKN-1-1znl7nt91ucwz5doyuh53k6bhwihw7ked01804r60zfz8egg5c-7kr2iheffncoz6fqcj49n4fql 192.168.7.102:2377 This node joined a swarm as a manager.
离开集群,在要离家的集群上执行
docker swarm leave -f
准备
其中一台机器是经理(称为manager01),其中两台是工人(node01和node02)
192.168.7.102 manager01 192.168.6.9 node01 192.168.6.17 node02
1 初始化
在manager01 执行
[root@manager01 testswarm]# docker swarm init Swarm initialized: current node (shd6lryp0b2frr9ypzbqofdib) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-3bfwjhrg0sjsbrx8dqxez3hdmt38hmj0x18ph0w7prafw9c6fb-5hl8g51f7uimqleq7x9li5ukw 192.168.7.102:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
在 node01 和node02 上分别执行,将node01 和node02 加入到集群中
docker swarm join --token SWMTKN-1-3bfwjhrg0sjsbrx8dqxez3hdmt38hmj0x18ph0w7prafw9c6fb-5hl8g51f7uimqleq7x9li5ukw 192.168.7.102:2377
在 manager01 上查看
[root@manager01 testswarm]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION shd6lryp0b2frr9ypzbqofdib * manager01 Ready Active Leader 20.10.11 mzqgkj7ry6hvy3ef54jz83w8t node01 Ready Active 20.10.11 l6btk3f69mojxe2e6aprc9jcr node02 Ready Active 20.10.11
部署一个服务
docker service create --replicas 1 --name helloworld alpine ping docker.com
- 该
docker service create命令创建服务。 - 该
--name标志名称的服务helloworld。 - 该
--replicas标志指定 1 个正在运行的实例的所需状态。 - 这些参数
alpine ping docker.com将服务定义为执行命令的 Alpine Linux 容器ping docker.com
运行docker service ls查看正在运行的服务列表
docker service ls
查询服务的详细信息
[root@manager01 testswarm]# docker service inspect --pretty helloworld ID: 48fqoen12m8qp67nluwmgcjqu Name: helloworld Service Mode: Replicated Replicas: 1 Placement: UpdateConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Update order: stop-first RollbackConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Rollback order: stop-first ContainerSpec: Image: alpine:latest@sha256:21a3deaa0d32a8057914f36584b5288d2e5ecc984380bc0118285c70fa8c9300 Args: ping baidu.com Init: false Resources: Endpoint Mode: vip
要以 json 格式返回服务详细信息,请运行不带--pretty标志的相同命令
[root@manager01 testswarm]# docker service inspect helloworld [ { "ID": "48fqoen12m8qp67nluwmgcjqu", "Version": { "Index": 46 }, "CreatedAt": "2021-12-07T21:31:28.234140986Z", "UpdatedAt": "2021-12-07T21:31:28.234140986Z", "Spec": { "Name": "helloworld", "Labels": {}, "TaskTemplate": { "ContainerSpec": { "Image": "alpine:latest@sha256:21a3deaa0d32a8057914f36584b5288d2e5ecc984380bc0118285c70fa8c9300", "Args": [ "ping", "baidu.com" ], "Init": false, "StopGracePeriod": 10000000000, "DNSConfig": {}, "Isolation": "default" }, "Resources": { "Limits": {}, "Reservations": {} }, "RestartPolicy": { "Condition": "any", "Delay": 5000000000, "MaxAttempts": 0 }, "Placement": { "Platforms": [ { "Architecture": "amd64", "OS": "linux" }, { "OS": "linux" }, { "OS": "linux" }, { "Architecture": "arm64", "OS": "linux" }, { "Architecture": "386", "OS": "linux" }, { "Architecture": "ppc64le", "OS": "linux" }, { "Architecture": "s390x", "OS": "linux" } ] }, "ForceUpdate": 0, "Runtime": "container" }, "Mode": { "Replicated": { "Replicas": 1 } }, "UpdateConfig": { "Parallelism": 1, "FailureAction": "pause", "Monitor": 5000000000, "MaxFailureRatio": 0, "Order": "stop-first" }, "RollbackConfig": { "Parallelism": 1, "FailureAction": "pause", "Monitor": 5000000000, "MaxFailureRatio": 0, "Order": "stop-first" }, "EndpointSpec": { "Mode": "vip" } }, "Endpoint": { "Spec": {} } } ]
运行docker service ps <SERVICE-ID>以查看哪些节点正在运行服务
默认情况下,swarm 中的管理节点可以像工作节点一样执行任务。
[root@manager01 testswarm]# docker service ps helloworld ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS 2jz5o9xre325 helloworld.1 alpine:latest manager01 Running Running 21 minutes ago
在运行service的节点上 查看容器的状态
[root@manager01 testswarm]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 31cf4a72d3d8 alpine:latest "ping baidu.com" 31 minutes ago Up 31 minutes helloworld.1.2jz5o9xre325p2eqff9d80a4z
在集群中扩展服务
docker service scale <SERVICE-ID>=<NUMBER-OF-TASKS>
扩张helloworld service 扩展到5个
[root@manager01 testswarm]# docker service scale helloworld=5 helloworld scaled to 5 overall progress: 5 out of 5 tasks
查看状态
[root@manager01 testswarm]# docker service ps helloworld ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS 2jz5o9xre325 helloworld.1 alpine:latest manager01 Running Running about an hour ago qzmn0m8qgbh1 helloworld.2 alpine:latest node01 Running Running about a minute ago 7uc3hyclsbcr helloworld.3 alpine:latest manager01 Running Running 2 minutes ago vo6lp0soapcj helloworld.4 alpine:latest node02 Running Running about a minute ago jkzf20ex9ylp helloworld.5 alpine:latest node01 Running Running about a minute ago
删除运行的服务
[root@manager01 testswarm]# docker service rm helloworld helloworld
验证是否删除
[root@manager01 testswarm]# docker service inspect helloword [] Status: Error: no such service: helloword, Code: 1
即使服务不再存在,任务容器也需要几秒钟来清理。您可以docker ps在节点上使用来验证何时删除了任务
滚动更新 service
[root@manager01 testswarm]# docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6
您可以在服务部署时配置滚动更新策略。
该--update-delay标志配置更新服务任务或任务集之间的时间延迟。您可以将时间描述T为秒数Ts、分钟数Tm或小时数的组合Th。So 10m30s表示 10 分 30 秒的延迟。
默认情况下,调度程序一次更新 1 个任务。您可以通过该 --update-parallelism标志来配置调度程序同时更新的最大服务任务数。
默认情况下,当对单个任务的更新返回 状态时 RUNNING,调度程序会调度另一个任务进行更新,直到所有任务都更新为止。如果在更新期间的任何时间有任务返回FAILED,调度程序就会暂停更新。您可以使用或 的--update-failure-action标志来控制行为 。
docker service create docker service update
更新redis
docker service update --image redis:3.0.7 redis
默认情况下,调度程序按如下方式应用滚动更新:
- 停止第一个任务。
- 为停止的任务安排更新。
- 启动更新任务的容器。
- 如果对任务的更新返回
RUNNING,则等待指定的延迟时间然后开始下一个任务。 - 如果在更新期间的任何时间有任务返回
FAILED,请暂停更新。
- 运行
docker service inspect --pretty redis以查看处于所需状态的新图像:
[root@manager01 testswarm]# docker service inspect --pretty redis ID: j6djgm5fx1jyvgmork3nksgny Name: redis Service Mode: Replicated Replicas: 3 UpdateStatus: State: completed Started: 2 hours ago Completed: 2 hours ago Message: update completed Placement: UpdateConfig: Parallelism: 1 Delay: 10s On failure: pause Monitoring Period: 5s Max failure ratio: 0 Update order: stop-first RollbackConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Rollback order: stop-first ContainerSpec: Image: redis:3.0.7@sha256:730b765df9fe96af414da64a2b67f3a5f70b8fd13a31e5096fee4807ed802e20 Init: false Resources: Endpoint Mode: vip
排除一个节点
创建service redis
[root@manager01 testswarm]# docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6 nbywlmoed6onu7ad4aumgrwy2 overall progress: 3 out of 3 tasks 1/3: running [==================================================>] 2/3: running [==================================================>] 3/3: running [==================================================>] verify: Service converged
查看node状态
[root@manager01 testswarm]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION shd6lryp0b2frr9ypzbqofdib * manager01 Ready Active Leader 20.10.11 mzqgkj7ry6hvy3ef54jz83w8t node01 Ready Active 20.10.11 l6btk3f69mojxe2e6aprc9jcr node02 Ready Active 20.10.11
查看redis service的状态
[root@manager01 testswarm]# docker service ps redis ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS us41kpxn52hm redis.1 redis:3.0.6 node02 Running Running 2 minutes ago y07h2qmh9xq5 redis.2 redis:3.0.6 node01 Running Running 2 minutes ago jsetpqki6ufb redis.3 redis:3.0.6 manager01 Running Running 2 minutes ago
排除节点
docker node update --availability drain <NODE-ID>
[root@manager01 testswarm]# docker node update --availability drain node01
node01
检查节点的可用性
[root@manager01 testswarm]# docker node inspect --pretty node01 ID: mzqgkj7ry6hvy3ef54jz83w8t Hostname: node01 Joined at: 2021-12-07 21:07:22.691396678 +0000 utc Status: State: Ready Availability: Drain Address: 192.168.6.9
节点的Availability 是 Drain
查询节点
[root@manager01 testswarm]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION shd6lryp0b2frr9ypzbqofdib * manager01 Ready Active Leader 20.10.11 mzqgkj7ry6hvy3ef54jz83w8t node01 Ready Drain 20.10.11 l6btk3f69mojxe2e6aprc9jcr node02 Ready Active 20.10.11
查看service redis 的状态
[root@manager01 testswarm]# docker service ps redis ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS us41kpxn52hm redis.1 redis:3.0.6 node02 Running Running 18 minutes ago btdg9aikile0 redis.2 redis:3.0.6 node02 Running Running 13 minutes ago y07h2qmh9xq5 \_ redis.2 redis:3.0.6 node01 Shutdown Shutdown 13 minutes ago jsetpqki6ufb redis.3 redis:3.0.6 manager01 Running Running 18 minutes ago
发现node1 上的容器已经排空了
将节点变到可用的状态
[root@manager01 testswarm]# docker node update --availability active node01
node01
查看节点状态
[root@manager01 testswarm]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION shd6lryp0b2frr9ypzbqofdib * manager01 Ready Active Leader 20.10.11 mzqgkj7ry6hvy3ef54jz83w8t node01 Ready Active 20.10.11 l6btk3f69mojxe2e6aprc9jcr node02 Ready Active 20.10.11
当您将节点设置回Active可用性时,它可以接收新任务:
- 在服务更新期间扩大规模
- 在滚动更新期间
- 当您将另一个节点设置为
Drain可用性时 - 当另一个活动节点上的任务失败时
路由网络
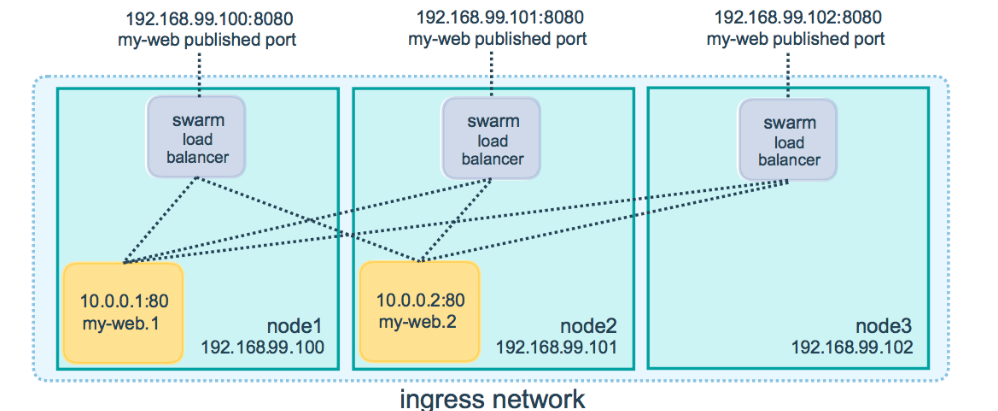
Docker Engine swarm 模式可以很容易地为服务发布端口,使其可用于 swarm 之外的资源。所有节点都参与一个入口路由网格。路由网格使 swarm 中的每个节点都可以接受在已发布端口上为在 swarm 中运行的任何服务的连接,即使节点上没有运行任何任务。路由网格将所有传入请求路由到可用节点上的已发布端口到活动容器。
要在 swarm 中使用 ingress 网络,您需要在启用 swarm 模式之前在 swarm 节点之间打开以下端口:
7946用于容器网络发现的端口TCP/UDP。4789容器入口网络的端口UDP。
您还必须打开 swarm 节点和需要访问端口的任何外部资源(例如外部负载均衡器)之间的已发布端口。
发布一个service 的端口
--publish创建服务时使用该标志发布端口。target 用于指定容器内部的端口,published用于指定要绑定到路由网格上的端口。如果离开published 端口,每个服务任务都会绑定一个随机的高编号端口。您需要检查任务以确定端口
docker service create \ --name <SERVICE-NAME> \ --publish published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> \ <IMAGE>
PUBLISHED-PORT 是暴漏的端口 CONTAINER-PORT 是容器的端口
创建一个my_web 的service 暴漏端口8080
docker service create \ --name my-web \ --publish published=8080,target=80 \ --replicas 2 \ nginx
当您访问任何节点上的 8080 端口时,Docker 会将您的请求路由到活动容器。在 swarm 节点本身,端口 8080 可能实际上没有被绑定,但路由网格知道如何路由流量并防止发生任何端口冲突
您可以使用以下命令为现有服务发布端口
docker service update \ --publish-add published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> \ <SERVICE>
您可以使用docker service inspect来查看服务的已发布端口。例如
[root@manager01 testswarm]# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web [{"Protocol":"tcp","TargetPort":80,"PublishedPort":8080,"PublishMode":"ingress"}]
发布TCP和UDP的端口
默认是TCP 端口
TCP
长语法
docker service create --name dns-cache \ --publish published=53,target=53 \ dns-cache
短语法
docker service create --name dns-cache \ -p 53:53 \ dns-cache
UDP
长语法
docker service create --name dns-cache \ --publish published=53,target=53,protocol=udp \ dns-cache
短语法
docker service create --name dns-cache \ -p 53:53/udp \ dns-cache
TCP 和UDP
长语法
docker service create --name dns-cache \ --publish published=53,target=53 \ --publish published=53,target=53,protocol=udp \ dns-cache
短语法
docker service create --name dns-cache \ -p 53:53 \ -p 53:53/udp \ dns-cache
配置外部负载均衡器
使用HAProxy 配置 负载均衡
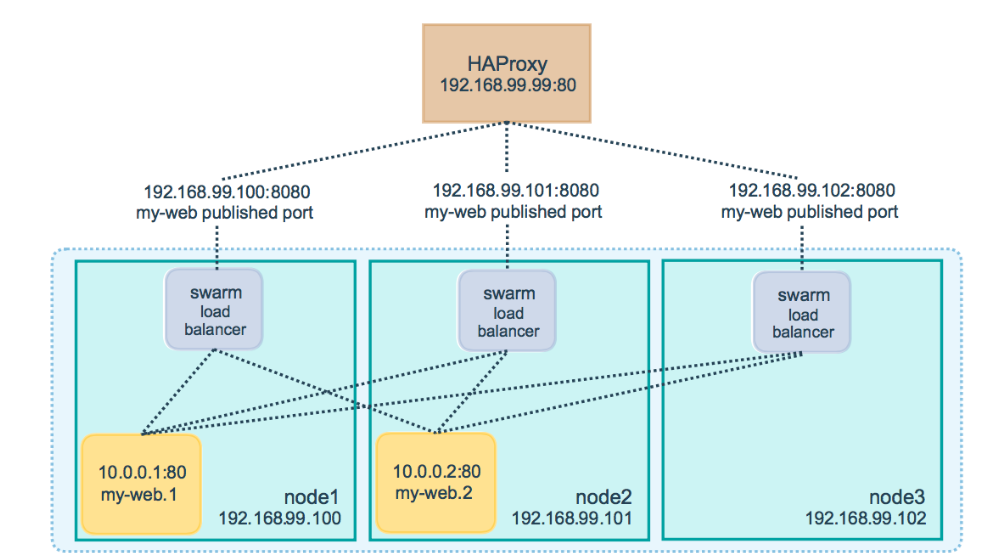
HAProxy 配置/etc/haproxy/haproxy.cfg
global log /dev/log local0 log /dev/log local1 notice ...snip... # Configure HAProxy to listen on port 80 frontend http_front bind *:80 stats uri /haproxy?stats default_backend http_back # Configure HAProxy to route requests to swarm nodes on port 8080 backend http_back balance roundrobin server node1 192.168.99.100:8080 check server node2 192.168.99.101:8080 check server node3 192.168.99.102:8080 check