字节序是指多字节数据在计算机内存中存储或者网络传输时各字节的存储顺序。常见的主要有以下2种:
- 小端序(Little-Endian):低位字节排放在内存的低地址端即该值的起始地址,高位字节排放在内存的高地址端。最符合人的思维的字节序,地址低位存储值的低位,地址高位存储值的高位。该序因为从人的第一观感来说低位值小,就应该放在内存地址小的地方,也即内存地址低位,反之,高位值就应该放在内存地址大的地方,也即内存地址高位。在80X86平台上,系统将多字节中的低位存储在变量起始地址,使用小端法。
- 大端序(Big-Endian):高位字节排放在内存的低地址端即该值的起始地址,低位字节排放在内存的高地址端。最直观的字节序,地址低位存储值的高位,地址高位存储值的低位。该序不需考虑对应关系,只需要把内存地址从左到右按照由低到高的顺序写出把值按照通常的高位到低位的顺序写出,两者对照,一个字节一个字节的填充进去。
常见的还一种是网络序,即网络字节顺序,它是TCP/IP中规定好的一种数据表示格式,它与具体的CPU类型、操作系统等无关,从而可以保证数据在不同主机之间传输时能够被正确解释,网络字节顺序采用big endian排序方式。
在C语言中,为了进行转换,socket库中提供了转换函数,包括下面四个:
- htons:把unsigned short类型从主机序转换到网络序
- htonl:把unsigned long类型从主机序转换到网络序
- ntohs:把unsigned short类型从网络序转换到主机序
- ntohl:把unsigned long类型从网络序转换到主机序
在使用little endian的系统中,这些函数会把字节序进行转换;在使用big endian类型的系统中,这些函数会定义成空宏而不作任何转换。
【例】如对于整数0x12345678,在Windows系统上(小端序存储)使用C语言和Python语言查看其不同表示方式。
其位[0-31]表示方式为:

小端序(Little-Endian)和大端序(Big-Endian)的表示方式为:

其网络字节序同大端法表示相同。
(1)C语言程序:
1 #include <iostream> 2 #include <WinSock.h> 3 #pragma comment(lib, "ws2_32") 4 using namespace std; 5 6 void main() 7 { 8 int a = 0x12345678; 9 cout<<"a = "<<showbase<<hex<<a<<endl; 10 cout<<"Little Endian: ["; 11 for (int i=0; i<4; i++) 12 { 13 cout<<int(*((char*)&a+i))<<" "; 14 } 15 cout<<"]"<<endl; 16 17 int b = htonl(a); 18 cout<<"Big Endian: ["; 19 for (int i=0; i<4; i++) 20 { 21 cout<<int(*((char*)&b+i))<<" "; 22 } 23 cout<<"]"<<endl; 24 25 getchar(); 26 }
其运行结果为:

在调试状态下,在内存窗口中查看变量a和变量b的地址,也可以清晰的看到两种字节序的不同存储情况。本例中变量a和变量b的地址分别为0x00B3FD3C和0x00B3FD24:
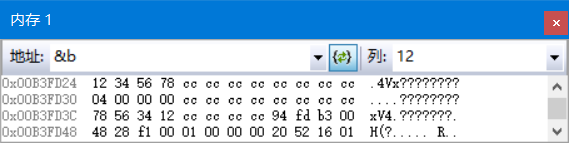
(2)Python语言程序:
1 # -*- coding: utf-8 -*-# 2 3 #------------------------------------------------------------------------------- 4 # Name: LittleAndBigEndianTest 5 # Description: 6 # Author: lgk 7 # Date: 2018/8/8 8 #------------------------------------------------------------------------------- 9 10 import sys 11 from struct import * 12 from ctypes import * 13 import numpy as np 14 15 a = 0x12345678 16 print('a: ' + hex(a)) 17 for name, fmt in zip(['LittleEndian: ', 'BigEndian: ', 'Network: '], [Struct('<1i'), Struct('>1i'), Struct('!1i')]): 18 buffer = create_string_buffer(fmt.size) 19 fmt.pack_into(buffer, 0, a) 20 data = np.frombuffer(buffer, dtype=np.uint8) 21 print(name + str(map(lambda x: hex(x), data)))
其运行结果为:

结果同C语言版本一致,同时也验证了网络字节序同大端序结果完全相同。