
找到对应版本
# 创建目录 mkdir /usr/local/java # 将下载的tar.gz 解压到当前路径下 tar -zxvf jdk-8u241-linux-x64.tar.gz rm -f jdk-8u241-linux-x64.tar.gz # 删除压缩包 ''' 命令介绍: tar 备份文件 -zxvf -z 通过gzip指令处理备份文件 -x 从备份文件中还原文件 -v 显示指令执行过程 -f 指定备份文件 jdk-8u241-linux-x64.tar 文件名 ''' # 进入bin文件,输入./java -version可以看到java版本,如果想直接使用,需要将命令加入环境变量
三 配置环境变量
# vim 打开profile vim /etc/profile # 在最后一行输入 export JAVA_HOME=/usr/local/java/jdk1.8.0_241 export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar export PATH=$PATH:${JAVA_HOME}/bin # 使配置生效 source /etc/profile # 检查 java -version
# 1 单表数据量到达千万级 (分库:一个库有table1,table2表,另一个库有table3,table4表) # 2 分表方案 -垂直分表:把原来一个大表,做成一对一关系 -水平分表:水平切,假设把2000万的数据,分到两个表中(按id分,按hash分)#可能会有热点问题,活跃的用户都在第一张表上,用hash分表会均匀的落在两个表中 # 备注: # 先读写分离,再搭集群(提高查询性能),(单表数据量过了千万级,若果是innodb数据引擎,查询基本就废了。即便做了集群,也需要分表)再做分库分表 # 大公司真正数据量大的东西(上亿级)不会放在mysql中, 用es,hadoop,mongodb
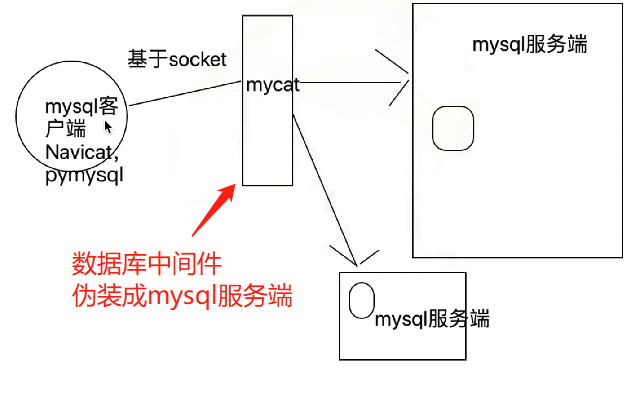
# 1 通过mycat数据库中间件实现(生根于阿里) 拓展:支持高并发,就是尽量让请求少往后走(写服务器中间件,不重要的或者处理不了的请求直接返回回去,或者放队列里做缓存),或者是异步。 # mycat官网:http://www.mycat.org.cn/ ##右边有下载地址,上边有github地址 # mycat作用:支持多种数据库,读写分离,自动故障切换(高可用),mysql主从.基于nio(Java)解决高并发问题(IO多路复用,异步io目前还没有成熟的解决方案)。支持跨库分页,聚合函数。。。mycat监控参考官网
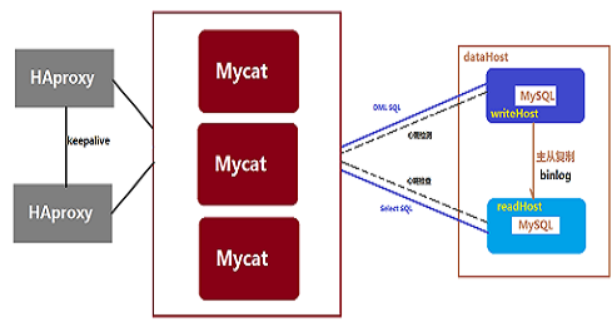
mycat高可用方案
# 2 基于java开发,需要安装jdk # 3 实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQL Server,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容 # 4 javase(基础,io,网络,并发) javaee(web相关) javame # 5 需要有两台服务器(docker模拟两个mysql) ## 使用docker启动多个数据库 docker run -di --name=test1_mysql -p 3306:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7 docker run -di --name=test2_mysql -p 3307:3306 -e MYSQL_ROOT_PASSWORD=123456 mysql:5.7
# 分库:mycat两种方式都支持 垂直分库:(用户相关表,订单相关表,支付相关表) 水平分库 :(用户表拆到了不同的库中)
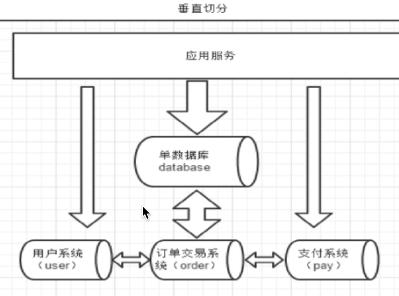 分库垂直切分
分库垂直切分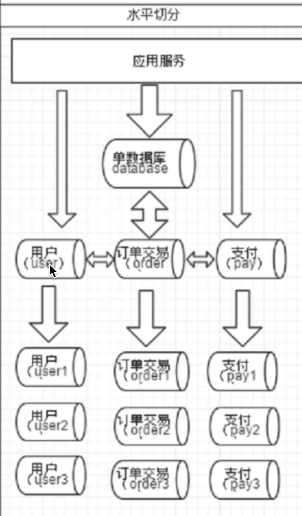 分库水平切分
分库水平切分
## mycat分片策略 如图,一个库有表A和表B,mycat把表根据分片规则(id和hash值)拆分成两个节点,分别放在两台机器上
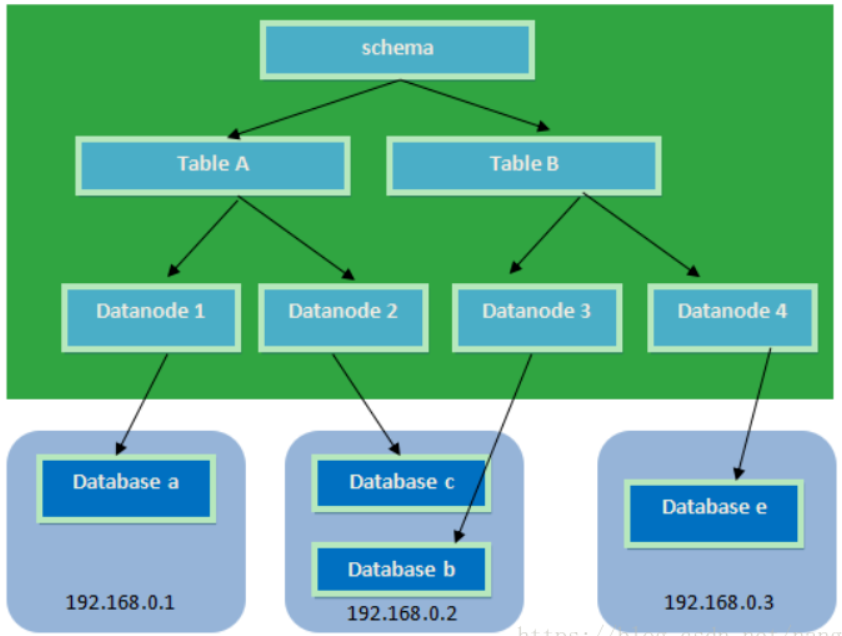
# 6 安装mycat -1 安装jdk8以上(必须1.8及以上版本) -2 下载,解压即可(安装完成,不需要编译) # 此处从官网下载1.6.7.5版本 # 放到~路径下,解压出mycat文件夹 tar -xzf Mycat-server-1.6.7.5-release-20200410174409-linux.tar.gz -3 cd到bin路径下,启动 ./mycat start stop console(前台运行,可以查看日志) # ./mycat start启动mycat # 返回Starting Mycat-server... ,代表启动了 # mycat的默认端口为8066 # ./mycat stop #停止mycat # ./mycat console #启动,前台一直hang着 可以看到日志,报错信息 # 7 mycat安装完,需要关注的几个文件 ##都在mycat/conf中 server.xml:综合配置数据库的相关信息,端口,内存占用,创建账号,密码 schema.xml:对数据库表结构的定义#mycat连接后面的数据在,显示出来表结构 rule.xml:指定相关算法,来实现不同的分片数据库#来定义按id分,还是hash分 ## 推荐使用Sublime Text编辑(激活后,看是否有sftp功能。若无则设定channel_v3.json地址不翻墙,装sftp插件)。本地改完(edit编辑,Chmod改变权限,ctrl+s自动保存上去),远程同步过去。比直接vim修改体验好 ## server.xml大概配置讲解,一般不需要动,除非加个用户 具体看文档 106行 <user name="root" defaultAccount="true"> # 配置一个用户(navicat连接使用) <property name="password">123456</property> # 配置密码 <property name="schemas">TESTDB</property> # 数据库 <property name="defaultSchema">TESTDB</property>#默认能看到的数据库(Navicat连接就能看到的库) 123行 <user name="user"> <property name="password">user</property> <property name="schemas">TESTDB</property> <property name="readOnly">true</property> # 只有读的权限 <property name="defaultSchema">TESTDB</property> </user> 44行 <!-- # 默认参数配置,想修改只要解开端口号修改即可 默认端口8066 <property name="serverPort">8066</property> <property name="managerPort">9066</property> <property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property> <property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查 <property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> --> # 8 id分表规则配置 -shema.xml # schema name和server.xml中的<property name="schemas">TESTDB</property>名字对上 <schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1"> # name指定表名,dataNode指定节点,rule指定分片规则(水平分表的规则),auto-sharding-long通过id来分片 ##————在mycat上的user表会分表,经测试没配置的表不能在mycat上修改 <table name="user" primaryKey="id" dataNode="dn1,dn2" rule="auto-sharding-long" autoIncrement="true" fetchStoreNodeByJdbc="true"> </table> # 上面的dataNode="dn1,dn2" 跟这个地方对应,dataHost在下面配置,database数据库名,name随意(这里的db1就要在对应的地址建db1库) <dataNode name="dn1" dataHost="localhost1" database="db1" /> <dataNode name="dn2" dataHost="localhost2" database="db1" /> # 在这配置跟上面对应,主机的地址和端口,连接mysql服务端的用户名和密码 # maxCon最多连接数,minCon最小连接数,dbType数据库类型 <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat># 用心跳监测是否还有连接,有响应说明还没挂 <!-- can have multi write hosts --> # 地址为本地3306端口,本地跑不用改 <writeHost host="hostM1" url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="jdbc:mysql://localhost:3307" user="root" password="123456"> </writeHost> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> # 9 配置规则 auto-sharding-long---》rule.xml # shema.xml中设置分片规则在rule.xml中配的 <tableRule name="auto-sharding-long"> <rule> <columns>id</columns> <algorithm>rang-long</algorithm> </rule> </tableRule> # rang-long ##全文查找rang-long,下面对应java的类,对应一个txt <function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong"> <property name="mapFile">autopartition-long.txt</property> </function> # autopartition-long.txt ## 在conf文件夹中打开autopartition-long.txt文件,内容如下 # range start-end ,data node index # K=1000,M=10000. 0-500M=0 # id号为0---5000000的数据落在 0库上 500M-1000M=1 # id号为5000000---10000000的数据落在 1库上 意味着id最大1千万,超了会报错 # 10 启动mycat cd bin/ ./mycat console启动看看会不会报错 # 11 远程连接,需要在3306和3307库上创建出db1数据库(名字是shema.xml里设的) # 12 远程连接到mycat,创建表(配置过的表),插入数据,如果是不通范围的id会落到不同库上 ##通过Navicat在mycat库中直接建user表,会报错连接的库里没表(没事),两个链接的库会自动创建表(正常操作是三个库都先建表。如果连接库原本没表,用mycat直接建表,所有连接库表名都会大写)
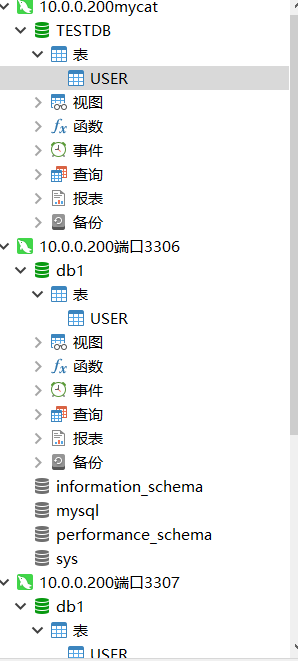 navicat连接mycat效果
navicat连接mycat效果 mycat插入数据
mycat插入数据
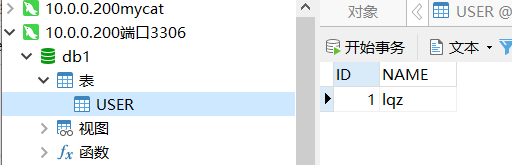 库1user表
库1user表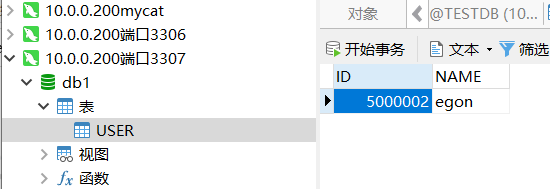 库2user表
库2user表
## 通过hash方式实现水平分表 -只需要修改shema.xml(添加下表,sharding-by-murmur代表hash分表) #相当于再添加article表,按照sharding-by-murmur方法做,其他配置之前已经配好了(该配置规则不需要修改配置) <table name="article" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-murmur"> </table> -重启mycat -在客户端测试,创建article表。插入数据,会均匀的散落在两个库上
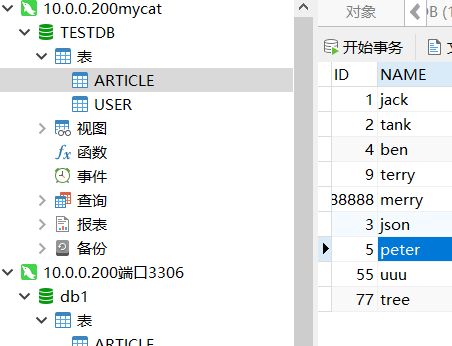 mycat表
mycat表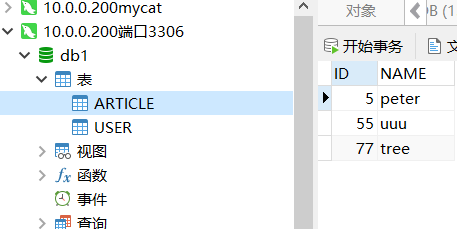 表1
表1 表2
表2
# 原来由于我的设计,没有考虑到分表的情况(单数据---》数据量越来越大,要分表了?) -起一个从库,把原来的业务数据同步过来---》操作从库---》通过mycat从库分表--》再练mycat(缺一部分数据---》把这部分数据重放回来)