列表,元组
#list l1 = [1, 2, 3, '高弟弟'] #定义一个列表 #增 l1.append("DSB") #最后增加"DSB"的元素 #删 l1.remove("高弟弟") #删除"高弟弟"元素 l1.pop(3) #删除列表第4个元素 del l1[-1] #删除列表最后一个元素 #改 l1[3] = 'DSB' #修改第4个元素为'DSB' #查 l2 = [2, 5, 4, 8, 6, 1, 4, 5, 3, 5] l2.sort(reverse=False) #把列表正序排列 l2.sort(reverse=True) #把列表倒序排列 l2_sort = sorted(l2) #把列表正序排列 l1.reverse() #把列表倒叙排列 ## 元组(tuple) t1 = (1,2,3,'高弟弟') #定义一个元组,元组无法进行更改 t2 = tuple(l1) #转为元组类型 l3=list(t1) #转为列表,即可进行更改
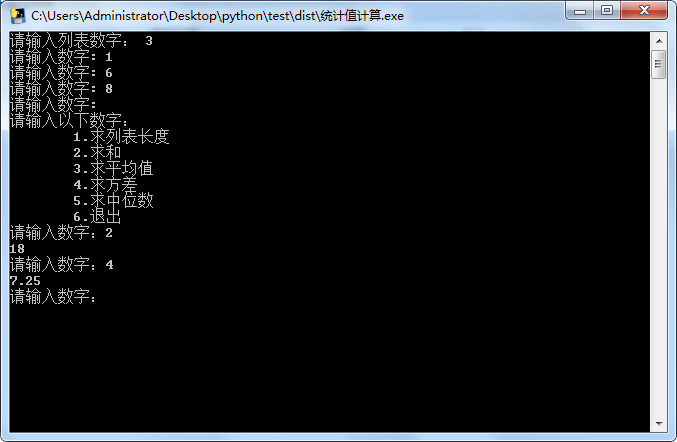
统计值计算示例
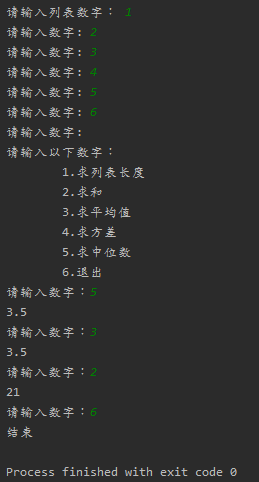
def get_nums(): """获取数据""" nums = [] num = input("请输入列表数字: ").strip() while num != '': nums.append(num) num = input("请输入数字: ").strip() return nums # 函数返回nums def get_len(a): """获取长度""" len = 0 for i in a: if i != '': len += 1 return len def get_add(a): """求和""" sum = 0 for i in a: if i != '': sum += eval(i) # 去除字符串引号 return sum def get_mean(a): """求平均数""" mean = get_add(a) / get_len(a) return mean def get_var(a): """求方差""" sum = 0 for i in a: sum += (get_mean(a) - eval(i)) ** 2 # 去除字符串引号 var = sum / get_len(a) return var def get_median(a): """求中位数""" num_sort = sorted(a) # 正序排列 len = get_len(a) if len % 2 == 0: med = (eval(num_sort[len // 2 - 1]) + eval(num_sort[len // 2])) / 2 else: med = eval(num_sort[len // 2]) return med def calculator(): while True: input_list = get_nums() # 三引号字符串可以换行 print("""请输入以下数字: 1.求列表长度 2.求和 3.求平均值 4.求方差 5.求中位数 6.退出""") while True: input_num = input("请输入数字:") if input_num == '1': print(get_len(input_list)) elif input_num == '2': print(get_add(input_list)) elif input_num == '3': print(get_mean(input_list)) elif input_num == '4': print(get_var(input_list)) elif input_num == '5': print(get_median(input_list)) elif input_num == '6': print("结束") return # 结束当前函数 else: print("输入无效,请重新输入") calculator()
py文件转为EXE文件
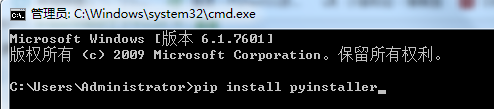
1.运行cmd,输入 pip install pyinstaller(如果慢,可把下载源改为清华源,方法见 https://mirrors.tuna.tsinghua.edu.cn/help/pypi/) ,安装pyinstaller
2.输入 pyinstaller --version,可查看当前pyinstaller库的版本

3.拷贝需要转为exe文件格式的项目路径。也可以打开pycharm程序,如下图对项目右键,点击copy path
4.在cmd中打开到当前路径(生成文件会在此路径下,否则在默认路径),输入pyinstaller -F -w 项目名称,其中-w参数可取消exe运行时cmd弹出窗口


5.exe文件生成完成,在画框的位置下
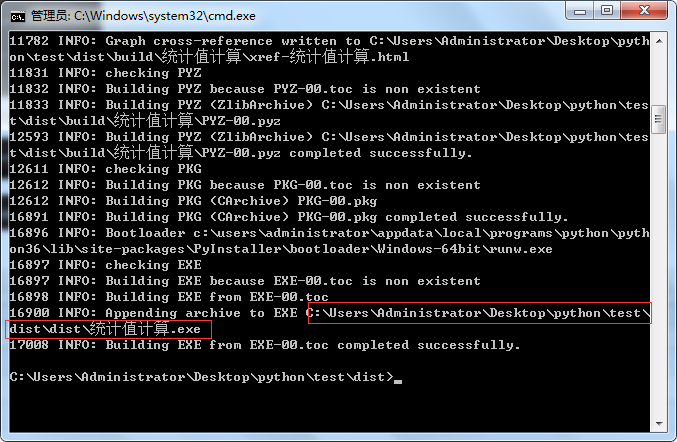
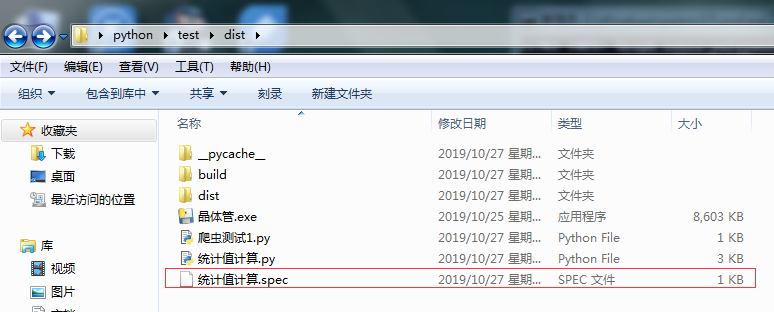
6.如下右图生成统计值计算exe文件,其中如下左图再上一个文件目录下会生成spec的临时文件,可以删除
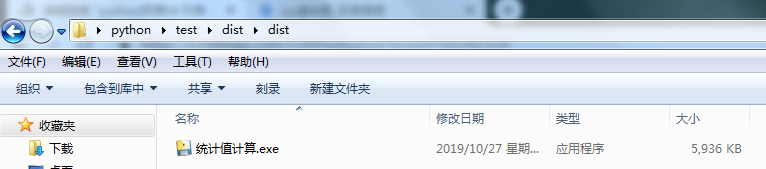
然而打开文件,电脑报错
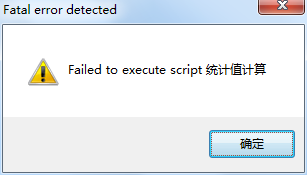
经过网上查找分析,我猜测与pyinstaller -F -w 命令中,-w参数取消exe运行时cmd弹出窗口有关。于是我测试在cmd下运行 pyinstaller -F 统计值计算.exe
经测试,运行成功,推断正确
爬虫初步学习
安装 http请求模块,为爬虫做准备

爬取百度首页
import requests url='http://baidu.com' res=requests.get(url=url) #发送请求,url=可以省略 res.encoding=res.apparent_encoding #res.encoding获取res的编码格式;res.apparent_encoding获取网页正确的编码格式 print(res.text) #返回的结果是处理过的Unicode类型的数据
resutlt:
<html>
<meta http-equiv="refresh" content="0;url=http://www.baidu.com/">
</html>
爬取抽屉网信息
抽屉网会自动判断是否是脚本发送请求,如下图右下角复制用户代理信息

import requests header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36' } #黏贴浏览器用户代理信息代理,并改为字典类型,伪装成浏览器访问 url = 'https://dig.chouti.com/' res = requests.get(url,headers=header) #发送请求,header参数设定为给定参数,不设定header参数会被抽屉网判断为脚本 print(res.text) #返回的结果是处理过的Unicode类型的数据
爬取所得:

在pycharm中新键一个html文件,把结果复制进去。如下图,点击右上交搜狗浏览器图标进入浏览器打开

运行结果
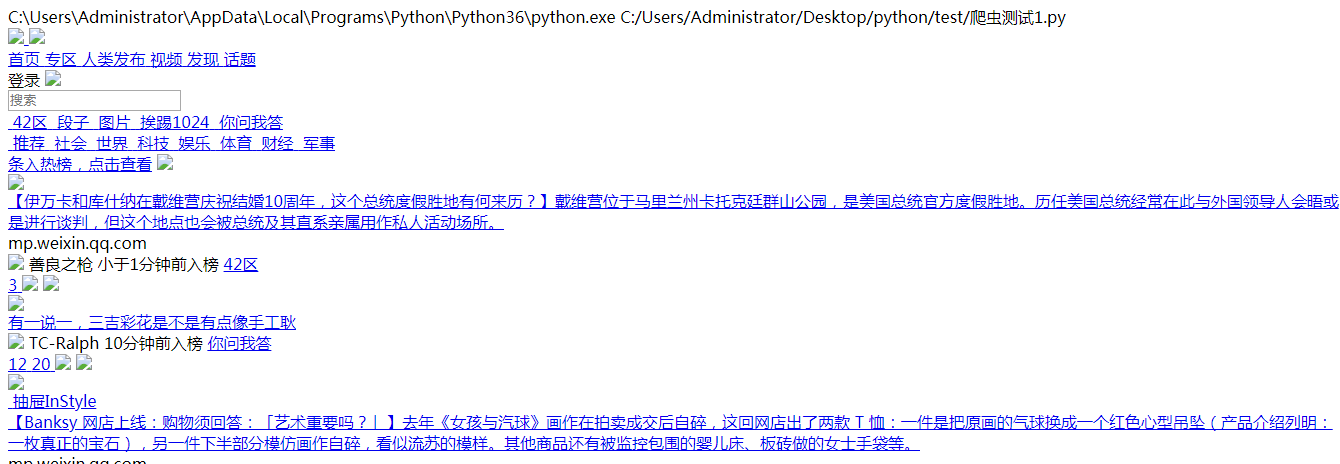
图片无法显示,原因是抽屉网图片使用相对路径,非绝对路径,无法直接调用