ElasticSearch
倒排索引:将文档进行分词,形成词条和id的对应关系即为反向索引
1、ElasticSearch存储和查询的原理
ElasticSearch是一个基于Lucene的搜索服务器
是一个分布式、高扩展、高实时的搜索与数据分析引擎
基于RESTful web接口
应用场景:
搜索:海量数据的查询
日志数据分析
实时数据分析
数据库查询存在问题:
1.性能低:使用模糊查询,会使索引失效,进行全表扫描,性能低
2.功能弱:当使用string做为查询的条件,可能查询不出来数据
ElasticSearch使用倒排索引,对数据库中的字段进行分词,可以快速查询到数据
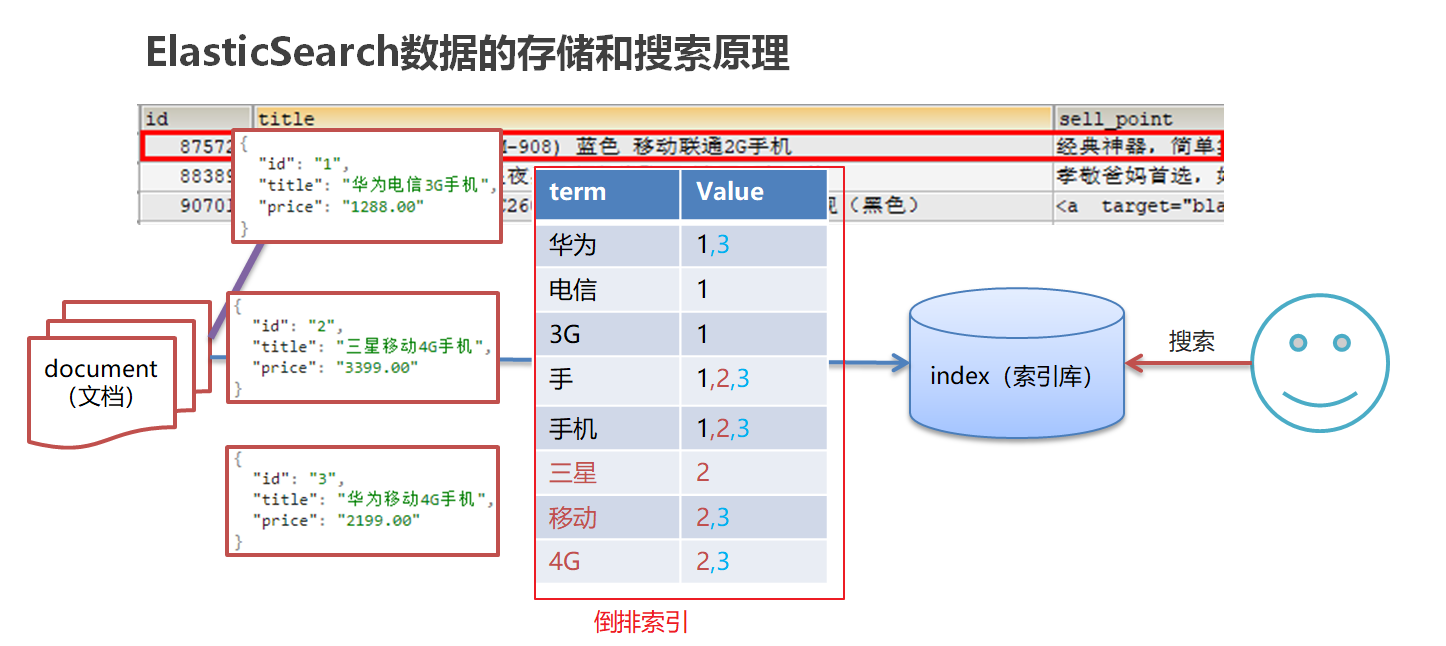
索引(index)
ElasticSearch存储数据的地方,可以理解成关系型数据库中的数据库概念。成为索引库
映射(mapping)
mapping定义了每个字段的类型、字段所使用的分词器等。相当于关系型数据库中的表结构。
文档(document)
Elasticsearch中的最小数据单元,常以json格式显示。一个document相当于关系型数据库中的一行数据。
倒排索引
一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,对应一个包含它的文档id列表。
类型(type)
一种type就像一类表。如用户表、角色表等。在Elasticsearch7.X默认type为_doc
RESTful风格介绍
REST(Representational State Transfer)表述性状态转移 ,是一组架构约束性条件和原则,满足这些原则和条件的应用程序或设计就是RESTful风格
是基于HTTP协议,使用XML格式定义或者JSON格式定义,每个url代表一种资源,客户端使用GET、POST、PUT、DELETE 4个表示操作方式的动词对服务端资源进行操作
GET:用来获取资源
PUT:用来更新资源
DELETE:用来删除资源
2、操作索引
利用postman进行索引的操作
添加索引(put) http://ip:端口/索引名称
查询索引(get)
http://ip:端口/索引名称 # 查询单个索引信息
http://ip:端口/索引名称1,索引名称2... # 查询多个索引信息
http://ip:端口/_all # 查询所有索引信息
关闭、打开索引(post)
http://ip:端口/索引名称/_close
http://ip:端口/索引名称/_open
删除索引(delete)
http://ip:端口/索引名称
数据类型:
字符串:
text:会分词,不支持聚合
keyword:不会分词,将全部内容作为一个词条,支持聚合
操作映射
- 添加映射
-
1 #添加映射 2 PUT /person/_mapping 3 { 4 "properties":{ 5 "name":{ 6 "type":"text" 7 }, 8 "age":{ 9 "type":"integer" 10 } 11 } 12 }
-
- 创建索引并添加映射
-
#创建索引并添加映射 PUT /person1 { "mappings": { "properties": { "name": { "type": "text" }, "age": { "type": "integer" } } } }
-
- 添加字段
-
1 #添加字段 2 PUT /person1/_mapping 3 { 4 "properties": { 5 "name": { 6 "type": "text" 7 }, 8 "age": { 9 "type": "integer" 10 } 11 } 12 }
-
操作文档
- 添加文档,指定id
-
1 POST /person1/_doc/2 2 { 3 "name":"张三", 4 "age":18, 5 "address":"北京" 6 } 7 8 GET /person1/_doc/1
-
- 添加文档不指定id
-
1 #添加文档,不指定id 2 POST /person1/_doc/ 3 { 4 "name":"张三", 5 "age":18, 6 "address":"北京" 7 } 8 9 #查询所有文档 10 GET /person1/_search
-
- 删除指定文档id
- #删除指定id文档 DELETE /person1/_doc/1
3、分词器
分词器:IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包
IK分词器有两种分词模式:
ik_max_word 会将文本进行最细粒度的拆分
例如 乒乓球 分为 乒、乓、球和乒乓球
ik_smart 会做最粗粒度的拆分
例如 乒乓球牛皮 拆分为 乒乓球 、牛皮
IK分词器查询文档
词条查询 term
词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时,才匹配搜索
全文查询: match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
- 创建索引,添加映射,并制定分词器为ik分词器
-
1 PUT person2 2 { 3 "mappings": { 4 "properties": { 5 "name": { 6 "type": "keyword" 7 }, 8 "address": { 9 "type": "text", 10 "analyzer": "ik_max_word" 11 } 12 } 13 } 14 }
-
- 添加文档
-
1 POST /person2/_doc/1 2 { 3 "name":"张三", 4 "age":18, 5 "address":"北京海淀区" 6 } 7 8 POST /person2/_doc/2 9 { 10 "name":"李四", 11 "age":18, 12 "address":"北京朝阳区" 13 } 14 15 POST /person2/_doc/3 16 { 17 "name":"王五", 18 "age":18, 19 "address":"北京昌平区" 20 }
-
- 查询分词效果
- 1 GET _analyze 2 { 3 "analyzer": "ik_max_word", 4 "text": "北京海淀" 5 }
- 词条查询: term
-
1 GET /person2/_search 2 { 3 "query": { 4 "term": { 5 "address": { 6 "value": "北京" 7 } 8 } 9 } 10 }
-
- 全文查询: match 全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
-
1 GET /person2/_search 2 { 3 "query": { 4 "match": { 5 "address":"北京昌平" 6 } 7 } 8 }
-