隔离级别
数据库事务的四个基本特征(ACID)
-
原子性(Atomic):事务中包含的操作被看做一个整体的业务单元,这个业务单元中的操作,要么全部成功,要么全部失败。
-
一致性(Consisitency):事务在完成时,必须使所有的数据都保持一致状态,在数据库中所有的修改都基于事务,保证了数据的完整性。例,A账户有一千元,B账户有一千元,A+B = 2000元, A向B转账100元,此时A有900元,B有1100元,A+B依然是2000元。
-
隔离性(Isolation) :当多个线程访问同一数据,此时数据库同样的数据就会在各个不同的事务中访问,这样会产生丢失更新。例,事务A读取了事务B尚未提交的数据。为了压制丢失更新的产生,数据库定义了隔离级别的概念。
-
持久性(Durability):事务结束后,所有的数据都会固化到一个地方,如保存到磁盘当中,即时断电重启也可以提供给应用程序访问。
丢失更新类型
这四个特性,除了隔离性都比较好理解。我们再举例说明下,在多个事务同时操作数据的情况下,会引发丢失更新的场景。例如,电商有一种商品,在疯狂抢购,此时会出现多个事务同时访问商品库存的情景,这样就会产生丢失更新。一般而言,存在两种类型的丢失更新。
假设某种商品A库存数量为100,抢购时,每个用户仅允许抢购一件商品,name在抢购过程中就可能出现如下场景:

可以看到,T5时刻事务1回滚,此时库存从99变为了100,事务2 的结果就丢失了。类似的,对于这样的一个事务回滚另外的一个事务提交引发的数据不一致的情况,称为第一类丢失更新 。但是,目前大部分数据库已经克服了第一类丢失更新的问题。
如果多个事务并发提交?

T5时刻提交的事务,以为在事务1中,无法感知事务2的操作,此时事务1不知道事务2 已经修改过了数据,从而产生了错误的结果,T5时刻提交事务1的事务,就会引发事务2提交结果的丢失,我们把这样的多个事务提交引发的丢失更新,称之为第二类丢失更新。
因隔离级别引发的问题
1.脏读
指一个事务读取了另外一个事务未提交的数据。
2.不可重复读
指在一个事务内读取表中的某一行数据,多次读取结果不同。
不可重复读和脏读的区别是,脏读是读取前一事务未提交的脏数据,不可重复度是重新读取了前一事务已提交的事务
3. 幻读
指在一个事务内读取到了别的事务插入的数据,导致前后读取不一致
隔离级别类型
为了压制丢失更新,数据库标准提出了四类隔离级别,在不同的程度上压制丢失更新,这四类隔离级别分别是:
- 未提交读
- 读写提交
- 可重复度
- 串行化
也许我们会想到,既然是为了压制丢失更新,直接压制就好,为什么还要设置级别呢?
数据库现有技术完全可以避免丢失更新,但是这样做的代价就是付出锁的代价。但是在实际开发中,我们不仅仅需要考虑保证数据的一致性问题,也想考虑性能的问题。试想,在调用过程中使用过多的锁,一旦出现商品抢购的场景,必然会导致大量的线程被挂起和恢复,因为使用了锁之后,一个时刻只能有一个线程访问数据,这样整个系统就会十分缓慢,当系统被数万用户同时访问,过多的锁就会引发宕机,大部分的线程用户被挂起,等待持有锁实物的完成,这样用户体验会十分糟糕。因此数据库规范就为中和一致性和性能的问题,提出了四种隔离级别来在不同程度上压制丢失更新。
1.未提交读
未提交读(read uncommitted)是最低的隔离界别,其含义是允许一个事务读取到另一个事务未提交的数据。未提交读的有点在于并发能力高,适合对数据一致性没有要求而追求高并发的场景,但他最大的坏处就是会出现脏读。

在T3时刻,因为采用未提交读,所以事务2可以读取到事务1俄日提交的库存数据为1,当事务2扣减库存后并提交了事务则库存为0,然后事务1在T5时刻回滚事务,因为第一类丢失更新已被客服,所以库存不会回滚到2,最后结果变成了0,这样就出现了错误。
2.读写提交
读写提交(read committed)隔离级别,是指一个事务只能读取到另外一个事务已经提交的数据,不能读取到未提交的数据。
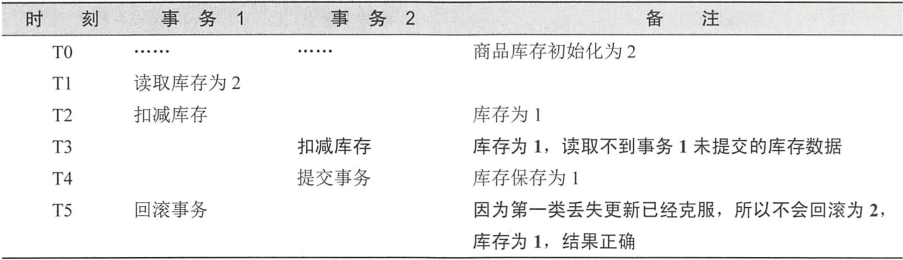
在T3时刻,由于采用了读写提交的隔离级别,因此事务2不能读取到事务1中未提交的库存1,然后事务2提交事务,则库存在T4时刻就变为了1。T5时刻,事务1回滚,因为第一类丢失更新已经克服,所以结果库存为1,这是一个正确的结果。但是读写提交也会产生下面的问题。

在T3时刻事务2读取库存的时候,由于事务1没有提交,所以事务2读到的库存为1,此时事务2认为当前可扣减库存;在T4时刻,事务1已经提交事务,所以在T5时刻,它扣减库存的时候发现库存为0,扣减失败。此时库存对于事务2来说是一个可变化的值,这样的现象称为不可重复读,这就是读写提交的一个不足,为了克服这个不足,数据库隔离级别还提出了可重复读的隔离级别,他能够消除不可重读的问题。
3.可重复读
可重复读的目标是克服读写提交中出现的不可重复读的现象,因为在读写提交的时候,可能会出现一些值的变化,影响当前事务的执行,如上述的库存是个变化的值,这个时候数据库提出了可重复读的隔离级别。

事务2在T3时刻尝试读取库存,但是此时这个库存已经被事务1事先读取,所以此时数据库就阻塞事务2的读取,直至事务1提交,事务2才能读取库存的值。此时已经是T5时刻,而读取到的值为0,这是就已经无法扣减了,显然在读写提交中出现的不可重复读的场景被消除了。但这样也会引发新的问题,就是幻读。假设现在商品交易正在进行中,而后台也有人也在进行查询分析和打印的业务

这便是幻读现象。首先这里的笔数不是数据库存储的值,而是一个统计值,商品库存则是数据库存储的值。幻读不是针对一条数据库记录而言,而是多条记录,例如,这51笔交易笔数就是多条数据库记录统计出来的。而可重复读是针对数据库的单一条记录,例如,商品的库存是以数据库里面的一条记录存储的,它可以产生可重复读,而不能产生幻读。
4.串行化
串行化是数据库最高的隔离级别,他会要求所有的sql按照顺序执行,这样就可以克服上述隔离级别出现的各种问题,所以它能够完全保证数据的一致性。
5.使用合理的隔离级别

隔离级别越高,性能越差,所以再选择隔离级别的时候,要根据业务场景进行考虑选择。例如,一个高并发抢购的场景,如果采用穿行胡隔离级别,能够有效的避免数据的不一致性问题,但会导致并发的各个线程挂起,因为只有一个线程可以操作数据,这样就会导致大量的线程挂起和恢复,导致系统缓慢。后续的用户要得到系统的相应就需要等待很长的时间,从而影响了用户的体验。
所以在现实开发而言,选择隔离级别会以读写提交为主,它能够防止脏读,而不能避免不可重复读和幻读。
对于隔离级别,不同的数据库支持也是不同的,oracle只能支持读写提交和串行化,而mysql能够支持四种,对于oracle默认的隔离级别为读写提交,mysql则是可重复读。