、装饰器
1、装饰器:在原有函数的前后增加功能,且不改变原函数的调用方式
例子1(不带参数的装饰器):计算func1函数的执行时间(计算一个函数的运行时间)
import time
def timer(f):
def inner():
starttime=time.time()
ret=f()
endtime=time.time()
print('函数耗时:%s'% (endtime-starttime))
return ret
return inner
def func1():
print('begin....')
time.sleep(0.1)
print('end....')
return 666
func1=timer(func1)
func1()
执行结果:
begin....
end....
函数耗时:0.1000056266784668
以上不是写成@timer那种形式,可以改写成:
import time
def timer(f):
def inner():
starttime=time.time()
ret=f()
endtime=time.time()
print('函数耗时:%s'% (endtime-starttime))
return ret
return inner
@timer
def func1():
print('begin....')
time.sleep(0.1)
print('end....')
return 666
result=func1()
print(result)
执行结果:
begin....
end....
函数耗时:0.1000056266784668
666
例子2(带参数的装饰器)
import time
def timer(f):
def inner(*args,**kwargs):
starttime=time.time()
ret=f(*args,**kwargs)
endtime=time.time()
print('函数耗时:%s'% (endtime-starttime))
return ret
return inner
@timer
def func1(a,b):
print('begin....',a)
time.sleep(0.1)
print('end....',b)
return True
result=func1(100,101)
print(result)
执行结果:
begin.... 100
end.... 101
函数耗时:0.1000056266784668
True
总结:装饰器的结构如下
 简单来讲,这个就是个外层函数,定义个inner内层函数,return inner函数
简单来讲,这个就是个外层函数,定义个inner内层函数,return inner函数
# def timmer(f):
# def inner(*args,**kwargs):
# 调用函数之前可以加的功能
# ret = f(*args,**kwargs)
# 调用函数之后可以加的功能
# return ret
# return inner
复习装饰器:
装饰器的进阶
给装饰器加上一个开关 - 从外部传了一个参数到装饰器内
多个装饰器装饰同一个函数 - 套娃
每个装饰器都完成一个独立的功能
功能与功能之间互相分离
同一个函数需要两个或以上额外的功能
def wrapper1(func):
def inner(*args,**kwargs):
'''执行a代码'''
ret = func(*args,**kwargs)
'''执行b代码'''
return ret
return inner
def wrapper2(func):
def inner(*args,**kwargs):
'''执行c代码'''
ret = func(*args,**kwargs)
'''执行d代码'''
return ret
return inner
@wrapper1
@wrapper2
def func():pass
# 执行顺序:a代码 c代码 func d代码 b代码
备注:哪个离函数最近,谁里面的func就是真正的被装饰的函数
2、装饰器的进阶的需求
第一种情况,500个函数,你可以设计你的装饰器 来确认是否生效(考虑给装饰器传参)
举例1:
import time
def outetr(flag):
def timmer(f):
def inner(*args,**kwargs):
if flag==True:
start_time = time.time()
ret = f(*args,**kwargs)
end_time = time.time()
print(end_time - start_time)
else:
ret = f(*args, **kwargs)
return ret
return inner
return timmer
@outetr(True) # func = timmer(func) 这样话outetr(True),这个只执行了outetr这个函数,其余的没有执行,返回timmer。就相当于outetr(True)=timmer,这样@timmer再去执行后面的
def func(a,b):
print('begin func',a)
time.sleep(0.1)
print('end func',b)
return True
ret = func(1,2) #--> inner()
执行结果:
begin func 1
end func 2
0.10100579261779785
如果给装饰器传参是false
import time
def outetr(flag):
def timmer(f):
def inner(*args,**kwargs):
if flag==True: ##内部函数使用外部函数的变量
start_time = time.time()
ret = f(*args,**kwargs)
end_time = time.time()
print(end_time - start_time)
else:
ret = f(*args, **kwargs)
return ret
return inner
return timmer
@outetr(False) # func = timmer(func)
def func(a,b):
print('begin func',a)
time.sleep(0.1)
print('end func',b)
return True
ret = func(1,2) #--> inner()
执行结果:
begin func 1
end func 2
以上可以再改造成:
import time
FLAG = True ##全部变量,假如有500个函数,底下的都看这个定义的
def outer(flag):
def timmer(f):
def inner(*args,**kwargs):
if flag == True:
start_time = time.time()
ret = f(*args,**kwargs)
end_time = time.time()
print(end_time - start_time)
else:
ret = f(*args, **kwargs)
return ret
return inner
return timmer
@outer(FLAG) # func = timmer(func)
def func(a,b):
print('begin func',a)
time.sleep(0.1)
print('end func',b)
return True
func(1,2)
执行结果:
begin func 1
end func 2
0.1000056266784668 #如果FLAG=False的话,就没有这一行的这个结果,其余的还有
第二种情况:两个函数同时装饰同一个函数
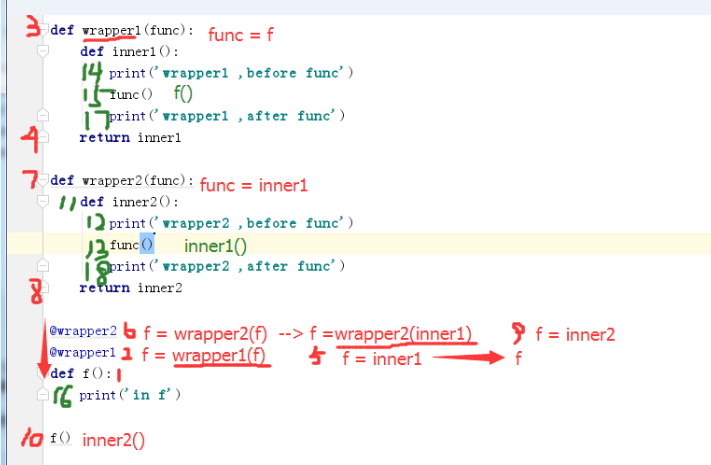
def wrapper1(func): #f传进来了
def inner1():
print('wrapper1 ,before func')
func() #f
print('wrapper1 ,after func')
return inner1
def wrapper2(func): #innner1传进来了
def inner2():
print('wrapper2 ,before func')
func() #inner1
print('wrapper2 ,after func')
return inner2
@wrapper2 #f=warpper2(f) 此时的f是inner1 f=wrapper2(inner1)=inner2
@wrapper1 #f=wrapper1(f) =inner1
def f():
print('in f')
f() #这句等于inner2()
执行结果:
wrapper2 ,before func
wrapper1 ,before func
in f
wrapper1 ,after func
wrapper2 ,after func
执行顺序如下:
例子:(上周day03作业可以用类似方法去做)
# 装饰器 登录 记录日志
import time
login_info = {'alex':False}
def login(func): # manager
def inner(name):
if login_info[name] != True:
user = input('user :')
pwd = input('pwd :')
if user == 'alex' and pwd == 'alex3714':
login_info[name] = True
if login_info[name] == True:
ret = func(name) # timmer中的inner
return ret
return inner
def timmer(f):
def inner(*args,**kwargs):
start_time = time.time()
ret = f(*args,**kwargs) # 调用被装饰的方法
end_time = time.time() #
print(end_time - start_time)
return ret
return inner
@login
@timmer
def index(name):
print('欢迎%s来到博客园首页~'%name)
@login
@timmer # manager = login(manager) #这块应该是先登录再计算时间再计算时间,所以登录写上面,timmer写下面
def manager(name):
print('欢迎%s来到博客园管理页~'%name)
index('alex')
index('alex')
manager('alex')
manager('alex')
# 计算index 和 manager的执行时间
执行结果:
user :alex
pwd :alex3714
欢迎alex来到博客园首页~
0.0
欢迎alex来到博客园首页~
0.0
欢迎alex来到博客园管理页~
0.0
欢迎alex来到博客园管理页~
0.0
总结:整体是先执行login中的inner,再执行timmer中的inner,只要登录之后就不再登录,想去哪儿去哪儿,看执行结果也可以看出
二、迭代器
# 迭代器
# 如何从列表、字典中取值的
# index索引 ,key
# for循环
# 凡是可以使用for循环取值的都是可迭代的
# 可迭代协议 :内部含有__iter__方法的都是可迭代的
# 迭代器协议 :内部含有__iter__方法和__next__方法的都是迭代器
举例1:
print(dir([1,2,3]))
lst_iter = [1,2,3].__iter__() #lst_iter这个是迭代器,迭代器只记得当前值和下一个值
print(lst_iter.__next__())
print(lst_iter.__next__())
print(lst_iter.__next__())
执行结果:
['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
1
2
3
调用完iter方法之后,是迭代器
print(dir([1,2,3].__iter__())) 有next方法和iter方法,所以说被iter之后的这个是迭代器
['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
举例2:
for i in [1,2,3]: # [1,2,3].__iter__() [1,2,3]这个本身不是迭代器,只是可迭代的,但是for循环之后,会在内部调用[1,2,3].__iter__(),调用iter方法之后,转变成迭代器,然后
print(i) 每一次循环就像是调用next方法赋值给i,然后再输出
举例3:
l = [1,2,3]
lst_iter = iter(l) # l.__iter__()
while True:
try:
print(next(lst_iter)) # lst_iter.__next__()
except StopIteration:
break
执行结果:
1
2
3
总结:
# 什么是可迭代的
# 什么是迭代器 迭代器 = iter(可迭代的),自带一个__next__方法
# 可迭代 最大的优势 节省内存
from collections import Iterable,Iterator
print(range(100000000))
print(isinstance(range(100000000),Iterable)) #判断是不是可迭代的
print(isinstance(range(100000000),Iterator)) #判断是不是迭代器
执行结果:
range(0, 100000000)
True
False
# py2 range 不管range多少 会生成一个列表 这个列表将用来存储所有的值
# py3 range 不管range多少 都不会实际的生成任何一个值
# 迭代器的优势:
# 节省内存
# 取一个值就能进行接下来的计算 ,而不需要等到所有的值都计算出来才开始接下来的运算 —— 快
# 迭代器的特性:惰性运算(你找迭代器要值的时候才会生成值)
以下都是可迭代的:
# f = open()
# for line in f:
# 列表 字典 元组 字符串 集合 range 文件句柄 enumerate(给元素加序号)
三、生成器
# 生成器 Generator
# 自己写的迭代器 就是一个生成器
# 两种自己写生成器(迭代器)的机制:生成器函数 生成器表达式
举例1:
def func1():
print('***')
yield 1
print('%%%')
yield 2
m=func1()
print('--',next(m))
执行结果:
***
-- 1
举例2:
def func1():
print('***')
yield 1
print('%%%')
yield 2
m=func1() #这块调用生成器函数,不会触发代码的执行,返回一个生成器
print('--',next(m))
print('--',next(m))
执行结果:
***
-- 1
%%%
-- 2
# 生成器函数的调用不会触发代码的执行,而是会返回一个生成器(迭代器)
# 想要生成器函数执行,需要用next
举例3:
def cloth_g(num):
for i in range(num):
yield 'cloth%s'%i
g = cloth_g(1000)
print(next(g))
print(next(g))
print(next(g))
执行结果:
cloth0
cloth1
cloth2
举例4:
# 使用生成器监听文件输入的例子
import time
def listen_file():
with open('userinfo') as f:
while True:
line = f.readline()
if line.strip():
yield line.strip()
time.sleep(0.1)
g = listen_file()
for line in g:
print(line)
执行结果:
ahjskhfklsjdahf
asjkhfdjlhflk
ajskhjkldfh
2387497
wlhql jewo91804
sssdkajlhgd
执行顺序:
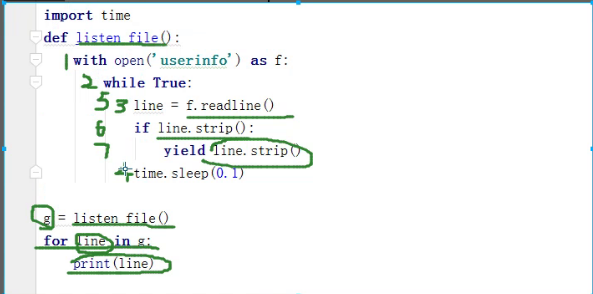
总结:这个可以实现边往文件里写,写完保存,会自动输出到控制台中
# send关键字
def func():
print(11111)
ret1 = yield 1 #这块是接收参数,可以直接写yield 1,这样就是不接收参数,不影响send发送参数
print(22222,'ret1 :',ret1)
ret2 = yield 2
print(33333,'ret2 :',ret2)
yield 3
g = func()
ret = next(g)
print(ret)
print(g.send('alex')) # 在执行next的过程中 传递一个参数 给生成器函数的内部 send相当于调用了个next方法
print(g.send('金老板'))
# 向生成器中传递值 有一个激活的过程 第一次必须要用next触发这个生成器(也就是第一次next的时候不能用send)
执行结果:
11111
1
22222 ret1 : alex
2
33333 ret2 : 金老板
3
执行顺序:
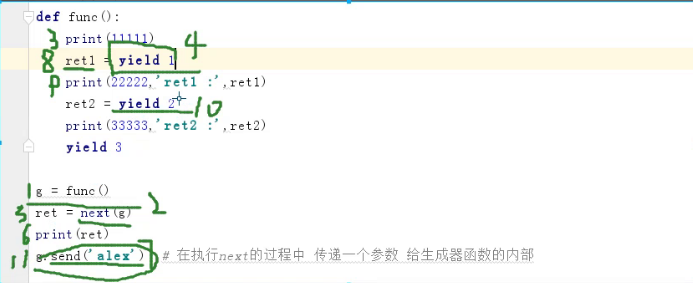
send举例1:
# 例子
# 计算移动平均值
# 12 13 15 18
# 月度 的 天平均收入
def average():
sum_money = 0
day = 0
avg = 0
while True:
money = yield avg
sum_money += money
day += 1
avg = sum_money/day
g = average()
next(g)
print(g.send(200))
print(g.send(300))
print(g.send(600))
执行结果:
200.0
250.0
366.666666666666
执行顺序:
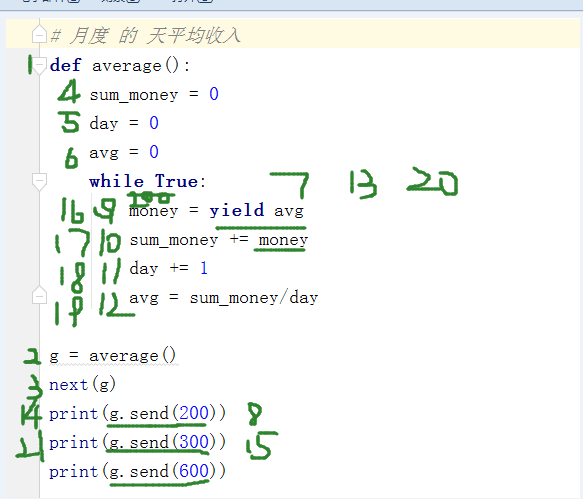
#预激生成器
# 预激生成器
def init(func):
def inner(*args,**kwargs):
ret = func(*args,**kwargs)
next(ret) # 预激活
return ret
return inner
@init
def average():
sum_money = 0
day = 0
avg = 0
while True:
money = yield avg
sum_money += money
day += 1
avg = sum_money/day
g = average()
print(g.send(200))
print(g.send(300))
print(g.send(600))
执行结果:
200.0
250.0
366.6666666666667
# yield from
def generator_func():
yield from range(5) #相当于for循环
yield from 'hello'
# for i in range(5):
# yield i
# for j in 'hello':
# yield j
g = generator_func()
for i in generator_func():
print(i)
执行结果:
0
1
2
3
4
h
e
l
l
o
总结:
# 如何从生成器中取值
# 第一种 :next 随时都可以停止 最后一次会报错
# print(next(g))
# print(next(g))
结果是:
0
1
# 第二种 :for循环 从头到尾遍历一次 不遇到break、return不会停止
# for i in g:
# print(i)
结果是g中每个元素输出出来了,一竖列
# 第三种 :使用list tuple 数据类型的强转 会把所有的数据都加载到内存里 非常的浪费内存
# print(g)
# print(list(g)) 相当于强制把g中的每个元素取出来生成一个列表
执行结果:
<generator object generator_func at 0x01E654E0>
[0, 1, 2, 3, 4, 'h', 'e', 'l', 'l', 'o']
# 生成器函数 是我们python程序员实现迭代器的一种手段
# 主要特征是 在函数中 含有yield
# 调用一个生成器函数 不会执行这个函数中的代码 只是会获得一个生成器(迭代器)
# 只有从生成器中取值的时候,才会执行函数内部的代码,且每获取一个数据才执行得到这个数据的代码
# 获取数据的方式包括 next send 循环 数据类型的强制转化
# yield返回值的简便方法,如果本身就是循环一个可迭代的,且要把可迭代数据中的每一个元素都返回 可以用yield from
# 使用send的时候,在生成器创造出来之后需要进行预激,这一步可以使用装饰器完成
# 生成器的特点 : 节省内存 惰性运算
# 生成器用来解决 内存问题 和程序功能之间的解耦
# 列表推倒式
举例1:
new_lst = []
for i in range(10):
new_lst.append(i**2)
print(new_lst)
执行结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
上面的可以用一句话写:
print([i**2 for i in range(10)]) #这个就是列表推导式
执行结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
举例2:求0到9对2取余
print([i%2 for i in range(10)])
执行结果:[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
举例3:求l列表中的所有奇数
l = [1,2,3,-5,6,20,-7]
print([num for num in l if num%2 == 1])
执行结果:[1, 3, -5, -7]
举例4:
# 30以内所有能被3整除的数
print([num for num in range(30) if num %3 ==0])
执行结果:[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
举例5:
# 30以内所有能被3整除的数的平方
print([num**2 for num in range(30) if num %3 ==0])
执行结果:[0, 9, 36, 81, 144, 225, 324, 441, 576, 729]
举例6:
# 找到嵌套列表中名字含有两个‘e’的所有名字
names = [['Tom', 'Billy', 'Jefferson', 'Andrew', 'Wesley', 'Steven', 'Joe'],
['Alice', 'Jill', 'Ana', 'Wendy', 'Jennifer', 'Sherry', 'Eva']]
print([name for name_lst in names for name in name_lst if name.count('e') == 2])
执行结果:['Jefferson', 'Wesley', 'Steven', 'Jennifer']
# 生成器表达式
l = [i for i in range(30) if i%3 ==0] # 列表推倒式 排序的时候
g = (i for i in range(30) if i%3 ==0) # 生成器表达式 庞大数据量的时候 使用生成器表达式
print(l)
print(g)
for i in g:print(i)
执行结果:
[0, 3, 6, 9, 12, 15, 18, 21, 24, 27]
<generator object <genexpr> at 0x01E55420>
0
3
6
9
12
15
18
21
24
27
举例1:
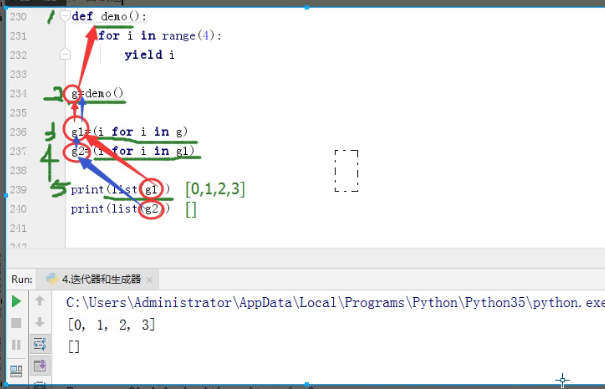
def demo():
for i in range(4):
yield i
g=demo()
g1=(i for i in g) #g1这个是生成器表达式,也没有取值,只是拿到个生成器的内存地址
g2=(i for i in g1) #这块也没有取值
print(list(g1)) #list强转 真正干活取值的是在这步开始的
print(list(g2)) #强转
执行结果:
[0, 1, 2, 3]
[]
执行顺序:
举例2:这个比较难理解
def add(n,i):
return n+i
#
def test():
for i in range(4):
yield i
g=test()
for n in [1,3,10]:
g=(add(n,i) for i in g)
print(list(g))
执行结果:[30, 31, 32, 33]
总结:
# 一个生成器 只能取一次
# 生成器在不找它要值的时候始终不执行
# 当他执行的时候,要以执行时候的所有变量值为准
四、内置函数(min max sorted filter map 面试明星知识点)
# len
# max min
# dir
举例:
def func():
a = 1
b = 2
print(locals())
print(globals())
# 全局命名空间中的名字
func()
执行结果:
{'b': 2, 'a': 1}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0052C410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'H:/MyProject/ke删除.py', '__cached__': None, 'func': <function func at 0x003FB660>}
print(locals()) # 本地的命名空间
print(globals()) # 全局的命名空间
执行结果:
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0041C410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'H:/MyProject/ke删除.py', '__cached__': None, 'func': <function func at 0x003DB660>}
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x0041C410>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'H:/MyProject/ke删除.py', '__cached__': None, 'func': <function func at 0x003DB660>}
举例2:99乘法表
# 99乘法表
for i in range(1,10):
for j in range(1,i+1):
print('%s * %s = %2s'%(i,j,i*j),end=' ')
print()
举例3:
print(1,2,3,4,5,sep=';',end=' ')
print(1,2,3,4,5,sep=';',end='')
执行结果:
1;2;3;4;5 1;2;3;4;5
#举例3:打印进度条(默认表示将输出的内容返回到第一个指针,这样的话,后面的内容会覆盖前面的内容)
import time
for i in range(0,101,2): #0,2,4,6,8
time.sleep(0.1)
char_num = i//2 #打印多少个'*' 4
if i == 100:
per_str = ' %s%% : %s ' % (i, '*' * char_num)
else:
per_str = ' %s%% : %s'%(i,'*'*char_num)
print(per_str,end='',flush=True) # 0.01 flush表示即时的意思
print() #写文件
执行结果:
100% : **************************************************
# python 能直接操作文件 —————— 需要发起系统调用 才能操作文件
举例4:hash
print(hash('1291748917'))
#对可hash的数据类型进行hash之后会得到一个数字
# 在一次程序的执行过程中 对相同的可哈希变量 哈希之后的结果永远相同的
# 在一次程序的执行过程中 对不相同的可哈希变量 哈希之后的结果几乎总是不相同的
# hash 字典底层的存储 和set 集合的去重机制
举例5:# callable 可调用
def func():pass
a = 1
print(callable(func))
print(callable(a))
执行结果:
True
False
举例6:查看一个变量所拥有的所有名字
print(dir('1')) # 查看一个变量所拥有的所有名字
执行结果:
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
举例7:
print(bin(10))
print(oct(10))
print(hex(10)) # 0123456789abcdef
执行结果:
0b1010
0o12
0xa
举例8:取绝对值
print(abs(4))
print(abs(-4))
执行结果:
4
4
举例9:商余函数,返回一个元组
print(divmod(10,2)) # 商余函数
print(divmod(7,3)) # 商余函数
print(divmod(9,7)) # 商余函数
执行结果:
(5, 0)
(2, 1)
(1, 2)
举例10、round()
print(round(3.1415926,4)) # 默认取整,小数精确 会四舍五入
执行结果:3.1416
举例11、
print(pow(2,3,5)) # 相当于(2**3)%5
print(pow(3,2,2))
执行结果:
3
1
举例12、sum
print(sum([1,2,3,4,5]))
print(sum([1,2,3,4,5],0)) #0代表起始值
print(sum([1,2,3,4,5],20)) #20代表起始值
print(sum(range(1,6)))
执行结果:
15
15
35
15
举例13、min
print(min([1,2,3,4,5]))
print(min(1,2,3,4))
print(min(1,-2,3,-4))
print(min(1,-2,3,-4,key=abs))
执行结果:
1
1
-4
1
def func(num):
return num%2 #对2区域之后,是0,1,0,那么最小的0对应的就是-2
print(min(-2,3,-4,key=func))
执行结果:-2
举例14、reverse和reversed
ret = [1,2,3,4,5]
ret.reverse()
print(ret)
执行结果:[5, 4, 3, 2, 1]
ret = [1,2,3,4,5]
# ret.reverse() 直接改变原来的值
# print(ret)
ret1 = reversed(ret)
ret2 = reversed((1,2,3,4,5))
print(ret)
print(list(ret1)) #没改变原来的值,只是赋值给了新的
print(list(ret2)) #没改变原来的值,只是赋值给了新的
执行结果:
[1, 2, 3, 4, 5]
[5, 4, 3, 2, 1]
[5, 4, 3, 2, 1]
举例15、format
print(format('test', '<20'))
print(format('test', '>20'))
print(format('test', '^20'))
执行结果:
test
test
test
举例16、
print(ord('a')) # 小写的a-z 97+26 A-Z 65+26
print(chr(97))
执行结果:
97
a
举例17、
print(1)
print('1')
print(repr(1))
print(repr('1'))
执行结果:
1
1
1
'1'
举例18、enumerate
l = ['苹果','香蕉']
ret = enumerate(l,1) # 枚举 接收两个参数:一个容器类型,一个序号起始值 返回值:可迭代的
print(ret)
for num,item in enumerate(l,1):
print(num,item)
执行结果:
<enumerate object at 0x006C8418>
1 苹果
2 香蕉
举例19、all (0为False、空字符串为false,None为false,all的话有一个为false为false)
print(all([1,2,3,4,5]))
print(all([0,1,2,3,4,5]))
print(all(['a',1,2,3,4,5]))
print(all(['',1,2,3,4,5]))
print(any([0,None,False]))
print(all([None]))
print(any([0,None,True])) #任何一个为true为true
执行结果:
True
False
True
False
False
False
True
举例20、拉链方法(以最少的为准)
ret = zip([1,2,3,4,5],('a','b','c','d'),(4,5)) #拉链方法
print(ret)
for i in ret:
print(i)
执行结果:
<zip object at 0x007684B8>
(1, 'a', 4)
(2, 'b', 5)
举例21:filter(过滤)
lst = [1, 4, 6, 7, 9, 12, 17]
def func(num):
if num % 2 == 0:return True
filter(func,lst)
for i in filter(func,lst):
print(i)
执行结果:
4
6
12
# g = (i for i in lst if i%2 == 0) 上面的相当于这句
for i in g:
print(i)
找到list中非空的字符串
l = ['test', None, '', 'str', ' ', 'END']
def func(item):
if item and item.strip():return True
for i in filter(func,l):
print(i)
执行结果:
test
str
END
举例22:map
#[i**2 for i in range(10)]
def func(num):
return num ** 2
for i in map(func,range(10)):print(i)
执行结果:
0
1
4
9
16
25
36
49
64
81
举例23:排序功能sort(改变原来的)、sorted(不改变原来的,生成新的)
# 排序功能
l = [1,-4,-2,3,-5,6,5]
l.sort(key=abs)
print(l)
l = [1,-4,-2,3,-5,6,5]
new_l = sorted(l,key=abs,reverse=True)
print(new_l)
执行结果:
[1, -2, 3, -4, -5, 5, 6]
[6, -5, 5, -4, 3, -2, 1]
l = [[1,2],[3,4,5,6],(7,),'123']
print(sorted(l,key=len))
执行结果:[(7,), [1, 2], '123', [3, 4, 5, 6]]
举例24:# eval()
文档里面给出来的功能解释是:将字符串string对象转化为有效的表达式参与求值运算返回计算结果
eval('print(123)')
exec('print(123)')
print(eval('1+2-3*20/(2+3)'))
print(exec('1+2-3*20/(2+3)'))
执行结果:
123
123
-9.0
None
总结:
# 内置函数
# 标红的如果不会
# 标黄的 是能够节省你的代码 面试会用
# min max sorted filter map 面试明星知识点
# 你经常不见 且没被点名说重点的 就不用特别了解了
五、匿名函数
1、lambda表达式
# def add(a,b):
# return a+b
add=lambda a,b : a+b 这个就相当于上面的def的函数,这个就是匿名函数
print(add(1,2))
执行结果:3
2、求10以内的数的平方的几种方法:
方法一、列表推导式
result=[i**2 for i in range(10)]
print(result)
执行结果:[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
方法二:生成器表达式
result=(i**2 for i in range(10))
for i in result:
print(i)
执行结果:
0
1
4
9
16
25
36
49
64
81
方法三、map内置函数
def func(num):
return num ** 2
for i in map(func,range(10)):print(i)
执行结果同方法二样式
方法四、map函数
for i in map(lambda num:num**2,range(10)):print(i)
3、
def func(num):
return num%2
print(min(-2,3,-4,key=func))
执行结果:-2
上面的可以写成:
print(min(-2,3,-4,key=lambda num: num%2))
执行结果:-2
4、lamdba表达式
d = lambda p:p*2
t = lambda p:p*3
x = 2
x = d(x) # x = 4
x = t(x) # x = 12
x = d(x)
print(x)
执行结果:24
4、练习题:(练习1&练习2)
# 练习1:现有两元组(('a'),('b')),(('c'),('d')),请使用python中匿名函数生成列表[{'a':'c'},{'b':'d'}]
方法一、
def func(t):
return {t[0]:t[1]}
ret = map(func,zip((('a'),('b')),(('c'),('d'))))
print(list(ret))
执行结果:[{'a': 'c'}, {'b': 'd'}]
方法二:
ret = map(lambda t:{t[0]:t[1]},zip((('a'),('b')),(('c'),('d'))))
print(list(ret))
执行结果:[{'a': 'c'}, {'b': 'd'}]
#练习2:
# 3.以下代码的输出是什么?请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print([m(2) for m in multipliers()])
执行结果:
[6, 6, 6, 6]
# def multipliers():
# lst = []
# i = 0
# lst.append(lambda x:i*x)
# i = 1
# lst.append(lambda x:i*x)
# i = 2
# lst.append(lambda x:i*x)
# i = 3
# lst.append(lambda x:i*x)
# # lst = [lambda x:3*2,lambda x:i*x,lambda x:i*x,lambda x:i*x]
# return lst
# print([m(2) for m in multipliers()])
改造后:
def multipliers():
return (lambda x:i*x for i in range(4))
g = (lambda x:i*x for i in range(4))
print([m(2) for m in g])
执行结果:[0, 2, 4, 6]
# 请修改multipliers的定义来产生期望的结果。
六、递归(递归最大深度是997或者998)
# def func():
# print(1)
# func()
#
# func() # 997 /998
# import sys
# def foo(n):
# print(n)
# n += 1
# foo(n)
# foo(1)
# 6!
# print(6*5*4*3*2*1) #720
def fn(n):
if n == 1:return 1
return n*fn(n-1)
print(fn(6))
执行结果:720
# 递归 就是自己调用自己
# 递归需要有一个停止的条件
# def fn(6):
# if 6 == 1:return 1
# return 6*fn(5)
# print(fn(6))
#
# def fn(5):
# return 5*fn(4)
#
# def fn(4):
# return 4*fn(3)
#
# def fn(3):
# return 3*fn(2)
#
# def fn(2):
# return 2*fn(1)
#
# def fn(1):
# return 1
复习:
一、生成器和迭代器
迭代器 : iter next
可以被for循环 节省内存空间 它没有所谓的索引取值的概念 当前的值和下一个值- 公式
生成器和迭代器本质上是一样的
yield函数
执行生成器函数 会得到一个生成器 不会执行这个函数中的代码
有几个yield,就能从中取出多少个值
生成器表达式
生成器表达式也会返回一个生成器 也不会直接被执行
for循环里有几个符合条件的值生成器就返回多少值
每一个生成器都会从头开始取值,当取到最后的时候,生成器中就没有值了
一个生成器只能用一次
def fff():
for i in range(10):
yield i
g2 = (i**i for i in range(20))
g = fff()
print(next(g))
print(next(g))
print(next(g))
执行结果:
0
1
2
def fff():
for i in range(10):
yield i
g2 = (i**i for i in range(20))
g = fff()
# print(next(g))
# print(next(g))
# print(next(g))
print(next(fff()))
print(next(fff()))
print(next(fff()))
执行结果:
0
0
0
def fff():
for i in range(10):
yield i
g2 = (i**i for i in range(20))
g = fff()
# print(next(g))
# print(next(g))
# print(next(g))
# print(next(fff()))
# print(next(fff()))
# print(next(fff()))
for i in fff():
print(i)
执行结果:
0
1
2
3
4
5
6
7
8
9
# 内置函数和匿名函数
# map filter sorted max min zip(重点)
def func(n):
if n%2 == 0:
return True
ret = filter(func,range(20))
# ret = filter(lambda n: True if n%2 == 0 else False ,range(20))
# ret = filter(lambda n: n%2 == 0 ,range(20))
print(list(ret))
执行结果:[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
def func(n):
if n%2 == 0:
return True
# ret = filter(func,range(20))
ret = filter(lambda n: True if n%2 == 0 else False ,range(20))
# ret = filter(lambda n: n%2 == 0 ,range(20))
print(list(ret))
执行结果:[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
def func(n):
if n%2 == 0:
return True
# ret = filter(func,range(20))
# ret = filter(lambda n: True if n%2 == 0 else False ,range(20))
ret = filter(lambda n: n%2 == 0 ,range(20))
print(list(ret))
执行结果:[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]