郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Published as a conference paper at ICLR 2020
ABSTRACT
我们提出了一种称为SEED(可扩展的高效深度强化学习)的现代可扩展强化学习智能体。通过有效利用现代加速器,我们表明与当前方法相比,不仅可以每秒进行数百万帧的训练,而且还可以降低实验成本。我们通过一个简单的架构来实现这一点,该架构具有集中推理和优化的通信层。SEED采用两种最先进的分布式算法,IMPALA/V-trace(策略梯度)和R2D2 (Q-learning),并在Atari-57、DeepMind Lab和Google Research Football上进行评估。我们改进了足球的最先进技术,并且能够将 Atari-57 上的最先进技术提高三倍的时间。对于我们考虑的场景,运行实验的成本降低了40%到80%。实现和实验是开源的,因此可以复制结果并尝试新颖的想法。
Github: http://github.com/google-research/seed_rl.
1 INTRODUCTION
2 RELATED WORK
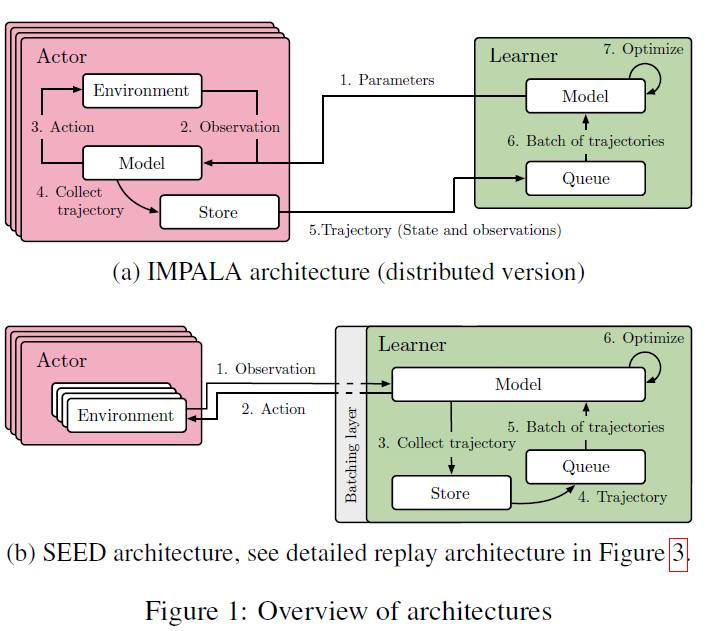
3 ARCHITECTURE
在介绍SEED的架构之前,我们先分析一下IMPALA使用的通用的执行者-学习者架构,它在Ape-X,OpenAI Rapid等中也有各种形式的使用。该架构的概述如图1a所示。
大量执行者从学习者(或参数服务器)重复读取模型参数。然后,每个执行者使用本地模型对动作进行采样,并生成观测值、动作、策略逻辑/Q值的完整轨迹。最后,这个轨迹连同循环状态被转移到一个共享队列或重放缓冲区。异步地,学习者从队列/重放缓冲区读取成批的轨迹,并优化模型。
有很多原因导致了这个架构的不足:
- 使用CPU进行神经网络推理:执行者机器通常基于CPU(在昂贵的环境中偶尔基于GPU)。众所周知,对于神经网络来说,CPU的计算效率很低(Raina et al., 2009)。当模型的计算需求增加时,花费在推理上的时间开始超过环境步骤计算。解决方案是增加执行者的数量,这会增加成本并影响收敛(Espeholt et al., 2018)。
- 低效的资源利用:执行者在两个任务之间交替:环境步骤和推理步骤。这两个任务的计算需求通常不相似,这将导致较低的利用率或较慢的执行者。例如,有些环境本质上是单线程的,而神经网络很容易并行化。
- 带宽要求:模型参数、循环状态和观测值在执行者和学习者之间传递。相对于模型参数,观测轨迹的大小往往只占几个百分比1。此外,基于内存的模型发送较大的状态,增加带宽需求。
虽然单机方法如GA3C (Mahmood, 2017)和单机IMPALA避免使用CPU进行推理(1),没有网络带宽要求(3),但它们受到资源使用(2)和许多类型环境所需的规模的限制。
SEED(图1b)中使用的架构解决了上面提到的问题。推理和轨迹积累转移到学习者,使其在概念上成为带有远程环境的单机设置(除了处理故障)。有效地移动逻辑使执行者在环境周围形成一个小循环。对于每一个单独的环境步骤,观测值结果都被发送给学习者,学习者运行推断并将操作发回给执行者。这就带来了一个新问题:延迟。
为了减少延迟,我们创建了一个使用gRPC (grpc.io)的简单框架——高性能RPC库。具体来说,我们采用流式RPC,从执行者到学习者的连接保持开放,元数据只发送一次。此外,该框架还包括一个批处理模块,可以有效地将多个执行者推断调用批处理在一起。在执行者和学习者可以在同一台机器上工作的情况下,gRPC使用unix域套接字,从而减少了延迟、CPU和系统调用开销。总的来说,端到端延迟(包括网络和推理)对于我们考虑的许多模型来说都更快(参见附录A.7)。
IMPALA和SEED架构的不同之处在于,对于SEED,在任何时间点上,只有一个模型的副本存在,而对于分布式IMPALA,每个执行者都有自己的副本。这改变了轨迹偏离策略的方式。在IMPALA(图2a)中,执行者对整个轨迹使用相同的策略。对于SEED(图2b),轨迹展开期间的策略可能会多次改变,后续步骤使用更接近优化时使用的策略。
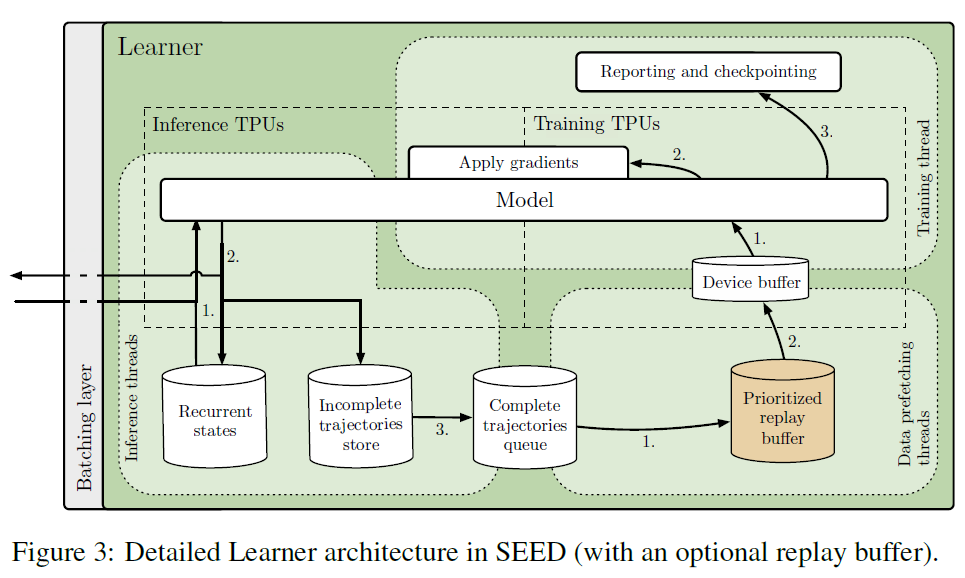
图3显示了SEED架构中执行者的详细视图。有三种类型的线程正在运行:1、推理;2、数据预取;3、训练。推理线程接收一批观测值、奖励和回合终止标志。它们加载循环状态并将数据发送到推断TPU核。采样的动作和新的循环状态被接收,动作被发送回执行者,而最新的循环状态被存储。当轨迹完全展开时,它会被添加到FIFO队列或重放缓冲区,然后由数据预取线程进行采样。最后,轨迹被推到每个TPU核参与训练的设备缓冲区。训练线程(Python main线程)获取预取的轨迹,使用训练TPU核计算梯度,并同步地将梯度应用于所有TPU核的模型(推理和训练)。可以调整推理和训练核的比率,以获得最大的吞吐量和利用率。该体系结构通过轮转将执行者分配给TPU主机,并为每个TPU主机拥有单独的推理线程,从而扩展到一个TPU pod(2048核)。当执行者等待学习者的响应时,它们是空闲的,所以为了充分利用机器,我们在一个执行者上运行多个环境。
综上所述,我们通过以下方式解决上述问题:
- 移动推理到学习者,从而在执行者中消除任何神经网络相关的计算。在这个体系结构中增加模型大小并不会增加对更多执行者的需求(事实上恰恰相反)。
- 学习者进行批量推理,而执行者有多个环境。这充分利用了学习者上的加速器和执行者上的CPU。用于推理和训练的TPU核数经过微调,以匹配推理和训练工作负载。所有的因素都有助于降低实验成本。
- 所有涉及模型的东西都留在学习者身上,只有观测值和动作在执行者和学习者之间发送。这将减少多达99%的带宽需求。
- 使用具有最小延迟和最小开销的流式gRPC,并将批处理集成到服务器模块中。
我们提供了在SEED框架中实现的两种算法:V-trace和Q-learning。
1每秒发送100000次观测(每个96 x 72 x 3字节),轨迹长度为20,模型为30MB,总带宽要求为148 GB/s。传输观测值仅使用2 GB/s。

3.1 V-TRACE
我们在框架中采用的算法之一是V-trace (Espeholt et al., 2018)。我们不包括已提议在IMPALA上增加的任何东西,如van den Oord et al. (2018); Gregor et al. (2019)。添加的内容也可以应用到SEED,由于它们的计算成本更高,它们将从SEED架构中受益。
3.2 Q-LEARNING
我们通过完全实现R2D2 (Kapturowski et al., 2018)展示了SEED架构的多功能性,R2D2是一种最先进的基于价值的分布式智能体。R2D2本身建立在一长串DQN (Mnih et al., 2015)改进的基础上:双重Q学习(van Hasselt, 2010; Van Hasselt et al., 2016),多步引导目标(Sutton, 1988; Sutton & Barto, 1998; Mnih et al., 2016),对偶网络架构(Wang et al., 2016),优先分布式重放缓冲区(Schaul et al., 2015; Horgan et al., 2018),值-函数缩放(Pohlen et al., 2018),LSTM's (Hochreiter & Schmidhuber, 1997)和burn-in (Kapturowski et al., 2018)。
代替一个分布式重放缓冲区,我们展示了用一个简单灵活的实现在学习者上保持重放缓冲区是可能的。这通过在设置中删除一种类型的工作来降低复杂性。它的缺点是学习者的内存有限,但这在我们的实验中以很大的优势不是一个问题:105个轨迹的重放缓冲区,其中轨迹由120个84×84的未压缩灰度观测值组成(遵循R2D2的超参数),需要85 GB的内存,而谷歌云机器可以提供数以百计的GB。然而,在需要更大的重放缓冲区的情况下,没有什么可以阻止分布式重放缓冲区与SEED的中心推断一起使用。
4 EXPERIMENTS
4.1 DEEPMIND LAB AND V-TRACE
4.1.1 STABILITY
4.1.2 SPEED
4.2 GOOGLE RESEARCH FOOTBALL AND V-TRACE
4.2.1 SPEED
4.2.2 INCREASED MAP SIZE
4.3 ARCADE LEARNING ENVIRONMENT AND Q-LEARNING
4.4 COST COMPARISONS
4.4.1 DEEPMIND LAB
4.4.2 GOOGLE RESEARCH FOOTBALL
4.4.3 ARCADE LEARNING ENVIRONMENT
5 CONCLUSION
A APPENDIX
A.1 DEEPMIND LAB
A.1.1 LEVEL CACHE
A.1.2 HYPERPARAMETERS
A.2 GOOGLE RESEARCH FOOTBALL
A.2.1 HYPERPARAMETERS
A.3 ALE
A.3.1 HYPERPARAMETERS
A.3.2 FULL RESULTS ON ATARI-57
A.4 SEED LOCALLY AND ON CLOUD
A.5 EXPERIMENTS COST SPLIT
A.6 COST COMPARISON ON DEEPMIND LAB USING NVIDIA P100 GPUS
A.7 INFERENCE LATENCY