郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

ICCV 2021(同组的工作,已集成入SpikingJelly平台)
Abstract
由于时序信息处理能力、低功耗和高生物合理性,脉冲神经网络(SNN)引起了巨大的研究兴趣。然而,为SNN制定高效和高性能的学习算法仍然具有挑战性。大多数现有的学习方法只学习与突触相关的参数,并且需要手动调整膜相关参数,这些参数决定了单个脉冲神经元的动态。这些参数通常被选择为对所有神经元都相同,这限制了神经元的多样性,从而限制了所得SNN的表达能力。在本文中,我们从不同大脑区域膜相关参数不同的观察中汲取灵感,提出了一种训练算法,该算法不仅能够学习SNN的突触权重,还能够学习膜时间常数。我们表明,结合可学习的膜时间常数可以使网络对初始值不那么敏感,并可以加快学习速度。此外,我们重新评估了SNN中的池化方法,发现最大池化能够提高SNN在时间任务中的拟合能力,并降低计算成本。我们在传统静态MNIST、Fashion-MNIST、CIFAR-10数据集和神经形态N-MNIST、CIFAR10-DVS、DVS128手势数据集上评估了所提出的图像分类任务方法。实验结果表明,所提出的方法在几乎所有数据集上都优于最先进的精度,使用更少的时间步长。
1. Introduction
脉冲神经网络(SNN)被视为第三代神经网络模型,它更接近大脑中的生物神经元[38]。与神经元和突触状态一起,SNN中还考虑了脉冲时序的重要性。由于其独特的特性,例如时序信息处理能力、低功耗[50]和高生物合理性[16],近年来SNN越来越引起研究人员的极大兴趣。然而,为SNN制定高效和高性能的学习算法仍然具有挑战性。
通常,SNN的学习算法可以分为无监督学习、监督学习、基于奖励的学习和人工神经网络(ANN)到SNN的转换方法。无论哪种方式,我们发现大多数现有的学习方法只考虑学习突触相关参数,如突触权重,并将膜相关参数视为超参数。这些与膜相关的参数,如膜时间常数,决定了单个脉冲神经元的动力学,通常选择为对所有神经元都相同。然而,请注意,跨大脑区域的脉冲神经元存在不同的膜时间常数[39, 9],这被证明对于工作记忆的表示和学习的制定[20, 54]是必不可少的。因此,简单地忽略SNN中的不同时间常数将限制神经元的异质性,从而限制所得SNN的表达能力。
在本文中,我们提出了一种训练算法,该算法不仅能够学习SNN的突触权重,还能够学习膜时间常数。如图1所示,我们发现突触权重和膜时间常数的调整对神经元动力学有不同的影响。我们表明,结合可学习的膜时间常数能够增强SNN的学习。
本文的主要贡献可以总结如下:
- 我们提出了基于反向传播的学习算法,使用具有可学习膜参数的脉冲神经元,称为参数化LIF (PLIF)脉冲神经元,它更好地代表了神经元的异质性,从而增强了SNN的表达能力。我们表明,由PLIF神经元组成的SNN对初始值更稳健,并且比由具有固定时间常数的神经元组成的SNN学习得更快。
- 我们重新评估了SNN中的池化方法,并否定了先前的结论,即最大池化会导致显著的信息丢失。我们表明,通过在空间域中引入赢家通吃机制和在时间域中引入时变拓扑,最大池化可以提高SNN在时间任务中的拟合能力并降低计算成本。
- 我们在ANN中广泛用作基准的传统静态MNIST [31]、Fashion-MNIST [60]、CIFAR-10 [30]数据集以及神经形态N-MNIST [44]、CIFAR10-DVS [35]上评估我们的方法,DVS128 Gesture [1]数据集,用于验证网络的时序信息处理能力。所提出的方法使用更少的时间步长,在几乎所有测试数据集上都超过了最先进的精度。

2. Related Works
Unsupervised learning of SNNs SNN的无监督学习方法基于生物学合理的局部学习规则,如Hebbian学习[22]和SpikeTiming-Dependent Plasticity (STDP)[3]。现有方法利用自组织原理[57, 11, 28]和基于STDP的期望最大化算法[43, 17]。然而,这些方法只适用于浅层SNN,性能远低于最先进的ANN结果。
Reward-based learning of SNNs SNN的基于奖励的学习通过利用多巴胺能、血清素能、胆碱能或肾上腺素能神经元诱导的奖励或惩罚信号来模仿人类大脑的学习方式[13, 6, 41]。尽管在强化学习中出现了一些方法,如策略梯度[53, 27]、时序差分学习[47, 14]和Q-learning[6],但一些基于STDP 的启发式现象学模型也在最近被提出[15, 63]。
ANN to SNN conversion ANN到SNN的转换(ANN2SNN)通过使用每个脉冲神经元的发放率来近似模拟神经元的相应ReLU激活[24, 7, 51],将经过训练的非脉冲ANN转换为SNN。它可以获得与ANN相比接近无损的推理结果[52],但在准确性和延迟之间存在权衡。为了提高准确性,需要更长的推理延迟[19]。ANN2SNN仅限于发放率编码,这在时序任务中失去了处理能力。据我们所知,ANN2SNN仅适用于静态数据集,不适用于神经形态数据集。
Supervised learning of SNNs SpikeProp[5]是第一个基于反向传播的SNN监督学习方法,它使用线性近似来克服SNN不可微分的阈值触发发放机制。随后的工作包括Tempotron[18]、ReSuMe[46]和SPAN[40],但它们只能应用于单层SNN。最近,替代梯度方法被提出并提供了另一种训练多层SNN的解决方案[34, 25, 65, 58, 55, 33, 26]。它利用替代导数来定义阈值触发发放机制的导数。因此,SNN可以使用梯度下降算法作为ANN进行优化。实验表明,通过替代梯度方法优化的SNN显示出与ANN的竞争性能[42]。与 ANN2SNN相比,替代梯度方法对模拟时间步长没有限制,因为它不是基于发放率编码[59, 64]。
Spiking neurons and layers of deep SNNs 脉冲神经元和层模型在SNN中起着至关重要的作用。Wu et al. [59]提出神经元归一化来平衡每个神经元的发放率,以避免严重的信息丢失。Cheng et al. [8]增加了相邻神经元之间的横向相互作用,获得了更好的准确性和更强的噪声鲁棒性。Zimmer et al. [66]首先在语音识别任务中采用LIF神经元中的可学习时间常数。Bellec et al. [2]提出了自适应阈值脉冲神经元来增强SNN的计算和学习能力,[62]对其进行了改进,具有可学习的时间常数。Rathi et al. [48]提出使用可学习的膜泄漏和发放阈值来微调从ANN转换而来的SNN。尽管如此,到目前为止还没有系统研究学习膜时间常数对SNN的影响,这正是本文的目的。
3. Method
在本节中,我们首先简要回顾一下第3.1节中的LIF模型,在第3.2节分析突触权重和膜时间常数的影响。然后在第3.3节和第3.4节中介绍了参数化LIF模型和SNN的网络结构。最后,我们在第3.5节和第3.6节中描述了脉冲最大池化和SNN的学习算法。
3.1. Leaky Integrate-and-Fire model
3.2. Function comparison of synaptic weight and membrane time constant
3.3. Parametric Leaky Integrate-and-Fire model
3.4. Network Formulation
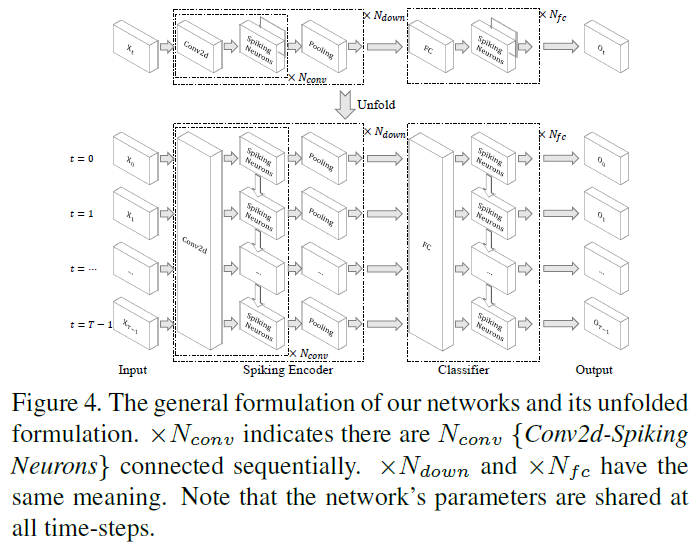
3.5. Spike Max-Pooling
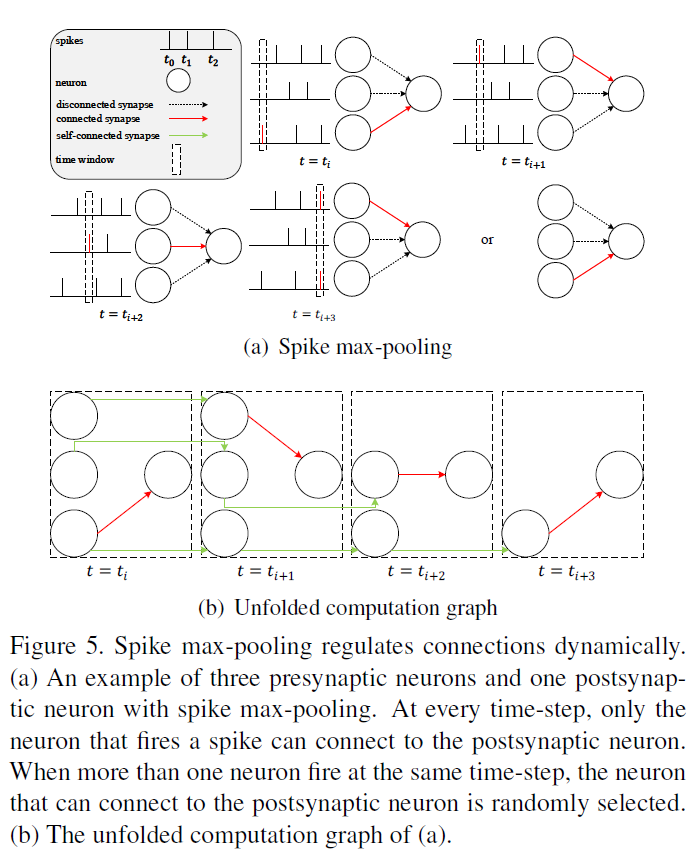
池化层被广泛用于减少特征图的大小并在卷积ANN和SNN中提取紧凑的表征。大多数先前的研究[52, 8, 49]更喜欢在SNN中使用平均池化,因为他们发现SNN中的最大池会导致显著的信息丢失。我们认为最大池化与SNN的时间信息处理能力一致,可以提高SNN在时间任务中的拟合能力并降低下一层的计算成本。
具体来说,在我们的模型中,最大池化层位于脉冲神经元层之后(图4),并且最大池化操作是在脉冲上进行的。与所有神经元在平均池化窗口中均等地向下一层传递信息不同的是,只有神经元在最大池化窗口中发出脉冲信号才能将信息传递到下一层。因此,最大池化层引入了赢家通吃的机制,允许最活跃的神经元与下一层通信,而忽略池化窗口中的其他神经元。另一个吸引人的特性是最大池化层将动态调节连接(图5)。脉冲神经元的膜电位Vt将在发放脉冲后返回Vreset。由于充电需要时间,因此脉冲神经元很难再次发放。但是,如果最大池化窗口中的神经元异步发放,它们将依次连接到突触后神经元,这使得突触后神经元类似于连接一个持续发放的突触前神经元,更容易发放。通过最大池化实现的空间域中的赢家通吃机制和时域中的时变拓扑结构可以提高SNN在时间任务中的拟合能力,例如对CIFAR10-DVS数据集进行分类。值得注意的是,最大池化层的输出仍然是二进制的,而平均池化层的输出是浮点数。将乘法替换为逻辑AND &可以加速对脉冲的矩阵乘法和逐元素乘法运算,这也是SNN与ANN相比的优势。
3.6. Training Framework
4. Experiments
我们在传统静态MNIST、Fashion-MNIST、CIFAR-10数据集和神经形态N-MNIST、CIFAR10-DVS和DVS128手势数据集上评估具有PLIF神经元和脉冲最大池的SNN的性能,用于分类任务。有关训练的更多详细信息,请参见补充资料。
4.1. Preprocessing
4.2. Network Structure

4.3. Performance
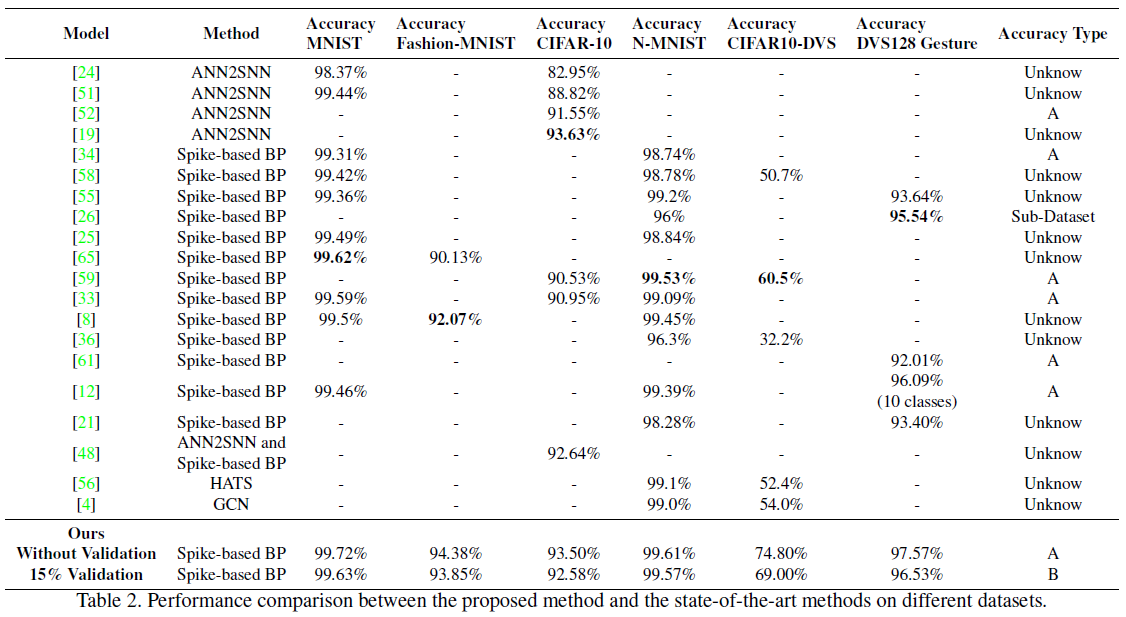
Quantitative evaluation. 表2显示了所提出的方法和其他比较方法在传统静态MNIST、Fashion-MNIST、CIFAR-10数据集和神经形态N-MNIST、CIFAR10-DVS、DVS128手势数据集上的准确性。我们为所有数据集设置了相同的训练超参数(见补充)。为了公平比较,我们报告了两种类型的准确性。在训练集上训练,交替在测试集上测试,记录最大测试精度,得到accuracy-A。accuracy-B是通过将原始训练集拆分为新的训练集和验证集,在新的训练集上训练,交替在验证集上进行测试,并在测试集上只记录一次达到最大验证精度的模型的测试准确率。我们知道方法B是迄今为止最佳实践,因为方法A高估了泛化精度。不幸的是,以前的大部分工作都使用了方法A(见表2)。因此,我们决定将其包括在内以进行公平比较。我们利用原始训练集中每个类的85%样本作为新训练集,将其余15%设置为验证集。如表2所示,无论有没有验证集,我们的方法在 MNIST、Fashion-MNIST、N-MNIST、CIFAR10-DVS 和 DVS128 Gesture 上都达到了最高的准确率。CIFAR-10的准确率略低于基于ANN2SNN转换的[19]。然而,它们仅适用于静态图像,因为ANN不适用于神经形态数据集。与它们不同的是,我们的方法也适用于神经形态数据集并且优于SOTA精度。
表3比较了我们的方法和之前在每个数据集上实现最佳性能的方法的时间步数。可以发现,所提出的方法比所有其他方法花费的时间步数更少。例如,与ANN2SNN转换[19]相比,我们的方法使用了比它小256倍的推理时间步长。因此,我们的方法不仅可以减少内存消耗和训练时间,还可以大大提高推理速度。

Visualization of the spiking encoder. 如第3.4节所示,带有脉冲神经元的传统层可以看作是一个可学习的脉冲编码器。在此,我们展示了脉冲编码器的可视化(图6)。来自DVS128 Gesture数据集的三个样本标记random other gestures,right hand clockwise,t = 0, 1, ..., 19时的drums,显示在图6的第1、3、5行。为了比较,第2、4、6行显示了来自第一个常规层中PLIF神经元通道59的相应输出脉冲。关键的区别在于输出几乎只包括手势的响应脉冲,这表明脉冲神经元对空间变量和时间变量输入数据实现了高效和准确的过滤,保留了手势但丢弃了玩家(更多结果见补充)。


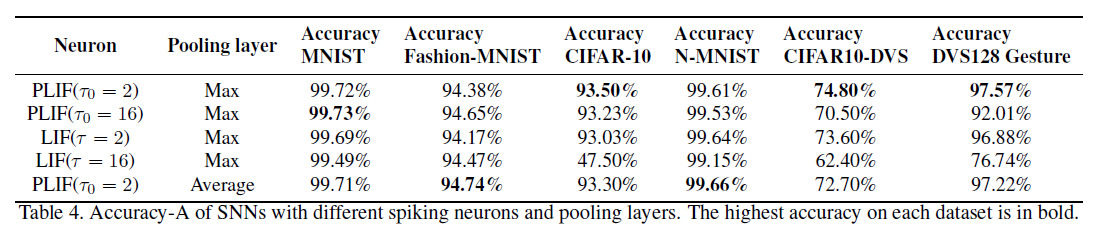
Comparison of PLIF and LIF. 我们在四个具有挑战性的数据集上比较了PLIF神经元和LIF神经元的accuracy-A,以说明PLIF神经元的好处(图7)。可以看出,如果将PLIF神经元的初始膜时间常数τ0设置为等于LIF神经元的膜时间常数τ,则带有PLIF神经元的SNN的测试精度始终高于带有LIF神经元的SNN。这是因为学习后不同层的PLIF神经元的膜时间常数可以不同,更能代表神经元的异质性。此外,如果膜时间常数的初始值不合理(红色曲线),带有LIF神经元的SNN的准确性和收敛速度会严重下降。相比之下,PLIF神经元可以学习适当的膜时间常数并获得更好的性能(绿色曲线)。为了分析PLIF神经元中初始值的影响,我们展示了在学习过程中每一层神经元的膜时间常数如何随着不同的初始值而变化。如图8所示,每层具有不同初始值的膜时间常数在训练过程中趋于聚集,这表明PLIF神经元对初始值具有鲁棒性。
表4总结了在所有六个数据集上具有不同神经元模型和池化层的SNN的accuracy-A。不同方法在简单数据集(例如MNIST和N-MNIST)上的性能非常接近且不显著。当数据集很复杂时,具有PLIF神经元的SNN的准确度总体上优于具有LIF神经元的SNN。表4中的最后一行表明最大池化的性能与平均池化相似,这证明了之前关于在SNN中使用最大池化的怀疑是不合理的。值得注意的是,最大池化在CIFAR-10、CIFAR10-DVS和DVS128 Gesture数据集上的准确率略高,表明其在复杂任务中具有更好的拟合能力。
5. Conclusion
在这项工作中,我们提出了PLIF神经元,将可学习的膜时间参数合并到SNN中。我们表明,带有PLIF神经元的SNN在静态和神经形态数据集上的性能都优于最先进的比较方法。此外,我们证明了由PLIF神经元组成的SNN对初始值的鲁棒性更强,并且比由LIF神经元组成的SNN学习得更快。我们还重新评估了SNN中最大池化和平均池化的性能,发现之前的工作低估了最大池化的性能。我们提出在SNN中使用最大池化,因为它具有更低的计算成本、更高的时间拟合能力以及接收脉冲和输出脉冲的特性,而不是作为平均池化的浮动值。
A. Supplementary Materials
A.1. Reproducibility
A.2. RNN-like Expression of LIF and PLIF
A.3. Introduction of the Datasets
A.4. Network Structure Details
A.5. Training Algorithm to Fit Target Output
A.6. HyperParameters

A.7. Visualization of Spiking Encoder
正如正文中提到的,带有脉冲神经元的卷积层可以看作是脉冲编码器,它从模拟输入中提取特征并将它们转换为脉冲。与广泛用于SNN [11,33,55]的泊松编码器不同,脉冲编码器是一种可学习的编码器。为了评估编码器,我们向训练网络提供输入xt,并显示来自第 n 层通道 c 的输出脉冲![]() 和发放率
和发放率![]() ,类似于[10]。尽管来自更深脉冲神经元层的输出脉冲包含更多语义特征,但它们更难阅读和理解。因此,我们只显示来自第一个脉冲神经元层的脉冲,即n = 2。
,类似于[10]。尽管来自更深脉冲神经元层的输出脉冲包含更多语义特征,但它们更难阅读和理解。因此,我们只显示来自第一个脉冲神经元层的脉冲,即n = 2。
图9说明了来自静态FashionMNIST数据集(第1行)的10个输入图像以及第一个PLIF神经元层(第2、3和4行)的三个典型通道(45、75和76)的发放率。可以发现来自通道45、75和76的发放率检测输入图像的上、左、右边缘。图10(a)显示了当给定标记为horse的输入样本时,来自3-D张量![]() (c = 0, 1, ... , 127)的跨通道的2-D网格展平,这说明了特征在t = 0时由脉冲编码器提取。由于CIFAR10-DVS数据集是从静态CIFAR10数据集转换而来的,从脉冲中累积的发放率可以重建由卷积层滤波的图像。图10(b)说明了所有128个通道(c = 0, 1, ... , 127)的发放率
(c = 0, 1, ... , 127)的跨通道的2-D网格展平,这说明了特征在t = 0时由脉冲编码器提取。由于CIFAR10-DVS数据集是从静态CIFAR10数据集转换而来的,从脉冲中累积的发放率可以重建由卷积层滤波的图像。图10(b)说明了所有128个通道(c = 0, 1, ... , 127)的发放率![]() ,它们比图10(a)中的二值输出脉冲具有更清晰的纹理。图11(a)显示了输入xt(第1行)以及t = 0, 1, ... , 19时通道40和103(第2行和第3行)相应的输出脉冲
,它们比图10(a)中的二值输出脉冲具有更清晰的纹理。图11(a)显示了输入xt(第1行)以及t = 0, 1, ... , 19时通道40和103(第2行和第3行)相应的输出脉冲![]() ,并且图11(b)显示了平均输入
,并且图11(b)显示了平均输入![]() (第1行)和相应的通道40和103(第2行和第3行)的发放率,其中Ts = 0, 1, ... , 19。可以发现随着Ts的增加,由发放率
(第1行)和相应的通道40和103(第2行和第3行)的发放率,其中Ts = 0, 1, ... , 19。可以发现随着Ts的增加,由发放率![]() 构建的纹理变得更加清晰,这类似于使用泊松编码器。
构建的纹理变得更加清晰,这类似于使用泊松编码器。

