郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Front. Neurorobot., (2019): 81
Abstract
了解大脑的努力涉及多个合作研究领域。传统上,由理论神经科学家得出的突触可塑性规则是在模式分类任务中单独评估的。这与生物大脑形成对比,其目的是在闭环中控制身体。本文通过集成来自这两个领域的开源软件组件,有助于将计算神经科学和机器人领域更紧密地结合在一起。由此产生的框架允许评估闭环机器人环境中生物学合理可塑性模型的有效性。我们展示了这个框架,以通过在线强化学习来评估突触可塑性(Synaptic Plasticity with Online REinforcement learning, SPORE),这是一种基于突触采样的奖励学习规则,用于两个视觉运动任务:到达和车道跟随。我们表明,SPORE能够在模拟时间内为这两项任务学习执行策略。临时参数探索表明,需要调节控制突触学习动态的随机过程的学习率和温度,以保持性能改进。我们最后讨论了最近的深度强化学习技术,这将有助于增加SPORE在视觉运动任务上的功能。
Keywords: Neurorobotics, Synaptic Plasticity, Spiking Neural Networks, Neuromorphic Vision, Reinforcement Learning
1 Introduction
大脑进化了数百万年,其唯一目的是以目标为导向的方式控制身体。计算是依靠神经动力学和异步通信来执行的。脉冲神经网络模型的计算基于这些计算原理。定期提出用于脉冲神经网络功能学习的生物学合理的突触可塑性规则([46, 17, 32, 35, 41])。通常,导出这些规则是为了最小化网络输出与目标之间的距离(称为误差)。因此,这些规则的评估通常是在开环模式分类任务上进行的。通过忽略具体化,这种类型的评估忽略了大脑必须处理环境的闭环动态。事实上,大脑做出的决定会对环境产生影响,而这种变化会被大脑感知回来。为了更深入地了解这些规则的合理性,有必要进行具体评估。这种评估在技术上很复杂,因为脉冲神经元是必须与环境同步的动态系统。此外,与生物体一样,感觉信息和运动指令需要分别编码和解码。
在本文中,我们通过集成来自这两个领域的开源软件组件,将计算神经科学和机器人学领域更紧密地结合在一起。由此产生的框架能够以模块化方式通过脉冲网络在线学习模拟和真实机器人的控制。该框架在两个闭环机器人任务上对有前途的神经奖励学习规则突触可塑性与在线强化学习(SPORE) ([21, 19, 22, 45])的评估中得到了证明。SPORE是[21, 19]中介绍的突触采样方案的实例化。它结合了一种策略采样方法,该方法可以模拟关于多巴胺涌入的树突棘的生长。与当前使用传统神经网络([30, 29, 28])实现的最先进的强化学习方法不同,SPORE从精确的脉冲时间在线学习,并且完全由脉冲神经元实现。我们在闭环到达和车道跟随([4, 18])设置中评估此学习规则。在这两个任务中,学习了端到端的视觉运动策略,将视觉输入映射到运动命令。在过去的几年里,通过深度学习从视觉输入中学习控制取得了重要进展。然而,深度学习方法的计算成本很高,并且依赖于生物学上难以置信的机制,例如密集同步通信和批量学习。对于使用突触可塑性规则在线学习视觉运动任务的脉冲神经元网络仍然具有挑战性。在本文中,视觉输入被编码为地址事件表征和动态视觉传感器(DVS)模拟([27, 18])。这种表征极大地减少了视觉输入的冗余,因为只感知运动,从而提高学习效率。它与两种途径的假设一致,即运动与视觉皮层中的颜色和形状分开处理([25])。
本文的主要贡献是SPORE的实施例及其使用开源软件组件组合对两个神经机器人任务的评估。这个实施例使我们能够识别出调节SPORE学习动态的关键技术,在之前的工作中没有讨论过,该学习规则仅在简单的概念验证学习问题上进行评估([21, 19, 22, 45])。我们的结果表明,诸如学习率退火之类的外部机制有利于保留高级车道跟随任务的执行策略。
此篇文章的结构如下。我们在第2节中回顾了相关工作。在第3节中,我们简要概述了SPORE并讨论了其实现所需的贡献技术。在第4节中对两个选定的神经机器人任务进行了实现和评估。最后,我们在第5节中讨论了如何改进该方法。
2 Related Work
2015年是深度强化学习取得重大突破的一年。模拟神经元的人工神经网络现在能够解决各种任务,从玩电子游戏([30])到控制多关节机器人([39, 28])和车道跟随([44])。最近的方法([39, 38, 28, 29])基于策略梯度。具体来说,策略参数通过执行带有反向传播的上升梯度步骤来更新,以最大化采取奖励动作的概率。虽然功能有效,但这些方法并非基于生物学合理的过程。首先,很大一部分神经动力学被忽略了。重要的是,与SPORE不同,这些方法不会在线学习——权重更新是针对存储在rollout内存中的整个轨迹执行的。其次,学习基于反向传播,这不是生物学合理的学习机制,如[3]所述。
[40]和[2]介绍了受深度强化学习技术启发的脉冲网络模型。在这两篇论文中,脉冲网络都是用深度学习框架(分别是PyTorch和TensorFlow)实现的,并依赖于自动微分。他们的策略梯度方法基于近端策略优化(PPO) ([39])。由于学习机制包括反向传播PPO损失(在[2]的情况下是通过时间),[3]中所述的大多数生物约束仍然被违反。实际上,计算基于脉冲(4),但反向传播是纯线性的(1),反馈路径需要精确了解相应前馈路径的导数(2)和权重(3),以及前馈和反馈阶段同步交替(5)(枚举参考[3])。
只有一小部分工作专注于使用脉冲神经网络进行强化学习,同时解决了之前的问题。[16, 10, 26]介绍了使用脉冲网络进行强化学习的基础。在这些工作中,引入了一种数学形式化来表征多巴胺调节的脉冲时序依赖可塑性(DA-STDP)如何解决具有资格迹的远端奖励问题。特别是,由于只有在执行奖励动作后才会收到奖励,因此大脑需要一种记忆形式来强化先前选择的动作。这个问题是通过引入资格迹解决的,它将信度分配给最近活跃的突触。这个概念已经在大脑中观察到([11, 34]),而SPORE也依赖于资格迹。在奖励最大化的实施例中评估DA-STDP的工作较少——最近的一篇综述涵盖了这个主题,可在[5]中找到。
与本文最接近的先前工作是[18, 4]和[6]。[18]提出了神经机器人车道跟随任务,其中模拟车辆从基于事件的视觉到运动命令的端到端控制。该任务是通过一个由16个神经元组成的硬编码脉冲网络实现的,该网络实现了一个简单的Braitenberg车辆。性能是根据与车道中间的距离和方向差异来评估的。在本文中,这些性能指标被组合成一个奖励信号,脉冲网络使用SPORE学习规则最大化该信号。
在[4]中,作者在类似的车道跟随环境中评估了DA-STDP (对于奖励调节的STDP,称为R-STDP)。他们的方法优于[18]中提出的硬编码Braitenberg车辆。无论车辆在车道左侧还是右侧,控制转向的两个运动神经元都会接收不同的(镜像)奖励信号。这样,奖励提供了应该采取什么运动命令的信息,类似于监督学习设置。相反,本文中提出的方法更通用,因为全局奖励分配给所有突触,并且不指示智能体应该采取哪种动作。
[6]中导出了一个类似的可塑性规则,该规则采用策略梯度方法。同样依赖于资格迹,此奖励学习规则使用"慢"噪声项来驱动探索。该规则在与第4.1.1节中讨论的任务相当的目标达到任务上得到了证明,并获得了令人印象深刻的学习时间(在100秒的数量级)并适当调整噪声项。
[31]介绍了[33]中提出的基于自由能的强化学习框架的脉冲版本。在这个框架中,脉冲受限玻尔兹曼机(RBM)使用奖励调节可塑性规则进行训练,该规则降低了奖励状态-动作对的自由能。该方法在离散动作任务上进行评估,其中观察由预训练特征提取器处理的MNIST数字组成。然而,RBM的一些特性在生物学上是不可信的,并且使得它们的实现很麻烦:对称突触和时钟网络活动。使用我们的方法,网络活动不必手动同步到任意持续时间的观察和动作阶段以进行学习。
[13]引入了一种名为基于反馈的在线局部权重学习(FOLLOW)的监督突触学习规则。该规则用于学习双连杆臂的逆动力学——该模型预测给定臂轨迹的控制命令(扭矩)。[14]通过将预测扭矩作为控制命令馈送来关闭回路。相比之下,SPORE从奖励信号中学习,可以解决各种任务。
3 Method
在本节中,我们简要概述了基于奖励的学习规则SPORE。然后,我们讨论了SPORE如何体现在闭环中,以及我们为提高学习策略的鲁棒性所做的修改。
3.1 Synaptic Plasticity with Online Reinforcement Learning (SPORE)
在我们的实验中,我们使用了一种基于奖励的在线学习规则,用于脉冲神经网络,称为突触采样,在[21]中引入。学习规则采用由全局奖励信号调节的突触更新来最大化期望奖励。更准确地说,学习规则不会收敛到突触参数向量θ的局部最大值θ*,而是从目标分布中连续采样不同的解θ ~ p*(θ),该分布在可能产生高奖励的参数向量处达到峰值。温度参数 T 允许使分布p*(θ)更平坦(高探索)或更尖峰(高开发)。
SPORE ([20])是基于奖励的突触采样规则[21]的实现,它使用NEST神经模拟器([12])。SPORE针对闭环应用进行优化,形成在线策略梯度方法。我们在这里简要回顾了突触采样算法的主要特征。
我们考虑强化学习的目标,以最大化由下式给出的期望未来折扣奖励V(θ):
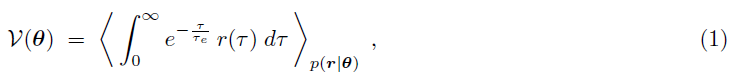
其中r(τ)表示时间 τ 上的奖励,τe是一个时间常数,用于折扣远程奖励。我们在任何时候都考虑非负奖励r(τ) ≥ 0使得对于所有θ,都有V(θ) ≥ 0。分布p(r|θ)表示在给定参数向量θ下观察到奖励序列 r 的概率。请注意,计算此期望涉及对许多实验试验和网络响应进行平均。
正如[21]中所提出的,我们用一个概率框架替换了强化学习的标准目标,以最大化公式(1)中的目标函数,该框架根据某个目标分布θ ~ p*(θ)从参数向量θ生成样本。我们将重点从以下形式的目标分布p*(θ)中采样:
![]()
其中p(θ)是网络参数的先验分布,例如,它允许我们引入对网络参数稀疏性的约束。在[21]中已经表明,如果所有突触参数 θi 都遵循随机微分方程,则实现公式(2)中的学习目标:
![]()
其中 β 是用作学习率的缩放参数,dWi 是Wiener过程的随机增量和减量,T 是温度参数。![]() 表示关于突触参数 i 的偏导数。公式(3)中的随机过程生成的样本很有可能接近目标分布p*(θ)的局部最优值。
表示关于突触参数 i 的偏导数。公式(3)中的随机过程生成的样本很有可能接近目标分布p*(θ)的局部最优值。
[21]中进一步表明,可以使用具有局部更新规则的突触模型来实现公式(3)。每个突触 i 的状态由动态变量yi(t), ei(t), gi(t), θi(t)和wi(t)组成。变量yi(t)是用突触后电位核过滤的突触前脉冲序列。ei(t)是保持前/后神经活动简短历史的资格迹。gi(t)是一个变量,用于估计奖励梯度,即公式(1)中目标函数相对于突触参数θi(t)的梯度。wi(t)表示突触 i 在时间 t 的权重。此外,每个突触都可以访问全局奖励信号r(t)。变量ei(t), gi(t)和θi(t)通过求解微分方程更新:
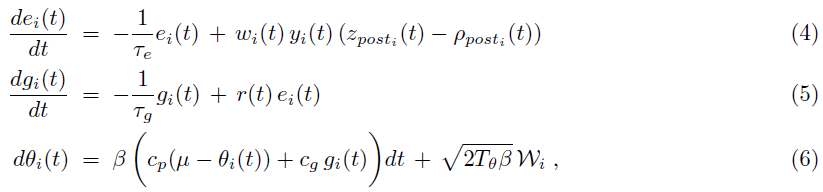
其中![]() 是放置在突触后神经元发放时间的Dirac delta脉冲的总和,μ 是突触参数(公式(2)中的p(θ))的先验均值,
是放置在突触后神经元发放时间的Dirac delta脉冲的总和,μ 是突触参数(公式(2)中的p(θ))的先验均值,![]() 是 t 时刻突触后神经元的瞬时发放率。常数 cp 和 cg 是算法的调整参数,它们根据奖励调节项的影响来调整先验分布p(θ)的影响。设置cp = 0对应于非信息性(平坦的)先验。通常,先验分布被建模为以 μ 为中心的高斯分布:
是 t 时刻突触后神经元的瞬时发放率。常数 cp 和 cg 是算法的调整参数,它们根据奖励调节项的影响来调整先验分布p(θ)的影响。设置cp = 0对应于非信息性(平坦的)先验。通常,先验分布被建模为以 μ 为中心的高斯分布:![]() 。我们在模拟中使用μ = 0。奖励梯度估计(公式(5))的方差可以通过减去[43]中介绍的奖励的基准来减少,尽管本文没有对此进行研究。
。我们在模拟中使用μ = 0。奖励梯度估计(公式(5))的方差可以通过减去[43]中介绍的奖励的基准来减少,尽管本文没有对此进行研究。
最后突触权重由投影给出:
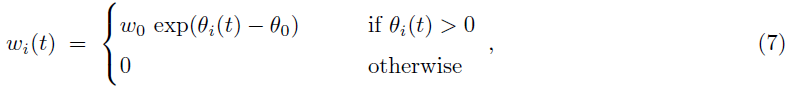
其中缩放和弥补参数分别设置为w0和θ0。
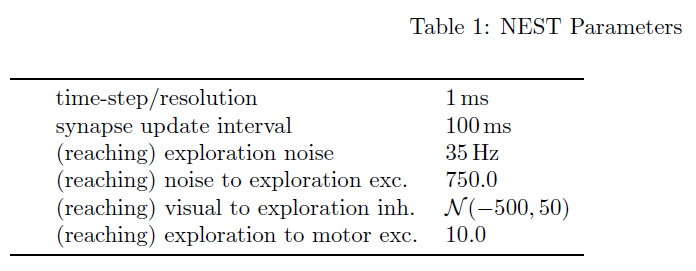
在SPORE中,微分方程公式(4)到(6)使用欧拉方法以1毫秒的时间步长求解。在每个时间步骤更新突触后项yi(t)、资格迹ei(t)和奖励梯度gi(t)的动态。为提高仿真速度,θi(t)和wi(t)的动态在步长为100 ms的较粗的时间网格上更新。突触权重在两次更新之间保持不变。突触参数被限制在θmin和θmax处。参数梯度gi(t)被裁剪为![]() 。我们评估中使用的参数列于表1至表3中。
。我们评估中使用的参数列于表1至表3中。
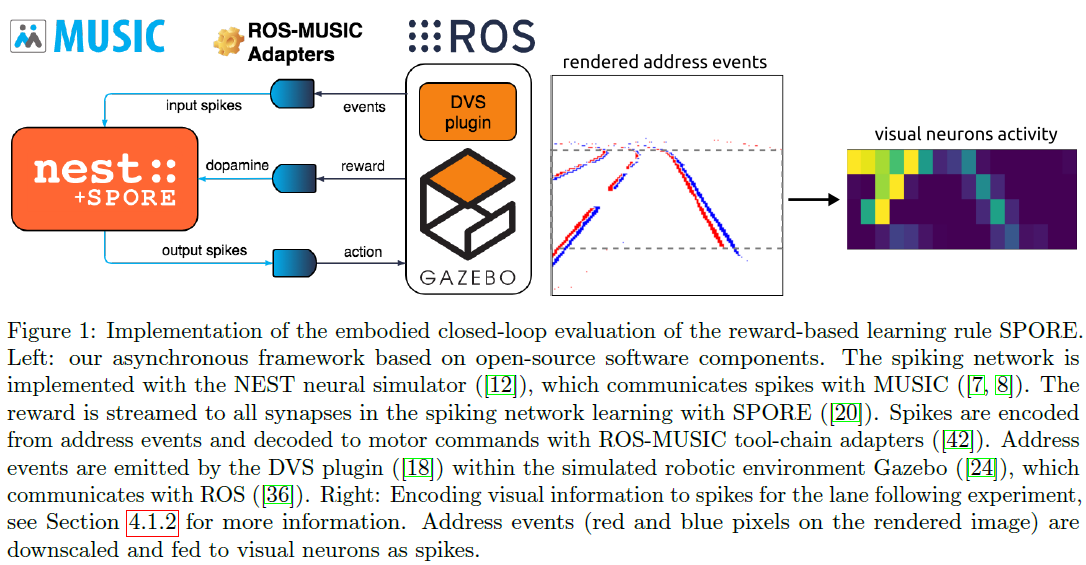
3.2 Closed-Loop Embodiment Implementation
通常,突触学习规则仅在开环模式分类任务上进行评估[46, 32, 35, 41]。实施例评估在技术上更复杂,需要闭环环境模拟。本文的一个核心贡献是实现了一个框架,该框架允许评估闭环机器人环境中生物可信可塑性模型的有效性。我们依靠这个框架来评估突触采样规则SPORE ([20]),如图1所示。这个框架是为评估一个实施例中的脉冲网络学习规则而定制的。视觉感官输入被感知,编码为脉冲信号,由网络处理,输出脉冲信号被转换为运动指令。运动命令由智能体执行,智能体会修改环境。智能体会感知环境的这种变化。此外,环境会发出持续的奖励信号。SPORE试图通过将网络正在进行的突触可塑性过程转向有望产生更多整体奖励的配置来最大化在线奖励信号。与经典的强化学习设置不同,脉冲网络被视为一个动态系统,不断接收输入和输出运动命令。这使我们能够报告关于(生物)模拟时间的学习进度,这与传统的强化学习不同,后者以迭代次数报告学习进度。类似地,我们仅在任务完成时(在到达任务中)或当智能体跑偏时(在车道跟随任务中)才重置智能体。我们不会强制执行有限时间episodes,并且智能体和SPORE都不会被通知重置。
该框架依赖于许多开源软件组件:作为神经模拟器,我们使用NEST ([12])与SPORE ([21]1)的开源实现相结合。机器人模拟由Gazebo ([24])和ROS ([36])管理,视觉感知是使用Gazebo的开源DVS插件([18]2)实现的。当像素强度的变化超过阈值时,此插件会发出极化地址事件。机器人模拟器和神经网络在不同的过程中运行。我们依靠MUSIC ([7, 8])来通信和转换脉冲,我们使用[42]的ROS-MUSIC工具链在两个通信框架之间架起桥梁。后者还将ROS时间与脉冲网络时间同步。除了MUSIC和ROS-MUSIC工具链之外,大多数这些组件也集成在神经机器人平台(NRP) [9]中。因此,NRP不支持将奖励信号流式传输到我们实验中所需的所有突触。
作为这项工作的一部分,我们将Gazebo DVS插件集成到ROS-MUSIC中,并通过将其与MUSIC集成为SPORE模块做出了贡献。这些贡献使研究人员能够使用基于事件的视觉来设计新的ROS-MUSIC实验,以评估SPORE或他们自己的生物学合理的学习规则。该框架的一个明显优势是机器人模拟可以无缝地替代真实机器人。然而,实际机器人技术中必要的人工监督,加上SPORE学习执行策略所需的大量时间,目前令人望而却步。整个框架的模拟是在具有16GB RAM的四核Intel Core i7-4790K上实时进行的。
1 https://github.com/IGITUGraz/spore-nest-module
2 https://github.com/HBPNeurorobotics/gazebo_dvs_plugin
3.3 Learning Rate Annealing
在展示SPORE ([21, 19, 22, 45])的原始工作中,学习率 β 和温度 T 在整个学习过程中保持恒定。请注意,在深度学习中,学习率通常由优化过程调节([23])。我们发现SPORE的学习率在学习中起着重要作用,并从退火机制中受益。该规则允许突触权重收敛到稳定的配置,并防止网络忘记之前的策略改进。对于本文提出的车道跟随实验,学习率随着时间的推移而降低,这也降低了温度(随机探索),见公式(3)。特别地,我们相对于时间以指数方式衰减学习率:
![]()
学习率按照这个公式每10分钟更新一次。没有研究温度项 T 的独立衰减,但是由于奖励梯度估计的高方差,我们预计对性能的影响很小,本质上会导致智能体进行探索。
4 Evaluation
我们评估了我们在两个神经机器人任务上的方法:到达任务和[18, 4]中提出的车道跟随任务。在以下部分中,我们将描述这些任务以及SPORE解决它们的能力。此外,我们根据先验分布p(θ)和学习率 β 分析了学习策略的性能和稳定性,参见公式(3)。
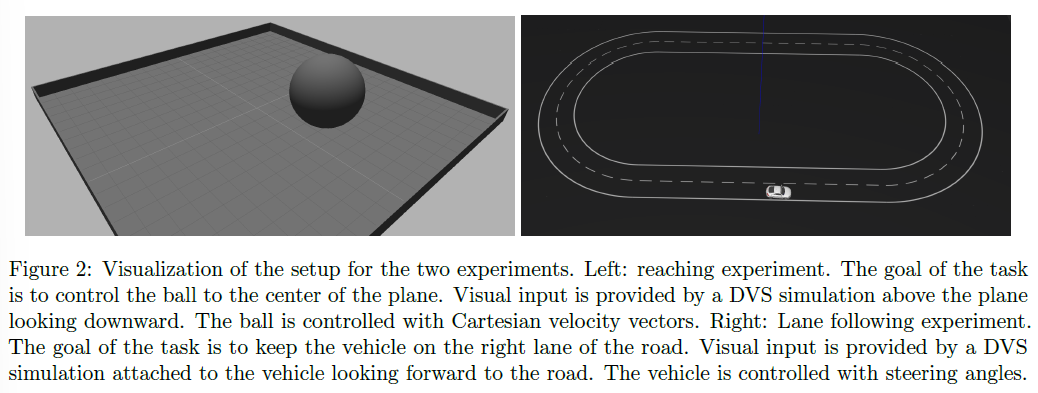
4.1 Experimental Setup
用于我们评估的任务如图2所示。在这两个任务中,使用SPORE训练一个前馈all-to-all两层脉冲神经元网络,以最大化任务特定的奖励。先前的工作表明,这种架构足以满足所考虑的任务复杂性[18, 4, 6]。该网络是端到端的,将模拟DVS的地址事件映射到电机命令。用于评估的参数如表1至3所示。在接下来的段落中,我们将描述任务及其解码方案和奖励函数。
4.1.1 Reaching Task
到达任务是[45]中评估SPORE的开环盲到达任务的自然延伸。[6]中提出了类似的视觉跟踪任务,具有不同的视觉输入编码。在我们的设置中,在智能体控制一个半径为2m的球,该球必须向由墙壁包围的20mx20m平面的2m半径中心移动。感官输入由位于中心上方的分辨率为16x16像素的模拟DVS提供,可感知球和整个平面。每个DVS像素对应一个视觉神经元——我们不区分ON和OFF事件。我们还使用每行和每列的轴特征神经元来增强输入空间。这些神经元针对它们覆盖的相应行或列神经元中的每个脉冲。16x16视觉神经元和2x16轴特征神经元都通过10个可塑SPORE突触连接到所有8个运动神经元,从而产生23040个可学习参数。网络通过Gazebo平面移动插件以瞬时速度矢量控制球。使用线性解码器从输出脉冲解码速度向量:
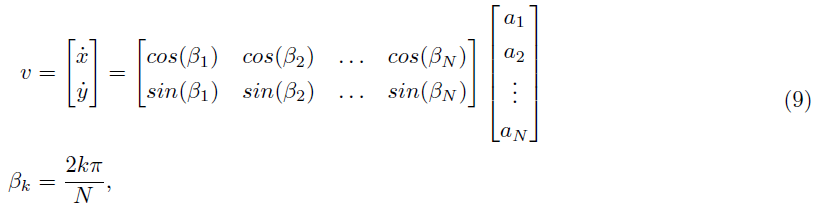
其中运动神经元 k 的活动 ak 通过在时间常数为 τ 的脉冲上应用低通滤波器获得。该解码方案包括将 N 个运动神经元均匀分布在一个圆圈上,代表它们对位移向量的贡献。对于我们的实验,我们设置N = 8个运动神经元。我们在网络中添加了一个额外的探索神经元,它会激发运动神经元并被视觉神经元抑制。这个神经元可以防止长时间的不动。事实上,当智能体决定保持静止时,它不会收到任何感官输入,因为DVS模拟只感知变化。由于网络是前馈的,没有感觉输入会导致神经活动下降,导致更多的不动。
如果球已到达中心,则球将重置到平面上的随机位置。此重置不会向网络发出信号——除了视觉输入的突然变化之外——并且不会标志着episode的结束。令 βerr 表示到目标的直线与球所走方向之间夹角的绝对值。如果球以足够的速度v > vlim向目标βerr < βlim的方向移动,则智能体将获得奖励。具体来说,奖励r(t)计算如下:

该信号在传输到智能体之前使用指数滤波器进行平滑处理。这种公式为智能体提供了持续的反馈,不像在达到目标状态时提供离散的终端奖励。在我们的实验中,离散的终端奖励并不能让智能体在合理的时间内学习执行策略。另一方面,SPORE通过资格迹支持远端奖励,如[21, 45]中针对具有明确分隔episode的开环任务所证明的那样。这表明SPORE需要额外的机制或超参数调整才能在线学习远端奖励。
4.1.2 Lane following Task
车道跟随任务已经在[18]和[4]中用于演示脉冲神经控制器。任务的目标是引导车辆保持在轨道的右侧车道上。感官输入由安装在车辆顶部的分辨率为128x32像素的模拟DVS提供,显示前方的轨迹。有16x4的视觉神经元覆盖像素,每个神经元负责一个8x8像素的窗口。每个视觉神经元以与其窗口中的事件数量相关的发放率出现脉冲,参见图1。车辆开始在轨道的右侧车道上以恒定速度行驶在固定起点上。一旦车辆离开轨道,它就会重置到起点。与到达任务一样,此重置并未明确通知网络,也不标志着学习阶段的结束。
网络通过转向来控制车辆的角度,而其线速度是恒定的。输出层被分成两个神经群体。发送给智能体的转向命令由这两个群体之间的活动差异组成。特别地,转向命令从输出脉冲解码为以下线性解码器之间的比率:

前 N/2 个神经元将转向拉向一侧,而其余的 N/2 个神经元将转向拉向另一侧。我们设置N = 8,以便有4个左侧运动神经元和4个右侧运动神经元。通过将比率 r 离散为五种可能的命令来获得转向命令:硬左(-30°)、左(-15°)、直行(0°)、右(15°)和硬右(30°)。这些转向角之间的决策边界分别为r = {10, -2.5, 2.5, 10}。这种离散化类似于[44]中使用的离散化。与直接使用 r (乘以缩放常数 k)作为连续空间转向命令相比,它产生了更好的性能,如[18]。
传递给车辆的奖励信号相当于[18]中用于评估策略的性能指标。在到达任务中,奖励取决于两项——角度误差 βerr 和距离误差 derr。角度误差 βerr 是右车道与车辆夹角的绝对值。距离误差 derr 是车辆与右侧车道中心的距离。奖励r(t)计算如下:
![]()
选择常数使得分数每0.1m距离误差或5个角度误差减半。请注意,此奖励函数包含在[0, 1]并且比[4]中使用的误差信息少。在我们的例子中,相同的奖励被传递给所有的突触,一个特定的奖励值并不表示车辆是在车道的左侧还是右侧。学习率的衰减为λ = 8.5 x 10-5,见表2。
4.2 Results
我们的结果表明,SPORE能够在一些模拟小时内为中等难度的具体任务在线学习策略。我们首先讨论到达任务的结果,我们评估了先验分布的影响。然后我们展示了车道跟随任务的结果,其中评估了学习率的影响。
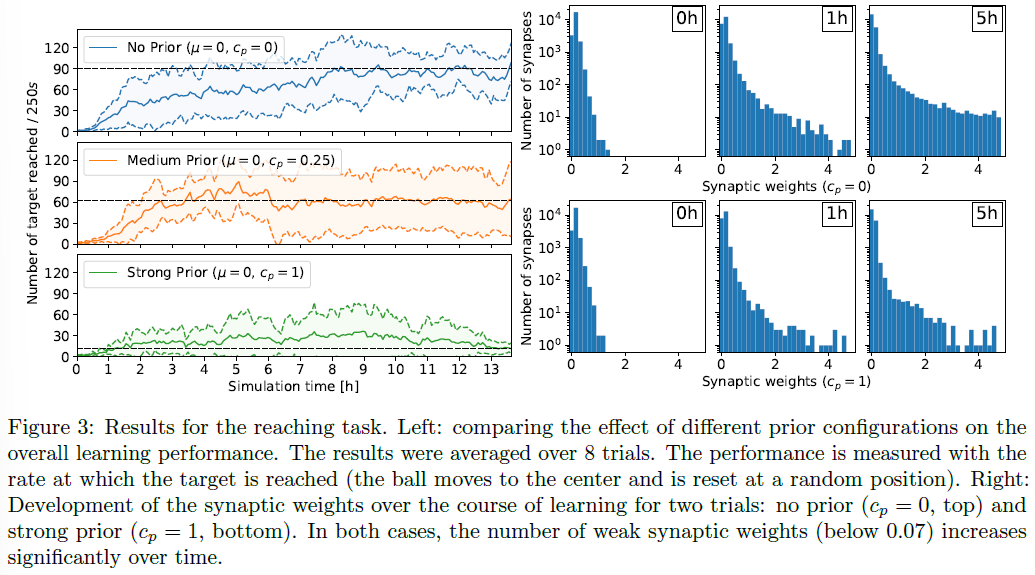
4.2.1 Impact of Prior Distribution
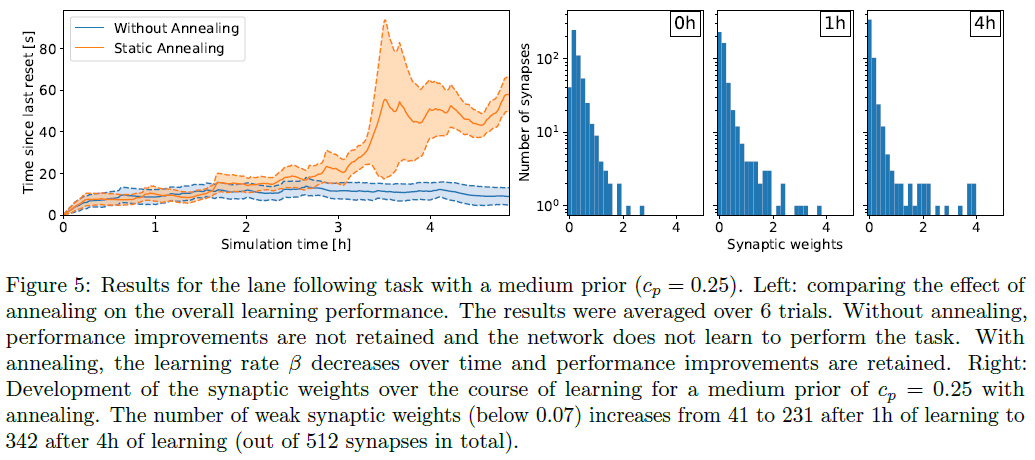
对于到达任务,平坦的先验cp = 0产生了性能最高的策略,见图3。在这种情况下,性能在模拟时间的几个小时内迅速提高,球每250秒到达中心约90次。相反,强先验(cp = 1)迫使突触权重接近0阻止了执行策略的出现。在这种情况下,经过13小时的学习,球平均每250秒只到达中心约10次,性能与随机策略相当。与无约束情况相比,较少约束的先验也会影响学习策略的性能,但允许学习发生。cp = 0.25时,球平均每250秒到达中心约60次。此外,缩回突触的数量会随着时间的推移而增加——即使在平坦的先验情况下——减少计算开销,这对于神经形态硬件实现很重要([1])。事实上,对于cp = 0,弱突触权重的数量(低于0.07)在学习1小时后从3329增加到7557,在学习5小时后增加到14753(总共23040个突触)。换句话说,所有突触中只有36%处于活动状态。cp = 0.25的权重分布类似于无先验情况cp = 0。强先验cp = 1阻止了形成强权重,权衡性能。在车道跟随任务中观察到相同的趋势,在学习4小时后,所有突触中只有33%处于活动状态,见图5。
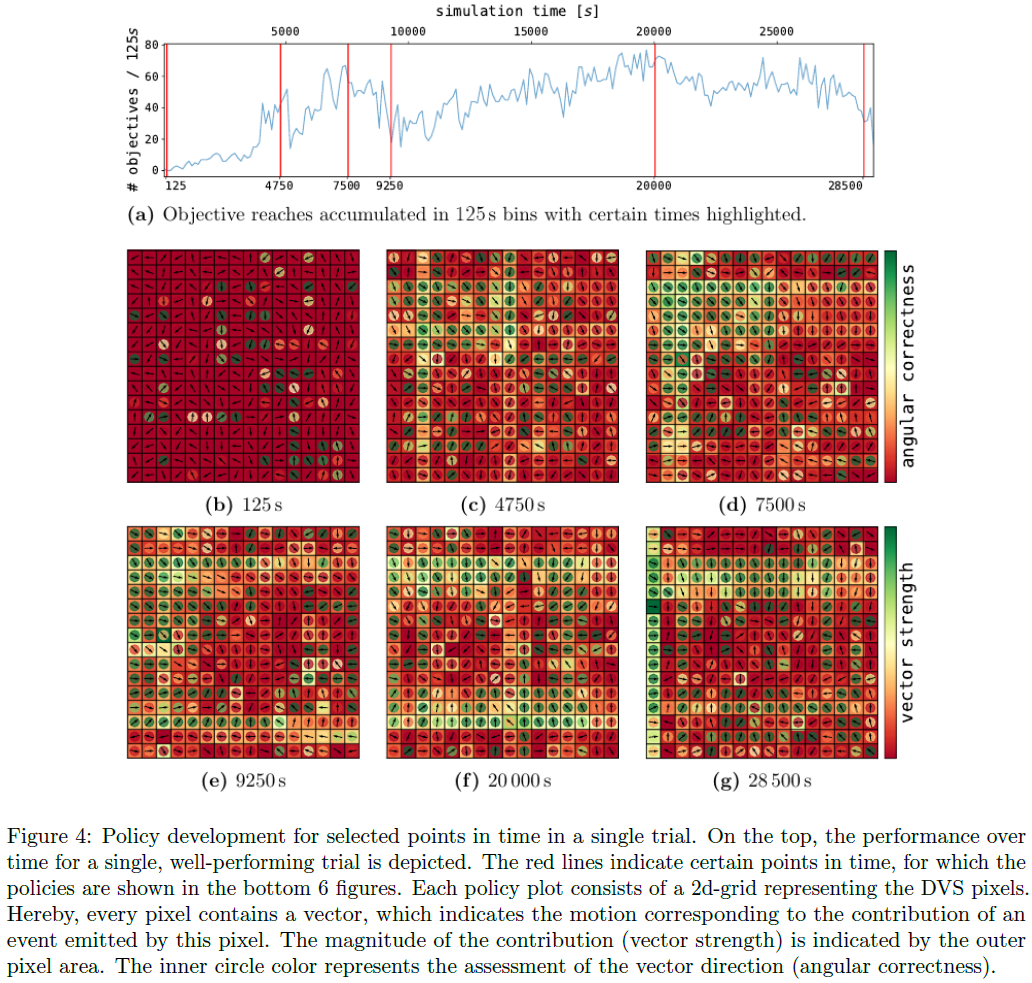
cp = 0.25的单个试验的分析如图4所示。当网络对配置进行采样时,性能不会收敛,而是会上升和下降。在初始化(b)时,该策略采用具有随机方向的弱动作。
经过超过4750s的学习(c),达到了第一个局部最大值。矢量方向在很大程度上转向了网格中心(参见内部像素颜色)。此外,从图3中的权重直方图可以看出,权重的整体幅度已大大增加。特别是,由于第4.1.1节中描述的2x16轴特征神经元,出现了单行和单列的模式。在像素的中心列中可以看到轴特征神经元的一个缺点。负责该列的轴特征神经元学会了将球向下推,因为球主要访问了网格的上部。但是,在中心位置,将球推向中心的正确方向被翻转。
在7500s (d)时,性能进一步提高。对于许多也指向正确方向的像素,如第二个峰值所示,该策略变得更加强大。 指向错误方向的像素大多具有较低的矢量强度。
9250s (e)后,性能下降到之前性能的一半。正如我们从策略中看到的那样,权重变得更加强大。出现了一些相互指向的强像素向量,这会导致小球不断上下移动,而没有得到任何奖励。
在这个谷值之后,性能再次缓慢上升,在20000s的模拟时间(f)时,策略已达到本次试验的最大性能。在整个网格周围,强运动矢量将球推向中心,球每250秒到达中心约140次。
就在试验结束之前,性能再次下降(g)。大多数向量仍然指向正确的方向,但是,整体强度已经大大下降。
4.2.2 Impact of Learning Rate
对于车道跟随实验,我们表明学习率β在保持策略改进方面起着重要作用。特别是,当学习率在整个学习过程中保持恒定时,与随机策略相比,策略并没有改善,见图5。在随机情况下,车辆在右侧车道上保持大约10秒,直到触发重置。经过大约3小时的学习,学习率下降到初始值的40%,策略开始改善。学习5小时后,学习率接近初始值的20%,性能提升得以保留。事实上,虽然权重没有被冻结,但随后突触更新的幅度会急剧减少。在这种情况下,该策略明显优于随机策略,并且车辆平均保持在右侧车道上大约60秒。
5 Conclusion
了解大脑的努力跨越了多个研究领域。允许在闭环实现中评估由理论神经科学家得出的突触学习规则的合作是这一努力的一个重要里程碑。在本文中,我们通过依赖用于脉冲网络模拟[12, 20]、同步和通信[7, 8, 42, 36]和机器人模拟[24, 18]的开源软件组件,成功实现了允许进行这种评估的框架。由此产生的框架能够以模块化方式通过脉冲网络在线学习模拟和真实机器人的控制。该框架用于评估两个闭环视觉运动任务上的奖励学习规则SPORE ([21, 19, 22, 45])。总体而言,我们已经证明SPORE能够在一些模拟小时内在线学习针对中等难度的具体任务的浅层前馈策略。这种评估使我们能够表征先验分布对学习策略的影响。特别是,约束先验会降低学习策略的性能,但会阻止出现强大的突触权重,见图3。此外,对于车道跟随实验,我们展示了学习率调节如何使策略改进得以保留。受模拟退火的启发,我们提出了一种随时间降低学习率的简单方法。这种方法没有模拟特定的生物机制,但在实践中似乎效果更好。另一方面,已知新颖性通过多种机制调节可塑性([37, 15])。因此,熟悉任务后降低学习率是合理的。
在功能范围内,深度学习方法仍然优于生物学合理的学习规则,例如SPORE。对于未来的工作,应该通过从深度学习方法中汲取灵感来解决SPORE和深度学习方法之间的性能差距。特别是,SPORE固有的在线学习方法受到策略评估的高方差的影响。通过引入受过训练来估计给定状态的期望回报的critic,这个问题在策略梯度方法中得到了缓解。该期望回报被用作减少策略评估方差的基准。通过考虑[6]中的动作空间噪声,而不是公式(3)中的Wiener过程实现的参数空间噪声,也可以减少方差。最后,调节学习率的自动机制对于更复杂的任务是有益的。这种机制可能受到信任区域方法([38])的启发,它限制权重更新以一点一点地改变策略。这些改进应该会提高SPORE的性能,以便可以考虑更复杂的任务,例如多关节效应器控制和离散终端奖励——由所提出的框架设计支持。
Data Availability Statement
本研究未生成数据集。