参考链接:
参考文献:
- Sandy H. Huang, Nicolas Papernot, Ian J. Goodfellow, Yan Duan, and Pieter Abbeel. Adversarial attacks on neural network policies. arXiv:1702.02284v1 [cs.LG], 2017.
- Jernej Kos and Dawn Song. Delving into adversarial attacks on deep policies. arXiv:1705.06452v1 [stat.ML], 2017.
1、Adversarial Attacks on Neural Network Policies (2017 ICLR)
Fast Gradient Sign Method (FGSM):FGSM专注于对抗性扰动,其中输入图像的每个像素的变化不超过ε。给定具有参数θ和损失J(θ, x, y)的图像分类网络,其中 x 是图像,y 是所有可能的类别标签的分布,围绕输入 x 线性化损失函数会导出:
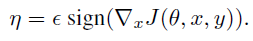
在工作中,作者使用FGSM作为白盒攻击来计算训练好的神经网络策略的对抗性扰动,对手可以使用其架构和参数,并作为黑盒攻击通过计算单独训练的策略![]() 的梯度,使用对抗性示例可转移性进行攻击。
的梯度,使用对抗性示例可转移性进行攻击。
FGSM需要计算![]() ,即代价函数J(θ, x, y)相对于输入 x 的梯度。在强化学习设置中,作者假设输出 y 是对可能动作的加权值(即,策略是随机的:
,即代价函数J(θ, x, y)相对于输入 x 的梯度。在强化学习设置中,作者假设输出 y 是对可能动作的加权值(即,策略是随机的:![]() )。当使用FGSM计算训练策略的对抗性扰动时,我们假设 y 中权重最大的动作是要采取的最优动作:换句话说,作者假设策略在任务中表现良好。因此,J(θ, x, y)是 y 和分布之间的交叉熵损失,该分布将所有权重放在 y 中权重最高的动作上(在功能上,这相当于在图像分类上下文中引入的一种技术,无需访问真正的类标签即可生成对抗性示例)。
)。当使用FGSM计算训练策略的对抗性扰动时,我们假设 y 中权重最大的动作是要采取的最优动作:换句话说,作者假设策略在任务中表现良好。因此,J(θ, x, y)是 y 和分布之间的交叉熵损失,该分布将所有权重放在 y 中权重最高的动作上(在功能上,这相当于在图像分类上下文中引入的一种技术,无需访问真正的类标签即可生成对抗性示例)。
在作者考虑的三种学习算法中,TRPO和A3C都训练随机策略。然而,DQN产生了一个确定性的策略,因为它总是选择最大化计算出的Q值的动作。这是有问题的,因为它导致几乎所有输入 x 的梯度![]() 为零。因此,当为使用DQN训练的策略计算J(θ, x, y)时,我们将 y 定义为计算出的Q值的softmax(温度为1)。请注意,作者这样做只是为了创建对抗性示例;在测试执行期间,使用DQN训练的策略仍然是确定性的。
为零。因此,当为使用DQN训练的策略计算J(θ, x, y)时,我们将 y 定义为计算出的Q值的softmax(温度为1)。请注意,作者这样做只是为了创建对抗性示例;在测试执行期间,使用DQN训练的策略仍然是确定性的。
令 η 为对抗性扰动。在某些情况下,可能希望将所有输入特征更改不超过一小部分(即约束 η 的l∞-范数),或者仅更改少量输入特征可能更好(即约束 η 的l1-范数)。因此,我们考虑约束 η 的l1-和l2-范数的FGSM的变体,以及约束 η 的l∞-范数的FGSM的原始版本(第3.1节)。
围绕当前输入 x 线性化成本函数J(θ, x, y),每种范数约束的最优扰动是:

其中 d 是输入 x 的维数。
请注意,l2-范数和l1-范数约束已分别将 ε 调整为向量的l2-范数和l1-范数ε1d,因为这是l∞-范数约束下的扰动量。此外,l1-范数约束的最佳扰动要么最大化或最小化输入维度 i 处的特征值,按![]() 递减排序。对于这个范数,对手的预算——允许对手在输入中引入的扰动总量——是εd。
递减排序。对于这个范数,对手的预算——允许对手在输入中引入的扰动总量——是εd。
2、Delving into Adversarial Attacks on Deep Policies (2017 ICLR)
研究目标:
- Attack Effectiveness of Adversarial Examples vs. Random Noise:我们研究如何将随机噪声注入环境与注入FGSM对抗性扰动进行比较。
- Using the Value Function to Guide Adversarial Perturbation Injection:我们想看看降低对抗性扰动注入的频率是否仍然可以产生有效的攻击。我们研究了三种不同的方法:a)我们只每 N 帧注入一个对抗性扰动,中间帧没有任何扰动,b)我们只每 N 帧重新计算一个对抗性扰动,并在中间帧中注入最后计算出的扰动;c) 我们使用在原始输入上计算的价值函数,以估计何时注入对抗性扰动使其最有效,并且仅当此估计值高于某个阈值时才注入对抗性扰动。
- Effectiveness of Re-training with Adversarial Examples and Random Noise:我们研究是否可以在注入随机噪声或对抗性扰动的环境中重新训练智能体,以使其对进一步的对抗性扰动更具弹性。此外,我们研究了这种获得的弹性是否转移到具有不同幅度和不同类型扰动的环境中(例如,对随机噪声进行训练的智能体是否对FGSM对抗性扰动更具弹性)。
在我们所有的实验中,智能体首先在基准(非带噪)环境中进行训练,直到它在多个回合(基准智能体)中获得最优奖励。然后,为了生成FGSM扰动,我们设置适当的 ε 并计算![]() 。为了生成随机噪声,我们从均匀分布Unif(0, β)中采样,我们根据所需强度对 β 进行设置。
。为了生成随机噪声,我们从均匀分布Unif(0, β)中采样,我们根据所需强度对 β 进行设置。
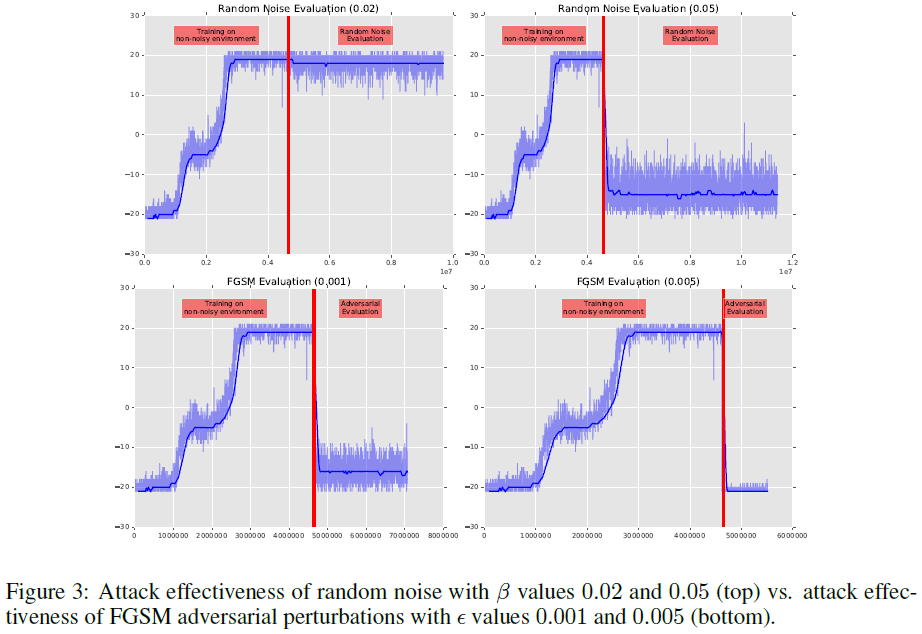
Attack Effectiveness of Adversarial Examples vs. Random Noise:基准智能体在环境的修改版本上进行评估,其中在每一帧上注入随机噪声或FGSM扰动。附录中的图3显示了随机噪声和FGSM扰动之间的攻击有效性差异。虽然低水平的随机噪声(β ≤ 0.02)不会对智能体的性能产生太大影响,但使用更大规模的随机噪声(β ≥ 0.02)会严重降低性能。对于成功的攻击,FGSM对抗性扰动比随机噪声有效几个数量级,成功地以低得多的扰动水平攻击基准智能体。
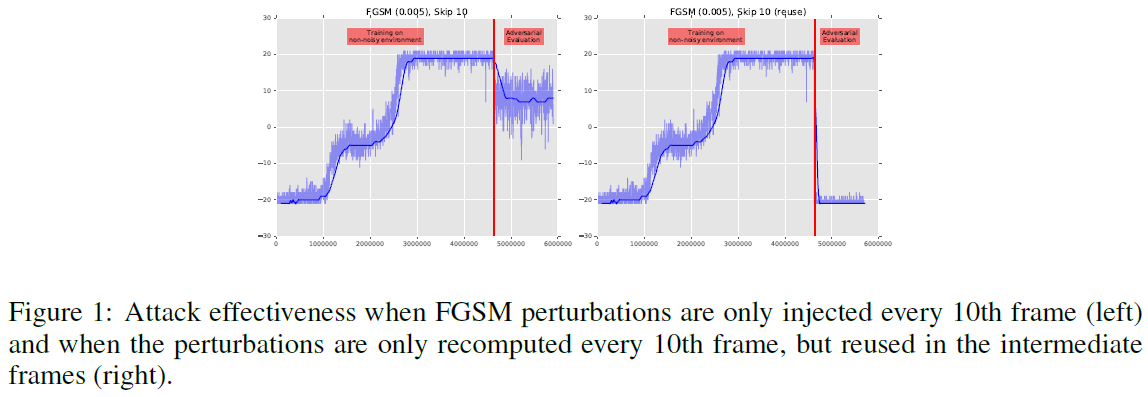
Using the Value Function to Guide Adversarial Perturbation Injection:首先,我们探索注入对抗性扰动的频率如何影响攻击成功。在这个实验中,我们要么每十帧只注入FGSM扰动并在中间使用原始帧,要么每十帧重新计算扰动并在中间使用最后计算的扰动。所有实验均设置 ε 为0.001。我们的结果表明,仅在每十帧注入FGSM扰动似乎并不是特别有效的攻击(图1, 左)。另一方面,每十帧重新计算扰动并在中间帧中重用之前的扰动与原始攻击同样有效(图1, 右)。
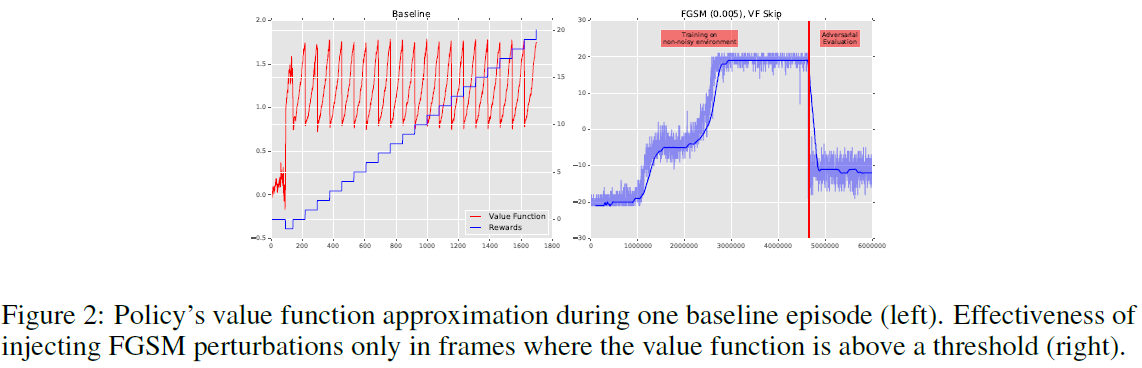
我们还开发了一种攻击方法(VF),只有当在原始帧上计算的价值函数高于某个阈值(在本实验中,我们将阈值设置为1.4)时,我们才会注入对抗性扰动。这背后的原因是我们只想在接近获得奖励的关键时刻扰乱智能体。图2显示了该方法的有效性,表明VF攻击方法非常有效,同时仅在一小部分帧中注入了对抗性扰动。我们可以将VF方法与每十帧盲目注入扰动进行比较(图1, 左)。尽管两种方法在一个回合中平均注入的扰动次数相似(VF方法为120次,盲目法为125次),但VF方法显示出更有效。这表明攻击者可以使用价值函数进行比在每一帧中注入对抗性扰动的传统攻击方法更有效的攻击(如(Huang et al., 2017))。这也表明,在强化学习设置中,对抗性攻击可能比以前研究的其他设置(例如图像分类)复杂得多。
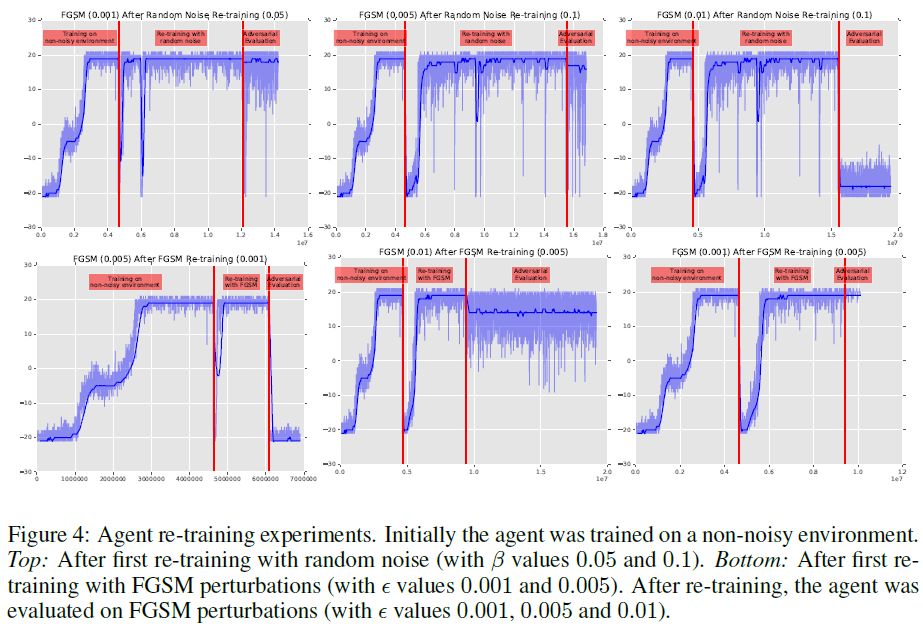
Effectiveness of Re-training with Adversarial Examples and Random Noise:最后,我们还探讨了是否可以重新训练智能体以提高对随机噪声和FGSM对抗性扰动的弹性。我们还探讨了这种弹性是否会转移到不同程度和类型的扰动。在这些实验中,在无噪声环境中进行初始训练后,首先允许智能体重新训练,同时我们在每帧上注入随机噪声或FGSM扰动。在智能体获得良好性能后,它会被冻结并在新的带噪环境中进行评估,无论是随机噪声还是FGSM扰动。
附录中的图4显示,在此设置中,基准智能体可以在带噪的环境中重新训练多次后对一定水平的FGSM扰动具有弹性,并在重新训练期间添加足够水平的随机噪声或FGSM扰动。更有趣的是,我们的实验表明,与重新训练期间使用的FGSM扰动的幅度相比,重新训练的智能体还可以抵御比FGSM扰动的幅度更大(或更小)的FGSM扰动。我们还在图像空间中可视化策略预测的动作(见图5)。