郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IEEE transactions on neural networks and learning systems, 2021
Abstract
脉冲神经网络(SNN)包含比标准人工神经网络(ANN)中更多的生物现实结构和生物启发的学习原理。SNN被认为是第三代ANN,强大的鲁棒计算能力和低计算成本。SNN中的神经元是非微分的,包含衰减的历史状态并在其状态达到发放阈值后生成基于事件的脉冲。SNN的这些动态特性使其难以直接使用标准反向传播(BP)进行训练,这在生物学上也被认为是不合理的。在本文中,提出了一种生物学上合理的奖励传播(BRP)算法,并将其应用于具有脉冲卷积(具有一维和二维卷积核)和全连接层的SNN架构。与标准BP将误差信号从突触后逐层传播到突触前神经元不同,BRP将目标标签而不是误差直接从输出层传播到所有预隐藏层。这种努力与新皮层柱中自上而下的奖励引导学习更加一致。仅具有局部梯度差异的突触修改是由伪BP诱导的,伪BP也可能被脉冲时序依赖可塑性(STDP)取代。所提出的BRP-SNN的性能在空间(包括MNIST和Cifar-10)和时间(包括TIDigits和DvsGesture)任务上得到了进一步验证,其中使用BRP的SNN与其他最先进的基于BP的SNN到达了相似的精度,并比ANN节省了50%以上的计算成本。我们认为,将生物学上合理的学习规则引入到生物学真实SNN的训练过程中,将为我们更好地理解生物系统的智能本质提供更多提示和灵感。
Index Terms—Spiking Neural Network, Biologically-plausible Computing, Reward Propagation, Neuronal Dynamics.
I. INTRODUCTION
深度学习(或深度神经网络, DNN)的快速发展通过简单高效的端到端网络学习打破了许多研究障碍,实现了统一解决方案。DNN在某些特定任务中已经取代了许多传统的机器学习方法,并且这些任务的数量还在不断增加[1]。然而,在DNN的快速扩张过程中,许多重要且具有挑战性的问题也相应暴露出来,例如对抗性网络攻击[2][3]、灾难性遗忘[4]、数据饥渴[5]、缺乏因果推理[6]和低透明度[7]。一些研究人员试图通过DNN本身的内部研究来寻找答案,比如构建特定的网络结构,设计更强大的成本函数,或者构建更精细的可视化工具来打开DNN的黑匣子。这些努力是有效的,并为DNN的进一步发展做出了贡献[8]。在本文中,我们认为有一些替代和更简单的方法可以实现这些目标,尤其是在稳健和高效的计算方面,通过转化为生物神经网络并从中获得灵感[9]-[17]。
脉冲神经网络(SNN)被认为是第三代人工神经网络(ANN)[18]。SNN中神经元之间传递的基本信息单元是离散脉冲,包含膜电位状态达到发放阈值的精确时间。这种事件类型的信号包含内部神经元动力学和历史上积累(和衰减)的膜电位。SNN中的脉冲训练,与ANN中的对应物相比,发放率(这里我们将发放率定义为描述传播信息的模拟值),为更好地表示处理序列信息开辟了新的时间坐标。除了神经元动力学,生物学特征学习原理是SNN的其他关键特征,描述了局部和全局可塑性原理对突触权重的修改。对于局部原则,它们中的大多数是"无监督的",包括但不限于脉冲时序依赖可塑性(STDP)[19][20]、短期可塑性(STP)[21]、长期 增强(LTP)[22][23]、长期抑制(LTD)[24]和横向抑制[25][26]。对于全局原则,它们更受"监督",数量比局部原则少,但与网络功能更相关,例如可塑性传播[27]、奖励传播[28]、反馈对齐[29]和目标传播[30]。
SNN不同于结构和功能,例如回声状态机[31]、液态状态机[32]、具有生物神经元的前馈架构[12][33],以及一些与任务相关的结构[34]-[36]。SNN的一些调整方法是基于BP的(例如,ReSuMe[37]、SpikeProp[38]和先用BP训练然后转换为SNN[39]的ANN)或与BP相关的(通过时间的BP[40][41]、SuperSpike[42]和STDP型BP[43])。仍然有一些努力用生物学上合理的可塑性原则训练SNN(例如,基于STDP或STP的学习[19][21][44]-[48]、平衡学习[49]-[51]、多规则整合学习[52]-[54]和基于好奇心的学习[55])。
本文更侧重于使用生物学上合理的学习原理训练SNN,而不是直接使用BP对其进行调整,以更接近于首先了解大脑,然后实现人类级别的人工智能。因此,具有脉冲卷积层(包含1D和2D脉冲卷积核)和全连接层(包含神经元动力学)的SNN是用所提出的生物学合理奖励传播(BRP)构建和调整的(命名为BRP-SNN)。BRP-SNN专注于描述膜电位的神经元级动态计算和全局突触的网络级重连接。与通常更关注局部可塑性原则(例如STDP和STP)或混合局部和全局原则的其他调整方法不同,我们使用全局BRP只是为了简单和清晰。在全局奖励传播之后,只用局部梯度差异进一步诱导突触改进,也可以用STDP和微分Hebb原理代替。
本文的主要贡献包括:
- 我们构建了一个包含LIF神经元的多层SNN架构和一个具有高效脉冲卷积和脉冲池化层的网络。
-
我们提出了一种新的生物学合理奖励传播(BRP),用于有效学习SNN。与其他基于BP的调整算法不同,BRP仅使用来自输出层的标签而不是逐层误差反向传播来全局调整隐藏神经元。这种新方法达到相同性能的计算成本要低得多。此外,奖励信息比生物系统中其他基于误差的信号在生物学上更合理。我们认为这是通过使用生物学上合理的可塑性原理调整生物学上真实的SNN来实现生物学上有效学习的另一种努力。
-
我们使用空间(包括MNIST和Cifar-10)和时间(包括TIDigits和DvsGesture)数据集来测试所提出的算法在SNN上的性能。BRP-SNN实现了高性能(在测试集上的准确率,MNIST为99.01%,Cifar-10为57.08%,TIDigits为94.86%,DvsGesture为80.90%),与其他最先进的(SOTA)SNN相比,其使用纯生物学上合理的原则进行调整。此外,BRP-SNN还显示出较低的计算成本(节省超过50%的神经元计算)。
在本文的其余部分安排如下。第二节简要介绍了生物神经元和网络中的信息处理。第三节描述了具有脉冲卷积和脉冲池化层的多层SNN,然后通过三种类型的目标传播方法(包括BRP)进行调整。第IV节介绍了BRP-SNN与使用生物学合理(或基于BP)学习方法调整的其他SOTA算法相比具有可比的收敛性、更低的计算成本和更好(或兼容)的性能。最后,在第五节中给出了一些结论。
II. BACKGROUND OF BIOLOGICALLY-PLAUSIBLE INFORMATION PROCESSING
A. Dynamic spiking neurons
SNN中的动态神经元与DNN中的对应激活函数非常不同。神经元在不同层次的SNN中相互通信,在DNN中具有离散的基于事件的脉冲,但不具有连续的发放率。DNN还包含各种"神经元"(激活函数),如整流线性单元(ReLU)、Sigmoid函数和Tanh函数。然而,它们只描述了神经元输入和输出信号之间的空间非线性映射,而不是将它们与神经元动力学暂时联系起来。
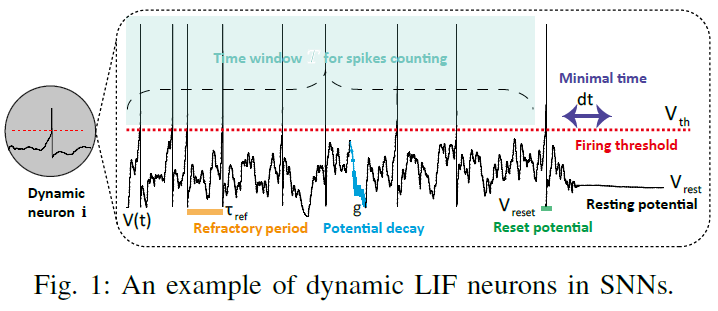
SNN中的基本计算单元是不同类型的动态神经元[33],例如,Hodgkin-Huxley (HH)神经元、Leaky Integrated-and-Fire (LIF)神经元、Izhikevich神经元和脉冲响应神经元(SRM)。LIF神经元描述了膜电位的动力学(如图1所示)。根据以下公式,典型的LIF神经元在远程时域中动态更新其膜电位Vi(t):

其中τref是不应期,g是突触电导率,Vreset是Vi(t)达到发放阈值Vth后的重置值。静息膜电位Vrest被设置为Vi(t)的吸引子,尤其是在没有给出刺激输入时。C是膜电容。dt是Vi(t)更新的最小时间步长(通常设置为0.1-1 ms)。j 是突触前神经元的神经元指数。i 是当前神经元指数。N是当前层的神经元数量。Wi, j是突触前神经元 j 和当前神经元 i 之间的突触权重。tspike是神经元 i 的特定脉冲时间。Xj(t)是来自突触前神经元 j 的神经元输入。所有这些神经元动力学都将在时间窗口T内进行。
B. The biological plausibility of the BRP
生物网络中的计算是异步的,显然包含不同时间尺度的多个时钟,从突触、神经元到网络[56][57]。生物大脑通过包含空间和时间信号的基于事件的脉冲来处理这种多尺度信息处理挑战。这些复杂的脉冲动态也使得传统的基于BP的算法在网络学习上变得困难。
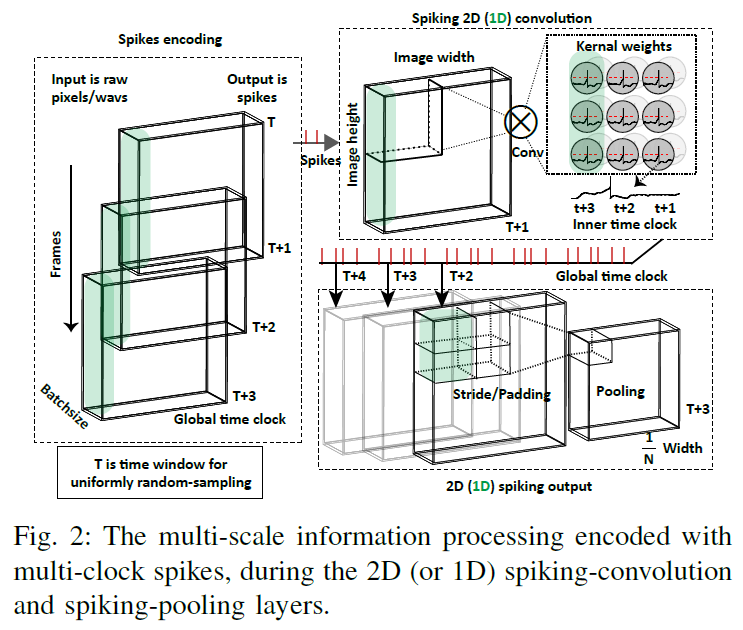
图2显示了卷积层和池化层的脉冲信息处理示例,其中集成了多时钟脉冲(包括局部时钟内部神经元和层之间的全局时钟)用于一般复杂的信息编码。
生物系统会将基底神经节中的神经元中的多巴胺直接释放到其他大脑回路(例如,通过丘脑改道)以改变突触状态。这个过程激发了我们提出的BRP算法,它是有效的并且不同于ANN中的BP[47]。
III. METHOD
这里我们在标准的LIF神经元中添加了一个Spike标志,以减缓Vi(t)的更新速度,而不是在不应期期间绝对阻塞它,如下所示:
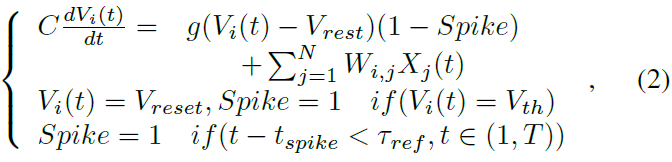
其中Vi(t)是其历史膜电位Vi(t-k) (k ∈ 1, 2, 3, .. )与衰减gk及其当前输入刺激Xj(t)的积分。g (即电导率)是Vi(t)的衰减因子,它通常被设计为一个值小于1 nS (纳秒)的超参数。如果Vi(t)达到发放阈值Vth,则会产生脉冲,同时,Vi(t)也将重置为预定义的膜电位Vreset。此外,给出了不应期的参数τref,在此期间Vi(t)的更新速度要低得多。Vrest也可以被认为是Vi(t)的一个吸引子,特别是当没有输入Xi(t)并且没有产生Spike时,膜电位Vi(t)将动态衰减为Vrest。用于计算神经元动力学的内部迭代时间窗口T在10到100毫秒的范围内。
A. Spiking-convolution layer with 1D and 2D kernels
一维和二维卷积已被证明分别在时间和空间信息处理上是有效的。卷积核的可重用性(即突触权重的共享)也在一定程度上有助于网络学习对SNN的抗过拟合特性。
如图2所示,每一层的信号都表示为脉冲序列。为简单起见,用于膜电位更新的LIF神经元内部的时钟 t 设计为与用于从前层到后层的信号传播的外部神经元时钟 T 相同。这种配置意味着为了便于计算,神经元内外信息传播的时间范围都是T。卷积层2D(或1D)脉冲输入具有高度和宽度维度(或仅具有高度维度的1D输入,即图2中的绿色条),然后使用2D(或1D)核进行卷积。核中的这些神经元被设计为包含脉冲的动态神经元,这些脉冲编码具有学习时间 t (直到T)的基于事件的信号。然后卷积后的脉冲进一步池化以降低维度。
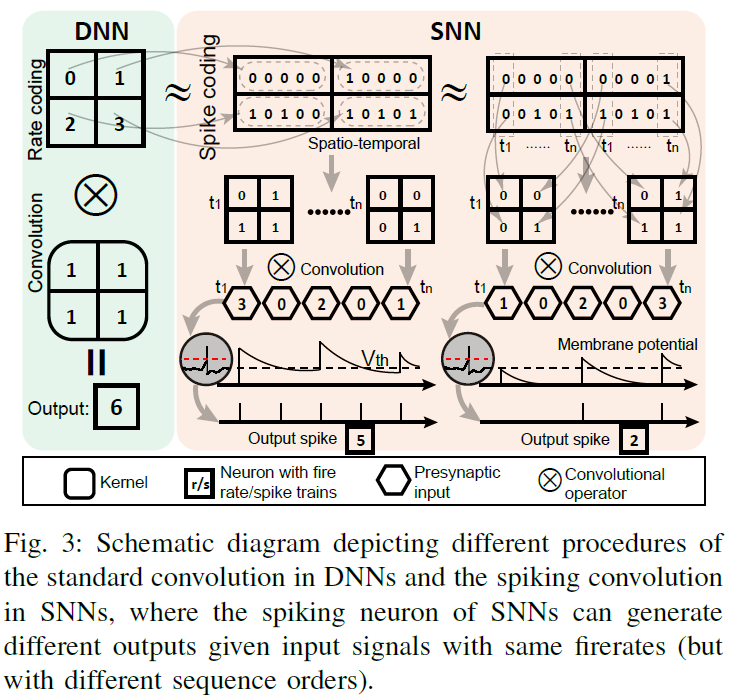
SNN中的卷积处理不同于传统DNN中的卷积处理。为了更清楚地描述它们的差异,图3描述并显示了两种类型的卷积的示意图。在SNN中,膜电位的衰减会使LIF神经元更难发放。相反,膜电位的历史正整合将使LIF神经元产生相对更多的输出脉冲。LIF神经元中的这两个动态部分将有助于在微尺度神经元级别对SNN进行时间信息处理。相反,人工神经网络通过忽略输入信号的顺序差异来产生与输出相同的发放率。LIF神经元的这种与序列相关的动态将有助于SNN中的时间信息表征和学习。
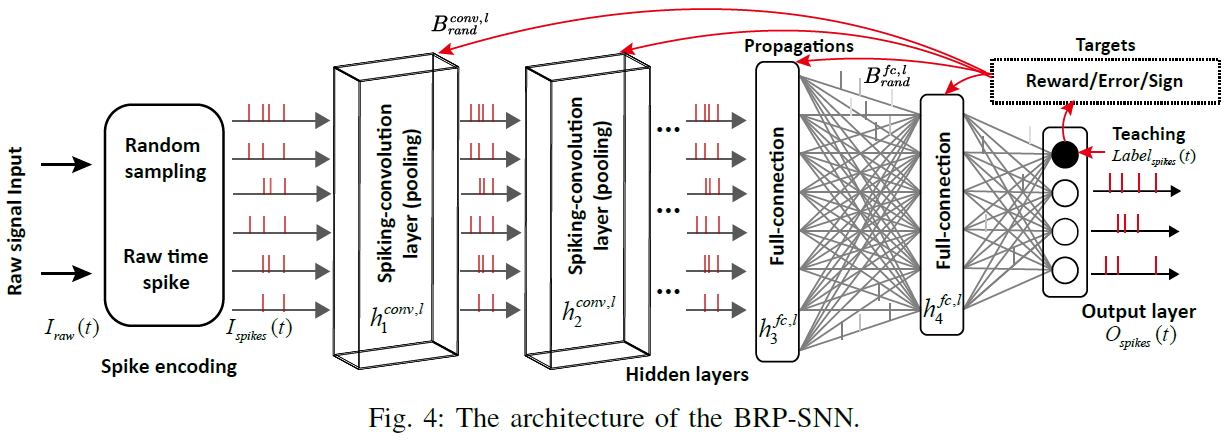
B. The BRP-SNN architecture
整个BRP-SNN架构如图4所示,其中输入脉冲序列是从原始信号输入生成和编码的,原始信号输入可以是一维听觉信号或二维图像信号。对于没有脉冲的一维和二维信号(例如,TIDigits和Cifar-10),原始输入信号Iraw(t)首先随机采样为顺序脉冲序列Ispikes(t),然后传播到以下卷积、池化和全连接层。对于具有自然脉冲的信号,例如3D动态视觉传感器(DVS)视频信号(例如DvsGesture),原始信号已经很好地编码为0或1事件类型符号,可以直接将其视为脉冲。因此不再需要额外的脉冲编码。脉冲生成器如下图所示:
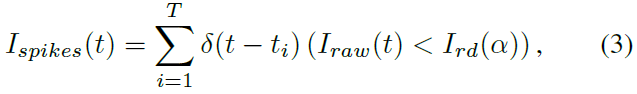
其中Ird是具有衰减因子α的0-1随机变量生成器,并且Ird(α) = Ird * α。T为全局网络时钟,与LIF神经元的内部时钟相同。
脉冲卷积和池化层用于空间特征检测,前馈全连接层用于下一步分类。在整个时间窗口 T 之后,SNN中不同隐藏层的脉冲训练可以首先汇总为发放率,然后结合传播的标签奖励信号来修改局部突触权重。
C. Tuning SNNs with the global BRP
为了SNN的收敛学习,前馈和反馈传播通常交织在一起。反馈传播也被描述为网络结构(例如,突触权重)的自上而下的细化,直接从误差到突触进行修改(例如,修订或伪BP)[10][58]。然而,这些BP的逐层误差反向传播在生物学上被认为是不合理的。
在生物系统中,信号可以在内部神经元内或仅在邻域层内反向传播[10][59]-[62]。长程传播描述了从大脑区域中的神经元直接向用于初级认知功能的目标神经元的高级认知功能的奖励传播[10]。直接随机目标传播算法[30]的想法符合这些生物学约束。因此,我们选择它作为BRP-SNN的底层骨骼架构,并通过神经元动力学、脉冲卷积和奖励传播进一步完善它。
生物学上合理的奖励传播BRP是根据以下条件构建的:
![]()
描述一个脉冲序列来表示目标标签(即T期间的一次性Labelspikes(t))作为直接传播到所有预隐藏层的奖励。TP是"Target Propagation"的简称,意思是将输出层的目标目标直接赋予前面的所有层。与TPBRP不同,还构造了另一个候选TPerr,如下所示:
![]()
其中TPerr描述了输出信号和教学信号之差。![]() 是教学信号(例如标签)的平均发放率。y(t)是来自SNN的输出脉冲序列(Ospikes(t))的平均总和,如下所示:
是教学信号(例如标签)的平均发放率。y(t)是来自SNN的输出脉冲序列(Ospikes(t))的平均总和,如下所示:

其中时间窗口 T 中的脉冲仅在 T 结束时被加在一起作为发放率y(t)。TPsign是第三种类型的TP,它描述了正负误差的符号,如下所示:
![]()
其中不需要详细的误差信号,只使用误差的符号进行传播。这种努力仅将正("+")和负("-")信号传播到隐藏层。但是,这个符号的计算包含的前提是必须首先计算详细的误差,然后将其量化为误差的符号。因此,它仍然需要y(t)和![]() ,与TPerr相同,而不是仅与网络的函数目标(其中y(t)不是必需的)相关的纯奖励定义,例如TPBRP。这个想法并不新鲜,之前的一些工作已经描述了符号而不是误差传播到网络。NormAD [63]是其中的一个很好的例子,它可以被视为一种有效的符号传播学习规则,尤其是在浅层SNN中。
,与TPerr相同,而不是仅与网络的函数目标(其中y(t)不是必需的)相关的纯奖励定义,例如TPBRP。这个想法并不新鲜,之前的一些工作已经描述了符号而不是误差传播到网络。NormAD [63]是其中的一个很好的例子,它可以被视为一种有效的符号传播学习规则,尤其是在浅层SNN中。
不同类型的TP将直接传播到所有隐藏层,包括脉冲卷积层和全连接层。额外的Brand将在网络初始化时作为随机生成的矩阵给出,它将在从输出层到所有隐藏层的不同维矩阵转换中发挥作用。请注意,全局传播只能传播信号并影响神经元状态(例如,膜电位)而不是突触权重。因此,对所学知识的突触修改将在局部突触权重巩固的下一步过程中进一步处理。
D. The local synaptic weight consolidation
BRP将在每个时间 t 直接传播回SNN的不同隐藏层。这种努力将影响当前的网络状态,同时在t+1时刻为SNN提供下一步学习所需的目标状态。SNN中的突触权重可以根据局部传播的神经状态![]() 与当前神经状态
与当前神经状态![]() 的差异进行更新。脉冲卷积层中突触权重的修改
的差异进行更新。脉冲卷积层中突触权重的修改![]() 更新如下:
更新如下:
![]()
其中![]() 是网络学习前为隐藏层 l 随机生成的矩阵,不会进一步更新。
是网络学习前为隐藏层 l 随机生成的矩阵,不会进一步更新。![]() 是卷积层 l 中从突触前神经元 j 到突触后神经元 i 的突触权重的修改。ηconv是学习率。hconv, l(t)是当前层 l 中的神经元状态(与膜电位V相同)。同理,全连接层对
是卷积层 l 中从突触前神经元 j 到突触后神经元 i 的突触权重的修改。ηconv是学习率。hconv, l(t)是当前层 l 中的神经元状态(与膜电位V相同)。同理,全连接层对![]() 的修改更新如下:
的修改更新如下:
![]()
其中![]() 也是网络学习前为隐藏层 l 随机生成的矩阵,在学习过程中不会进一步更新。
也是网络学习前为隐藏层 l 随机生成的矩阵,在学习过程中不会进一步更新。![]() 是全连接层 l 中从突触前神经元 j 到突触后神经元 i 的突触权重。ηfc是学习率,hfc, l(t)是当前层 l 的膜电位状态。
是全连接层 l 中从突触前神经元 j 到突触后神经元 i 的突触权重。ηfc是学习率,hfc, l(t)是当前层 l 的膜电位状态。
E. The pseudo gradient approximation
SNN中的动态LIF神经元是非微分的,难以传播梯度以进一步计算从全局BRP到局部权重合并的梯度。SNN的传统局部调整使用STDP或差分Hebb原理进行局部突触修改[19][46][48]。与此不同,在这里,我们给出了LIF神经元的额外伪梯度近似,以使用Pytorch架构调整SNN [64]。伪梯度将发放神经元的非差分过程(其中膜电位Vi(t)达到发放阈值Vth,然后重置为Vreset)作为特定的伪梯度。伪梯度近似计算如下:
![]()
其中ΔVi(t)在传播过程中被设置为一个有限数(这里为简单起见为1),以绕过传统梯度传播过程中Vi(t)的非微分问题,其中原始ΔVi(t)当Vi(t) = Vth时实际上是无穷大。
F. The algorithm complexity analysis
G. The BRP-SNN learning procedure
H. The analysis of why BRP works
IV. EXPERIMENTS
A. The spatial datasets
B. The temporal datasets
C. The configuration of parameters
D. The convergence learning of BRP-SNNs
E. BRP reached comparable performance with pseudo-BP
F. The comparison of BRP-SNNs with other SOTA algorithms
G. Low computation cost of the BRP-SNN with silent neurons
V. CONCLUSION