郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

IJCNN, pp.1-8, (2020)
Abstract
生物大脑在控制能力和功耗方面仍然远远超过人工智能系统。脉冲神经网络(SNN)是一种很有前途的模型,受到神经科学的启发,在功能上更接近神经元处理信息的方式。虽然神经形态硬件的最新进展允许脉冲网络的节能集成,但此类网络的训练仍然是一个悬而未决的问题。在这项工作中,我们专注于具有稀疏延迟奖励的强化学习。所提出的架构有四个不同的层,并解决了先前模型在输入维度的可扩展性方面的局限性。我们的SNN在经典强化学习和控制任务上进行评估,并与两种常见的RL算法进行比较:Q学习和深度Q网络(DQN)。实验表明,所提出的网络在具有六维观察空间的任务上优于Q学习,并且在稳定性和内存要求方面优于评估的DQN配置。
Index Terms—Reinforcement learning, spiking neural networks, reward-modulated STDP
I. INTRODUCTION
强化学习(RL)与动物的学习方式非常相似,并受其启发[1]。这是一个非常灵活的范式,可用于训练智能体执行任务,而无需事先了解如何逐步执行任务——成功试验结束时的奖励就足够了。RL的最新进展包括能够比人类更好地玩视频游戏的算法[2],以及为腿式机器人学习敏捷和动态运动技能[3]。
尽管机器人技术和机器学习取得了巨大进步,但与生物系统相比,人工系统仍然存在明显的缺点。首先,虽然动物可以快速适应和学习新行为,但训练人工神经网络(ANN)非常耗时,并且通常需要大量示例。其次,对已经训练过的人工神经网络进行推理是耗电的,并且可以显著降低电源有限的移动应用程序的自主性,例如太空探索、机器人和可穿戴设备[4]。例如,当人脑消耗约20 W时,人脑计划对皮层的模拟预计消耗500 MW,大约相当于25万个家庭[5], [6]。
传统ANN使用接收和传输连续信号的神经模型,本质上用作通用函数逼近器。另一方面,生物神经元通过离散脉冲发送和接收信息。基于神经科学的见解,人工脉冲神经网络(SNN)是利用时空信息处理和低能量需求的有前途的替代方案。最先进的低功耗神经形态硬件能够实时模拟105到106个脉冲神经元[6]。最近一项值得注意的工作提出并实现了一个完全光学脉冲神经网络,有可能进一步增加SNN的带宽和处理速度[7]。
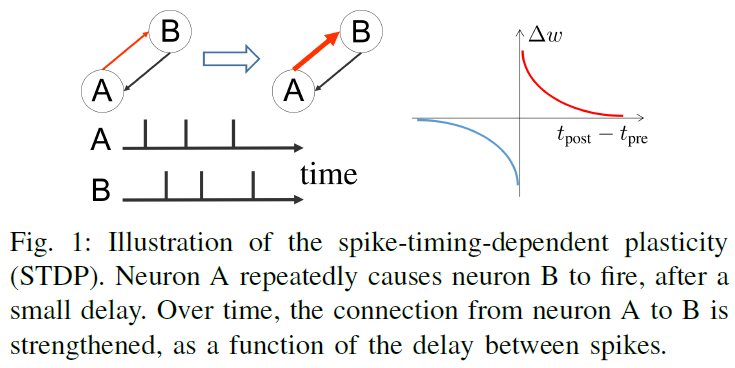
传统人工神经网络的训练通常涉及梯度下降方法。即使在RL框架中使用时,ANN也是通过反向传播对来自环境的一系列先前观察到的样本进行训练的[2]。虽然可以使用改进的基于梯度的优化来训练SNN,但这并没有利用生物神经元的低功耗要求[8]。SNN不是计算所有突触的全局梯度,而是可以采用一种生物学合理的过程,称为脉冲时序依赖可塑性(STDP)。这种传统ANN使用接收和传输连续信号的神经模型,本质上用作通用函数逼近器。另一方面,生物神经元通过离散脉冲发送和接收信息。基于神经科学的见解,人工脉冲神经网络(SNN)是利用时空信息处理和低能量需求的有前途的替代方案。最先进的低功耗神经形态硬件能够实时模拟105到106个脉冲神经元[6]。最近一项值得注意的工作提出并实现了一个完全光学脉冲神经网络,有可能进一步增加SNN的带宽和处理速度[7]。突触可塑性规则只要求每个突触都知道相应的突触前和突触后神经元。STDP如图1所示,可应用于神经元网络。此外,STDP可以通过全局奖励信号(R-STDP)进行调节,并且已被证明可以解决强化学习问题,而无需对突触进行显式梯度计算。在目前的工作中,我们专注于具有延迟和稀疏奖励的RL任务,类似于在成功完成任务后为动物提供食物奖励的方式。
第II节中介绍的相关工作分析表明,先前提出的RL脉冲网络不能随着传感器数量的增加而很好地扩展。此外,可塑性通常仅限于单层和线性可分问题。这项工作的主要目标是展示和评估一种新颖的脉冲架构,克服以前模型在感官空间可扩展性方面的局限性。我们的模型旨在用于未来在硬件上的实现。因此,我们遵循类似于最近工作[9], [10]的策略,并使用简化的神经和突触可塑性模型,将紧凑性优先于生物现实主义。
II. RELATED WORK
Izhikevich [11]和Florian [12]独立提出了具有奖励调节可塑性的SNN的早期版本。在这两种情况下,都使用了资格迹和STDP。特别是,Florian [12]证明了一个全连接的多层脉冲神经元网络可以解决具有延迟奖励的时序编码XOR问题。
Portjans et al. [13]提出了第一个实现actor-critic框架的脉冲网络,这是一种经典的RL算法。该网络的功能在离散的网格世界环境中进行了演示,其中智能体能够沿四个主要方向移动以到达目标位置。Frémaux、Sprekeler和Gerstner [14]还提出了一种具有时序差分(TD)误差驱动可塑性的连续时间actor-critic模型。所提出的神经调节后来包含在[15]中更一般的三因素学习规则中。该网络在具有障碍物的更大网格世界任务以及包括acrobot在内的两个控制任务上进行评估。应该注意的是,[13]和[14]都实现了一个没有隐藏层的脉冲网络。因此,输入层中的每个神经元,也称为位置神经元,用于编码环境的特定状态。例如,为了使acrobot问题在计算上易于处理并限制输入神经元的数量,[14]使用自定义编码来降低环境的维度并限制每个传感器的分辨率。尽管如此,对于四维状态空间,位置神经元的数量仍然达到11025。目前的工作提出了一种新颖的架构,该架构不会显著增加高维问题的神经元数量。例如,60个输入神经元对于具有六维观察的acrobot任务就足够了。
Nakano et al. [16]通过提出具有内存的受限玻尔兹曼机(RBM)的SNN版本来解决输入维度问题。该网络能够通过使用来自28 x 28个二值图像的视觉线索在T迷宫上导航。虽然这种方法在高维任务上是成功的,但该网络之前已接受过以监督方式进行视觉处理的训练。因此,尚不清楚这种架构是否可以应用于高维控制问题和持续学习。
Rueckert et al. [17]引入了带有基于模型的RL的SNN,包括单独的状态和上下文神经群体。虽然这个网络能够解决规划任务,但它仍然仅限于几个输入维度。Tannenberg et al. [18]通过模仿引入了一种相关但更具可扩展性的学习规则。目前的工作从[17][18]提出的模型中汲取灵感,同时保持强化学习范式并引入可以很好地扩展到四个以上维度的群体编码。
Wilson et al. [19]使用随机连接的Izhikevich神经元评估不同版本的R-STDP,随时间和空间引入可变的多巴胺浓度。该网络被训练用于虚拟水生动物的运动,并分布在智能体的身体上。可变时空多巴胺浓度似乎明显优于标准R-STDP[11]。该网络使用稀疏奖励信号进行训练,尽管评估连续奖励的成功率也较低。训练有素的网络能够将输入刺激与输出神经元相关联,以最大限度地提高运动速度。为了诱导动物身体的运动,网络的输入是一组固定的周期信号,没有感官信息。
Bing et al. [20]表明R-STDP优于其他基于SNN的最先进算法,用于跟踪机器人任务。在[21]中的虚拟蛇机器人上展示了一个类似但多层的SNN模型,其性能优于单层对应物。在这两项工作中,不断提供奖励信号以进行纠正,并且学习过程不针对远端奖励。
Wunderlich et al. [22]证明了神经形态硬件的功耗优势,其中带有R-STDP的小型脉冲网络学习在BrainScaleS 2神经形态系统上玩乒乓球游戏。与之前的相关工作一样,输入层用于对系统的所有状态进行编码。
Yuan et al. [23]提出了具有两种类型突触的突触可塑性规则。该规则旨在更好地近似生物可塑性机制,并涉及随机和确定性突触。虽然它是一种新颖的学习规则,可以深入了解大脑如何执行RL,但并未解决神经架构的可扩展性。

III. PROPOSED SPIKING NETWORK
所提出的SNN的示意图如图2所示。图示环境是一个3 x 3网格,智能体从两个传感器接收位置信息。输入层包含Ni = nd x ns神经元,其中一组nd神经元用于在one-hot配置中对来自每个ns传感器的信号强度进行编码。这样,输入层在任何给定的时间步长都会产生ns脉冲。四个离散的动作是可能的,代表在每个基本方向上的运动。以下部分更详细地描述了神经模型和所提出网络的结构。
A. Neural Model
B. Synaptic Plasticity
C. Hidden Layer
D. Place Neurons
E. Output Layer
IV. EXPERIMENTS
A. Setup
将所提出的模型与两个模拟任务的基准算法进行比较:maze和acrobot。两种环境在成功达到目标状态后都提供稀疏二值奖励,但需要智能体的不同能力。下面提供了这些环境的详细描述。
1) Maze task: 莫里斯水迷宫是一个经典的神经科学实验,其中一只老鼠在水不透明的水池中游泳,寻找一个淹没的平台。在一些相关的工作中发现了这个任务的变化,例如[13]和[14]。该环境如图4所示。为了学习任务,智能体必须执行一长串离散动作并达到一个目标,该目标包含50 x 50迷宫中所有可能状态的0.04%。到达目标位置后会收到二值奖励。
本文还对该任务的变体进行了初步实验,例如不同的迷宫大小、无墙和最多5个维度。所提出的SNN在这些探索性实验中表现良好,限制因素似乎是随机找到目标的概率,随着维数的增加,这个概率会呈指数级增长。如以下部分所述,acrobot环境更适合评估具有更高维度观察的可扩展性。
2) Acrobot: 为了证明对更高、更动态的状态空间的控制,我们转向RL文献中的另一个经典问题。设置如图5所示,目标是将机器人的尖端提升到一定水平。环境提供两个关节角度的正弦和余弦值,以及各自的角速度。第二个关节被弱驱动,系统包括引力。为了解决这个任务,智能体必须不断摆动驱动关节,积累能量。与迷宫相反,acrobot问题没有单个目标状态,而是在更高的六维状态空间上执行搜索。为了鼓励减少达到目标状态所需时间的策略,当达到目标时,智能体会收到一个二值奖励信号,而延迟时间低于最近100次试验。该环境与OpenAI Gym [26]提供的环境相同,只是奖励策略被修改为二值且稀疏。
B. Baseline Models
C. Hyperparameters
D. Results
V. CONCLUSION AND FUTURE WORK