参考链接:Speeding up DQN on PyTorch: how to solve Pong in 30 minutes | by Max Lapan | Medium

Intro
前段时间我实现了文章Rainbow: Combining Improvements in Deep Reinforcement Learning using PyTorch和我的名为PTAN的小型强化学习库中的所有模型。如果你好奇,这里有八个系统的代码。
为了调试和测试它,我使用了Atari套件中的Pong游戏,主要是因为它的简单性、快速收敛性和超参数鲁棒性:你可以将回放缓存尺寸缩小10到100倍,它仍然会很好地收敛。这对于无法访问谷歌员工拥有的计算资源的深度强化学习爱好者来说非常有帮助。在代码的实现和调试过程中,我需要运行大约100-200次优化,因此,一次运行需要多长时间并不重要:2-3天或一个小时。
尽管如此,你始终应该在这里保持平衡:尝试尽可能多地压缩性能,您可能会引入错误,这将使已经很复杂的调试和实现过程变得非常复杂。所以,在Rainbow论文上的所有系统都实现之后,我问自己一个问题:是否有可能使我的实现更快,不仅能够在Pong上训练,而且能够挑战其余的游戏,这至少需要50M帧进行训练,如SeaQuest、River Raid、Breakout等。
由于我的计算资源非常有限,只有两个1080Ti + 一个1080,(在现在已经非常有限了),唯一的办法就是让代码更快。
Initial numbers
作为起点,我采用了具有以下超参数的经典DQN版本:
- 使用了gym 0.9.3的环境PongNoFrameskip-v4;
- 前100k帧的epsilon从1.0衰减到0.02,然后epsilon保持0.02;
- 每1k帧同步目标网络;
- 大小为100k的简单回放缓存最初在训练前预取10k次转换;
- Gamma=0.99;
- Adam学习率为1e-4;
- 每个训练步骤,从环境中添加一个转换到回放缓存,并在从回放缓存均匀采样的32个转换中执行训练;
- 当最近100次游戏的平均得分大于18时,认为Pong已解决。
应用于环境的包装器对于速度和收敛都非常重要(前段时间,我浪费了两天时间试图在工作代码中找到一个错误,该错误仅仅因为缺少"Fire at reset"包装器而拒绝收敛。所以,我前段时间从OpenAI基准项目中使用的包装器列表:
- EpisodicLifeEnv:在每一次失去生命时结束回合,这有助于更快地收敛;
- NoopResetEnv:在重置时执行随机数量的NOOP动作;
- MaxAndSkipEnv:为4个Atari环境帧重复选择的动作以加速训练;
- FireResetEnv:在开始时按下开火。一些环境需要这个才能开始游戏。
- ProcessFrame84:帧转换为灰度并缩小到84*84像素;
- FrameStack:传递最后4帧作为观察;
- ClippedRewardWrapper:裁剪奖励到-1..+1范围。
在GTX 1080Ti上运行的初始代码版本显示训练期间每秒154次观察的速度,并且根据初始随机种子可以在60到90分钟解决Pong。这就是我们的出发点。从这个角度来看,RL论文通常使用的100M帧需要我们耐心等待7.5天。
Change 1: larger batch size + several steps
我们通常用于加速深度学习训练的第一个想法是更大的批量。它适用于深度强化学习领域,但这里需要小心。在正常的监督学习案例中,一个简单的规则"大批量更好"通常是正确的:你只需增加你的批量,直到你的GPU内存允许极限,并且更大的批量通常意味着将在单位时间内处理更多的样本,这要归功于巨大的GPU并行性。
强化学习案例略有不同。在训练期间,两件事同时发生:
- 你的网络经过训练可以更好地预测当前数据;
- 你的智能体正在探索环境。
当智能体探索环境并了解其动作的结果时,训练数据正在发生变化。例如,在射击游戏中,你的智能体可以随机运行一段时间,被怪物击中,在训练缓存中只有"死亡无处不在"的悲惨经历。 但过了一会儿,智能体会发现他有一个可以使用的武器。这种新经验可以极大地改变我们用于训练的数据。
RL收敛通常建立在训练和探索之间的脆弱平衡上。如果我们只是在不调整其他选项的情况下增加批量大小,我们很容易过拟合当前数据(对于上面的射击游戏示例,你的智能体可能会开始认为"早点去死"是最大程度减少痛苦的唯一选择,并且永远无法发现它有的枪)。
因此,在02_play_steps.py中,我们在每个训练循环中执行多个步骤,并使用批次大小乘以该步骤数。但是我们需要小心这个步数参数。更多的步骤意味着更大的批量大小,这应该会导致更快的训练,但同时在训练之间做很多步骤可以用从旧网络获得的样本填充我们的缓存。
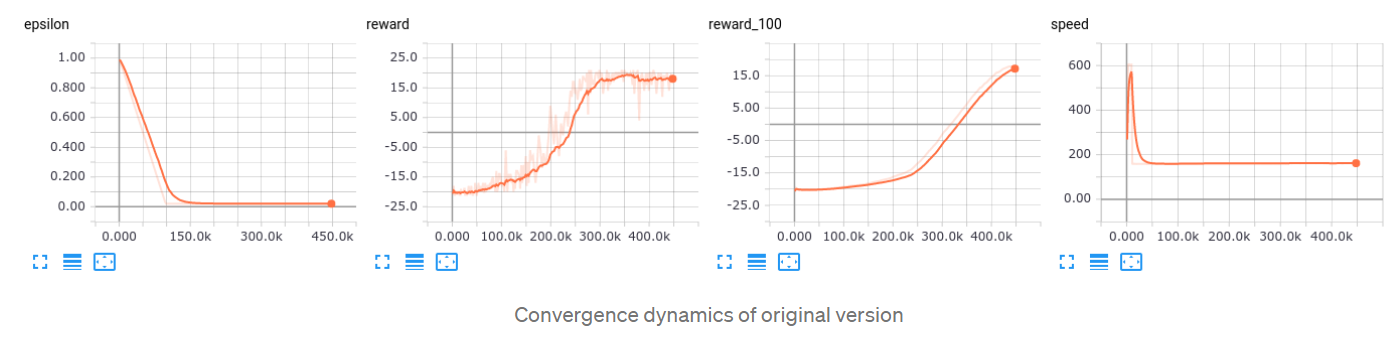
为了找到最佳位置,我使用随机种子(你需要同时通过numpy和pytorch)修复了训练过程,并针对各个步骤对其进行了训练。
- steps=1: speed 154 f/s (显然,它与原始版本相同)
- steps=2: speed 200 f/s (+30%)
- steps=3: speed 212 f/s (+37%)
- steps=4: speed 227 f/s (+47%)
- steps=5: speed 228 f/s (+48%)
- steps=6: speed 232 f/s (+50%)
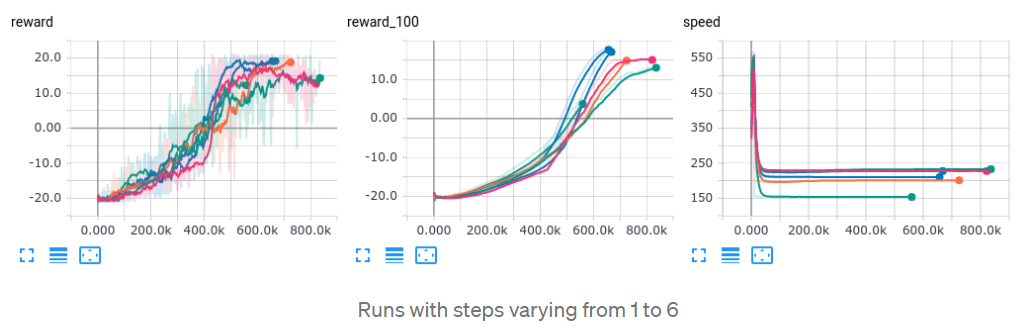
收敛动态几乎相同(见下图),但速度增加在4步左右饱和,因此,我决定坚持这个数字进行后续实验。
好的,我们的性能提升了47%。
Change 2: play and train in separate processes
在这一步中,我们将检查我们的训练循环,它基本上包含以下步骤的重复:
- 使用当前网络在环境中玩N个步骤以选择动作;
- 将这些步骤中的观察值放入回放缓存;
- 从回放缓存中随机采样批次;
- 在这批上训练。
前两步的目的是用来自环境的样本(观察、动作、奖励和下一次观察)填充回放缓存。最后两步是训练我们的网络。
上述步骤及其与环境的通信、GPU上的DQN和回放缓存的说明如下图所示。
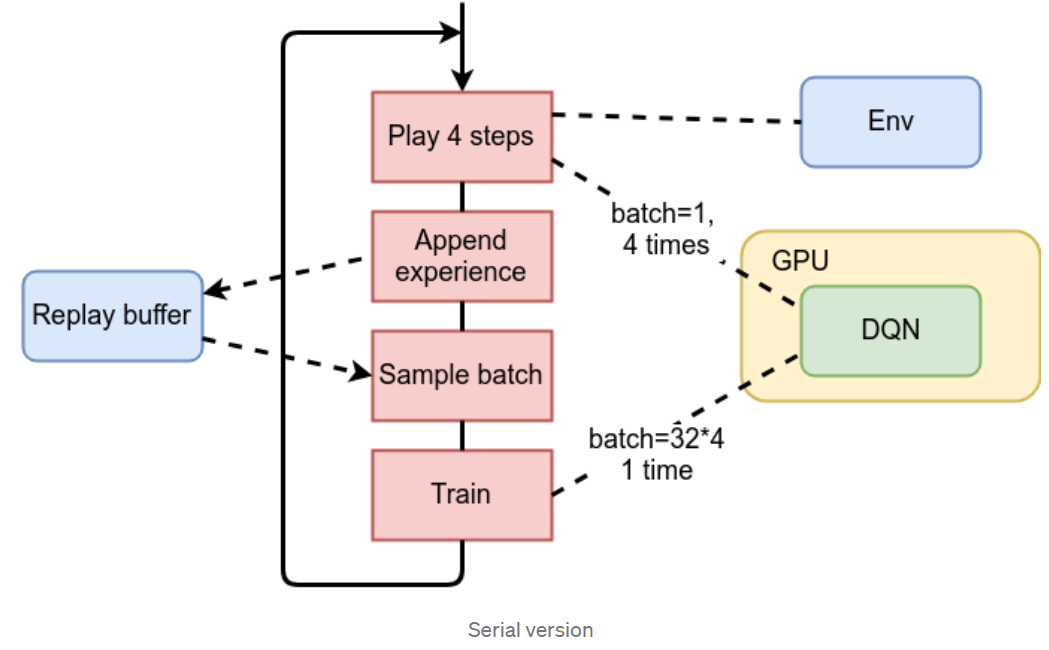
正如我们所看到的,环境仅被第一步使用,我们训练的上半部分和下半部分之间的唯一连接是我们的回放缓存。由于这种数据独立性,我们可以并行运行两个进程:
- 第一个进程将与环境通信,向回放缓存提供新数据;
- 第二个进程将从回放缓存中采样训练批次并执行训练。
这两个活动应该同步运行,以保持我们在上一节中讨论的训练/探索平衡。
这个想法是在03_parallel.py中实现的,并且正在使用torch.multiprocessing模块来并行玩游戏和训练仍然能够与GPU同时工作。为了尽量减少其他类中的修改,只有第一步(环境通信)放在单独的过程中。使Queue类将获得的观察结果传输到训练循环。

这个新版本的基准测试显示令人印象深刻的395帧/秒,与之前的版本相比增加了74%,与代码的原始版本相比增加了156%。
Change 3: async cuda transfers
下一步很简单:每次我们调用Tensor的cuda()方法时,我们都会传递async=True参数,这将禁止等待传输完成。它不会给你带来非常令人印象深刻的加速,但有时会给你一些东西并且很容易实现。
此版本位于文件04_cuda_async.py中,唯一的区别是将cuda_async=True传递给calc_loss函数。
基准测试后,我获得了406帧/秒的训练速度,比上一步提高了3.5%,与原始DQN相比提高了165%。
Change 4: latest Atari wrappers
正如我之前所说,DQN的原始版本使用了一些来自OpenAI基准项目的旧Atari包装器。几天前,这些包装器被更改为名为"更改atari预处理以使用更快的opencv"的提交,这绝对值得一试。
这是基准存储库中包装器的新代码。DQN的下一个版本在05_new_wrapper.py中。由于我还没有将新的包装器拉入ptan库中,因此它们在示例中位于单独的库中。
基准测试结果是484帧/秒,比上一步增加了18%,最终比原始版本增加了214%。
Summary
谢谢阅读!
通过几个不太复杂的技巧,我们将 DQN 的速度提高了3倍以上,同时不会牺牲可读性并增加代码的额外复杂性(训练循环仍然少于100行Python代码)。而现在,最新版本能够在20-30分钟内在Pong中达到18分,这为尝试其他Atari游戏开辟了许多新的可能性,因为每秒484帧意味着处理100M观察的时间不到2.5天。
如果你知道更多可以提高PyTorch代码性能的东西,请留下评论,我真的很想知道它们。