郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

NATURE COMMUNICATIONS, no. 1 (2020): 3625-21
Abstract
循环连接的脉冲神经元网络是大脑惊人的信息处理能力的基础。然而,尽管进行了广泛的研究,但它们如何通过突触可塑性学习以执行复杂的网络计算仍不清楚。我们认为这个难题的两个部分是由神经科学的实验数据提供的。数学结果告诉我们需要如何组合这些部分,以通过梯度下降实现生物学合理的在线网络学习,尤其是深度强化学习。这种称为e-prop的学习方法接近时间反向传播(BPTT)的性能,这是机器学习中训练循环神经网络的最著名方法。此外,它还提出了一种在用于人工智能的节能脉冲硬件中进行强大片上学习的方法。
大脑中的神经元网络与机器学习中的深度神经网络在至少两个基本方面有所不同:它们循环连接,形成大量循环,并且它们通过异步发放的定型电脉冲(称为脉冲)进行通信,而不是由深度前馈网络的每一层以同步方式产生的比特或数值。我们考虑了大脑中突触神经元可以说是最突出的模型:LIF神经元,其中通过突触连接从其他神经元到达的脉冲与相应的突触权重相乘,并通过泄漏膜电位进行线性积分。当膜电位达到发放阈值时,神经元发放——即发出脉冲信号。
(待续)
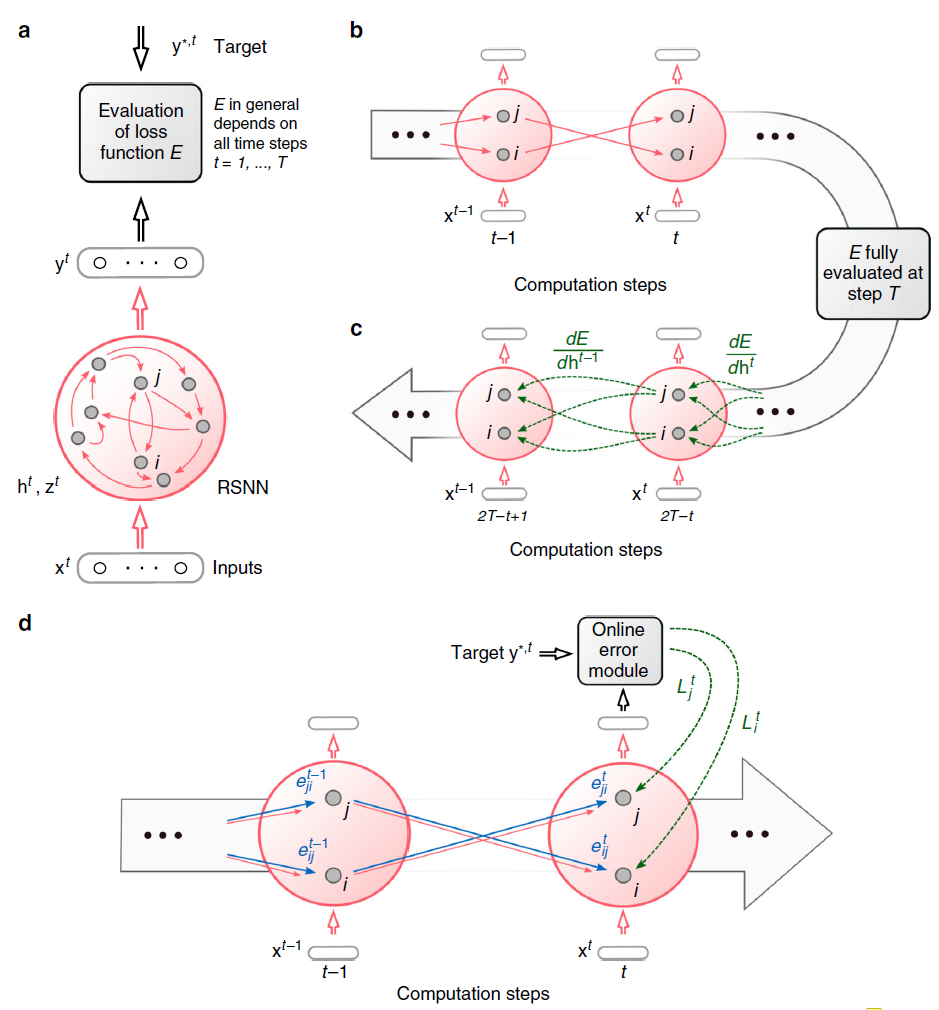
图1:BPTT和e-prop的方案。(a) 对于RSNN计算的每个时间步骤 t,具有网络输入 x,神经元脉冲 z,隐含神经元状态 h 和输出目标 y* 的RSNN。输出神经元 y 提供网络脉冲 z 的加权和的低通滤波器。(b) BPTT计算网络的展开版本中的梯度。对于每个时间步骤 t,它都有RSNN神经元的新拷贝。从RSNN的神经元 i 到神经元 j 的突触连接被一组前馈连接代替,每个时间步骤 t,将时间步骤 t 时层中神经元 i 的拷贝到时间步骤t + 1时层中神经元 j 的拷贝。此数组中的所有突触都具有相同的权重:RSNN中此突触连接的权重。(c) 在前馈计算经过层很长时间之后,BPTT的损失梯度会及时反向传播,并以离线方式跨突触逆行。(d) e-prop的在线学习动态。资格迹的前馈计算以蓝色表示。根据等式(1),这些与在线学习信号结合在一起。
Results
Mathematical basis for e-prop.
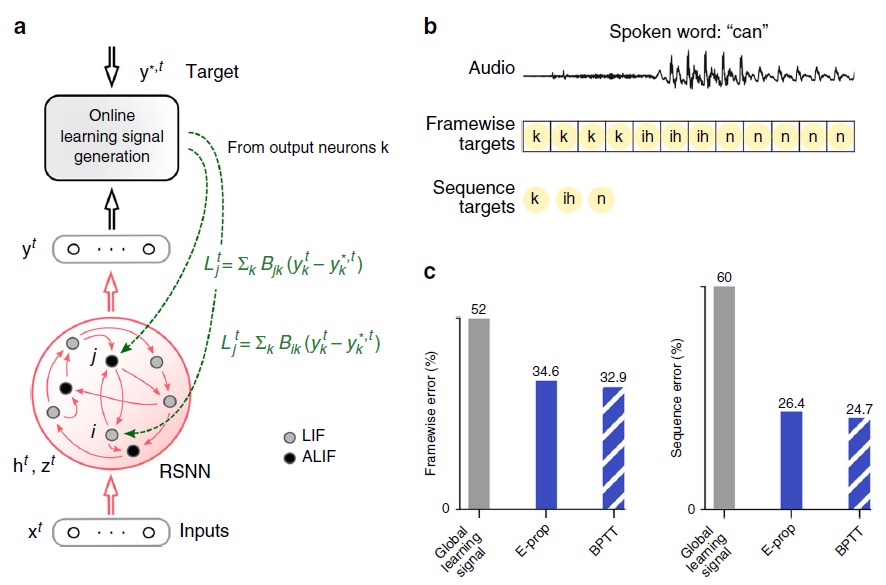
图2:BPTT和e-prop用于学习音素识别的比较。(a) e-prop的网络架构,针对由LIF和ALIF神经元组成的LSNN进行了说明。(b) TIMIT的两个版本的输入和目标输出。(c) LSNN中BPTT和对称e-prop的性能由用于框架目标的800个神经元和用于序列目标的2400个神经元组成(随机和自适应e-prop产生了相似的结果,请参见补充图2)。为了获得全局学习信号基准,将神经元特定的反馈替换为全局反馈。
Learning phoneme recognition with e-prop.
Solving difficult temporal credit assignment.
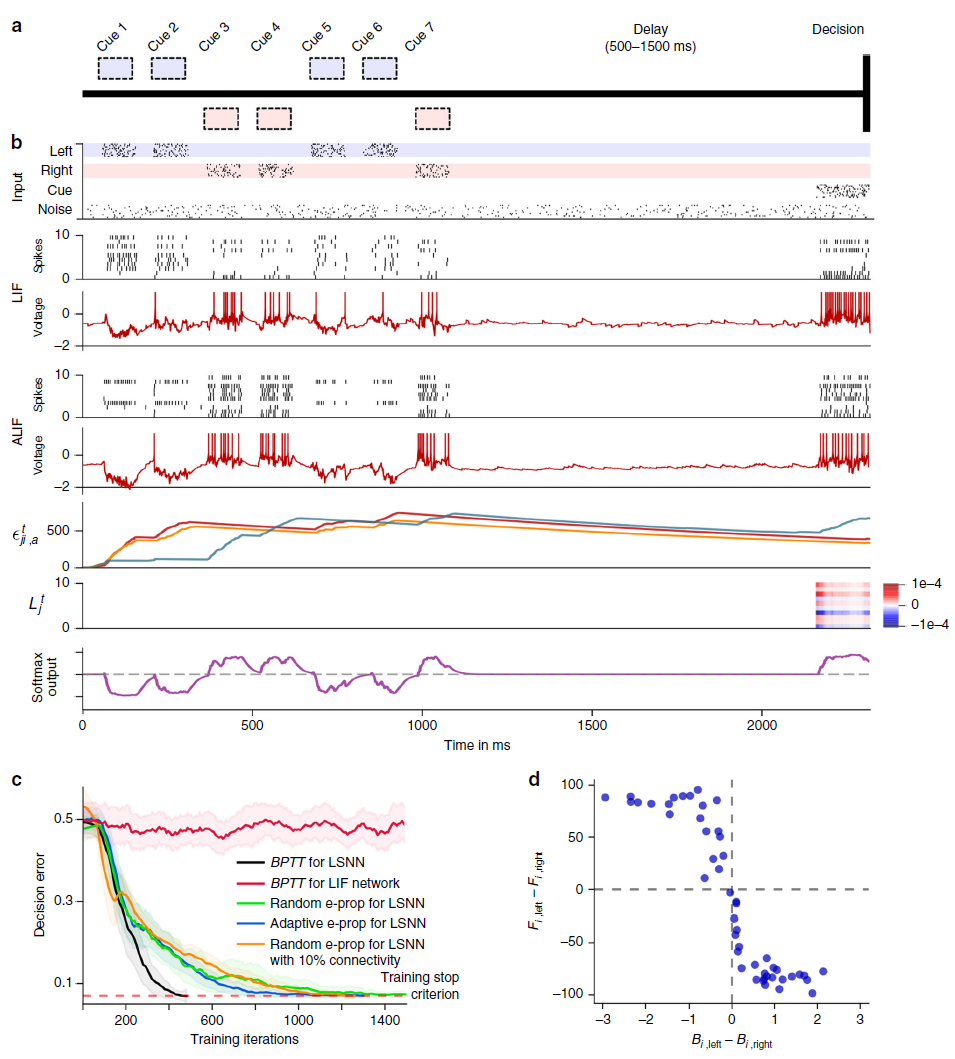
图3:解决具有困难的时序信度分配的任务。(a) 参考文献23,14的相应啮齿动物实验的设置,参见补充影片1。(b) 输入脉冲,50个LIF样本神经元中10个和50个ALIF样本神经元中10个的脉冲活动,两个样本神经元 j 的膜电位(更准确地:![]() ),三个资格迹的慢分量的样本,10个神经元的样本学习信号和softmax网络输出。(c) BPTT和两个e-prop版本应用于LSNN的学习曲线,BPTT应用于RSNN,而无需调整神经元(红色曲线)。橙色曲线显示了稀疏连接的LSNN(由兴奋性神经元和抑制性神经元组成)对e-prop的学习性能(遵守了戴尔定律)。阴影区域是通过20次运行计算得出的平均精度的95%置信区间。(d) 随机e-prop中学习信号的k = left/right时,随机抽取的广播权重Bjk与学习后对左右输入分量的灵敏度之间的相关性。fj,left(fj,right)是学习后左(右)线索的呈现过程中神经元 j 的平均发放率。
),三个资格迹的慢分量的样本,10个神经元的样本学习信号和softmax网络输出。(c) BPTT和两个e-prop版本应用于LSNN的学习曲线,BPTT应用于RSNN,而无需调整神经元(红色曲线)。橙色曲线显示了稀疏连接的LSNN(由兴奋性神经元和抑制性神经元组成)对e-prop的学习性能(遵守了戴尔定律)。阴影区域是通过20次运行计算得出的平均精度的95%置信区间。(d) 随机e-prop中学习信号的k = left/right时,随机抽取的广播权重Bjk与学习后对左右输入分量的灵敏度之间的相关性。fj,left(fj,right)是学习后左(右)线索的呈现过程中神经元 j 的平均发放率。
Reward-based e-prop.

图4:e-prop在Atari游戏Pong中的应用。(a) 在此,玩家(绿色球拍)必须胜过对手(浅棕色)。当对手无法反弹球时获得奖励(一个小白方块)。为了达到这个目的,智能体必须学会用球拍的边缘击球,这会导致难以预测的轨迹。(b) 该智能体是通过LSNN实现的。提供游戏当前视频帧的像素作为输入。在由LSNN处理视频帧流的过程中,随机策略以在线方式生成操作。同时,可以预测未来奖励。当前的预测误差将反馈到LSNN和对帧进行预处理的脉冲CNN。(c) 使用基于奖励的e-prop学习后,对LSNN进行样本试验。从上到下:随机动作的概率,未来奖励的预测,随机突触的学习动态(任意单位),240个样本LIF神经元中10个和160个样本ALIF神经元中10个的脉冲活动以及位于上方脉冲栅格底部的两个样本神经元的膜电位。(d) 受基于奖励的e-prop训练的LSNN的学习进度,报告为一个回合中收集的奖励总和。学习曲线在五个不同的运行中取均值,阴影区域代表标准差。有关我们的结果与A3C之间比较的更多信息,请参见补充说明5。
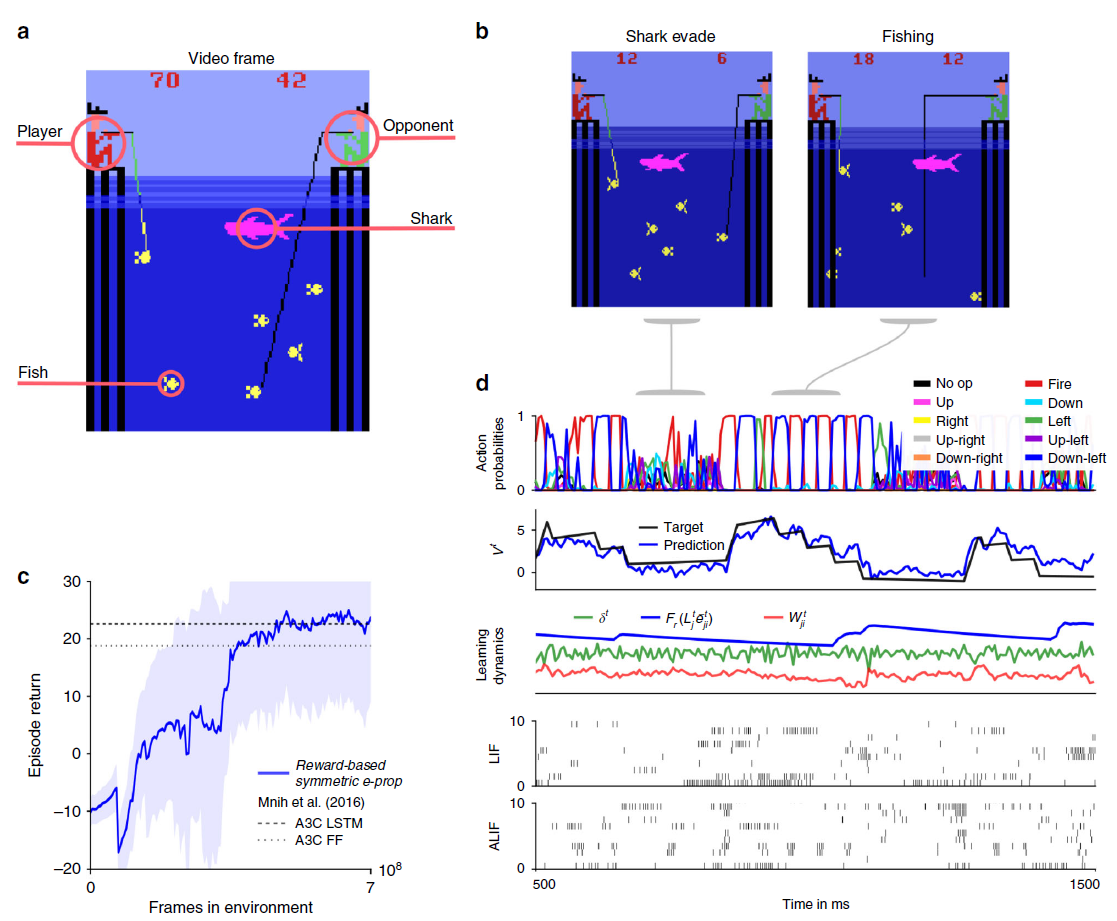
图5:学习赢得Atari游戏Fishing Derby的e-prop应用。(a) 在此,玩家必须与对手竞争,并尝试从海中捕捞更多的鱼。(b) 一旦鱼被咬了,智能体必须避免鲨鱼碰到鱼。(c) 训练好的网络的样本试验。从上到下:随机动作的概率,未来奖励的预测,随机突触的学习动态(任意单位),180个样本LIF神经元中20个和120个样本ALIF神经元中20个的脉冲活动。(d) 如图4d所示,使用基于奖励的e-prop训练的LSNN的学习曲线。
Discussion
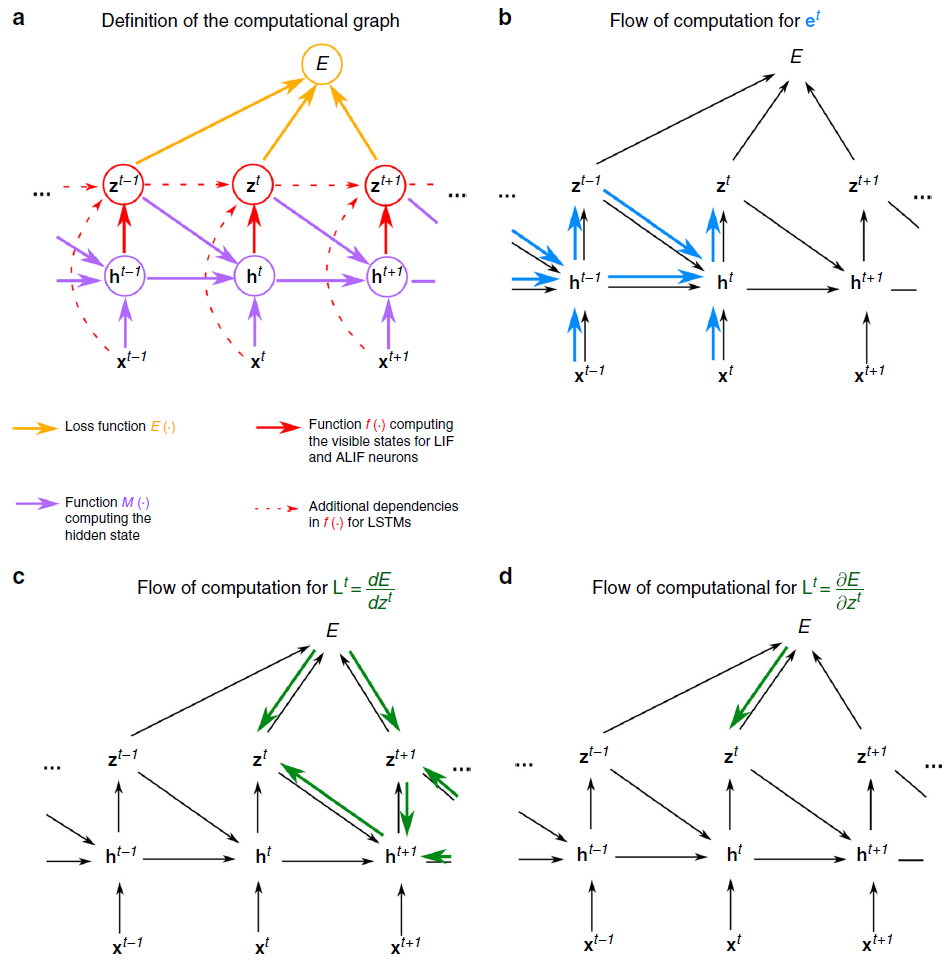
图6:计算图和梯度传播。(a) 假设隐含神经元状态,神经元输出,网络输入以及通过数学函数的损失函数E之间的数学依赖性由彩色箭头表示。(b–d) 合并到等式3的损失梯度中的两个分量et和Lt的计算流程可以用类似的图形表示。(b) 遵循等式14,资格迹的计算流正在及时前进。(c) 相反,理想学习信号L要求在时间上反向传播梯度。(d) 因此,尽管资格迹是精确计算的,但在e-prop应用程序中L是近似的,以产生在线学习算法。
Methods
Network models.
LIF neurons.
LSNNs.
Gradient descent for RSNNs.
Network output and loss functions.
Notation for derivatives.
Notation for temporal filters.
Mathematical basis for e-prop.
Derivation of eligibility traces LIF neurons.
Eligibility traces for ALIF neurons.
Synaptic plasticity rules resulting from e-prop.
Reward-based e-prop: application of e-prop to deep RL.
Data availability
Code availability