资格迹机制的核心是一个短时记忆向量,资格迹zt ∈ Rd,以及与之相对的长时权重向量wt ∈ Rd。这个方向核心的思想是,当参数wt的一个分量参与计算并产生一个估计值时,对应的zt的分量会骤然升高,然后逐渐衰减。在迹归零前,如果发现了非零的时序差分误差,那么相应的wt的分量就可以学习。迹衰减参数λ ∈ [0, 1]决定了迹的衰减率。
在n-步算法中资格迹的主要计算优势在于,它只需要追踪一个迹向量,而不需要存储最近的n个特征向量。同时,学习也会持续并统一地在整个时间上进行,而不是延迟到整个幕的末尾才能获得信号。另外,可以在遇到一个状态后马上进行学习并影响后续决策而不需要n步的延迟。
12.1 λ-回报
n步回报被定义为最初n步的折后收益加上n步后到达状态的折后预估价值。
注意,一次有效的更新除了以任意的n步回报为目标之外,也可以用不同n的平均n步回报作为更新目标。
可以把TD(λ)算法视作平均n步更新的一种特例。这里的平均值包括了所有可能的n步更新,每一个按比例λn-1加权,这里λ ∈ [0, 1],最后乘上正则项(1 - λ)保证权值和为1。这产生的结果称为λ-回报。
在λ = 1时,λ-回报的更新算法就是蒙特卡洛算法。在λ = 0时,λ-回报的更新算法就是单步时序差分算法。
12.2 TD(λ)
TD(λ)是强化学习中最古老、使用也最广泛的算法之一,它是第一个使用资格迹展示了更理论化的前向视图和更易于计算的后向视图之间关系的算法。
TD(λ)通过三种方式改进了离线λ-回报算法。首先它在一幕序列的每一步更新权重向量而不仅仅在结束时才更新。其次,它的计算平均分配在整个时间轴上,而不仅仅是幕的结尾。第三,它也适用于持续性问题而不是仅仅适用于分幕式的情况。
通过函数逼近,资格迹zt ∈ Rd是一个和权重向量wt同维度的向量。权值向量是一个长期的记忆,在整个系统的生命周期中进行积累;而资格迹是一个短期记忆,其持续时间通常少于一幕的长度。资格迹辅助整个学习过程,它们唯一的作用是影响权值向量,而权值向量则决定了估计值。
在TD(λ)中,资格迹向量被初始化为零,然后在每一步累加价值函数的梯度,并以γλ衰减:
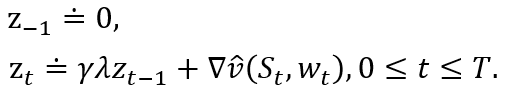
这里γ是折扣系数,而λ为前一章介绍的衰减率参数。资格迹追踪了对最近的状态评估值做出了或正或负贡献的权值向量的分量,这里的"最近"由γλ来定义。当强化事件出现时,我们认为这些贡献"痕迹"展示了权值向量的对应分量有多少"资格"可以接受学习过程引起的变化。我们关注的强化事件是一个又一个时刻的单步时序差分误差。预测的状态价值函数的时序差分误差为:
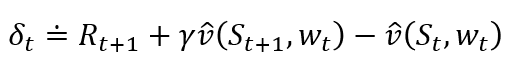
在TD(λ)中,权值向量每一步的更新正比于时序差分的标量误差和资格迹:
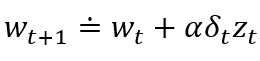 TD(λ)在时间上往回看。每个时刻我们计算当前的时序差分误差,并根据之前状态对当前资格迹的贡献来分配它。
TD(λ)在时间上往回看。每个时刻我们计算当前的时序差分误差,并根据之前状态对当前资格迹的贡献来分配它。
TD(0)仅仅让当前时刻的前导状态被当前的时序差分误差所改变,对于更大的λ (λ < 1),更多的之前的状态会被改变,越远的状态改变越少,这是因为对应的资格迹更小。也可以这样说,较早的状态被分配了较小的信用来"消费"TD误差。
如果λ = 1,那么之前状态的信用每步仅仅衰减γ。这个恰好与蒙特卡洛算法的行为一致。如果λ = 1并且γ = 1,那么资格迹在任何时候都不衰减。在这种情况下,该算法与无折扣的分幕式任务的蒙特卡洛算法的表现就是完全相同的。当λ = 1时,这种算法也被称为TD(1)。
12.3 n-步截断 λ-回报方法
离线λ-回报算法描述的是一种理想状况,但是其作用是有限的,因为它使用了直到幕末尾才知道的λ-回报。在持续性任务的情况下,严格说λ-回报是永远未知的,因为它依赖于任意大的n所对应的n-步回报,也即依赖于任意遥远的未来所产生的收益。然而,由于每一时刻有γλ的衰减,实际上对长期未来的收益的依赖是越来越弱的。那么一个自然的近似便是截断一定步数之后的序列。现有的n-步回报方法很自然地给我们提供了一种启示:缺少的真实收益可以用估计值来代替。
12.4 重做更新:在线λ-回报算法
选择截断TD(λ)中的截断参数n时需要折中考虑。n应该尽量大使其更接近离线λ-回报算法,同时它也应该比较小使得更新更快且更迅速地影响后续行为。
基本思想是,在每一步收集到的新的数据增量的同时,回到当前幕的开始并重做所有的更新。由于获得了新的数据,因此新的更新会比原来的更好。换言之,更新总是朝向一个n-步截断λ-回报目标,但是每次都使用新的视界。每一次遍历当前幕时,都可以使用一个稍长一点的视界来得到一个稍好一点的结果。
12.5 真实的在线TD(λ)
刚才提出的在线λ-回报算法是效果最好的时序差分算法。然而,这种算法很复杂。是否存在一种方法将这个前向视图算法转换为一个利用资格迹的有效前向视图算法呢?事实上,对于线性函数逼近,的确存在一种在线λ-回报算法的精确计算实现。这种实现被称为真实在线TD(λ)算法,因为它对TD(λ)的近似比理想的在线λ-回报算法对TD(λ)算法的近似更加"真实"。
12.6 蒙特卡洛学习中的荷兰迹
利用荷兰迹可以推导出一个等价的但是计算代价更小的后向视图算法。
12.7 Sarsa(λ)
对于本章中提出的方法,我们只需要做很少的改动就可以将资格迹扩展到动作价值函数方法中。为了学习近似动作价值函数![]() 而非近似状态价值函数
而非近似状态价值函数![]() ,我们需要利用n-步回报的动作价值函数形式:
,我们需要利用n-步回报的动作价值函数形式:
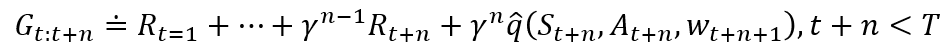
动作价值函数的时序差分方法,又被称为Sarsa(λ),近似了前向视图。它与前面提到的TD(λ)有着相同的更新规则:
自然地,动作价值函数版本的TD误差为:
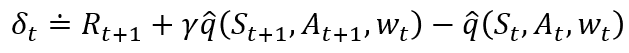
以及动作价值函数版本的资格迹为:
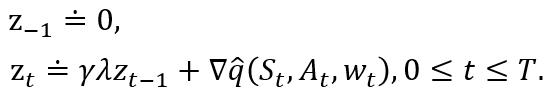
12.8 变量λ和γ
为了用更一般化的形式表述最终的算法,有必要将自举法和折扣的常数系数推广到依赖于状态和动作的函数。也就是说,每一个时刻会有一个不同的λ和一个不同的γ,用λt和γt来表示。
12.9 带有控制变量的离轨策略资格迹
最后一步是引入重要度采样。
12.10 从Watkins的Q(λ)到树回溯TB(λ)
多年以来,学术界提出了一系列将Q学习拓展到资格迹的方法。
12.11 采用资格迹保障离轨策略方法的稳定性
前面介绍的一些使用资格迹的方法,在离轨策略训练的情况下可以有稳定性的保证。在这里,我们使用本书中的一些标准概念,包括通用的自举和折扣函数,来介绍四种最重要的方法。它们全部都基于11.7节和11.8节中介绍的梯度TD或强调TD的思想。这里的所有算法都假设采用线性函数逼近,到非线性函数逼近的拓展可以在相关文献中找到。
12.12 实现中的问题
初看上去使用资格迹的表格型方法可能比单步法复杂得多。最朴素的实现需要每个状态(或"状态-动作"二元组)在每个时间步骤同时更新价值估计和资格迹。对于单指令多任务(SIMD)的并行计算机或合理的神经网络,实现不会是一个问题;但是对于常规的串行计算机上的实现来说,这就是一个问题。幸运的是,对于λ和γ的一些经典值,几乎所有状态的资格迹都总是接近于零,只有那些最近被访问过的状态的资格迹才会有显著大于零的值,因此,实际上只需要更新这几个状态,就能对原始算法有很好的近似。
在实践中,常规计算机上的实现可以仅跟踪和更新具有非零迹的少数状态。有了这个技巧,在表格型方法中使用资格迹的计算复杂度通常只是单步法的几倍。当然,确切的倍数取决于λ,γ和其他部分的计算复杂度。请注意,表格型情况在某种意义上是资格迹计算复杂度的最坏情况。当使用函数逼近时,不使用资格迹的计算优势会减小。例如,如果使用人工神经网络和反向传播算法,则使用资格迹通常仅会导致每步计算所需存储空间和计算量增加一倍。截断λ-回报法(12.3节)可以在常规计算机上高效计算,但一般需要一些额外的内存。
12.13 本章小结
资格迹和时序差分误差的结合提供了一种可以在蒙特卡洛法和时序差分法之间进行转换的高效的增量式方法。
正如我们在第5章中提到的,蒙特卡洛法由于不使用自举法,可能在非马尔可夫任务中有优势。因为资格迹使时序差分方法更像蒙特卡洛方法,它们在这些情况下也可以有优势。如果由于其他优点而想使用时序差分方法,但任务至少部分为非马尔可夫,那么就可以使用资格迹方法了。资格迹是针对长延迟的收益和非马尔可夫任务的首选方法。
通过调整λ,资格迹方法作为可以介于蒙特卡洛法和单步时序差分法之间的任一种方法。
使用资格迹的方法需要比单步法进行更多的计算,但作为好处,它们的学习速度显著加快,特别是当收益被延迟许多时间步骤时。因此,在数据稀缺并且不能被重复处理的情况下,使用资格迹通常是有意义的,许多在线应用就是这种情况。另一方面,在离线应用中可以很容易地生成数据,例如从廉价的模拟中生成数据,那么通常不使用资格迹。在这种情况下,目标不是从有限的数据中获得更多的数据,而是尽可能快地处理尽可能多的数据。使用资格迹带来的学习的加速通常抵不过它们的计算成本,因此在这种情况下单步法更受欢迎。