郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Nature Reviews Neuroscience, no. 3 (2018): 166-180
Abstract
人类和许多其他动物具有学习感官刺激和掌握新技能的巨大能力。但是,保证我们学习的许多机制仍有待了解。系统神经科学的最大挑战之一是解释突触连接如何变化以支持最大的适应性行为。在此,我们提供决定突触强度变化的因素的概述,重点是感觉皮层的突触可塑性。我们回顾神经调节剂和反馈连接在突触可塑性中的影响,并提出了一个特定的框架,其中这些因素可以相互作用,以改进整个网络的功能。
Introduction
感觉或联想皮层中的神经元如何优化其突触强度以改进整个大脑网络的性能?在计算神经科学中,确定与行为相关的联系的任务被称为"信度分配问题"(参考文献1,2)。对于ANN,存在解决此问题的强大方法3,4。然而,如何在大脑中解决它是一个重要但仍未解决的问题。
假设动物识别出特定的刺激,选择一个反应,然后意外地得到奖励。如果未来再次出现相同的刺激,则应改变联想和运动皮层的突触,以促进对相同动作的选择。此外,如果稍有不同的刺激需要不同的反应,则学习应加强对感觉皮层刺激的表征。
在这篇综述中,我们讨论了生物学合理的学习规则,这些规则可能使突触以优化行为结果的方式发生变化。我们专注于感觉皮层中的突触可塑性,并回顾其中学习依赖于突触可塑性的调节剂的框架。第一个修改因素是从响应选择处理阶段返回到联想和感觉皮层的反馈信号,该信号通知神经元有关所选动作的信息。该反馈信号导致突触的"标记"并控制其可塑性。第二个调节因素是神经调节剂的释放,神经调节剂除其他功能外,还向突触提供有关奖励预测误差(RPE;即动作的结果是否好于期望)的信息。我们将讨论反馈连接和神经调节剂的组合如何允许新的学习规则促进未来的动作,从而带来更多的奖励并在大脑中实现"深度学习"。
Box 1 | Deep learning in the brain
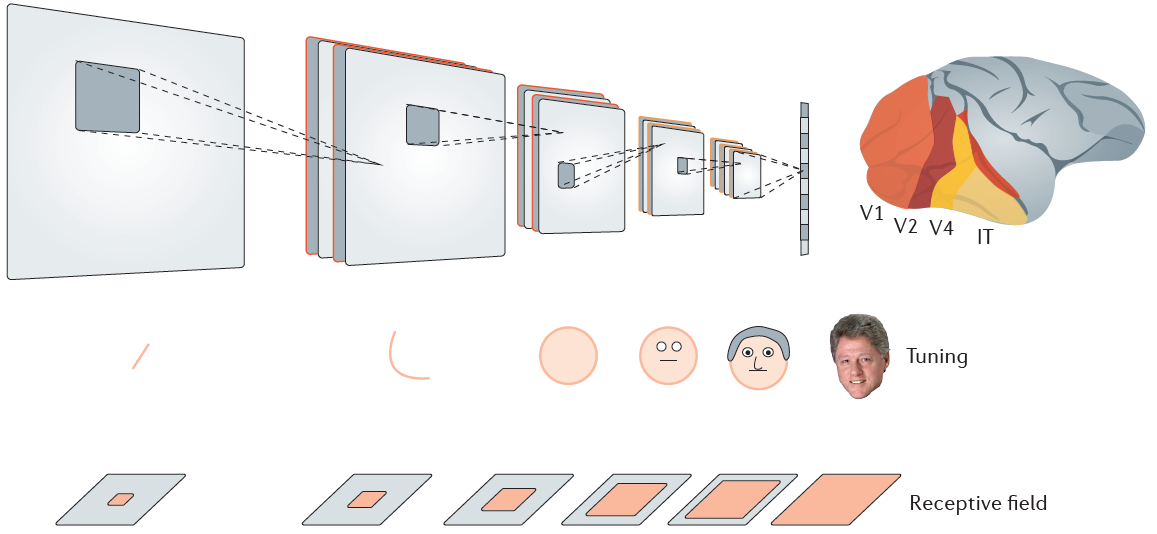
近年来,深度ANN已经取得了长足的进步,深度ANN由多层组成,并通过所谓的误差反向传播规则进行训练,该规则指定在训练期间网络单元之间的连接应如何变化。误差反向传播规则会调整由多层组成的网络中的突触权重,以减少输入到较低层,再到顶层输出中的映射中的误差。为此,首先要计算误差,该误差是输出单元的实际活动水平与期望活动水平之间的差异。然后,通过使用称为梯度下降3的方法计算导数,误差反向传播可以确定应如何改变连续较低层之间的连接强度以减小该误差。经过误差反向传播训练的ANN当前在图像识别4和某些计算机游戏中达到了人类水平的性能33。
人工图像识别系统通常采用卷积网络方法,在这种方法中,单元调整的复杂性会在较高层中增加,而特定层则散布在整个空间中以池化活动并建立平移不变的感受野(见图)。这些卷积网络中较低和较高层次的单位调整类似于猴子和人类大脑的较高和较低区域的神经元调整38,181。在卷积网络中,许多权重是共享的(即从网络中的一个位置复制到另一位置),这在生物学上是不可行的。此外,在1989年,Francis Crick指出,误差反向传播规则本身在神经生物学上是不现实的34。他发现很难想象大脑中的突触如何确定它们的强度变化,从而减少整体网络误差,也就是说,它们如何计算自己的局部误差导数。
但是,研究人员提出了新的方法,可以在大脑中实现等同于误差反向传播的学习规则28,32,95,182–184(在其他地方进行了综述185)。具体而言,诸如AGREL(注意力门控RL)28和AuGMEnT(注意力门控记忆标记)32之类的学习规则解释深度网络中的突触如何以生物学现实的方式改变以优化RL期间的奖励结果。由于建立这些新学习规则与误差反向传播之间关系的公式有些复杂,因此我们向偏爱数学的读者推荐原始出版物28,32。从概念上讲,主要的见识是,突触误差导数可分为两个因素:首先,操纵奖励预测误差编码全局网络误差,并通过释放神经调节剂到达所有突触。第二,来自响应选择阶段的门控信号,由反馈连接承载,指示应将多少信度或责备归因于单个突触。这些操纵和门控因素共同决定了突触可塑性(如正文中的公式3)。在AGREL和AuGMEnT中,学习过程中反馈连接强度与前馈连接强度成正比;因此,学习规则在计算上变得等同于误差反向传播。有趣的是,如果反馈连接是固定的,而只有前馈连接是可塑性的,则前馈和反馈连接之间的近似互惠以及有效学习也可以通过称为反馈对齐的过程来实现。
换句话说,大脑能够以等同于深度学习的方式解决信度分配问题。因此,这些规则可用于在几个任务上训练简单的ANN,猴子可以通过试错学习32来对其进行训练,它们的能力超出了没有可塑性门控反馈连接的生物学合理的学习规则。有趣的是,这些网络犯了许多错误,这些错误也是训练中的动物所犯的,中间网络层次的单位调整变得类似于视觉和联想皮质中的神经元13,28,32(导致调节曲线类似于在训练过的动物中看到的那些,例如图3c,f中的那些)。因此,从分子生物学到机器学习和认知的许多学科的发展现在可能为真正了解如何在大脑中实现深度学习铺平道路。IT,颞下皮质;V1,主要视觉皮层。
Photograph of US President Bill Clinton, copyright Ian Dagnall / Alamy Stock Photo.
Changing the strength of synapses
1949年,Donald O. Hebb5提出,突触强度的变化取决于突触前和突触后的活动。他对这一假设的表述如下:"当细胞A的轴突足够接近以激发细胞B并反复或持续参与发放它时,一个或两个细胞中都会发生某些生长过程或代谢变化,从而使A的效率(发放B的细胞之一)增加。"赫布规则可以形式化如下:

其中Δwi,j是神经元 i 和 j 之间连接强度的变化,β是学习率参数并确定变化的幅度,fi(ai)和fj(aj)分别是取决于突触前活动(ai)和突触后活动(aj)的函数。
大量证据支持赫布规则6,但研究人员意识到,如果目的是选择适当的动作,则该规则是不完整的,因为该规则不了解网络输出的有用性。在动物中,奖励和惩罚会影响学习,从而增强导致奖励的行为,并抑制导致厌恶结果的行为。
当很明显神经调节系统(例如多巴胺能系统)7能够产生意想不到的奖励时,RL理论的影响大大增加。在RL理论中,意外的奖惩产生了RPE1,8。如果动物获得的奖励比期望的多,则RPE为正;如果结果令人失望,则RPE为负。RL理论已经提出,突触前和突触后神经元的同时活动在突触处诱导资格迹,从而确定在RPE的情况下突触是否将经历可塑性。资格迹对应于突触标记,突触是突触前和突触后同时活动诱导的突触上的生化标记,但在神经元停止发放后可以保留一段时间1,9-13。研究已经开始阐明这些突触标签的分子身份14,15,但仍有许多发现。
正RPE(例如,从黑质和腹侧被盖区释放的多巴胺发出的信号)是增强这些标记突触的合适信号,因为它增加将来再次采取有奖动作的可能性。相比之下,负RPE会降低标记突触的强度。神经调节系统,包括多巴胺能系统,相当扩散地投射到皮层和皮层下结构,这表明它们的信号是全球性的。将RPE作为赫布规则的一个因素导致以下可塑性规则11,16-19:
![]()
在此,我们将神经调节信号的影响称为"可塑性控制"效应。
决定学习的另一个因素是选择性注意力,这很直观。也就是说,如果我们关注20-22,我们会学到更多。测试注意力在学习中的作用的正式方法是使用冗余的相关提示范式20,21,23,在该范式中,受试者通过反复试验来学习,以将刺激映射到反应上。在每个试验中,参与者都会看到多个刺激,这些刺激都可以提供所需的响应信息,因此很多信息都是多余的,但是参与者只关注其中一种刺激,而仅了解参与的刺激,而不了解无人参与的刺激。这一点很重要,因为无人值守的刺激与相同的行为反应配对,并且与人为的刺激与相同的RPE相关联。只有在特殊条件下,感知学习才会在没有注意力的情况下发生24——例如,如果刺激非常弱。 弱刺激似乎无法从注意力控制机制中逃脱,否则它们会抑制未注意项的可塑性25。
门控学习的注意信号可能来自选择行为反应的运动和额叶皮层的大脑区域。动作选择始终与注意力转移26相关联,注意力转移26通过反馈连接到达感觉皮层中的神经元,这些神经元编码引起动作的特征27。将注意力信号引入学习规则可以得出:
![]()
其中FBj是来自较高大脑区域的反馈,这些区域控制突触在神经元 j 上的可塑性。我们将FBj的效果称为"门控",因为它的值在0(未注意)和1(完全注意)之间变化,并且始终为正(与"转向"RPE信号不同,后者可以更改符号)。
图1说明了该学习规则的主要思想25,28。在前馈处理阶段29(图1),刺激信息首先从感觉皮层传播到运动皮层。运动皮层选择一个动作,并使用反馈连接突出显示为动作提供输入的较低层次皮层中的表征。反馈连接会诱导可塑性的突触标签(也称为资格迹)。标签的位置和强度取决于突触前和突触后活动fi(ai)和fj(aj)以及反馈FBj。在此框架中,不同的动作将激活不同的反馈连接,并导致突触标签的模式不同,从而确保将信度(或责备)分配给对刺激-反应映射至关重要的那些突触。标签应一直保留到RPE信号可用为止。信号传导计算的RPE的神经调节剂与标记的突触选择性地相互作用,以改变其强度。
公式3中描述的学习规则允许训练在感觉皮层和运动皮层之间具有许多层的网络。如果反馈连接强度与前馈连接强度成正比,则这种属性可能在学习过程中出现28,31,则学习规则等同于所谓的误差反向传播规则32,该规则用于训练具有多个层次的网络3。这种深度ANN在图像识别任务4和计算机游戏中已经获得了出色的,有时甚至是超人的性能33。因此,尽管以前认为误差反向传播规则在生物学上是不现实的34,但新的见解表明,公式3的学习规则可以由大脑实现以保证各种形式的深度学习(方框1)。
下面,我们回顾可能在公式3中启用学习规则的皮层皮质和皮层下皮质连接。然后,我们讨论了学习如何改变感觉皮层和联想皮层中刺激的表征,并回顾控制可塑性的机制。
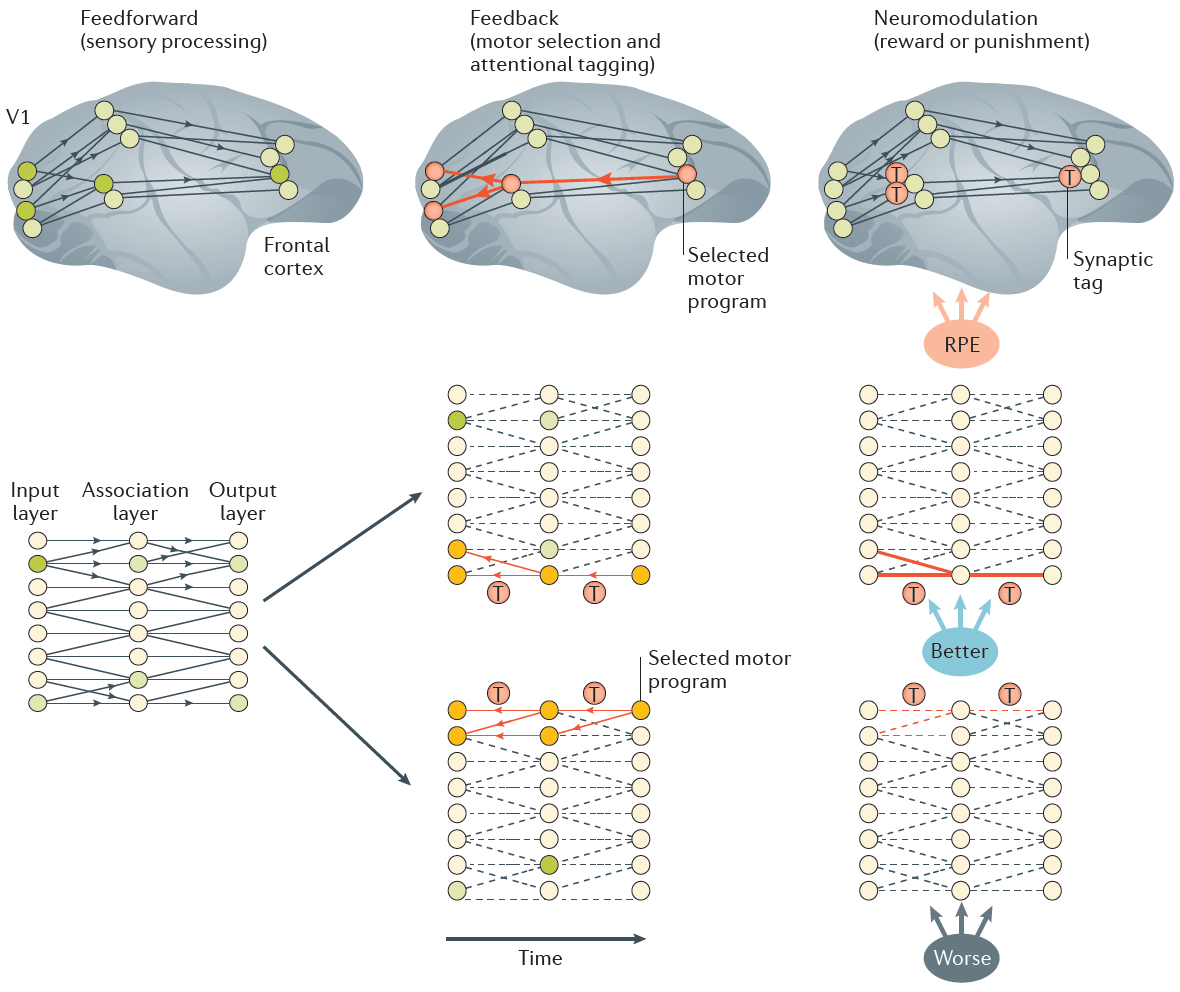
图1 | 可能影响突触可塑性的假定控制信号。在感官处理过程中(图左侧),前馈连接(黑色连接)将活动(由黑色箭头表示)从较低区域传播到较高区域。额叶皮层中的神经元竞争以确定所选的动作。如果选择某个动作,则"获胜"的神经元会向引起所选动作的较低层次突触提供注意反馈信号(红色连接),从而使其在与树突状细胞钙事件有关的过程中具有可塑性(中间图的一部分)。此启用称为"标记"(红色圆圈中的"T"表示标记的连接)。其他连接不是可塑的(在下一行的网络中为虚线连接)。请注意,不同的动作可以使如图所示的不同连接(网络的不同行)具有可塑性。神经调节剂编码奖励预测误差(RPE;即结果比期望好(蓝色)还是差(灰色)),并确定标记的突触强度是增加(红色粗线)还是降低(红色虚线)。V1,主要视觉皮层。下部面板经REF25,Elsevier许可进行改动。
Sensory and association cortex
皮层包含一个庞大的电路网络,用于局部和远程交互(图2a, b)。皮质区域由圆柱组成,不同区域的神经元亚型和局部连通性模式相似35,36。皮质区域可以以分层的方式排列,其中低阶皮质区域(图2b中的层次I)将信息转发到高阶区域(图2b中的层次II),而高阶区域可以将信息反馈回低阶区域37。当在层次结构中上升时,神经元感受野特性变得更加复杂37,38。皮质组织和连通性的原则在其他地方曾得到过出色的回顾39-46。在此,我们总结了皮质组织的关键方面,这些方面与前馈和反馈流有关,并且与理解分层网络中的可塑性规则有关。
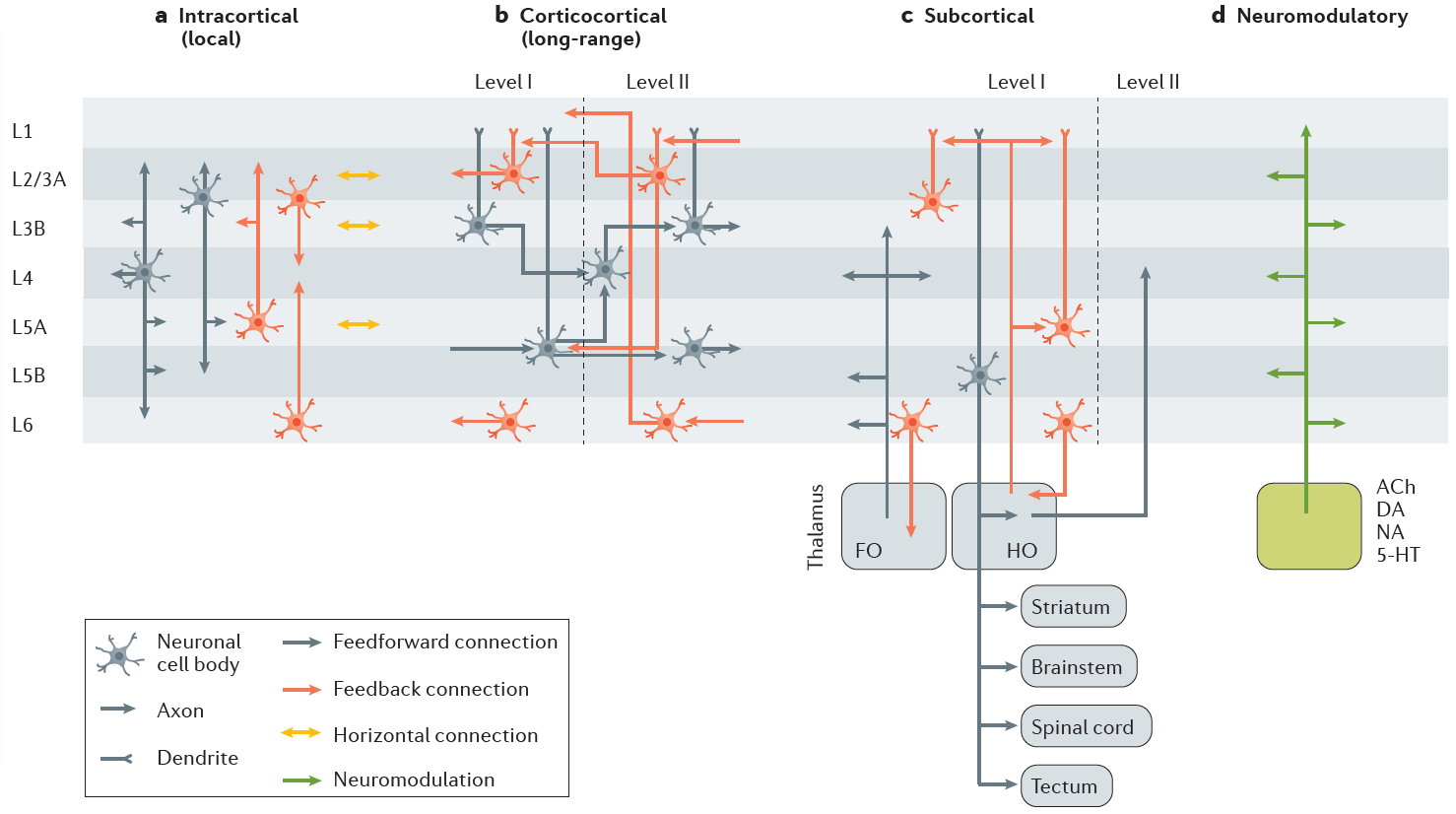
图2 | 皮质前馈,反馈和神经调节信息流。感觉皮层和联想皮层之间的皮质内(a部分),远距离皮层(b部分),皮层下(c部分)和神经调节(d部分)连接图。主要的轴突突触输入模式显示为箭头。皮质内信息流包括皮质柱内和之间的局部相互作用(a部分)。第4层(L4)和L2/3的输入通过上升和下降连接传播到所有其他层(L1除外)。水平连接在L2/3和L5A内分配信号,而从L6和L2/3到L4以及从L5A到L2/3提供反馈。皮质区域之间的信息交换是通过远距离皮层皮质连接和跨丘脑通路进行的(b和c部分)。一阶(FO)丘脑为下部皮质区域(c中的层次I)提供输入。皮质L5输出到达高阶(HO)丘脑,后者依次前馈至较高皮质区域(c中的层次II)或返回至低阶皮质(层次I)。前馈和反馈流被隔离在不同的层中,在灵长类动物中占很大的比例,在啮齿类动物中占一定的比例45,186。在灵长类动物中,较深的L3和浅表L5中的神经元向前突出到较高阶皮质区域的L4。浅表L2/3和较高区域的L5/6中的神经元向较低区域的L1和L5发送反馈投影43,56。在啮齿动物中,单独的前馈和反馈预测可能源自分子上不同的神经元亚型45,但它们在整个椎板中的分布类似于"盐和胡椒粉"186,187。L1是一个主反馈层,其中输入撞击在锥体神经元的顶端树突上。皮层的神经调节输入模式的特征仍然很差(d部分)。目前的观点认为,实际上所有类型的神经调节都到达所有皮质区域的所有层82,尽管胆碱能投影140,141观察到某些地形组织和层状特异性。神经调节信号通过突触传递和体积传递发生,并且在大多数情况下通过代谢型受体发生82,188。5‑HT,5‑羟基色胺(5-羟色胺);ACh,乙酰胆碱;DA,多巴胺;NA,去甲肾上腺素。来自REFS37,39,40,43,45,46的数据。
Feedforward and feedback connections
关于前馈和反馈输入在何处产生和终止的分层差异37,43(图2)。解剖和神经生理学研究表明,丘脑传递的感觉输入最初会激活灵长类动物感觉皮质中第4层(L4)和L6的神经元47–50,啮齿动物中L3和L5的输入也是如此51,52。然后,此输入迅速传播到其他层,以使所有层中的神经元都被感觉输入激活。皮层中有一个反馈系统,其中强烈的反馈来自L6,主要通过激活抑制性神经元来抑制活动53,54。
感觉区域还接收来自较高皮质区域的反馈连接,这些区域大部分为浅层(L1-L3)和L5的一部分提供输入(图2b)。因此,尽管区域间前馈输入的目标是L4,区域间反馈输入的目标是L2/3和L5锥体细胞的顶端簇56,57,以及抑制性58和去抑制微电路59,60。这些特征可能会对反馈连接在突触可塑性中的作用产生重要影响(如下所述)。
皮质区域也经由丘脑间接地彼此相互作用(图2c)。L5中投射到脑干的皮质神经元向高阶丘脑基质核(与一阶感觉特异性核心核相反)发送侧支,进而向高阶皮质区域的L4提供前馈输入39,61–63。此外,来自高阶丘脑核的投影还将信息反馈到低阶皮质区域57,64(图2c),在那里它们以L1和L5为目标(REFS61,65-67)。这些通过丘脑的前馈和反馈途径可以将周围的感觉信息68-71与联想和运动皮质的信息整合在一起39,64,72,73。
药理研究表明,前馈输入通过激活AMPA受体(AMPAR)来驱动突触后活动。相比之下,许多反馈连接的突触主要通过NMDA受体(NMDAR)74,75和代谢型谷氨酸受体39,76来调节发放率。与此相一致,小鼠高阶丘脑核的微刺激诱导皮质锥体神经元中强大的NMDAR介导的反应。与前馈连接的驱动作用一致,猴子的初级视觉皮层(区域V1)中的微刺激激活了较高区域V4中的神经元。相比之下,根据调节反馈效应,V4微刺激会影响视觉刺激引起的V1活动,但在没有视觉输入的情况下几乎没有影响。
Neuromodulation
所有皮质层均从多个深部脑核接收神经调节输入。这些系统包括腹侧被盖区的多巴胺能系统,血清素能神经的背核和内侧核(分别为DRN和MRN),蓝斑位置的去甲肾上腺素能投影和基底前脑的胆碱能传入神经(图2d)。这些调节系统提供有关唤醒状态以及奖励和惩罚的信息,并可能影响突触传递79和皮质状态80,81。重要的是,它们通过控制突触可塑性82-84(在下面讨论)在学习中发挥作用。
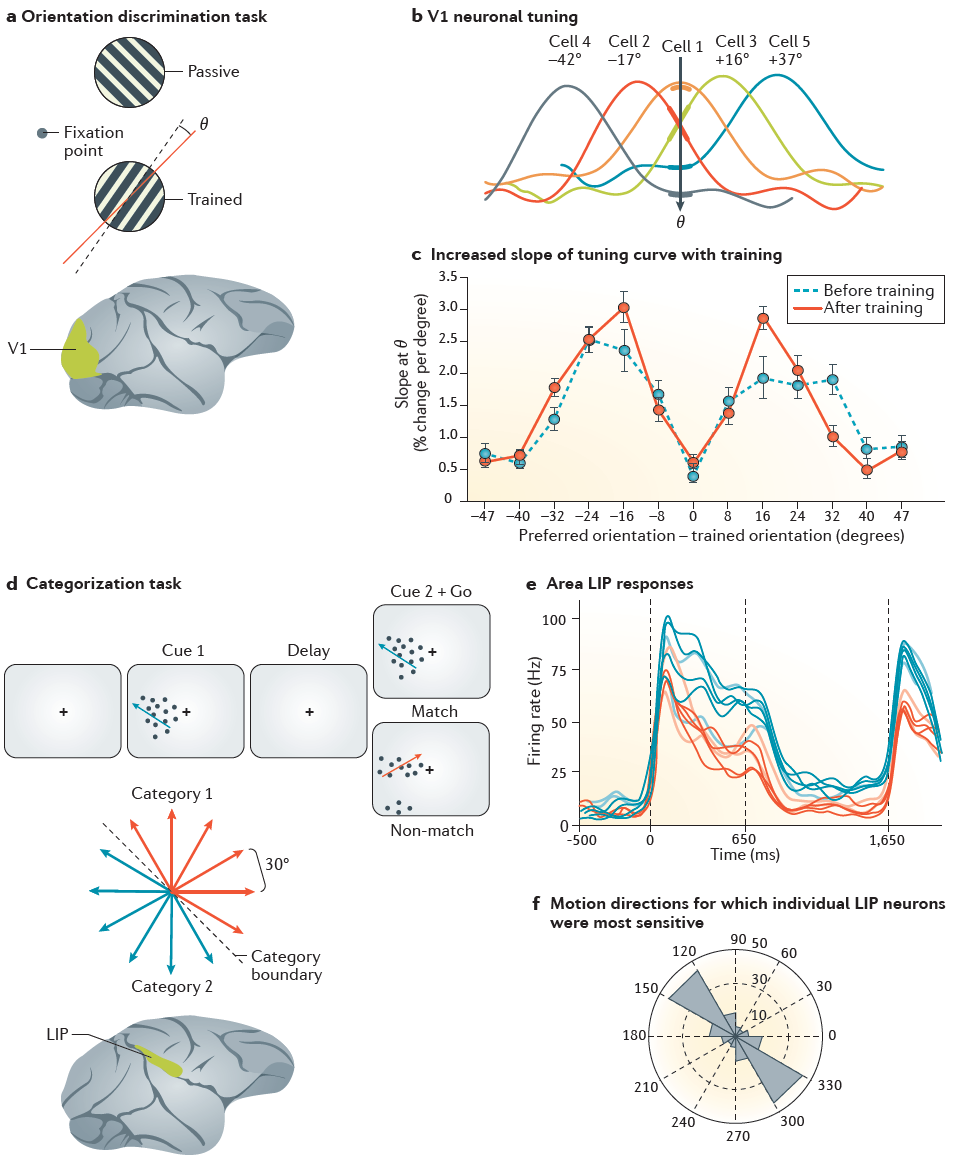
图3 | 学习对神经元调节曲线的影响。 a | Schoups et al. 89研究中的猴子判断下部光栅的方向是从右斜方向顺时针还是逆时针倾斜(红线,45°)。他们总是可以忽略上部格栅,因为它是干扰物。左侧的小圆圈表示注视点。b | 示例性初级视觉皮层(V1)神经元的方向调节曲线(黑色箭头指示训练的方向(θ))。粗线段突出显示了调节曲线在θ处的斜率。c | V1神经元调节曲线的斜率在θ处随神经元首选取向(每度取向的发放率变化百分比)而变化。在方向判断任务中进行训练会增加具有首选方向的神经元调节曲线的斜率,该方向与θ仅有微小的差异(约16°),并且对任务有最大的帮助。蓝色虚线表示训练前的调节曲线的斜率,而红线表示训练后的斜率。d | 在Freedman and Assad92的一项研究中,猴子看到点沿12个方向之一移动,这些方向分为2类(红色和蓝色箭头)。这些动物将样本刺激的类别(提示1)与后来的探针刺激的类别(提示2)进行了比较,并且在"go"信号时,如果类别相同,则释放杠杆。e | 由示例方向的顶壁内侧区域(LIP)神经元中的样本方向引起的活动。对于相同类别的刺激,神经元给出了相似的响应(红色对类别1的刺激做出响应,蓝色对类别2的刺激做出响应),但是刺激类别之间的活动差异更大。f | 相邻运动方向的分布在单个LIP神经元的刺激驱动活动中引起最大差异。请注意,对于大多数细胞而言,活动的最大变化发生在类别边界。a-c部分改编自REF89,Macmillan Publishers Limited。d–f部分改编自REF92,Macmillan Publishers Limited。
Cortical plasticity and learning
学习改变了大脑皮层85和皮层下结构86-88的许多区域中神经元的响应特性。在此,我们提供了关于学习对视神经89-91和联想皮质92的神经元调整刺激的影响的研究示例,证明神经元已被调整为具有重要作用的变异。
在一项研究中,Schoups et al. 89训练猴子执行定向识别任务。动物判断光栅刺激的方向相对于参考方向是顺时针还是逆时针旋转(图3a)。在训练开始时,猴子需要10°或更大的方位角才能可靠地执行任务。但是,经过数月的训练,它们以最小1°的方向差执行任务。训练的结果是,V1神经元在区分方向上的细微差别方面变得更好,这对于具有优选方向的神经元与训练后的方向仅稍有不同(例如,约15°)的神经元来说尤为明显(图3b)。对于这些神经元,训练的方向落在调节曲线的最高梯度部分上,训练增加了该部分的梯度(图3c)。在任务执行过程中,与任务无关的刺激暴露在另一个位置,并未引起神经元调节的相当变化。因此,仅仅呈现刺激并不会诱导可塑性。
Freedman and Assad92报告了联想皮层的相关影响。他们记录了经训练对运动刺激进行分类的猴子的外侧顶内(LIP)皮质中神经元的活动。猴子看到了刺激,这些刺激的点沿12个方向中的1个移动,并在"类别边界"的任一侧分为2个任意类别(图3d)。在每次试验中,猴子首先看到一个刺激样本并记住其类别,以便它们可以报告后来的刺激是属于同一类别还是另一个类别。图3e示出了对LIP神经元的调整,该LIP神经元对在一个类别的所有运动方向(图3d中的蓝色)上的运动比另一类别的任何方向(图3d中的红色)更强烈地响应。对具有相邻运动方向的刺激的响应的比较表明,跨越类别边界的成对的刺激观察到了发放率的最大差异(图3f)。因此,学习对刺激进行分类会导致神经元对类别边界的敏感性增加。这些结果提出了许多重要问题。
第一个问题是关于学习过程中变化的联系。在方向辨别任务中,V1调节曲线的锐化发生在L2/3和L5/6中,而不发生在L4(皮质的输入层)中。这些发现可能表明从L4到其他层的连接具有可塑性。然而,其他研究表明,在感觉皮层之间93以及感觉皮层与皮层下结构之间的连通性是可塑的86,88,94。在一项研究中86,受过训练以区分具有不同音高的听觉音调的大鼠显示出主要听觉皮层与纹状体之间的联系增强。在小鼠中进行的另一项研究表明,视皮层与辅助视神经系统之间的连接(控制视动反射的增益)在前庭皮病变后的可塑性88。因此,如Schoups et al. 89(图3a–c)所观察到的,皮质柱内连接的可塑性得到了其他连接类型的可塑性的补充。这些不同的连接类型对学习的可塑性的精确贡献似乎取决于任务,它们仍有待充分理解。
第二个问题是:感觉和关联区域的神经元如何调整到只能通过观察奖励结构(即取决于试验的刺激和选择)才能推断出的类别边界?一种可能的解决方案是,来自响应选择阶段的反馈连接通过标记负责动作选择的感觉皮质和联想皮质中的那些突触(即,放置资格迹;图1)来分配信度(或责备)。如果对动作进行奖励,则通过神经调节剂浓度的变化来增强标记的连接,所述神经调节剂浓度的变化促进突触增强(图1),以增加未来再次发生相同反应的可能性。如果动物做出了错误的选择,则来自编码该错误动作的神经元的反馈连接会标记另一组突触,这是由于神经调节剂浓度的变化以及缺乏奖励而导致强度降低的原因(图1)。反馈连接和神经调节剂之间的这种相互作用(在公式3的学习规则中正式化)可以解释在感觉和联想皮质中类别选择性的出现28,32,95(方框1)。
第三个问题涉及突触标签的身份及其与神经调节系统的相互作用。在感觉运动通路的活动与生物体评估反应的结果好于或差于期望的时间通常会有所延迟11。突触标签必须持续足够长的时间以弥合延迟。下面,我们回顾有关标签的分子身份和持久性以及它们如何与神经调节系统相互作用的初步见解。
Gating and steering plasticity
现在,我们讨论影响可塑性的因素,并区分那些门控可塑性和操纵可塑性的因素。我们提出通过将标记放在促进动作选择的突触上,从而将来自响应选择阶段门控可塑性的反馈信号,因此应对动作结果"负责"。相比之下,神经调节剂被提出以通过传递RPE来操纵可塑性,RPE为正,促进突触增强;RPE为负,导致突触抑制19。
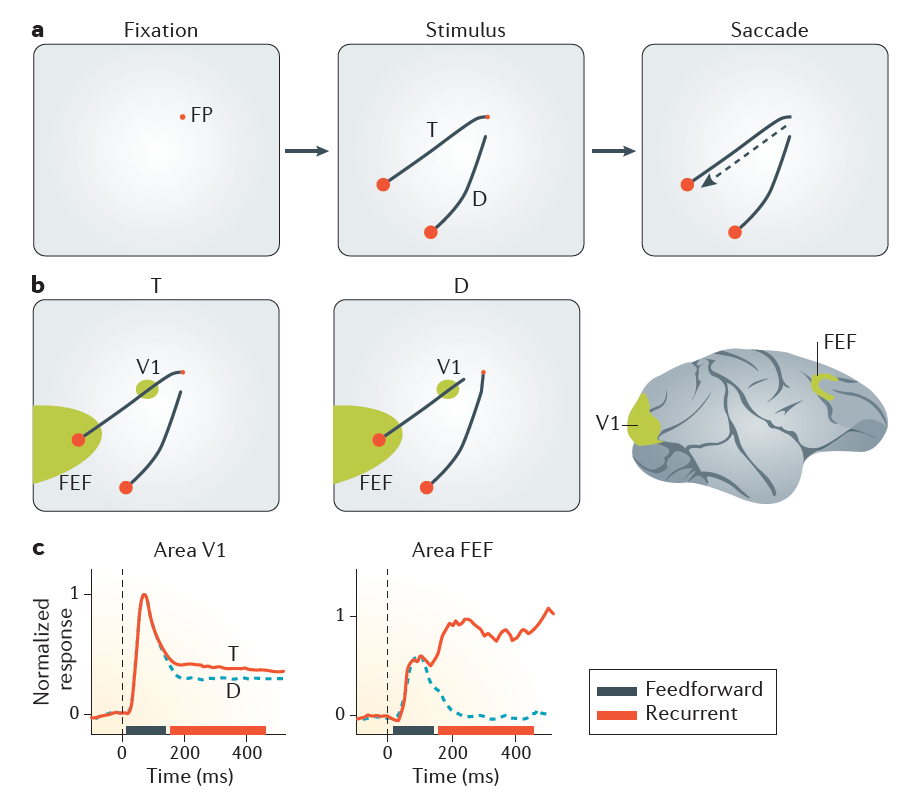
图4 | 在曲线跟踪过程中注意选择和眼睛移动选择。一个| 动物首先将视线指向一个小的固定点(FP)。 短暂的延迟后,屏幕上会出现两条曲线。 连接到FP的曲线是目标(T)曲线,另一条曲线是分散器(D)。 额外的延迟后,FP消失,猴子对先前连接到FP的较大的红色圆圈(即T曲线的末端)进行眼动。 b | 在左图中,初级视觉皮层(V1)和额眼视野(FEF)中神经元的接受场落在T曲线上,而在中图中,它们落在D曲线上。 c | 在初始前馈处理阶段(黑条)期间,区域V1和FEF中的神经元通过在其接受域中出现曲线(时间0处的黑色垂直虚线)而被激活。 在随后的循环处理阶段(红色条),反馈连接起作用,与眼睛运动响应的表示相比,在两个大脑区域中为眼睛运动反应选择的T曲线的表示现在得到了增强(红色线)。 未选择的干扰物(蓝色虚线)96。 c部分改编自《美国神经生理学杂志》,Khayat,P. S.,Pooresmaeili,A.和Roelfsema,P. R. 101,1813–1822(2009),并经美国生理学会批准(REF。100)。
Gating of synaptic plasticity
在动作选择,选择性注意和反馈连接对感觉皮层的影响之间存在强烈关系的证据来自心理学以及神经生理学。 心理学研究表明,眼睛或手臂的每一次视觉引导运动都与视觉注意力转移到运动目标有关。 此外,在非人类灵长类动物中进行的神经生理学实验表明,当动物计划对视觉对象进行扫视时,与未选择的刺激引起的活动相比,该对象在视觉和运动皮层中引起的神经元活动会增强27,96。视觉皮层中的这些响应增强是注意力转移到后续眼球运动目标的神经相关因素。
曲线跟踪任务很好地说明了动作选择和注意力之间的耦合(图4)。 在此任务中,猴子(或人类97)将视线指向固定点,并出现带有许多曲线的刺激。 曲线之一是目标曲线,并将注视点连接到较大的圆,该较大的圆是扫视的目标(图4a)。 猴子必须在精神上追踪目标曲线以找到扫视目标以便获得奖励,并且必须忽略其他会干扰目标的曲线。 曲线的出现激活了许多皮质区域的神经元,包括V1和额叶视野(图4b)。 在这些区域中的每个区域中,响应的初始部分由前馈处理控制,并且不能区分目标曲线和干扰曲线(图4c)。在此阶段之后,动物会在保持注视固定点的同时精神上追踪目标曲线。现在,反馈连接和水平连接有助于增强视觉曲线和额叶皮质96中目标曲线的表示(图4c)。 这种心理追踪导致的神经元活动的相对增加对应于目标曲线上注意力的分散98。 如果猴子错误地选择了牵张器曲线,并将其扫视到牵张器曲线末端的圆上,则在视觉皮层96、99、100(如图1所示)中,撑开器曲线的表示将得到增强。 因此,来自额叶皮层的注意力反馈信号增强了在关联和感觉皮层中激活的电路的活动,这是所选眼睛运动的原因。 因此,如果动作结果好于或坏于预期,则它们可以使应该改变的那些连接具有可塑性。
反馈途径可以通过两条途径标记突触的可塑性:通过皮层皮质反馈连接和/或通过丘脑。 两种途径均靶向表层和L5中的远侧树突(图2)。在猴子中,选择性注意不仅会增加视觉皮层101,102中神经元的活性,而且还会增加其高级别的视觉丘脑核103(相当于啮齿类动物的后丘脑外侧核)的神经元的活动。 肺泡的失活减少了视觉驱动的皮层活动104,并削弱了需要注意力转移的任务的表现103-105。 此外,肺部病变会干扰新的学习106。
为了支持门控假说,一项在小鼠中的研究77表明,高阶丘脑核中的活性确实会反馈到感觉皮层以控制门的可塑性。 研究人员从初级躯体感觉皮层(S1)进行了记录,并研究了通过须侧腹内侧后核(VPm)传递来自晶须的感觉信息的连接的可塑性(图5a)。 晶须的重复刺激在L2 / 3锥体细胞中诱导了长期增强(LTP)。 有趣的是,LTP的诱导依赖于后内侧核(POm)的活性,后内侧核是体感丘脑中高阶核的簇。外源性诱发的POm神经元活性在S1的L2 / 3神经元的远端树突中诱导了持久的(> 150 ms)NMDAR依赖性高原电位,可能是由钙流入引起的。 值得注意的是,仅当前馈输入与S1中的L2 / 3平台电位一致时,才会发生L2 / 3锥体细胞对晶须刺激的LTP。 用麝香酚阻止POm活性降低了S1高原电位并废除了S1 LTP。 还可以通过将NMDAR拮抗剂注射到S1中来阻断LTP,这也可以阻止钙流入远端树突中(图5b)。因此,显然需要反馈介导的依赖于NMDAR的平台电位来制备突触,该突触被具有可塑性的兴奋性前馈途径激活。
当来自感觉性脑干的上升驱动输入与来自S1的L5神经元的下降驱动输入一致时,啮齿动物中的POm神经元会变得活跃(参考文献68,69),但是尚不清楚POm是否将有关所选动作的信息传达给S1。 已知关于猴子的视觉形态的更多信息,在猴子的视觉形态中,鉴于上述注意和动作选择之间的关系,选择性注意会激活眼球,并可能特异性标记负责所选动作的皮质突触。
小鼠中的其他研究通过检查触觉刺激激活S1神经元的不同阶段(类似于曲线中V1响应的早期和晚期),证明了初级运动皮层(M1)的皮层皮质反馈连接对S1的直接影响。 -跟踪任务)。 S1反应的早期阶段由前馈感觉输入驱动,而后期活动还取决于来自较高皮质区域(包括M1)的反馈(参考资料107),这会导致平台电位和钙流入L5神经元的顶端树突107, 108。 有趣的是,后期S1活性109和钙流入S1树突中可预测动物(通过舔舔)110感觉刺激的报告,以支持运动皮层中的动作选择会引起感觉皮层上游效应的想法(图11)。 5c,d)。 此外,药理学或光遗传学抑制S1中晚期活性109或高原电位(参考文献110)会削弱舔response反应,特别是对于弱触觉刺激。 但是,与POm77的反馈一样,M1反馈是否也会影响S1中的可塑性。
可塑性的门控还可能取决于皮质柱中涉及血管活性肠肽(VIP)阳性中性神经元的去抑制性回路60,112,113。这些VIP +神经元接收来自多个来源的输入,包括来自高阶丘脑核114–116的反馈,并抑制生长抑素(SST)阳性的中间神经元,进而抑制锥体神经元59,117–119的活动。 SST +神经元在很大程度上与Martinotti细胞重叠,从而抑制了锥体神经元120的远侧树突的活动,靠近由高级丘脑核121–123反馈连接形成的突触附近。 当VIP +神经元抑制SST +神经元的活动时,它们可能因此使钙流入这些远端树突中,从而“打开”突触可塑性124-127。 确实,在小鼠中,SST +神经元的光遗传学抑制作用增强了一只眼睛的闭合诱导的V1可塑性。 此外,SST +神经元的光遗传或化学遗传沉默或它们的缺失促进了M1中学习驱动的可塑性(参考文献124,125)。
在老鼠的S1中观察到的反馈对高原电位,感觉知觉和可塑性的影响似乎可能会推广到其他感觉方式和其他物种。 最近显示,小鼠海马中的突触可塑性取决于平台电位128,并通过抑制作用来雕刻129。 在小鼠V1中,树突中依赖于NMDAR的钙事件增强了神经元130的刺激选择性。 此外,在猴子中,与V1的反馈连接以浅层和L5为目标,并激活NMDAR,以增加对行为重要的刺激的表示74。
上面审查的数据表明,反应选择会引起反馈信号,从而使上游突触具有可塑性。 这种门控假设提供了可能的机制,可以解释动物学习它们所参与的心理发现。 尽管我们专注于强化学习,但可以想象,注意力和反馈联系在无监督学习形式中具有同等作用,其中学习独立于行为结果77,131-133。 例如,对诸如“鸟”或“汽车”之类的抽象视觉概念的学习依赖于编码原始特征的较低视觉大脑区域与编码语义类别的较高视觉区域之间的交互。 也就是说,在无监督学习期间,较高区域的神经元可能会反馈以控制相关低级特征表示的突触可塑性。

图5 | 前馈连接到主要体感皮层的可塑性门控。一个| 实验示意图,显示了体感性丘脑皮质和皮层丘脑通路。 使用体内全细胞记录评估了2/3(L2 / 3)层神经元中晶须刺激驱动的感觉突触后电位(PSP)及其增强。 节律性晶须刺激(RWS)激活前腹(FF)输入(来自腹内侧后核(VPm))和反馈(FB)输入(来自后内侧核(POm))到初级体感皮层(S1),从而引起NMDA 受体(NMDAR)介导的锥体细胞电位。 POm的活动也受到其他皮质区域和不透明带的输入的控制。 b | 晶须偏转会在L2 / 3 S1神经元中诱导PSP,PSPs由两个部分(深蓝色电压迹线)组成:短时AMPA受体介导的去极化(PSPshort)和长时期高原去极化(NMDAplateau)。 平台组分可以通过NMDAR阻滞剂(例如d-2-氨基5-膦酸戊酸(d-AP5);浅蓝色电压迹线)或以muscimol注射剂为目标物(POm)进行阻挡(深绿色电压迹线;浅绿色) 显示了d-AP5和muscimol在一起后的电压曲线)。 如右图所示,这两种阻断NMDAR介导的平台电位的方法可防止晶须偏转引起的突触增强。 c | 晶须刺激检测任务的示意图以及S1中两个锥体细胞树突(#1和#2)中钙事件的成像。 d | 当晶须挠度接近检测阈值(θ)时,树突状Ca2 +事件在“命中”试验(动物检测到刺激并得到水奖励;在c部分的神经元#2)中比在“未命中”中更强 试验(其中动物未能检测到刺激并且没有奖励;如c部分的神经元#1),表明命中相关的FB输入(红色)参与了这些Ca2 +事件的产生(如神经元2所示)。 。 LTP,长期增强。 在获得REF许可的情况下,对a和c部分中的鼠标图进行了改编。 189,爱思唯尔。 b部分改编自REF。 77,麦克米伦出版有限公司。 d部分经REF许可改编。 110,AAAS。
Steering of synaptic plasticity
RPE应该控制可塑性。 也就是说,它应该确定标记的突触是增强还是抑制。 一个广泛持有的假设是RPE由释放的神经调节剂发出信号。 我们简要回顾了多巴胺能,胆碱能,血清素能和去甲肾上腺素能投射对皮层可塑性的可能影响,但我们注意到其他神经调节系统,例如组胺信号134和神经肽信号84也可能起作用。 除了在RPE编码中的作用外,神经调节剂的水平还可能表明其他行为状态,包括新奇,惊奇,唤醒和情绪化价17,18。 这些因素也可能通过影响神经调节剂的释放而影响可塑性。
Dopamine. 腹侧被盖区是皮质多巴胺的主要来源。 如果动物获得的奖励比预期的多135-137,许多但不是全部的多巴胺神经元就会活跃。 多巴胺投射物针对的是皮质层下结构,包括纹状体以及皮质,在前额叶和运动皮质中,投射物最密集,而在感觉区域则稀疏。 多巴胺能信号通过五种代谢型受体亚型发生,其中D1多巴胺受体(D1R)在皮质中含量最高。 D1R最终激活蛋白激酶A(PKA),这与长期可塑性密切相关。 此外,多巴胺可调节突触释放以及将AMPAR和NMDAR掺入细胞膜79。多巴胺调节纹状体14,海马17以及听觉皮层中的突触可塑性,其中特定音调与腹侧被盖区的电刺激配对会导致代表音调频率的皮层区扩大138。许多多巴胺神经元编码RPE,并能够控制含有多巴胺受体的结构的可塑性。 腹侧被盖区中的其他神经元除了RPE之外还编码了动机信号,并且可能在操纵可塑性中也起一定作用17,139。
Acetylcholine. 人们认为新皮层中的胆碱能信号在控制脑部状态,注意力和学习中具有重要作用。 觉醒期间和持续关注下胆碱能信号高度上调80。 基底前脑的胆碱能投射在大脑皮层中广泛分布,并显示出一个复杂的地形,与形态相关的组织140,141。乙酰胆碱在皮质中的作用是由代谢型毒蕈碱受体和离子型烟碱样受体介导的。 烟碱受体在某些丘脑皮层轴突142上突触前表达,在VIP +中神经元上突触后表达,后者也表达离子型5-羟色胺受体114,143。毒蕈碱受体在锥体细胞中突触前和突触后表达,它们在其中可能具有多种作用80。 小鼠胆碱能投射的光遗传激活增强了V1中神经元的视觉响应能力,并改善了定向判别任务的性能144。 许多胆碱能神经元对惩罚有反应,而少数也对意外的奖励有反应,这与RPE信号传导中的作用兼容146,146。 然而,其他行为因素,例如唤醒水平,也可能影响可塑性,因为它们与乙酰胆碱释放的变化有关。 胆碱能中枢的电刺激增强了小鼠的视觉皮层以及小鼠和大鼠的听觉皮层的可塑性147-151,而乙酰胆碱的消耗抑制了大鼠的听觉和体感皮层的突触可塑性151,152。 因此,胆碱能信号的药理阻断剂,或使用毒素使胆碱能纤维耗竭至颞叶,损害识别记忆和新感觉刺激的学习153,154,以及胆碱能核损伤损害空间学习155。 两者合计,这些结果表明胆碱能神经元可以引导皮质可塑性。
Serotonin. 5-羟色胺能系统被认为可以调节感觉加工、认知和情绪状态,并调节先天行为,如食物摄入和繁殖156。前脑几乎所有区域的5-羟色胺能投射源于脑干的两个头端5-羟色胺能簇-MRN和DRN156。在大脑皮层,5-羟色胺的作用是多种多样的,由大量的突触前和突触后代谢性和离子性受体83157介导。在其他因素156中,5-羟色胺能神经元的活动取决于预期和接受的奖赏或惩罚的数量158–163;然而,皮层中与奖赏相关的5-羟色胺能信号的作用仍不清楚。皮层5-羟色胺能输入的激活促进了AMPAR向突触的传递82,83,并在视觉剥夺期间锐化了大鼠的胡须桶图164。因此,5-羟色胺也影响皮层突触可塑性。
Noradrenaline. 去甲肾上腺素能信号与觉醒165和接受奖励性刺激166有关。去甲肾上腺素最重要的来源是蓝斑,它广泛投射到所有其他神经调节中枢,以及皮质的所有区域和层。蓝斑的活动影响各种认知和感觉过程165。例如,蓝斑的活动增强了丘脑和皮质的感觉诱发反应167168。去甲肾上腺素主要通过肾上腺素受体发挥作用,肾上腺素受体影响突触可塑性82169。此外,去甲肾上腺素能信号已被证明可诱导啮齿动物海马、杏仁核和新皮层的可塑性,并增强情境学习170、恐惧条件171和听觉感知167。
Spike-timing-dependent plasticity. 关于在大脑中实施强化学习的理论已经提出,神经调节剂的整体释放会影响可塑性,以确定未来是否会再次采取选定的行动16,19。它们可以通过改变突触(例如,通过改变受体的表面表达)或通过改变神经元的内在特性11、19、25、28169172来实现。一些研究探讨了不同的神经调节剂对突触时间依赖性可塑性(STDP)的影响,其中突触强度的增加或减少取决于突触前和突触后动作电位之间的精确时间间隔。这些研究表明,多巴胺、乙酰胆碱、去甲肾上腺素、血清素和内源性大麻素可以增加或降低神经元对STDP范式的敏感性,可以改变STDP功能的形状,甚至可以确定突触是否经历增强或抑制14,84132169173–175。因此,大量证据表明,神经调节系统控制着神经元的可塑性。然而,该领域尚未就这些神经调节系统(单独或联合)的相对重要性及其在可塑性控制中的确切作用达成共识。

图6 | 门控和操纵突触可塑性。 Aa | 在皮质柱内,反馈(FB)连接以远端树突以及可塑性的抑制电路为目标。 Ab | 前馈(FF)连接将活动传播到更高的水平,继而又为丘脑皮层突触提供FB,丘脑皮层突触将负责该动作的结果。 FB通过引起树突状钙事件来实现此目的,该事件会在激活的丘脑皮层突触(以及同一列中的其他突触)上诱导突触标签(由红色圆圈中的“ T”表示)。 交流电| 列的活动停止后,标签将保留。 广告| 奖励预测误差(RPE)引起神经调节剂的释放,以增加或降低标记突触的强度,影响将来选择相同动作的可能性。 Ae | 标记的突触现已增强。 B | 纹状体突触后棘中的分子事件序列。 谷氨酸(Glu)与NMDA受体(NMDARs)的结合通过钙的流入控制了可塑性。神经调节剂,例如多巴胺(DA),通过D1多巴胺受体(D1R),腺苷酸环化酶(AC),cAMP(被磷酸二酯酶(PDE)分解)和蛋白激酶A(PKA)激活另一条途径。 蛋白磷酸酶1调节亚基1B(PPP1R1B;也称为DARPP32)–蛋白磷酸酶1(PP1)信号传导。 两种途径都需要激活钙/钙调蛋白依赖性蛋白激酶II型(CAMKII)的激活,这会引起突触强度的增加(通过树突棘体积的增加来衡量)。 行动党,行动潜力; VDCC,电压依赖性钙通道。 B部分经REF许可改编。 14,AAAS。
Gating and steering together
皮质或丘脑皮质反馈连接与神经调节信号的结合可以确保突触更新所需的信息在经历可塑性的突触局部可用(方框1)。可以针对示例性强化学习场景(图6A)来说明这种可能性。首先,活动从感觉皮层传播到运动皮层,所选择的运动程序为早期的处理水平提供反馈。前馈和反馈通路的同时活动特别发生在负责的皮层柱中(图6A)。在这些柱中,皮质皮质和丘脑皮质反馈连接通过直接兴奋或通过间接VIP+神经元介导的去抑制诱导锥体树突中的钙事件。这些事件在激活的前向突触(也就是使其可塑性得以实现的生化修饰)处诱导合格性痕迹。一秒钟或几秒钟后,评估动作结果并计算RPE,然后控制可塑性。如果RPE为阳性(图6A),合格的突触会被神经调节剂增强,而RPE为阴性则会减弱。神经调节剂的释放可以从神经元的激活中及时分离出来,因为标记可以在没有神经元尖峰的情况下持续存在14174175。
事实上,合格痕迹的持续存在可能与在海马体中观察到的可塑性诱发事件之间的长期相互作用有关,并由此产生了“突触标记和捕获假说”(参考文献15176177)。根据这一假说,如果同一神经元的其他突触在数小时内发生更强烈的可塑性诱导事件,弱可塑性诱导事件会诱发突触标签,使这些突触发生可塑性。因此,其他突触的强增强导致可塑性相关蛋白的产生,这些蛋白被标记的突触捕获,从而也改变了它们的强度。突触标记与可塑性相关蛋白15176或编码RPE11,32的神经调节剂相互作用的假设并不相互排斥,并且这种相互作用可能在不同的时间尺度上发生(即,在强化学习中跨越几秒钟的延迟,在突触标记和捕捉中跨越几个小时)。未来的研究将致力于更好地描述作用于突触标签以控制可塑性的过程。
尽管我们以上集中于神经调节输入在转向可塑性中的作用,但一些研究表明,神经调节剂也可能通过改变神经元兴奋性178参与门控过程178,例如,通过改变突触前谷氨酸释放179或激活去抑制电路60,84112113117118。然而,值得注意的是,神经调节投射是相对分散的,这意味着它们所具有的任何门控功能都可能不如皮质皮质和丘脑皮质反馈连接的特异性强,后者更适合标记特定的相关突触。
与上述观点一致,最近的一项研究记录了突触标签的存在,这些标签使突触具有可塑性,并受到纹状体中神经调节物质的后期释放的影响。Yagishita等人14通过去老化谷氨酸盐激活切片中的单个神经元脊椎,同时通过注入电流使相同的细胞激发动作电位。如果多巴胺在事件发生后的1s内释放,激活的脊柱体积增加。这种增强依赖于NMDARs和几个细胞内信使的活性,以及多巴胺与D1R结合启动的通路中的延迟信号(图6B)。NMDARs和D1R下游的这两条通路汇聚激活钙/钙调蛋白依赖性蛋白激酶II(CaMKII),当突触前和突触后共同激活后释放多巴胺时,CaMKII最活跃。在海马脑片中,NMDAR依赖性可塑性和延迟多巴胺可用性之间也有类似的相互作用,间隔时间为180分钟。目前尚不清楚皮层神经元的突触中是否发生了类似的相互作用,尽管这可以用目前的技术进行测试。突触内的作用机制是复杂的;因此,我们期待着关于谷氨酸能传递和神经调节信号之间相互作用的许多发现还有待进一步研究。这些研究可以给我们提供新的视角,让我们了解注意力反馈信号和rpe如何相互作用,从而优化突触对行为的贡献。
Conclusions
近年来,研究人员在了解大脑神经回路在学习过程中是如何重新连接的方面取得了重大进展。在这里,我们集中讨论了感觉和联想皮质中表征的可塑性,回顾了一方面皮质皮质和丘脑皮质反馈连接作用和另一方面神经调节作用的证据。综合起来,这些因素可能允许学习规则,训练大脑皮层回路,以改善感官刺激的表现,以及将它们映射到适当的运动反应上。由此产生的学习规则可以通过大脑中的突触来实现,从而克服学分分配问题。我们简要地讨论了门控和控制因子如何影响控制突触增强或减弱的生化级联的新兴见解。未来的研究可以测试皮质和丘脑皮质的反馈是否标记了负责可塑性的刺激-反应映射的回路,并且可以阐明这些标记的身份以及它们如何使突触对神经调节信号敏感。尽管反馈连接似乎使前馈连接具有可塑性,但前馈连接和反馈连接之间的相互作用是以细胞精度发生还是以较粗的分辨率发生在例如皮层柱的水平上仍有待确定。此外,未来的研究可以考察除了强化学习外,门控和控制因素如何在场景中协同工作,考虑反馈连接和神经调节系统在检测新奇性和惊喜方面的作用。
尽管许多决定突触可塑性的过程仍有待发现,但令人鼓舞的是,我们已经达到了一个从分子水平,细胞和系统神经科学以及强化学习理论和深层人工网络相互联系,现在可能被整合到大脑学习的统一框架中。