郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!

Front. Neurorobot., (2018)
Abstract
生物智能利用冲动或脉冲来处理信息,这使那些能够在现实世界中感知并采取动作的生物格外出色,并且几乎在生活的各个方面都胜过最先进的机器人。为了弥补这一不足,神经科学、电子学和计算机科学领域新兴的硬件技术和软件知识使人们有可能设计出受大脑机制启发,由SNN控制的生物学上现实的机器人。但是,仍然缺少对基于SNN的控制机器人的全面调研。在本文中,我们调研了过去十年中用于控制任务的SNN领域的发展,并特别关注了快速出现的与机器人相关的应用。首先,我们从速度,能源效率和计算能力方面强调基于SNN的机器人技术的主要动力。然后,我们根据不同的学习规则对那些基于SNN的机器人应用进行分类,并将这些学习规则及其相应的机器人应用进行阐述。我们还简要介绍了一些现有平台,这些平台提供了SNN和机器人仿真之间的交互,以进行探索和开发。最后,我们以对基于SNN的机器人控制方面的未来挑战和一些相关的潜在研究主题的预测来结束调研。
Keywords: spiking neural network, brain-inspired robotics, neurorobotics, learning control, survey
1. INTRODUCTION
长期以来,生物的神秘生物智能一直吸引着我们探索其从感知,记忆,思考到产生语言和行为的能力。如今,由于人们越来越多地模仿这些结构和功能原理,科学家已经研究了大脑,机器人致动器和传感器如何协同工作,以自动执行复杂任务的机器人的操作,例如以自动驾驶汽车的形式(Schoettle and Sivak, 2014),仿生机器人(Ijspeert et al., 2007; Gong et al., 2016),协作型工业机器人(Shen and Norrie, 1999)。但是,为了获得更多的自主权并在现实世界中运行,应该进一步研究机器人的以下能力:(1) 通过通常传递高维数据的传感器感知环境;(2) 以低响应延迟和低能效处理冗余或稀疏信息;(3) 在动态且变化的条件下的表现,这需要自学能力。
同时,传统的控制策略和传统的ANN都无法满足上述需求。具体而言,利用数值技术,运动学和动力学方法的基于模型的传统控制方法通常无法适应未知情况(Ijspeert, 2008; Yu et al., 2014; Bing et al., 2017)。另一方面,尽管硬件进步使大型神经网络适用于现实世界中的问题,但传统ANN在进一步处理高计算要求方面仍存在困难。主要缺点如下。首先,训练ANN非常耗时(Krogh and Vedelsby, 1995),并且对于最先进的结构来说很容易花费几天的时间(Lee C.S. et al., 2016)。训练大规模网络在计算上是昂贵的[AlphaGo 1202 CPUs and 176 GPUs (Silver et al., 2016)],运行它们通常会产生高响应延迟(Dong et al., 2009)。其次,在传统硬件上使用大型网络执行计算通常也会消耗大量能量。例如,在自动驾驶汽车中,与人脑相比,计算硬件配置要消耗几千瓦,而人脑只需要20瓦左右的功率(Drubach, 2000)。尤其是在移动应用中,这些都是相当大的缺点,在这些缺点中,实时响应非常重要,并且能源供应受到限制。
在自然界中,信息是使用相对少量的脉冲及其精确的相对时间来处理的,足以驱动学习和行为(VanRullen et al., 2005; Houweling and Brecht, 2008; Huber et al., 2008; Wolfe et al., 2010)。因此,可以通过SNN来更真实地仿真大脑的基本机制,从而为机器人控制挑战提供有希望的解决方案。由于它们与大脑的功能相似,SNN具有在能量和数据方面以更好的方式处理信息和学习的能力,例如,建立大规模的大脑模型(Eliasmith et al., 2012)或使用神经学启发的硬件,例如SpiNNaker板(Furber et al., 2014)或动态视觉传感器(DVS) (Lichtsteiner et al., 2008)。此外,SNN为广泛的特定实现提供了解决方案,例如快速信号处理(Rossello et al., 2014),语音识别(Loiselle et al., 2005),机器人导航(Nichols et al., 2010)以及其他由non-SNN解决的问题,但实际上显示出更多的优势。然而,仍然缺少关于基于SNN的控制机器人的全面综述。
因此,在本文中,我们旨在调研自最近十年以来用于控制各种机器人应用的最新SNN建模,设计和训练方法。本文的总体动机是减轻机器人专家理解SNN复杂生物学知识的障碍,同时通过一些通用的基于学习的SNN方法启发读者来完成不同的机器人控制任务。这项调查的贡献是三方面的。首先,我们尝试阐述SNN在速度,能效和计算能力方面的优势。而且,我们概述了用于控制基于SNN的机器人任务的通用设计框架。然后,我们的调研旨在总结机器人任务中基于学习的SNN,包括建模,学习规则以及机器人实现和平台。我们通常根据不同的学习规则对选定的机器人实现方案进行分类,这会显示在学习信号的来源中,这些信号可以通过不同的方式获取,例如标记的数据集,中性刺激,来自环境或其他外部控制器的奖励。最后,我们试图指出在机器人任务中实现SNN所需要解决的开放主题。
本文的其余部分组织如下。在第2节中,将简要介绍SNN的理论背景,包括其生物学基础和基于学习规则的ANN的变化过程。第3节介绍了基于SNN的机器人控制的主要动机和研究框架。然后,我们将讨论从简单神经元单元到更高级系统的拓扑的SNN实现(第4节)。训练SNN进行控制任务的各种方法将基于其相应的机器人应用被分类和解释(第5节),以及用于探索神经机器人的现有平台(第6节)。最后,我们将在第7节中概括未来的挑战和潜在的研究主题,并在第8节中进行总结。
2. THEORETICAL BACKGROUND
在深入研究基于SNN的机器人控制之前,有必要简要概述一下人类神经系统中发生的生物学机制。因此,本节是理论基础以及以下各节中使用的词汇的简短摘要。在Vreeken (2003), Ghosh-Dastidar and Adeli (2009), Ponulak and Kasinski (2011)以及Grüning and Bohte (2014)中可以找到有关SNN的深入介绍。
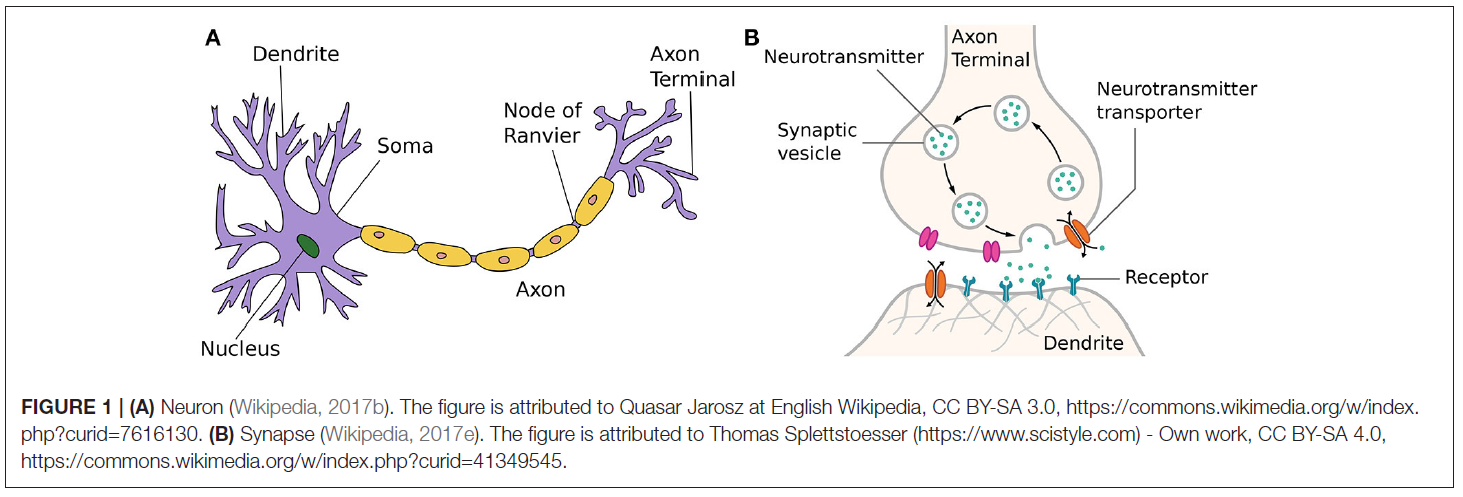
2.1. Biological Background
即使今天对人脑的理解仍然是不完整和充满挑战的,在过去的几十年中已经对我们的神经结构有了一些见解。自20世纪初Santiago Ramón y Cajal最初发现神经元是神经系统的基本结构以来,人们就已经提出了关于神经元如何工作的粗略概念。从根本上讲,神经元可以理解为将电能的短脉冲形式的输入信息处理为输入信号的简单构件。通过将神经元连接到巨大的网络,可以产生复杂的动态,以处理信息并理解我们的世界。这个基本概念可以在大自然中找到,从简单的生物(如具有数千个神经元的水母)到人类,在我们的神经系统中平均估计有860亿个神经元(Herculano-Houzel, 2012)。
嵌入咸细胞外液中的人脑典型神经元结构如图1A所示。来自多个树突的输入信号改变了神经元膜电压。当达到阈值时,细胞体或胞体自身发出动作电位(也称为脉冲)。这种产生短时(1ms)电压突然增加的过程通常称为神经元的脉冲或发放。发放后,紧随其后的是一个短暂的非活动期,称为不应期,在此期间,神经元无法发出其他脉冲信号,而与任何输入信号无关。
一旦达到膜电位阈值并发放神经元,生成的输出脉冲将通过神经元的轴突传递。这些可以长得很长,最后延伸到许多其他神经细胞。
在轴突末端,输入信号被传输到其他神经细胞,例如其他神经元或肌肉细胞。现在有证据表明,突触实际上是神经元中最复杂的部分之一。除了传递信息外,它们还充当信号预处理器,在学习和适应许多神经科学模型中扮演着至关重要的角色。当横穿的脉冲到达轴突末端时,它可能导致突触小泡向突触前膜迁移,如图1B所示。在突触前膜,被触发的囊泡将与膜融合,并将其储存的神经递质释放到充满细胞外液的突触间隙中。扩散到该间隙后,神经递质分子必须到达间隙的突触后侧并与之结合的匹配受体。直接或间接地,这导致突触后离子通道打开或关闭。产生的离子通量引发级联,该级联遍历树突状树向下到达体细胞的触发区,从而改变了突触后细胞的膜电位。因此,不同的神经递质会对突触后神经元的兴奋性产生相反的影响,从而介导信息传递。这些使突触后细胞或多或少发放动作电位的可能性的作用分别称为兴奋性突触后电位或抑制性突触后电位。突触后电位对释放的神经递质的不同数量和类型以及所激活的离子通道数量的依赖性通常简称为突触功效。一段时间后,神经递质分子再次从其受体释放到突触间隙中,或者被重吸收到突触前轴突末端,或者被细胞外液中的酶分解。
突触作为信号预处理器的特性,特征和能力(例如,囊泡展开或再生的机会以及受体的数量)不是固定的,而是始终根据其自身和外部影响的短期和长期历史而变化。细胞外液中的神经激素可以暂时影响突触前和突触后末梢,即通过增强囊泡再生或阻止神经递质激活离子门受体来实现。所有这些改变传入突波对突触后膜电位的影响的效应通常称为突触可塑性,并构成神经和计算机科学中大多数学习模型的基础。
2.2. From McCulloch-Pitts to Backpropagation
1943年,神经生理学家Warren McCulloch和数学家Walter Pitts撰写了一篇有关神经元如何工作的理论论文,描述了使用电回路的简单神经网络模型(McCulloch and Pitts, 1943)。这些第一代神经网络能够通过布尔输出执行数学运算,一旦在神经元中达到总输入信号的阈值,就会触发二值信号。它们已成功应用于强大的ANN,例如多层感知器和Hopfield网络(Hopfield, 1982)。
随着更强大的计算的出现,此概念后来通过引入连续的激活函数(例如sigmoid (Han and Moraga, 1995)或双曲正切函数)进行扩展,以处理模拟输入和输出。实际上,已经证明具有足够大的具有连续激活函数的神经网络可以通过改变其突触权重来改变网络信息流,从而很好地近似任意模拟函数(Hornik et al., 1989)。通过对误差函数使用梯度下降来利用连续激活函数的最常用且最强大的监督学习算法称为反向传播(Hecht-Nielsen, 1992)。
然而,第二代神经元并不建模生物学上已经描述过的电脉冲,它们的模拟信息信号实际上可以解释为抽象的发放率编码。在一定时间段内,可以使用平均窗口机制来编码脉冲发放率转换成模拟信号,使这些模型在生物学上更有意义。
2.3. Spiking Neural Networks
继其生物学对应后,引入了第三代神经网络(Maass, 1997, 2001),该神经网络通过单个脉冲序列直接进行通信。它们使用脉冲编码机制代替抽象的信息信号,该机制允许合并时空信息,否则这些时空信息将由于平均脉冲频率而丢失。显然,这些神经网络模型被称为Spiking-Neural-Networks (SNN),可以理解为对第二代神经网络的扩展,并且实际上可以应用于由non-SNN解决的所有问题(Fiasché and Taisch, 2015)。从理论上讲,这些模型比感知器和sigmoidal门更强大的计算能力(Maass, 1997)。
由于其与生物神经元的功能相似性(DasGupta and Schnitger, 1992),SNN已成为分析大脑过程的科学工具,例如,有助于解释人脑如何在极短的时间内处理视觉信息(Chun and Potter (1995)。此外,SNN有望为应用工程中的问题提供解决方案,并为第二代神经网络提供省电且低延迟的替代方案,例如用于机器人技术(Lee J.H. et al., 2016)。
3. PRIMARY MOTIVATION AND FRAMEWORK
在本节中,我们将从多个方面简要介绍基于SNN的机器人控制的研究动力,还介绍了一般组织用于机器人实现的SNN的核心点和主要框架。
3.1. Primary Impetuses
作为第三代神经网络模型,SNN受到越来越多的关注,并逐渐成为神经科学和机器人技术的跨学科研究领域。为了清楚和简单起见,可以很好地总结适用于机器人控制器的SNN的迷人特征。
3.1.1. Biological Plausibility
从神经科学的角度来看,SNN像真实的神经元一样,通过直接使用交流和计算中的单个脉冲序列再次提高了生物真实水平(Ferster and Spruston, 1995)。最近几年积累的实验证据表明,许多生物神经系统使用单动作电位(或"脉冲")的时序来编码信息(Maass, 1997),而不是传统的基于发放率的模型。在Walter et al. (2015a),解释了SNN中时间的精确建模如何作为基于神经生物学原理的强大计算的重要基础。
3.1.2. Speed and Energy Efficiency
尽管进行了硬件升级,使大型神经网络适用于实际问题,但通常不适用于能源和计算资源有限的机器人平台。由于SNN能够发送和接收仅由几个脉冲的相对时序编码的大量数据,因此这导致非常快速且有效的实现的可能性。例如,实验表明,尽管从视网膜到颞叶至少涉及10个突触阶段,但人类可以在100ms内完成视觉模式分析和模式分类(Thorpe et al., 2001)。另一方面,就能源效率而言,维持神经系统足够的运作以执行各种任务需要持续的能源供应(Sengupta and Stemmler, 2014)。然而,人脑仅需要非常低的功耗,即大约20W的功耗(Drubach, 2000)。
3.1.3. Computational Capabilities
最近,已建立的体内实验表明,SNN能够使用相对少量的脉冲来充分处理信息,以驱动学习和行为(VanRullen et al., 2005; Houweling and Brecht, 2008; Huber et al., 2008; Houweling and Brecht, 2008); Wolfe et al., 2010);同时,它们还可以处理包含多达一万亿个神经元的大规模网络,例如大象(Herculano-Houzel et al., 2014)。此外,在利用时序信息方面,SNN优于non-SNN,它指的是事件的精确时序,以令人难以置信的精确度和准确性来获取准确的信息。例如,谷仓猫头鹰的听觉系统能够在水平面中以1-2度的精度定位声源,这相当于左耳和右耳声波到达的时差仅为几微秒(5μs) (Gerstner et al., 1999)。
3.1.4. Information Processing
SNN使用脉冲编码机制,代替抽象的信息信号,该机制允许合并时空信息,否则这些时空信息将通过仅对脉冲频率求平均而丢失。这种在动态环境中学习和行动的能力,具有丰富的时序信息,对于寻求执行类似任务的生物系统和人工系统来说,这是必要的素质。神经生物学家使用电鱼作为模型来研究从刺激编码到特征提取的过程(Gabbiani et al., 1996; Metzner et al., 1998)。他们发现,尽管锥体细胞不能准确传达有关刺激时间过程的详细信息,但它们可以通过脉冲爆发可靠地编码随机调节的上下冲程。另外,被称为"动态绑定"的问题充其量仍然难以在神经网络中实现(在装配体中同时使用不同类型的传感器信息)。SNN能够以高效且位置不变的方式有效地检测大型输入网格上任何位置的图元(特征)的结合。诸如数据分类和图像识别任务之类的例子可以在Hopfield (1995),Thorpe et al. (2001), Bohte et al. (2002), Guyonneau et al. (2004)和Shin et al. (2010)的文章中找到。
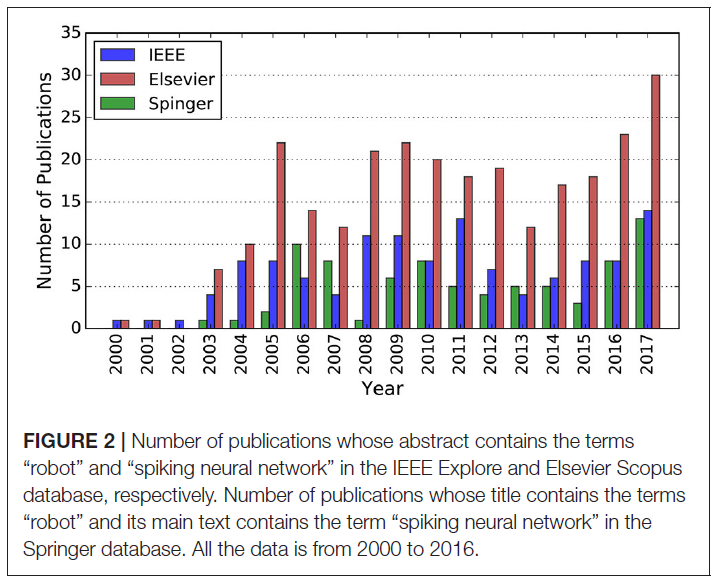
总之,这些有趣的特征使SNN适合于实现机器人实现的自主性。但是,由于SNN只是在理论层面进行研究,而不是被广泛应用于实际的机器人应用中,因此存在隐性的知识鸿沟。即便如此,对SNN不断增长的知识及其日益普及的应用始终吸引着越来越多的研究关注,并导致越来越多的基于SNN的实现,如图2所示。

3.2. Research Directions
SNN的主要研究方向集中在三个方面:SNN建模,训练和实现,在以下各节中将与其他参考资料一起详细讨论或简要介绍。图3显示了一个受学习启发的机器人控制的通用设计框架。大多数追求自主的机器人控制任务可以描述为一个包括三个步骤的循环,即感知,决策和执行(Gspandl et al., 2012)。机器人通常使用其传感器和执行器来感知环境并与环境互动,但是SNN可以被视为做出决策的大脑,它通过从环境中获取编码信息并输出解码后的机器人电机命令来建立感知与执行之间的桥梁。具体来说,首先,应该确定SNN的结构和数学模型,包括神经元和突触。已知神经元是神经系统的主要信号单元,并且突触可以看作是在神经元之间进行通信的信号传输器。因此,对SNN进行建模对于表征其特性非常重要。然后,应该像传统神经网络一样,使用特定的参数和学习规则对SNN进行初始化和训练。选择合适的学习规则将直接影响网络的性能。对于SNN,最常见的学习规则是Hebbian规则,将在下一节中对其进行说明。最后,在成功训练SNN之后,应在其他情况下对其进行验证,并在必要时进行优化。
4. MODELING OF SPIKING NEURAL NETWORKS
在构建用于机器人控制的SNN的最开始,应确定适当的SNN控制模型。基本任务是确定SNN的一般拓扑结构以及SNN每一层中的神经元模型。
4.1. Neuron Models
通常,神经元模型能够以常微分方程的形式表示。在文献中,提出了脉冲神经模型的许多不同的数学描述,它们使用内部状态变量来处理兴奋性和抑制性输入。用于SNN的最具影响力的模型是Hodgkin-Huxley模型(Hodgkin and Huxley, 1952)以及IF模型及其变体(Burkitt, 2006)。为了在现有的各种神经元模型中找到合适的模型,通常需要在生物学合理性和复杂性之间进行折衷。脉冲和爆发模型的神经计算特性的详细比较可在Izhikevich (2004)中找到。
使用最广泛的模型之一是所谓的LIF模型(Stein, 1965),可以用电学原理轻松解释。这些模型基于这样的假设,即脉冲时间(而不是特定形状)承载着神经信息(Andrew, 2003)。发放时间的序列称为脉冲序列,可以描述为:
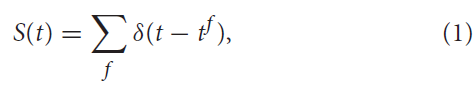
其中f = 1, 2, ... 是脉冲的标签,而δ(·)是狄拉克函数,定义为:
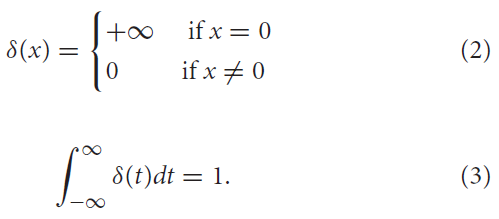
通过简化的突触模型,传入的脉冲序列将触发突触电流进入突触后神经元。由突触前脉冲序列Sj(t)诱发的该输入信号i(t)可以(用一种简单的形式)用指数函数描述(Ponulak and Kasinski, 2011):
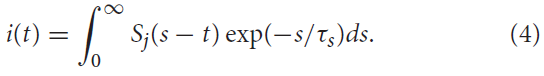
在此,τs表示突触时间常数。该突触传递可以通过低通滤波器动态建模。
突触后电流然后为LIF神经元模型充电,从而根据下式增加膜电压u:
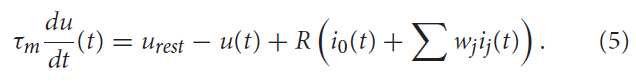
其中τm = RC是神经元膜时间常数,根据电阻R对电压泄漏建模。urest是每次重置后的电压值。i0(t)表示驱动神经状态的外部电流,ij(t)是第 j 个突触输入的输入电流,wj表示第 j 个突触的强度。一旦膜电位u达到特定的发放阈值ϑ,神经元就会发放单个脉冲,并且其膜电位重新设置为urest。通常,在发生脉冲事件之后是一个不应期,在此期间神经元保持不活动状态,无法再次充电。
值得指出的是,生物学研究突显了大脑中存在另一个可操作的单位细胞组装体(Braitenberg, 1978),它们被定义为一组具有强大的相互兴奋性连接的神经元,并且倾向于被整体激活。关于脉冲神经元模型的更深入的综述可以在Andrew (2003)中找到。
4.2. Information Encoding and Decoding
术语"神经编码"是指表示来自物理世界的信息(例如,运动刺激的方向)与神经元的活动(例如,其发放率)有关。另一方面,信息解码是一个反向过程,用于将神经元活动解释为执行器(例如肌肉或运动)的电信号。大脑如何编码信息要考虑两个空间:物理空间和神经空间。物理空间可以是目标的物理属性,例如颜色,速度和温度。神经空间由神经元的属性组成,例如大多数情况下的发放率。
已经提出了许多神经信息编码方法,例如二值编码(Gütig and Sompolinsky, 2006),群体编码(Probst et al., 2012),时序编码和最常用的发放率编码(Urbanczik and Senn, 2009; Wade et al., 2010)。对于二值编码,仅将神经元建模为采用两个值(开/关),但它完全忽略了时间性质和脉冲的多重性。由于简单,此编码机制已用于早期实现中。此外,二值编码还用于表示图像的像素值(Meschede, 2017)。对于发放率编码,这一发现受神经元趋向于更频繁地发放以产生更强的(感官或人工)刺激的观察启发。科学家通常在概率论中使用一种称为Poisson过程的概念来仿真具有与真实神经元接近的特征的脉冲序列。作为最直观和最简单的编码策略,大多数机器人实现都采用了发放率编码。对于时序编码,神经科学的证据表明,脉冲时序可以非常精确且可重现(Gerstner, 1996)。通过这种编码策略,信息以脉冲发生的时间表示。但是,其潜在机制仍不清楚。先前所述的编码方案通常是针对单个神经元的。但是,有时会使用大量的神经元来编码信息。这由生物大脑强烈支持,大脑的功能由一个区域的神经元群体控制。
神经解码的目的是表征神经元的电活动如何在大脑中引发活动和反应。最常用的解码方案是基于发放率的,其中较强的神经元活动通常表示较高的运动速度或力量。在Kaiser et al. (2016)中,根据输出神经元的脉冲数,提出了一种基于激动剂-拮抗剂(agonist-antagonist)肌肉系统的方向盘模型。
4.3. Synaptic Plasticity Models
一旦确定了神经元模型,就应仔细选择突触模型以连接SNN层内部和层之间的神经元。通过影响每个连接神经元的膜电位,首先在理论分析的基础上提出突触可塑性作为学习和记忆的机制(Hebb, 1949)。到目前为止,用于实际实现的突触可塑性模型通常非常简单。基于神经元活动和突触可塑性之间的输入-输出关系,它们大致分为两种类型,即基于发放率和基于脉冲,它们的输入变量类型不同。
4.3.1. Rate-Based
发放率的第一个也是最常用的定义是指随时间变化的脉冲计数均值(Andrew, 2003)。基于发放率的模型是一种将常规ANN转换为SNN的流行方法,仍然可以通过反向传播对其进行训练。它已成功地用于许多方面,尤其是在感觉或运动系统的实验中(Adrian, 1926; Bishop, 1995; Kubat, 1999; Kandel et al., 2000)。
4.3.2. Spike-Based
Gerstner et al. (1993), Ruf and Schmitt (1997), Senn et al. (1997), Kempter et al. (1999)和Roberts(1999)开发了基于脉冲的学习规则。实验表明,突触可塑性受单个脉冲的确切时间的影响,特别是受其顺序的影响(Markram et al., 1997; Bi and Poo, 1998)。如果突触前脉冲先于突触后脉冲,则可以观察到突触强度的增强,而相反的顺序则导致抑制。这种现象因正好相反的作用而被称为STDP或anti-STDP,并解释了神经系统的活动依赖性发展。换句话说,可能有助于神经元兴奋的神经输入得到加强,而不太可能有助于神经元兴奋的输入被削弱。在神经工程方面,STDP已证明已成功地实现为仿真和现实环境中的机器人和其他自主系统中的基础神经学习机制。
过去,例如,Gerstner and Kistler (2002)提出了STDP的不同数学模型。对于这项工作,将STDP下(作为突触前和突触后脉冲之间时差的函数)的权重更新规则定义为:
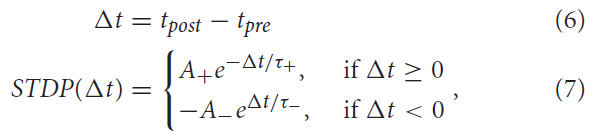
其中A+和A-分别代表增强和抑制强度的正常数。τ+和τ-是定义正负学习窗口宽度的正时间常数。要更深入地了解STDP机制的影响,读者可以参考Song et al. (2000), Rubin et al. (2001)以及Câteau and Fukai (2003)。
Diehl and Cook (2015)显示了用于MNIST分类的基于发放率和基于脉冲的SNN的比较。
4.4. Network Models
SNN网络模型类似于突触模型,因为它仿真了神经元之间的突触相互作用。由这些类型的神经元组成的神经网络的典型示例分为两大类:
4.4.1. Feed-Forward Networks
作为第一种也是最简单的网络拓扑,前馈网络中的信息始终从输入节点(通过隐含节点(如果有))传播到输出节点,并且永远不会向后传播。在生物神经系统中,主要发现抽象的前馈网络来获取和传输外部信息。因此,类似地,这种类型的网络通常用于机器人系统中的低级感官获取,例如视觉(Perrinet et al., 2004),触觉(Rochel et al., 2002)和嗅觉(Cassidy and Ekanayake, 2006)。例如,受到灵长类动物视觉皮层的结构和原理的启发,Qiao et al. (2014, 2015, 2016)利用记忆、关联、主动调整、语义和回合式特征学习能力等增强了分层最大池化(HAMX)模型和卷积深度信念网络(CDBN)等前馈模型,在视觉识别任务中取得了良好的结果。
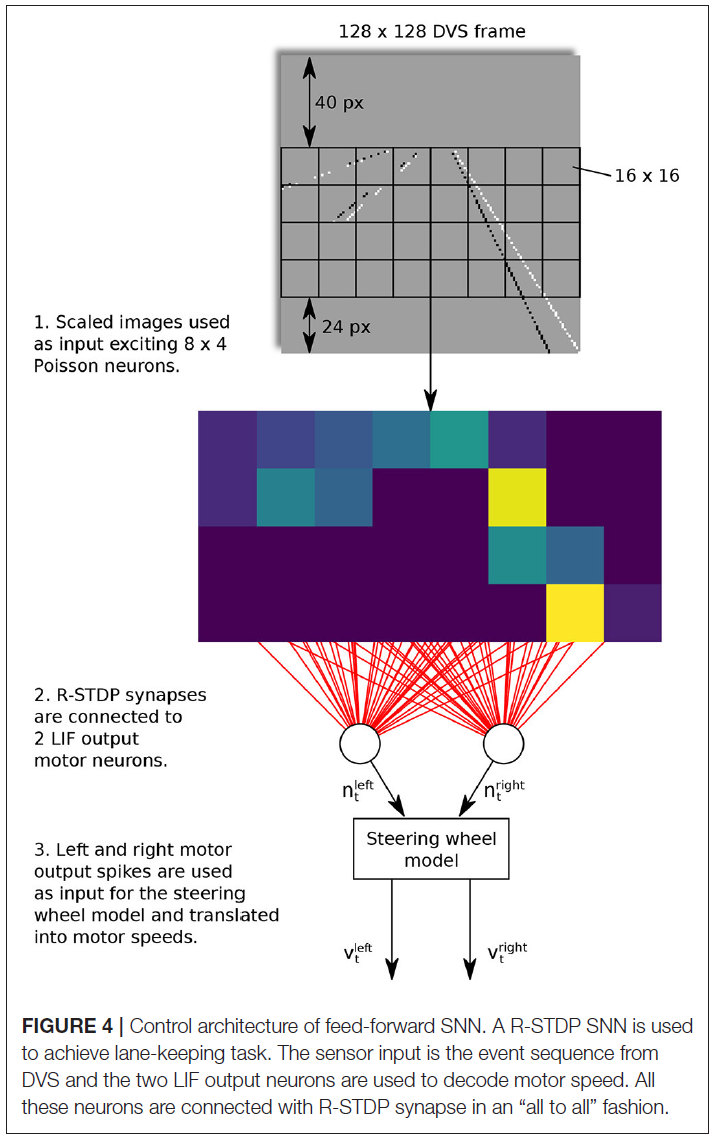
以Meschede (2017)的工作为例,对两层前馈SNN进行了车道保持车辆的训练。控制方案如图4所示。在这项工作中,动态视觉传感器(DVS)用于通过生成一系列事件来检测地面标志。输入层由8×4个Poisson神经元组成,并以"all to all"方式连接到具有R-STDP突触的两个LIF输出运动神经元。学习阶段是通过反复训练和从内车道和外车道的起始位置切换机器人来进行的。与其他三种学习方法,即深度Q学习(DQN),DQN-SNN和Braitenberg Vehicle相比,R-STDP SNN在不同车道场景中表现出最优的准确性和适应性。
4.4.2. Recurrent Networks
与前馈网络不同,RNN以定向循环传输其信息并表现出动态的时间行为。值得指出的是,RNN是具有特定结构(例如线性链)的递归神经网络(Wikipedia, 2017d)。活的生物似乎使用这种机制来处理输入的任意序列,并将其内部存储器存储在RNN中。至于机器人技术的实现,RNN被广泛用于视觉(Kubota and Nishida, 2006),规划(Soula et al., 2005; Rueckert et al., 2016)和动态控制(Probst et al., 2012)。
在Rueckert et al. (2016)中,提出了一个循环SNN来解决计划任务,它由两个神经元群体组成,即状态神经元群体和上下文神经元群体。(请参见图5) 状态神经元群体由K个状态神经元组成,它们控制自由移动目标的所有状态。在他们的有限视野规划任务中,智能体空间位置由九个状态神经元控制。这些状态神经元通过R-STDP突触相互连接,并与上下文神经元群体连接。上下文神经元产生时空脉冲模式,这些模式代表高级目标和上下文信息。在这种情况下,其平均发放率代表不同时间步骤下的目标空间位置。仅当智能体通过两个障碍时才收到最终奖励,一个障碍在T/2时刻,一个障碍在T时刻。它们表明,可以使用状态神经元遵循赢家通吃(WTA)动态的网络中的奖励调节更新规则来学习最优规划策略。由于这种可能性,在每个时间步骤中,只有一个状态神经元处于活动状态,并编码智能体的当前位置。他们的结果证明了使用循环SNN的成功的规划者轨迹规划任务。
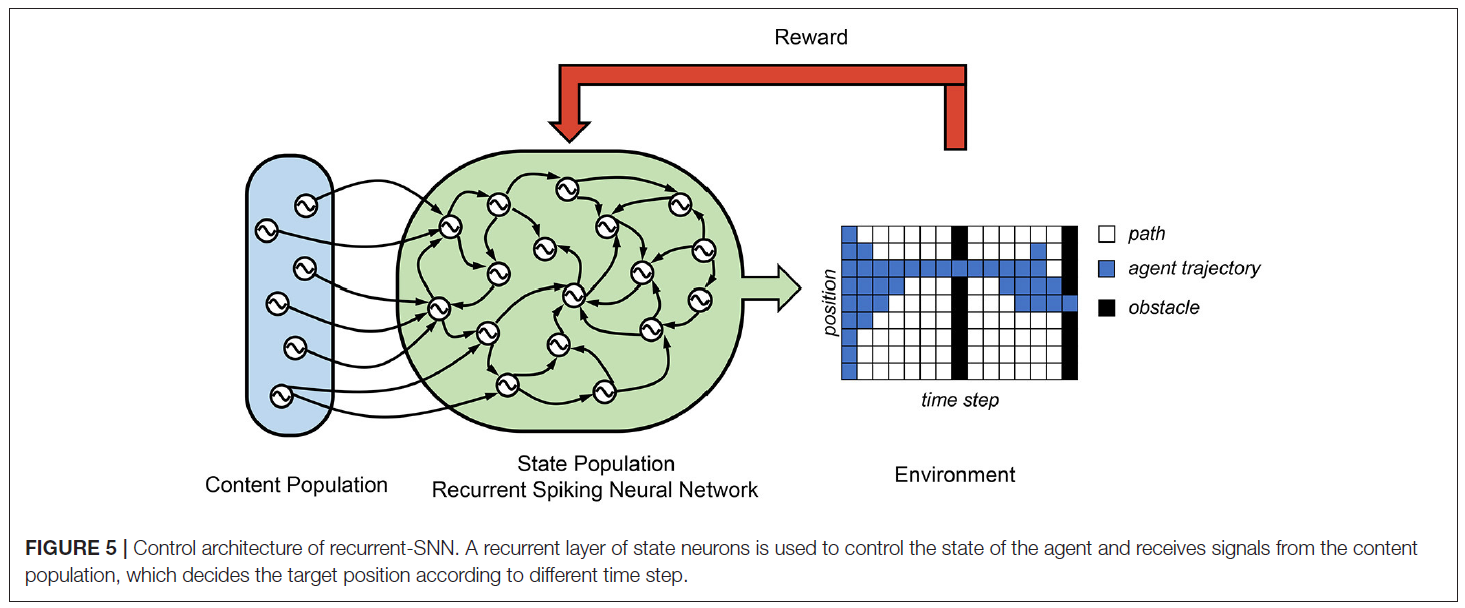
5. LEARNING AND ROBOTICS APPLICATIONS
神经元之间突触连接强度的变化被认为是学习的生理基础(Vasilaki et al., 2009)。这些变化可以由编码神经元和突触之间奖励或内部共同激活的存在的神经调节剂控制。在本节介绍的控制任务中,网络应该学习将某些状态输入映射到控制或动作输出的函数。成功学习后,该网络可以执行简单的任务,例如沿墙远动,避障,到达目标,车道跟踪,滑行行为或觅食。在大多数情况下,网络输入直接来自机器人的传感器,范围从二值传感器(例如,嗅觉)到多维连续传感器(例如相机)。在其他情况下,输入可以是预处理数据,例如来自脑电图(EEG)数据。类似地,输出范围可以从一维二值行为控制到多维连续输出值,例如,也用于电动机控制。
最初,通过手动设置网络权重来解决仿真控制任务,例如,在Lewis et al. (2000)和Ambrosano et al. (2016)中。然而,这种方法仅限于解决简单的行为任务,例如沿墙运动(Wang et al., 2009)或车道跟踪(Kaiser et al., 2016),通常仅适用于少量权重的小型网络架构。
因此,已经研究并发表了针对控制任务的SNN的多种训练方法。本节旨在从机器人技术和机器学习的角度出发,将已发布的算法分类为基本的基础训练机制,而不是着眼于研究领域,生物学合理性或特定任务等标准。在本节的第一部分,介绍了使用某种形式的基于Hebbian的学习的SNN控制的实现。在第二部分中,显示了试图弥合经典RL和SNN之间鸿沟的出版物。最后,讨论了有关如何训练和实现SNN的一些替代方法。
5.1. Hebbian-Based Learning
Donald Hebb在1949年的The Organization of Behavior (Hebb, 1949)一书中介绍了最早的神经科学理论之一,它解释了学习过程中大脑突触功效的适应性。通常用短语"将细胞一起发放,将它们连接在一起"概括,他的想法通常用数学术语表示为:

其中wij指突触前神经元 i 与突触后细胞 j 之间突触权重的变化;并且v代表那些神经元的活动。
基于Hebbian的学习规则(依赖于突触前和突触后脉冲的精确时间)在SNN中高度非线性函数的出现中起着至关重要的作用。基于Hebbs规则的学习已成功应用于诸如输入聚类,模式识别,源分离,降维,关联记忆的形成或自组织映射的形成等问题(Hinton and Sejnowski, 1999)。此外,已经在机器人控制任务中使用了不同的生物学合理的学习规则来使用SNN。但是,由于基本机制保持不变,因此可以通过以下不同方式来实现对这些网络的训练(请参见表1)。在表中,两轮车辆是指具有两个主动轮的车辆。
5.1.1. Unsupervised Learning
根据STDP,如果突触前脉冲在突触后脉冲之前,则可以观察到突触强度的增强[长期增强(LTP)],相反的序列则导致抑制[长期抑制(LTD)]。由于缺乏直接的目标、校正函数或知识渊博的监督者,这种学习通常被归类为无监督学习(Hinton and Sejnowski, 1999)。基于STDP规则的学习已成功应用于许多问题,例如输入聚类,模式识别,空间导航和对环境的思维探索。
Wang et al. (2008)使用这种方法来训练基于SNN的行为控制器,以通过移动机器人从不同的起始位置驱动超声波传感器信号来实现避障。与其他经典NN相比,他们证明了SNN需要更少的神经元并且相对简单。之后,他们(Wang et al., 2014)扩展了其导航控制器的跟踪能力和目标逼近能力。在类似的研究中,Arena et al. (2010)提出了一种基于无监督学习范式的SNN,以使机器人能够自主学习如何在未知环境中导航。他们的控制器通过不断加强非条件刺激(接触传感器和目标传感器)与条件刺激(距离传感器和视觉传感器)之间的关联,根据一系列基本反射,使机器人来学习高级传感器特征。
5.1.2. Supervised Learning
在non-SNN中,近年来的许多成功可以概括为寻找有效地从标记数据中学习的方法。神经网络模仿给定数据的已知结果的这种学习类型称为监督学习(Hastie et al., 2001)。各种不同的神经科学研究表明,这种学习也可以在人脑中找到(Knudsen, 1994),例如在运动控制和运动学习中(Thach, 1996; Montgomery et al., 2002)。但是,尽管对这些主题进行了广泛的探索,但是在生物神经元中监督学习的确切机制仍然未知。
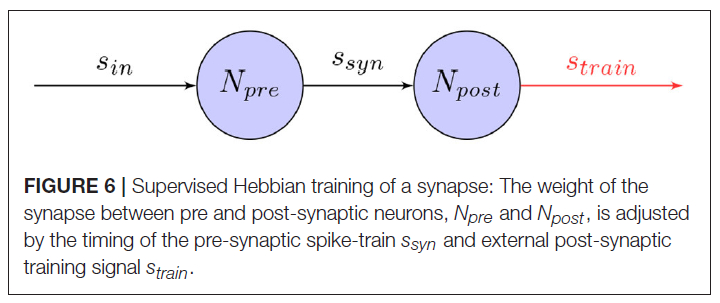
因此,训练机器人控制任务的SNN的简单方法是通过提供外部训练信号,该信号在有监督的学习环境中调节突触。如图6所示,当外部信号作为突触后脉冲序列引入网络时,突触可以调整其权重,例如,使用诸如STDP之类的学习规则。在初始训练阶段之后,这将使网络以令人满意的精度模拟训练信号。即使此方法为训练网络提供了一种简单直接的方法,但它仍依赖于外部控制器。特别是对于涉及高维网络输入的控制任务,这可能不可行。
已经提出了几种有关如何工作的模型,方法是使用活动模板进行复制(Miall and Wolpert, 1996)或将误差信号最小化(Kawato and Gomi, 1992; Montgomery et al., 2002)。在神经系统中,这些教学信号可能由感觉反馈或其他监督性神经结构提供(Carey et al., 2005)。这些模型中的一种最适合单层网络,称为监督性Hebbian学习(SHL)。根据8中得出的学习规则,教学信号用于训练突触后神经元在目标时间发放并在其他时间保持沉默。这可以表示为:
![]()
其中wij是突触前神经元 i 与突触后神经元 j 之间的突触功效,α是学习率,vi是突触前神经元活动,tj代表突触后教学信号。
Carrillo et al. (2008)使用这种基本方法来训练小脑的脉冲模型,以关节角度和速度以及目标位置作为输入,在达到目标的任务中控制具有2个自由度的机器臂。通过反复仿真机器臂到七个不同的目标来训练脉冲小脑模型。与其他STDP学习规则相反,训练信号仅在外部导致长期抑制,训练信号依赖于运动误差,即期望状态与实际状态之差。在类似的实验中,Bouganis and Shanahan (2010)训练了一个单层网络来控制3D空间中具有4个自由度的机械臂。作为输入,关节角度和空间,在每次训练迭代期间,所有四个关节均由随机电机命令驱动,范围为[−5°, 5°]。使用末端执行器的方向,而输出包括四个运动命令神经元。使用机械臂的逆运动学模型计算训练信号,并使用对称的STDP学习规则调整突触权重。在表1中可以找到更多示例,按年份降序排列。
5.1.3. Classical Conditioning
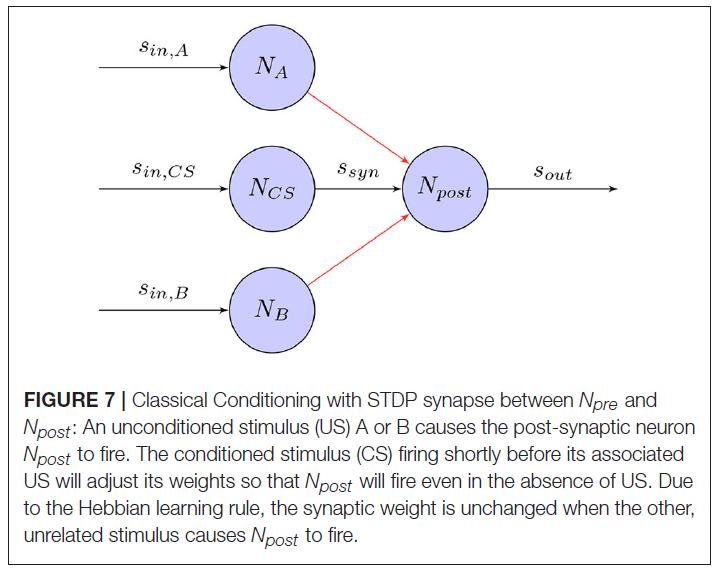
经典条件反射(Wikipedia, 2017a)是指一种学习程序,其中将具有生物强力刺激(例如食物)与之前的中性刺激(例如铃声)配对。这将导致中性刺激开始引起反应(例如唾液分泌),这通常是由强刺激引起的。在著名的经典条件反射实验中(Pavlov and Anrep, 2003),Pavlov的狗学会了将无条件刺激物(US)(在这种情况下为食物)与条件刺激物(CS)(铃铛)联系起来。虽然尚不清楚他的实验中给出的高水平刺激如何在大脑中进行处理,但相同的学习原理也可以用于神经水平的训练。图7显示了基于STDP学习规则的突触如何将US和CS关联起来,即使在没有US的情况下也能引起反应。
遵循此原理,受生物启发的机器人可以学习将CS(例如,感官信息)与充当外部增强剂的US关联起来。这样,机器人可以根据感官输入学会遵循期望的行为。Arena et al. (2009a, b, 2010)展示了如何在避障和目标到达任务中使用经典条件反射。在具有两个输出运动神经元的SNN中,距离和视觉传感器充当CS,而接触和目标传感器充当US,导致无条件响应。通过在预先设计的封闭环境中导航机器人,该机器人成功地学会了将CS和US联系在一起并达到目标而没有遇到障碍。在类似的实验中,Cyr and Boukadoum (2012)在受控的虚拟环境中使用红外,超声和视觉神经元作为CS,而振动神经元作为US在受控的虚拟环境中执行了不同的经典条件反射任务。Wang et al. (2008, 2014)构建了一个控制器,可以像US一样刺激两个运动神经元。然后使用接近传感器数据作为CS输入的单层SNN进行了诸如避障和到达目标等任务的训练。Iwadate (2014)在达到目标的任务中使用光传感器来惩罚误差行为。Jimenez-Romero et al. (2015, 2016)和Jimenez-Romero (2017)实现了一种虚拟蚂蚁,该蚂蚁通过单层SNN学习将嗅觉传感器输入与不同行为相关联。该机器人能够学习识别奖励和有害刺激以及在仿真环境中进行简单导航。Casellato et al. (2014)提出了一个具有真实触觉机器臂的现实小脑SNN,以实现多种感觉运动任务。在所有任务中,机器人都学会了调整时间和电机响应的增益,并成功地复制了人类生物系统,以在嘈杂的世界中获取,消灭和表达知识。
为了成功学习此类行为任务,必须为机器人应学习的每个相关条件刺激提供一些非条件刺激。这也意味着机器人将学会关联时间延迟的刺激。综上所述,将经典条件反射用于机器人控制基本上意味着构造一个外部控制器,该控制器为每个相关状态输入提供无条件刺激,这在许多任务中可能不可行。
5.1.4. Operant Conditioning
虽然经典条件反射涉及将条件刺激和非条件刺激彼此被动关联,但是工具性条件反射(OC)包括将刺激与响应关联并随后主动更改行为。从概念上讲,工具性条件发射涉及改变自愿行为,并且与RL及其智能体-环境交互周期密切相关。行为反应之后是强化或惩罚。行为后的强化会导致行为增加,但是如果行为后有惩罚,行为就会减少。代替开发正式的数学模型,主要是在生物学和心理学领域研究了工具性条件反射。尽管对工具性条件反射的理解有了进步,但仍不清楚如何在神经水平上实现这种学习。
在这种情况下,Cyr et al. (2014)和Cyr and Thériault (2015)开发了一个脉冲OC模型,该模型由输入馈送的提示神经元,动作神经元和接受奖励或惩罚的预测神经元组成。通过这种简单的基本结构和学习规则(例如习惯和STDP),他们能够在仿真环境(例如推箱子)中解决与OC相关的简单任务。在Dumesnil et al. (2016a, b)的另一出版物中,在机器人上实现了奖励依赖型STDP学习规则,以允许进行OC学习,并在迷宫任务中进行了演示。RGB相机用于捕获代表迷宫环境中的提示或奖励的颜色信息。最终,如果一个动作频繁地伴随着奖励,则机器人学会了这种关联。
5.1.5. Reward-Modulated Training
在图8中,显示了基于奖励的训练的学习规则。使用给定神经元发出的一种或多种化学物质来调节神经元的不同群体被称为神经调节(Hasselmo, 1999)。作为神经调节剂之一,形成中脑多巴胺能细胞群体的多巴胺神经元对于执行功能,运动控制,动机,增强和奖励至关重要。大多数类型的神经系统奖励都会增加大脑中的多巴胺水平,从而刺激多巴胺神经元(Schultz, 1998)。受大脑中多巴胺能神经元的启发,以资格迹收集了STDP事件的影响,全局奖励信号诱导了突触权重的变化。与前面讨论的监督训练相反,奖励可以归因于刺激,即使它们的时间被延迟。这对于机器人控制来说可能是非常有用的属性,因为它可以简化对外部训练信号的要求,从而导致更复杂的任务。Florian (2007)和Izhikevich (2007)提出了STDP和全局奖励信号的简单学习规则组合模型。在R-STDP中,突触权重w随奖励信号R的变化而变化。突触的资格迹可定义为:

其中c是资格迹。spre/post表示突触前/后脉冲的时间。C1是常数因子。τc是资格迹的时间常数。δ(·)是狄拉克增量函数。

其中R(t)是奖励信号。
在文献中,已经使用这种基本学习结构发布了各种算法进行训练。即使它们都基于相同的机制,也能够以不同的方式构建奖励。
- 奖励特定事件:类似于经典RL任务的基于奖励的学习的最直接实现是使用与特定事件相关的奖励。Evans (2012)在几个觅食任务中训练了一个简单的单层SNN,该任务由4个输入传感器神经元和4个输出运动神经元组成。在一个单独的网络中,其他与奖励有关的传感器神经元刺激了多巴胺能神经元,而后者又调节了突触权重的变化。通过这种仿真设置,机器人能够了解食物吸引行为,并随后在环境变化时取消这种行为。这是通过训练阶段实现的,在该阶段,随机驾驶机器人以有效地探索环境。通过将多巴胺反应从主要刺激转变为次要刺激,即使时间间隔很长,机器人也能够学习正确的行为和奖励之间的距离。Faghihi et al. (2017)显示了能够执行一阶和二阶条件反射的果蝇的SNN模型。在一个简单的任务中,仿真苍蝇学会了避免靠近发出电击的嗅觉目标。此外,相同的行为可以迁移到与初级刺激相关的次级刺激,而不会自身发出电击。
- 控制误差最小化:与奖励特定事件相反,多巴胺调节的学习也可以用于优化任务中以最小化目标函数。通常可以通过加强或削弱导致目标函数基于资格迹发生变化的连接来实现。Clawson et al. (2016)使用这种基本架构来训练SNN遵循轨迹。该网络由横向状态变量作为输入,隐含层和对横向控制输出进行解码的输出层组成。通过最小化由外部线性控制器提供的解码后的实际输出和所需输出之间的误差,可以离线实现学习。
- 间接控制误差最小化:对于SNN的某些潜在应用,例如植入大脑的神经假体设备,可能无法直接操纵突触权重。因此,Foderaro et al. (2010)展示了一种间接的训练SNN的方法,通过一个单独的critic SNN产生的输入脉冲诱导突触效用的变化。该外部网络具有控制输入和反馈信号,并使用基于奖励的STDP学习规则进行了训练。通过最小化离线控制输出和最优控制律之间的误差,它能够学习飞机的自适应控制。Zhang et al. (2012), Zhang et al. (2013), Hu et al. (2014),以及Mazumder et al. (2016)也提出了类似的想法。他在目标到达和避障任务中训练了一个简单的虚拟昆虫。
- 度量最小化:也可以应用相同的原理来最小化全局度量,该全局度量可能比外部控制器更易于构建和计算。Chadderdon et al. (2012)提出了运动皮层的脉冲神经元模型,该模型控制目标到达任务中的单关节臂。该模型由144个兴奋性神经元和64个抑制性神经元组成,其本体感受器输入细胞和输出细胞控制着屈伸肌。根据学习阶段中手部目标距离的变化,给出了全局的奖惩信号,在此期间,机器人被反复设置五个不同的目标。Neymotin et al. (2013)和Spüler et al. (2015)后来用两关节机械臂扩展了这种架构。同样,Dura-Bernal et al. (2015)使用由数百个脉冲模型神经元组成的仿生皮质脉冲模型来控制两关节臂。通过本体感觉输入(肌肉长度)和肌肉兴奋输出,通过最小化手目标距离来训练网络。通过在全局奖励/惩罚信号的指导下反复移动到目标,可以减少距离误差。Kocaturk et al. (2015)扩展了相同的基本架构,以开发脑机接口。细胞外记录的运动皮质神经元提供用于假体控制的网络输入。通过按下按钮,用户可以奖励所需的运动并将假肢引导向目标。Sarim et al. (2016a, b)使用在两轮差分驱动机器人上实现的具有电阻式纵横制存储器的小型微处理器,显示了基于STDP的学习规则如何导致目标接近和避障行为。尽管在这种情况下,学习是使用if-then规则实施的,该规则依赖于距目标和障碍物的距离变化,但从概念上讲,它与奖励调节学习相同。这可以通过将if-rules换成+1或-1的奖励来轻松看出。
- 增强联系:Chou et al. (2015)推出了一种触觉机器人,该机器人使用的网络结构受到岛状皮质的启发。与经典条件反射一样,使用多巴胺调节的突触可塑性规则来加强条件和非条件刺激之间的关联。

5.2. Reinforcement Learning
在上一小节中,提出了多种基于Hebbian学习规则的SNN训练方法。这可以通过外部控制器提供有监督的训练信号来完成,也可以通过使用基于奖励的学习规则以及构建奖励的不同方式来完成。但是,后一种学习类型仅根据延迟的奖励就可以成功地在简单任务中训练SNN。总的来说,所有这些方法都经过训练,不需要像RL理论通常要求的那样遥遥领先。
另一方面,在经典RL理论中,学习预先了解马尔可夫决策过程(MDP)中的多个步骤是主要关注的问题之一。 因此,已经发布了几种将SNN与经典RL算法相结合的算法。
5.2.1. Temporal Difference
引入一种学习规则(其中将时间向前看一个或多个步骤)作为TD学习。特此,Potjans et al. (2009)和Frémaux et al. (2013)使用位置单元表示MDP和单层SNN中的状态空间,用于状态评估和策略。经过一些训练,这两种算法都能够学习在简单的网格世界中进行导航的方法。用类似的方法,Nichols et al. (2013)提出了受生物系统控制结构启发的机器人控制器。在一个自组织的多层网络结构中,来自距离和方向传感器的感觉数据逐渐融合到代表感觉输入不同组合的状态神经元中。在顶部,每个单独状态神经元都连接到3个输出运动神经元。通过将感觉输入融合到不同的状态神经元中并将其连接到动作神经元,当机器人进行试验运动时,可以使用简化的TD学习规则分别设置最后一层的每个突触权重。该控制器的性能已在后续任务中得到了证明。
尽管这些状态表征对于相对较小的状态空间非常有效,但由于TD方法只能分几步获得奖励,因此它们通常注定会在较大的高维状态空间中失败。因此,它不稳定,可能会收敛到错误的解决方案,尤其是对于高维状态空间。实际上,从概念上讲,这些方法可以看作是基于表的Q学习的SNN实现。
5.2.2. Model-Based
尽管对于机器人控制任务(如本文中显示的任务),无模型的RL方法似乎很受欢迎,但至少有两篇最近的出版物值得一提,它们提供了基于模型的RL的SNN实现。Rueckert et al. (2016)提出了一种用于规划任务的循环SNN,该网络在一个真正的机器人避障任务中得到了证明。Friedrich and Lengyel (2016)实现了脉冲神经元的生物学真实网络来进行决策。该网络使用局部可塑性规则来解决一步以及序列决策任务,该任务仿真了执行类似任务期间额叶皮层中记录的神经反应。他们的模型重现了从简单的二值选择到多步骤序列决策等任务的行为和神经生理数据。他们以两步迷宫导航任务为例。在每种状态下,根据老鼠的行为给老鼠奖励不同的价值。奖励被建模为外部刺激。SNN在10毫秒内学会了稳定的策略。
5.3. Others
除了上述两种主要方法外,机器人控制任务中还有其他针对SNN的训练方法(见表2)。
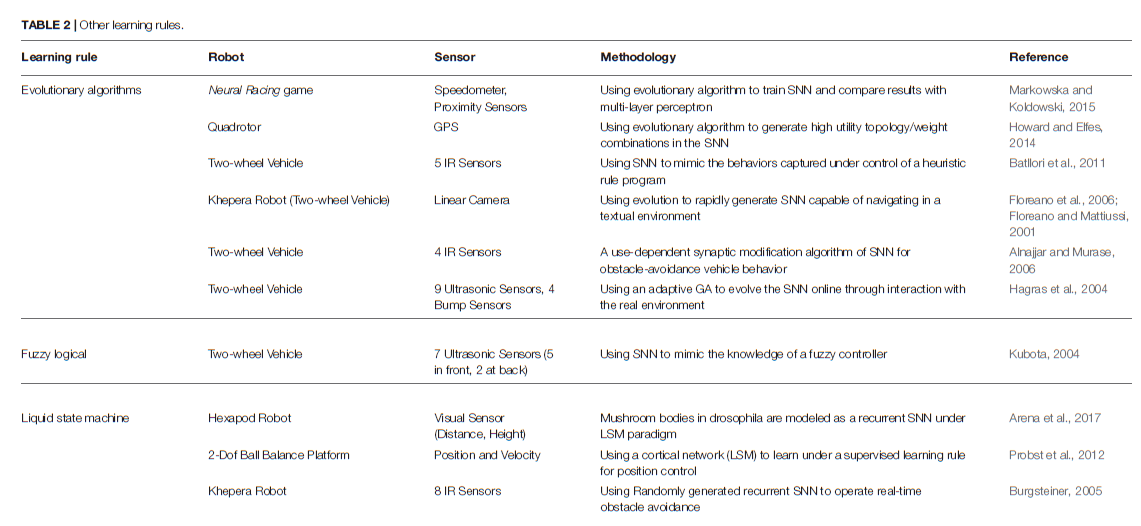
5.3.1. Evolutionary Algorithms
在自然界中,进化产生了各种形状的生物,其生存策略与环境条件的匹配最优。基于这些思想,已经开发出了一类算法,通过仿真基本自然过程(被称为进化算法)来寻找问题的解决方案(Michalewicz, 1996)。通常,进化过程可以理解为某种形式的梯度优化。因此,使用这些算法的典型问题是陷入局部最小值。在机器人控制中的应用中,已经证明,不断发展的SNN在大多数静态环境中都能很好地工作。由于试错学习的训练原理,在动态变化的环境中通常会遇到困难。
Floreano and Mattiussi (2001)在不规则纹理的环境中显示了基于视觉的控制器,该环境在导航时不会撞到障碍物。预定义的SNN由连接到10个全连接的隐含神经元和2个运动输出神经元的18个感觉输入受体组成。当机器人在实验装置中连续行驶时,使用静态突触权重值,该算法用于通过仅遗传权重的符号(兴奋性和抑制性)来搜索连通性的空间。在群体为60时,通过总结每个时间步骤的运动速度来评估适应性,并通过单点交叉,位变异和精英主义创造了新一代。Hagras et al. (2004)后来使用自适应交叉和变异概率将该方法扩展到了SNN权重的发展。在沿墙运动的情况下,他们能够在少量世代中发展出良好的SNN控制器。Howard and Elfes (2014)提出了一种四旋翼神经控制器,该控制器在充满挑战的风力条件下执行悬停任务。利用前馈网络,将当前位置和目标位置之差作为输入,将俯仰、侧倾和推力作为输出,从而发展了权重和拓扑结构,以将空间误差降至最低。Batllori et al. (2011)在使用双目传感器和接近传感器的目标到达和避障任务中,通过最小化控制误差来发展SNN,以仿真外部控制器信号。Markowska and Koldowski (2015)使用预定义大小的前馈网络架构来控制toy车。该网络根据速度、定位和道路边界输入信号,控制速度调节和转弯方向,并使用遗传算法演变其权重。
5.3.2. Self-Organizing Algorithms
Alnajjar and Murase (2006)制定了一个突触学习规则,该规则根据神经元的活动来加强神经元之间的连接。在学习阶段,机器人逐渐组织了网络,并形成了避障行为。通过这种类似于其他基于Hebbian的学习方法的自组织算法,他们能够学习避障和简单的导航行为。
5.3.3. Liquid State Machine
作为一种特殊的SNN,液体状态机(LSM)通常由大量的神经元组成,这些神经元从外部以及其他神经单元接收时变输入(Yamazaki and Tanaka, 2007)。所有混合且无序的神经元单元都是随机生成的,然后在从时变输入获得的连接的时空分布的周期性激活下进行排列。因此,LSM被认为是各种各样的非线性函数,它们能够将输出计算为输入的线性组合。LSM似乎是解释脑部操作的一种潜在且有前途的理论,这主要是因为神经元的活动不是硬编码的,并且只能用于特定任务。Burgsteiner (2005), Probst et al. (2012),以及Arena et al. (2017)展示了如何训练液体状态机来完成机器人控制任务。

6. SIMULATORS AND PLATFORMS
随着神经科学和芯片工业的飞速发展,已经研究了使用SNN的大规模神经形态硬件,以在速度、效率和机制上实现与动物大脑相同的功能。例如,SpiNNaker (Furber et al., 2013)是一个百万核系统,用于实时对大型SNN进行建模。TruthNorth (Merolla et al., 2014)包含100万个可编程的脉冲神经元,仅消耗不到100毫瓦的电量。可以在Schuller and Stevens (2015)中找到并引入其他神经形态计算平台,例如Neural Grid (Benjamin et al., 2014),NeuroFlow (Cheung et al., 2016)。同时,已经开发了越来越多的动态仿真器来辅助机器人研究(Ivaldi et al., 2014),例如Gazebo (Koenig and Howard, 2004),ODE (Wikipedia, 2017c)和V-Rep (Rohmer et al., 2013)。这些仿真器极大地促进了涉及机械设计,虚拟传感器仿真和控制结构的研究过程。
尽管存在足够的工具来仿真SNN (Brette et al., 2007; Bokolay et al., 2014)或机器人及其环境(Staranowicz and Mariottini, 2011; Harris and Conrad, 2011),但这些工具可以为研究人员提供联合交互,包括逼真的大脑模型,机器人和感觉丰富的环境。表3列出了一些现有平台。
作为结合SNN和机器人的首次尝试,iSpike (Gamez et al., 2012)是一个C++库,它在SNN仿真器和iCub类人机器人之间提供了接口。它采用受生物启发的方法,将机器人的感官信息转换为脉冲,然后传递到神经网络仿真器,然后将来自网络的输出脉冲解码为电机信号,然后发送给机器人以对其进行控制。CLONES (Voegtlin, 2011)在Brian神经仿真器(Goodman and Brette, 2009)与SOFA (Allard et al., 2007)之间进行通信,并且还是用于共享内存和信号量的接口。AnimatLab (Cofer et al., 2010)是允许处理仿真机器人平台的更通用的系统,它提供了诸如机器人建模,两个神经模型以及用于导入其他模型的插件之类的功能。
最近,HBP神经机器人平台(NRP)的第一个版本(American Association for the Advancement of Science, 2016; Falotico et al., 2017)被提出,该版本是在欧盟旗舰人类脑计划中开发的。它首次为科学家提供了集成的工具链,可将预定义和自定义的大脑模型连接到计算机仿真实验中机器人身体和环境的详细仿真。特别是,NRP由六个关键组件组成,这对于从头开始构建神经机器人实验至关重要。可以看出,NRP为机器人和大脑模型的耦合仿真提供了完整的框架。大脑仿真器通过生物启发式学习算法(如SNN)来仿真大脑,从而在计算机仿真神经机器人实验中控制机器人。世界仿真器模拟机器人及其交互环境。脑接口和身体集成器(BIBI)在脑模型和机器人模型之间建立了通信通道。闭环引擎(CLE)负责实验的控制逻辑以及不同组件之间的数据通信。后端从前端接收有关神经机器人实验的请求,并将它们主要通过ROS分发到相应的组件。前端是用于神经机器人实验的基于Web的用户界面。用户能够设计一个新实验或编辑现有模板实验。
7. OPEN RESEARCH TOPICS
在前面的部分中,已经根据学习方法对各种机器人的基于SNN的控制技术进行了调查。尽管已经进行了越来越多的工作来探索用于机器人控制的SNN的理论基础和实际实现,但仍需要研究许多相关主题,尤其是在以下领域。
7.1. Biological Mechanism
尽管对大脑的功能和结构进行了广泛的探索,但是在生物神经元中学习的确切机制仍然未知。与机器人应用相关的一些信息如下:(1) 在许多神经活动中,除了脉冲的发放率和时间以外,如何对各种信息进行编码?(2) 如何以如此有效且精确的方式区分,存储和检索记忆?(3) 大脑如何仿真未来,因为它涉及"先前步骤"的概念,因此需要某种形式的记忆?只要我们能够不断解决这些未解决的大脑奥秘,未来的机器人肯定可以实现更先进的智能。
7.2. Designing and Training SNNs
当前提出的算法都没有通用的用途,至少在原则上不能以反向传播(经过时间)及其变体(具有所有局限性)对发放率神经元起作用的方式来学习任意任务(Grüning and Bohte, 2014)。因此,没有通用的设计框架可以提供建模和训练的功能,也没有传统ANN的那些实质性工具,例如Tensorflow (Allaire et al., 2016),Theano (Theano开发团队, 2016)和Torch (Collobert et al., 2011)。这种情况的本质是,训练这类网络非常困难,尤其是在涉及深度网络结构时。由于脉冲时间的不可微分性,通常在ANN中使用的误差反向传播机制无法直接迁移到SNN,因此缺乏实用的学习方法。
此外,训练应加强与新兴的RL技术的结合,例如,将SNN扩展到深度架构或生成连续动作空间(Lillicrap et al., 2015)。将来,将R-STDP与奖励预测模型结合使用可能会产生一种实际上能够解决序列决策任务(例如MDP)的算法。
7.3. High Performance Computing With Neuromorphic Devices
另一个需要广泛研究且尚未明确定义的重要的普遍问题是如何将基于SNN的控制器集成到神经形态设备中,因为它们有潜力在速度和较低功耗等计算能力方面进行根本性的改进(Hang et al., 2003; Schuller and Stevens, 2015)。这些对于机器人应用至关重要,特别是在实时响应非常重要且能源供应有限的移动应用中。可以找到有关如何基于神经形态芯片对SNN进行编程的概述(Walter et al., 2015b)。
SNN的计算可以从并行计算中受益匪浅,比传统的ANN受益得多。与发放率编码中的传统神经元不同,脉冲神经元不需要在每个计算步骤都从每个突触前神经元接收权重值。由于在每个时间步骤中,只有少数神经元在SNN中处于活动状态,因此消除了消息传递的经典瓶颈。而且,计算膜电位的更新状态比计算加权和更复杂。因此,与传统的ANN相比,SNN并行实现中的通信时间和计算成本要平衡得多。
7.4. Interdisciplinary Research of Neuroscience and Robotics
需要消除的另一个障碍来自神经科学和机器人学研究人员的两难境地:机器人学家经常在虚拟机器人中使用简化的大脑模型进行实时仿真,而神经科学家则开发由于其高度复杂性而不可能被嵌入到现实世界中的详细大脑模型。还需要学习在动态和丰富的感官环境的交互下生成的机器人的复杂感官运动映射(Hwu et al., 2017)。正在进行的解决方案是Neurorobotics平台,该平台提供了足够的工具来建模虚拟机器人,高保真环境和(对于神经科学家和机器人专家)复杂的神经网络模型。
8. CONCLUSION
通过更加现实地仿真大脑的基本机制,SNN在速度、能效和计算能力方面显示出实现高级机器人智能的巨大潜力。因此,在本文中,我们旨在为读者提供有关基于SNN以及相关建模和训练方法来解决机器人控制任务的文献的全面综述,同时为研究人员提供启发。具体来说,我们回顾了SNN的生物学证据及其在开始时被机器人领域采用的主要动力。然后,我们从神经元、突触和网络方面介绍了设计SNN的主流建模方法。基于Hebbian规则和RL,SNN的学习解决方案通常分为两类,并通过详尽的机器人相关示例和汇总表进行了说明和阐述。最后,初步研究了一些流行的用于仿真机器人SNN的界面或平台。
如开放主题中所述,基于SNN的控制任务的最大挑战是缺乏通用的训练方法,因为反向传播是针对传统ANN的。因此,将来需要更多来自神经科学和机器人技术领域的知识和互动来探索这一领域。