郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
ASPLOS ’17, April 08-12, 2017, Xi’an, China

Abstract
如今的智能个人助理,如Apple Siri、Google Now和Microsoft Cortana,都是在云端进行计算的。这种仅限云计算的方法需要通过无线网络将大量数据发送到云计算,并给数据中心产生了巨大的计算压力。然而,随着移动设备中的计算资源变得更加强大和高效,出现了这样的问题:这种只使用云计算的处理是否值得推进,以及将部分或全部计算推到边缘的移动设备上意味着什么。
在本文中,我们研究了纯云处理的现状,并研究了能够有效利用整套云和移动设备来在这类智能应用上实现低延迟、低能耗和高数据中心吞吐量的计算划分策略。我们的研究使用了8个智能应用程序,涉及计算机视觉、语音和自然语言领域,所有这些应用程序都采用最先进的深度神经网络(DNNs)作为核心机器学习技术。我们发现,鉴于DNN算法的特点,一种基于DNN中每一层的数据和计算变化的细粒度层级计算划分策略比现有方法具有显著的延迟和能量优势。
利用这一观点,我们设计了一个轻量级调度器Neurosurgeon,它可以在移动设备和数据中心之间以神经网络层的粒度自动划分DNN计算。Neurosurgeon不需要每个应用程序的配置文件。它适用于各种DNN架构、硬件平台、无线网络和服务器负载级别,智能地划分计算以获得最佳延迟或最佳移动能量。我们在一个最先进的移动开发平台上对Neurosurgeon进行了评估,结果表明,Neurosurgeon的端到端延迟平均改善了3.1倍,最高可达40.7倍;移动设备能耗平均降低59.5%,最高可达94.7%;数据中心吞吐量平均提高1.5倍,最高可达6.7倍。
1. Introduction
随着移动设备越来越个性化和智能化,我们与当今移动设备的交互方式正在迅速改变。Apple Siri、Google Now和Microsoft Cortana等智能个人助理(IPA)在移动设备上默认处于集成状态,随着可穿戴设备和智能家庭设备的不断普及,预计将越来越受欢迎[1,2]。与这些智能移动应用程序的主要接口是使用语音或图片来引导设备并提出问题。这种交互模式的需求有望取代传统的基于文本的输入[3-5]。
为IPA应用处理语音和图像输入需要精确和高度复杂的机器学习技术,其中最常见的是深度神经网络(DNNs)。DNNs以其在语音识别、图像分类和自然语言理解等任务中的高精度,日益成为这些应用中的核心机器学习技术。包括Google、Microsoft、Facebook和Baidu在内的许多公司都在使用DNNs作为其生产系统中众多应用程序的机器学习组件[6-8]。
先前的工作已经表明,基于DNN的智能应用中的语音或图像查询需要比基于文本的输入更多的数量级处理[9]。传统的移动设备已经不能以合理的延迟和能量消耗来支持这么大的计算量,这是一个常识。因此,目前web服务提供商用于智能应用程序的方法是在高端云服务器上承载所有计算[10–13]。从用户的移动设备生成的查询将发送到云进行处理,如图1a所示。但是,使用这种方法,大量数据(例如,图像、视频和音频)通过无线网络上传到服务器,导致高延迟和能源成本。
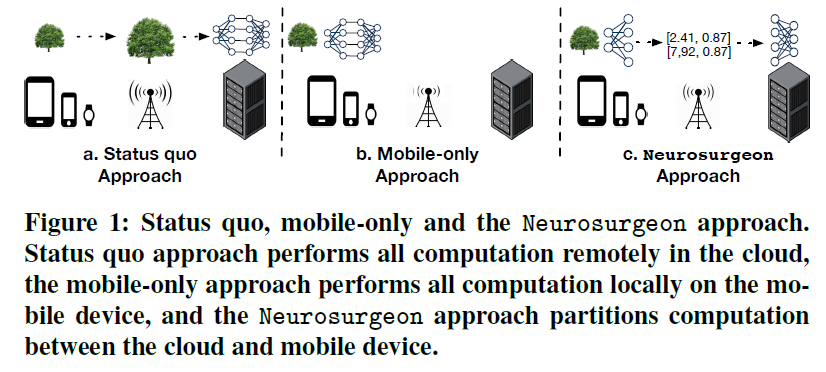
当数据传输成为延迟和能量瓶颈时,通过强大的移动SoC集成,现代移动硬件的性能和能量效率不断提高[14,15]。基于这一观察,本文重新研究了移动与云之间智能应用的计算划分。特别是,我们研究如何将计算从云端推到边缘的移动设备上,以全部或部分执行这些传统的仅限云计算的应用程序。我们在这项工作中解决的关键问题包括:
1. 在当今的移动平台上执行大规模智能工作负载的可行性如何?
2. 在哪一点上,通过无线网络传输语音和图像数据的成本过高,无法证明云处理的合理性?
3. 移动边缘在为需要大量计算的智能应用程序提供处理支持方面应该扮演什么角色?
基于我们使用的8个基于DNNs的智能应用程序(涉及视觉、语音和自然语言领域)进行的调查,我们发现,对于某些应用程序,由于数据传输开销高,在移动设备上本地执行(图1b)的速度可能比仅使用云的方法快11倍(图1a)。此外,我们发现,一个基于DNN拓扑结构和组成层的细粒度层级划分策略,不仅不限制计算完全在云中执行,也不限制计算完全在移动设备上执行,而且可以获得非常优异的端到端性能和移动能源效率。通过将计算从云端推到移动设备,我们还提高了数据中心的吞吐量,允许给定的数据中心支持更多的用户查询,并为移动和云系统创造双赢局面。
鉴于理想的细粒度DNN划分点依赖于DNN的层组成、使用的特定移动平台、无线网络配置和服务器负载,我们设计了一个轻量级的动态调度器Neurosurgeon。Neurosurgeon是一个实时系统,涉及云和移动平台,自动识别DNNs中的理想分区点,并协调移动设备和数据中心之间的计算分布。如图1c所示,Neurosurgeon对DNN计算进行了划分,并利用了移动和云的处理能力,同时减少了数据传输开销。本文的具体贡献如下:
- 深入调查现状——我们展示了在云端和移动设备上执行最新DNNs的延迟和能耗。我们观察到,通过无线网络上传是当前方法的瓶颈,而移动设备执行通常比当前方法提供更好的延迟和能量消耗。(第3节)
- DNN计算和数据大小特征研究——我们提供了8个DNNs的计算和数据大小的深入层级特征,跨越计算机视觉、语音和自然语言处理。我们的研究表明,DNN层具有明显不同的计算和数据大小特征,这取决于它们的类型和配置。(第4节)
- 跨云和移动边缘的DNN计算划分——基于DNN层的计算和数据特征,我们表明在层粒度上对DNN进行划分具有显著的性能优势。然后,我们设计了一个系统的方法来识别优化点,以便在一组应用程序中划分计算,从而减少延迟和移动能耗。(第4节)
- Neurosurgeon实时系统和层性能预测模型——我们开发了一组模型,根据DNN层的类型和配置预测其延迟和功耗,并设计Neurosurgeon,一个在移动设备和云之间智能划分DNN计算的系统。我们证明Neurosurgeon显著地改善了端到端的延迟,降低了移动能耗,并提高了数据中心的吞吐量。(第5、6节)
我们对一组8个DNNs应用程序的评估表明,使用Neurosurgeon平均可将端到端延迟提高3.1倍,将移动能耗降低59.5%,并将数据中心吞吐量提高1.5倍。
2. Background
在本节中,我们将概述深度神经网络(DNN),并描述计算机视觉、语音和自然语言处理应用程序如何利用DNN作为其核心机器学习算法。
DNNs被组织在一个有向图中,其中每个节点是一个处理元素(神经元),它将一个函数应用于其输入并生成一个输出。图2描述了用于图像分类的5层DNN,其中计算从左到右流动。图的边缘是定义数据流的每个神经元之间的连接。对输入的不同部分应用相同函数的多个神经元定义了一个层。对于通过DNN的前向传递,层的输出是下一层的输入。DNN的深度由层数决定。计算机视觉(CV)应用程序使用DNNs从输入图像中提取特征,并将图像分类为一个预定义的类。自动语音识别(ASR)应用程序使用DNN生成语音特征向量的预测,然后对其进行后处理以生成最有可能的文本。自然语言处理(NLP)应用程序使用DNNs从输入文本生成的词向量中分析和提取语义和句法信息。

3. Cloud-only Processing: The Status Quo
目前,云提供商用于智能应用程序的方法是在云中执行所有DNN处理[10–13]。这种方法的一大开销是通过无线网络发送数据。在这一部分中,我们研究了完全在最先进的移动设备上执行大型DNN的可行性,并与现状进行了比较。
3.1 Experimental setup
我们使用一个真正的硬件平台,代表当今最先进的移动设备,由NVIDIA开发的Jetson TK1移动平台[16],并用于Nexus 9平板电脑[17]。Jetson TK1配备了NVIDIA最新的移动SoC之一的Tegra K1:四核ARM A15和Kepler mobile GPU,带有单流多处理器(表1)。

我们的服务器平台配备了NVIDIA Tesla K40 GPU,这是NVIDIA最新提供的服务器级GPU之一(表2)。

我们使用caffe[18],一个积极开发的开源深度学习库,用于移动设备和服务器平台。对于移动设备CPU,我们使用OpenBLAS[19],一个NEON矢量矩阵乘法库,并使用可用的4核。对于这两个GPU,我们都使用cuDNN[20],这是一个优化的NVIDIA库,它加速了Caffe中的关键层,并对其余层使用Caffe的CUDA实现。
3.2 Examining the Mobile Edge
我们研究移动平台执行传统的仅云DNN工作负载的能力。我们使用AlexNet[21]作为我们的应用,这是一种用于图像分类的最先进的卷积神经网络。先前的工作已经注意到,AlexNet是当今部署在服务器环境中的DNN的代表[22]。
在图3中,我们划分了AlexNet查询的延迟,这是对152KB图像的一个推断。对于无线通信,我们使用TestMyNet[23]在几个移动设备上测量3G、LTE和Wi-Fi的带宽。
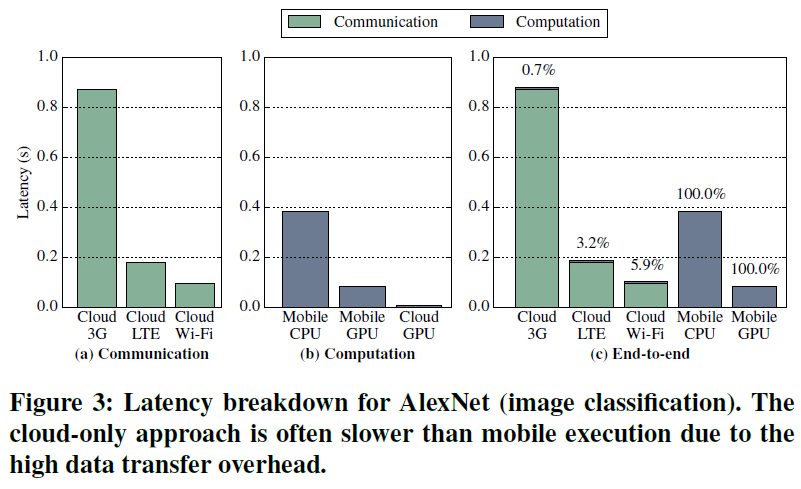
通信延迟——图3a显示了通过3G、LTE和Wi-Fi上传输入图像的延迟。最慢的是超过870ms的3G连接,LTE和Wi-Fi连接分别需要180ms和95ms的上传时间,这表明网络类型对于实现低延迟是至关重要的。
计算延迟——图3b显示了移动CPU、GPU和云GPU上的计算延迟。最慢的平台是移动CPU占用382ms,而移动GPU和云GPU分别占用81ms和6ms。注意,移动CPU处理图像的时间仍然比通过3G上传输入快2.3倍。
端到端延迟——图3c显示了现状和仅移动方式所需的总延迟。每个条形图顶部的一个符号是用于计算的端到端延迟的占比。目前的方法在服务器上计算的时间不到6%,传输数据的时间超过94%。与使用LTE和3G的现状方法相比,移动GPU实现的端到端延迟更低,而使用LTE和Wi-Fi的现状方法执行性能优于移动CPU。
能源消耗——我们用Watt Up? meter[24]和Huang等人描述的技术[25]来测量移动设备的能耗。与图3a所示的趋势类似,图4a显示通信能量在很大程度上取决于所使用的无线网络的类型。在图4b中,移动设备在CPU上的能量消耗高于GPU(虽然GPU需要更多的能量,但设备用于更短的突发,因此消耗的总能量更少)。图4c显示了纯云计算中的总移动能量消耗,以及移动执行在纯云计算消耗的能量主要由通信组成时。与通过LTE或3G传输输入进行云处理相比,移动GPU消耗的能量更少,而通过Wi-Fi进行的云处理消耗的能量少于移动执行。

关键观察——1)数据传输延迟通常高于移动计算延迟,尤其是在3G和LTE上。2)与移动处理相比,云处理具有显著的计算优势,但由于数据传输开销占主导地位,通常不会转化为端到端的延迟/能量优势。3)本地移动执行通常比纯云方式的延迟和能耗更低,而纯云方式在使用快速Wi-Fi连接时性能更好。
4. Fine-grained Computation Partitioning
根据第3节的研究结果,问题是在移动设备和云之间划分DNN计算是否有利。基于DNN层提供了适合于划分计算的抽象观察,我们从分析最新DNN体系结构在层粒度上的数据和计算特性开始。
4.1 Layer Taxonomy
在进行层级分析之前,了解当今DNNs中存在的各种类型的层是很重要的。
全连接层(fc)——全连接层中的所有神经元都与前一层中的所有神经元完全连接。该层使用一组学习的权重计算输入的加权和。
卷积层和局部层(conv,local)——卷积层和局部层用一组学习的滤波器卷积图像以生成一组特征图。这些层的主要区别在于其输入特征图的尺寸、其过滤器的数量和大小以及应用于过滤器的步幅。
池化层(pool)——池化层在输入特征图的区域上应用预定义函数(例如max或average)将特征组合在一起。这些层主要在其输入的维度、池化区域的大小以及应用池的步幅方面有所不同。
激活层——激活层将非线性函数分别应用于其每个输入数据,生成与输出相同数量的数据。神经网络的激活层包括sigmoid层(sig)、线性整流层(relu)和硬Tanh层(htanh)。
本文研究的其他层包括:正则化层(norm)对空间分组特征图中的特征进行正则化;softmax层(softmax)在分类的可能类上产生概率分布;argmax层(argmax)选择概率最高的类;而随机失活层(dropout)在训练过程中随机忽略神经元,避免模型过度拟合,并在预测过程中被传播。
4.2 Characterizing Layers in AlexNet
首先研究了AlexNet中各层的数据和计算特性。这些特性提供了在层级找到移动和云之间更好的计算划分的见解。在本节和后续章节的其余部分中,我们将在移动和云平台中使用GPU。
层级延迟——图5中的左栏(浅色)显示移动平台上每个层的延迟,按顺序从左到右排列。卷积层(conv)和全连接层(fc)是最耗时的层,占总执行时间的90%以上。中间部分的卷积层(conv3和conv4)比前一部分的卷积层(conv1和conv2)需要更长的执行时间。在DNN的后一部分,卷积层应用了大量的滤波器,逐步提取出更具鲁棒性和代表性的特征,增加了计算量。另一方面,全连接层比网络中的卷积层慢一个数量级。最耗时的层是fc6层,它是DNN中一个全连接层,占总执行时间的45%。
数据大小变化——图5中的右栏(深色)显示了每一层输出数据的大小,这也是下一层的输入。前三个卷积层(conv1、conv2和conv3)生成大量的输出数据(显示为最大的深色条),因为它们在输入特征图上应用数百个过滤器来提取有趣的特征。通过激活层(relu1-relu5),数据大小保持不变。池化层极大地减少了数据大小,高达4.7倍,因为他们总结了最大的相邻特征的区域。网络中更深的全连接层(fc6-fc8)逐渐减小数据大小,直到最后的softmax层(softmax)和argmax层(argmax)将数据减少为一个分类标签。
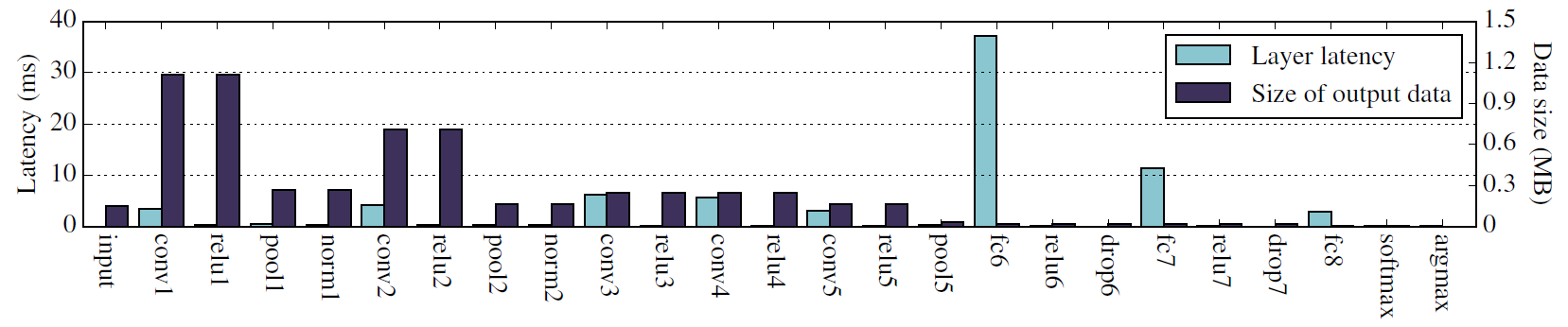
关键观察——1)根据其在网络中的类型和位置,每一层都有不同的计算和数据剖面。2)移动GPU上卷积层和池化层的延迟相对较小,而全连接层的延迟较高。3)卷积层和池化层主要位于网络的前端,而全连接层则位于后端。4)随着卷积层增加数据量,然后池化层减少数据量,前端层逐渐减小数据量。最后几层中的数据大小小于原始输入。5)前端数据量普遍减小,后端每层移动延迟普遍较高,这说明在移动与云之间的DNN中间有独特的计算划分机会。
4.3 Layer-granularity Computation Partitioning
第4.2节的分析表明,在神经网络中存在有趣的点来划分计算。在本节中,我们将探讨在移动和云之间的每一层对AlexNet进行划分。在本节中,我们使用Wi-Fi作为无线网络配置。
图6a中的每个条表示AlexNet的端到端延迟,在每个层之后进行划分。类似地,图6b中的每个条表示Alexnet的移动能耗,在每个层之后进行划分。在特定层之后进行计算划分意味着在移动设备上执行DNN到该层,通过无线网络将该层的输出传输到云,并在云中执行其余层。最左边的条表示发送原始输入进行纯云处理。当分割点从左向右移动时,在移动设备上执行更多层,因此存在越来越大的移动处理部分。最右边的条是在移动设备上本地执行整个DNN的延迟。
延迟划分——如果在前端划分,则数据传输控制端到端延迟,这与我们在第4.2节中的观察一致,即数据大小在DNN前端是最大的。后端的划分提供了更好的性能,因为应用程序可以最小化数据传输开销,同时利用功能强大的云在后端执行计算量更大的层。在使用移动GPU和Wi-Fi的AlexNet的情况下,最后一个池化层(pool5)和第一个全连接层(fc6)之间的划分实现了最低的延迟,如图6a所示,比纯云处理改进了2.0倍。
能量划分——类似于延迟,由于无线数据传输的高能量成本,传输输入用于纯云处理不是最节能的方法。如图6b所示,DNN中间的划分实现了最佳的移动能耗,比纯云计算的方法节能18%。
关键观察结果——在层粒度上进行划分可以提供显著的延迟和能效改进。对于使用GPU和Wi-Fi的AlexNet,最好的划分点在DNN的中间层之间。

4.4 Generalizing to More DNNs
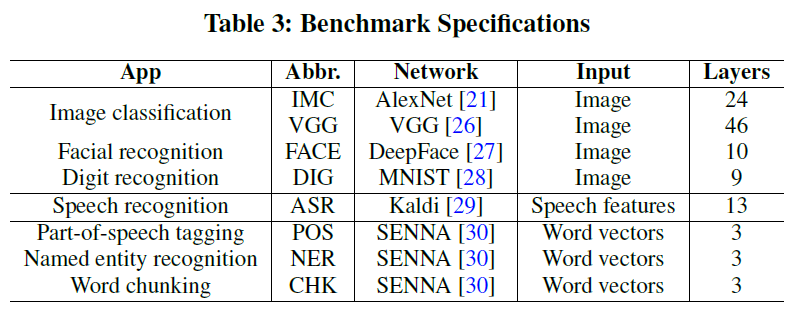
我们将研究扩展到7个更智能的应用程序,以研究它们的数据和计算特性及其对计算划分机会的影响。我们使用Tonic suite[9]中提供的DNNs以及VGG(一种最先进的图像分类DNN)和LTE作为无线网络配置。关于基准的详细信息见表3。我们计算每个DNN从第一个非输入层到最后一个层的层数,包括argmax(如果存在)。
CV应用程序——剩余的三个计算机视觉DNN(VGG、FACE和DIG)具有与AlexNet(图5)相似的特性,如图7a-7c所示。前端层是增加数据的卷积层,池化层减少数据。后端层中的数据大小与原始输入数据相似或更小。后端层的延迟高于大多数前端层(例如,fc6是VGG中最耗时的层),除了DIG是卷积层最耗时。与AlexNet类似,这些特性表明DNN的中间存在划分机会。图8a显示了VGG最佳延迟的划分点在中间层。此外,图8a-8c显示不同的CV应用程序具有不同的最佳延迟划分点,图9a-9c显示这些DNN的最佳能量划分点。

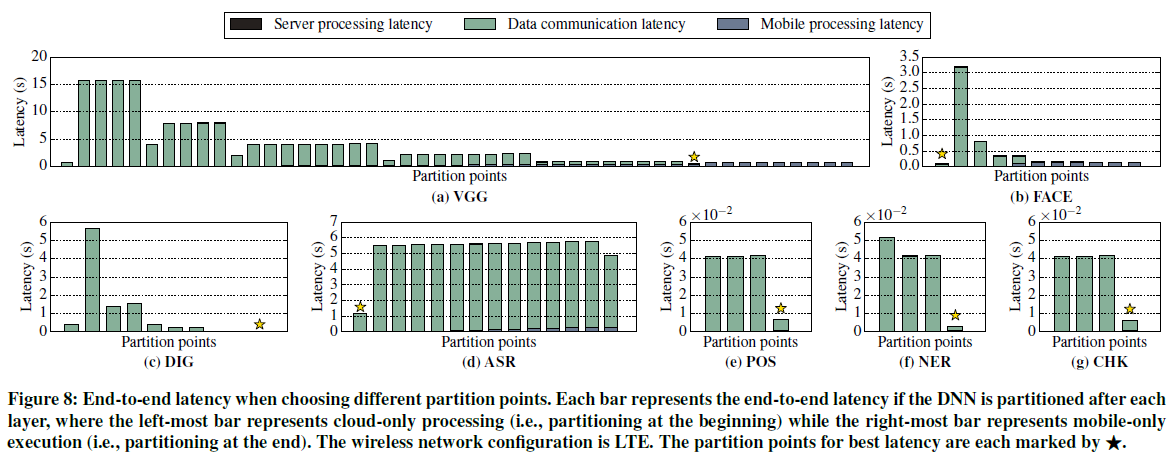
ASR和NLP应用程序——套件中的其余四个DNN(ASR、POS、NER和CHK)仅由全连接层和激活层组成。层分解如图7d-7g所示,其中,在整个执行过程中,相同类型的层产生相似的延迟,并且数据大小保持相对恒定,除了每个DNN的第一层和最后一层。这些DNNs没有数据增加层(即卷积层)或数据减少层(即池化层)。因此,在这些网络的末端存在计算划分的机会。图8d-8g和图9d-9g分别显示了这些DNNs的最佳延迟和能量的不同划分点。对于这些应用程序,最右边的栏中有数据通信部分(仅移动处理),因为DNN的输出被发送到云中,用于这些应用程序所需的后处理步骤。

关键观察结果——1)在具有卷积层和池化层的DNNs(例如计算机视觉应用)中,卷积层后的数据大小增加,池化层后的数据大小减少,而每层计算通常在执行过程中增加。2)只有具有相似大小的全连接层和激活层的DNNs在每层延迟和数据大小上变化较小(例如ASR和NLP DNNs)。3)DNN的最佳划分方法取决于其拓扑结构和组成层。计算机视觉DNNs有时在DNN的中间有较好的划分点,而对于ASR和NLP DNNs在开始或结束时进行划分更为有利。最佳划分点的强烈变化表明,需要一个基于神经网络架构的系统在移动和云之间划分DNN计算。
5. Neurosurgeon
DNN结构的最佳划分点取决于DNN的拓扑结构,它体现在每一层的计算和数据大小的变化上。此外,即使在相同的DNN结构下,无线网络的状态和数据中心的负载等动态因素也会影响最佳划分点。例如,移动设备的无线连接经常经历高方差[31],直接影响数据传输延迟。数据中心通常会经历日间负载模式[32],这导致其DNN查询服务时间的高度差异。由于这些动态因素,需要一个自动系统智能地选择最佳点来划分DNN,以优化端到端的延迟或移动设备的能耗。为了满足这一需求,我们设计了一种智能DNN划分引擎,Neurosurgeon。Neurosurgeon由一个部署阶段和一个实时系统组成,用于管理智能应用程序的划分执行。图10显示了Neurosurgeon的设计,它有两个阶段:部署和实时。
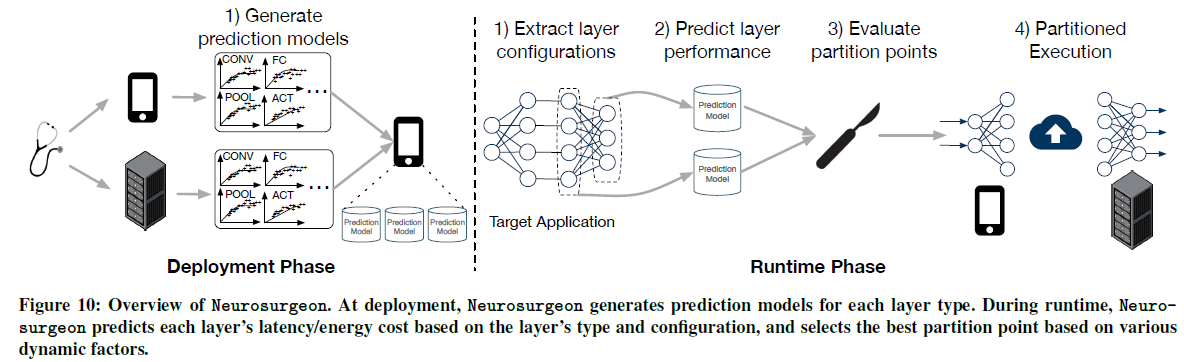
部署——Neurosurgeon对移动设备和服务器进行配置,以生成DNN层类型频谱的性能预测模型(在第4.1节中列举)。请注意,Neurosurgeon的分析是应用程序不可知的,只需要对给定的一组移动和服务器平台执行一次;不需要对每个应用程序进行分析。这组预测模型存储在移动设备上,随后用于预测每个层的延迟和能量成本(第5.1节)。
实时——在移动设备上执行基于DNN的智能应用程序期间,Neurosurgeon动态地确定DNN的最佳划分点。如图10所示,步骤如下:1)Neurosurgeon分析并提取DNN架构的层类型和配置;2)系统使用存储的层性能预测模型来估计在移动和云上执行每个层的延迟和能耗;3)结合这些预测在当前无线连接带宽和数据中心负载水平下,Neurosurgeon选择最佳划分点,优化最佳端到端延迟或最佳移动能耗;4)Neurosurgeon执行DNN,在移动和云之间划分工作。
5.1 Performance Prediction Model
Neurosurgeon对任意神经网络结构的每层延迟和能量消耗进行建模。这种方法允许Neurosurgeon在不执行DNN的情况下估计DNN组成层的延迟和能量消耗。
我们观察到,对于每种层类型,不同层配置有很大的延迟变化。因此,为了构造每种层类型的预测模型,我们改变层的可配置参数,并测量每种配置的延迟和功耗。利用这些剖面,我们为每种层类型建立了一个回归模型,以根据其配置预测层的延迟和功耗。我们将在本节后面描述每一层的回归模型变量。我们使用GFLOPS(每秒千兆浮点运算)作为性能度量。根据层类型,我们使用对数函数或线性函数作为回归函数。当层的计算需求接近可用硬件资源的极限时,使用基于对数的回归对性能平台进行建模。
卷积层、局部层和池化层的可配置参数包括输入特征图维数、滤波器数目、滤波器大小和步长。卷积层的回归模型基于两个变量:输入特征图中的特征数量和(滤波器大小/步长)2 × (滤波器数量),后者表示应用于输入特征图中每个像素的计算量。对于局部层和池化层,我们使用输入和输出特征图的大小作为回归模型变量。
在全连接层中,输入数据乘以所学习的权重矩阵以生成输出向量。我们使用输入神经元和输出神经元的数目作为回归模型变量。Softmax和argmax层的处理方式类似。
与其他层相比,激活层具有较少的可配置参数,因为激活层在其输入数据和输出之间具有一对一的映射。我们使用神经元数目作为回归模型变量。我们对正则化层应用同样的方法。
如前所述,这是每个移动和服务器硬件平台生成一组预测模型所需的一次性分析步骤。这些模型使Neurosurgeon能够根据其配置估计每一层的延迟和能量成本,这使得Neurosurgeon能够支持未来的神经网络架构,而无需额外的剖析开销。
5.2 Dynamic DNN Partitioning
利用层性能预测模型,Neurosurgeon动态选择最佳DNN划分点,如算法1所述。该算法分为两步:目标DNN分析和划分点选择。
分析目标DNN——Neurosurgeon分析目标DNN的组成层,并使用预测模型估计每一层在移动和云上的延迟,以及在移动上的功耗。具体来说,在算法1的第11行和第12行,Neurosurgeon提取每个层的类型和配置(Li),并使用回归模型预测在移动(TMi)和云(TCi)上执行层Li的延迟,同时考虑当前数据中心负载水平(K)。第13行估计在移动设备上执行层Li的功耗(PMi),第14行基于最新的无线网络带宽计算无线数据传输延迟(TUi)。
划分点选择——Neurosurgeon然后选择最佳划分点。候选点位于每一层之后。第16行和第18行评估在每个候选点进行划分时的性能,并为最佳端到端延迟或最佳移动能耗选择点。由于回归模型的简单性,此评估是轻量级和高效的。

5.3 Partitioned Execution
我们通过创建Caffe[18]的修改实例作为我们的移动端(NSmobile)和服务器端(NSserver)基础设施,来创建Neurosurgeon的原型。通过Caffe的这两个变体,我们使用Turffs[33]实现了我们的客户端-服务器接口,这是一个开放源码的RPC接口,用于进程间通信。为了允许动态选择划分点,NSmobile和NSServer主机都完成DNN模型,划分点由NSmobile和NSServer运行时强制执行。给定NSmobile的划分决策,执行从移动设备开始,并通过DNN的各层级联到该划分点。完成该层后,NSmobile将该层的输出从移动设备发送到位于服务器端的NSserver。然后,NSserver执行其余DNN层。DNN执行完成后,最终结果从NSserver发送回移动设备上的NSmobile。请注意,DNN中只有一个划分点,移动设备向云发送信息。
6. Evaluation
我们评估Neurosurgeon使用8个DNNs(表3)作为我们在Wi-Fi、LTE和3G无线连接中的基准,这些连接都是仅使用CPU和GPU的移动平台。我们证明Neurosurgeon对只使用云计算的方法(第6.1节和第6.2节)实现了显著的端到端延迟和移动能量的改进。然后我们将Neurosurgeon与MAUI[34]进行比较,MAUI[34]是一个著名的计算转移框架(第6.3节)。我们还评估了Neurosurgeon对无线网络连接(第6.4节)和服务器负载(第6.5节)变化的鲁棒性,证明了这种动态实时系统的必要性。最后,我们评估Neurosurgeon通过将计算从云端推送到移动设备来实现的数据中心吞吐量改进(第6.6节)。
6.1 Latency Improvement
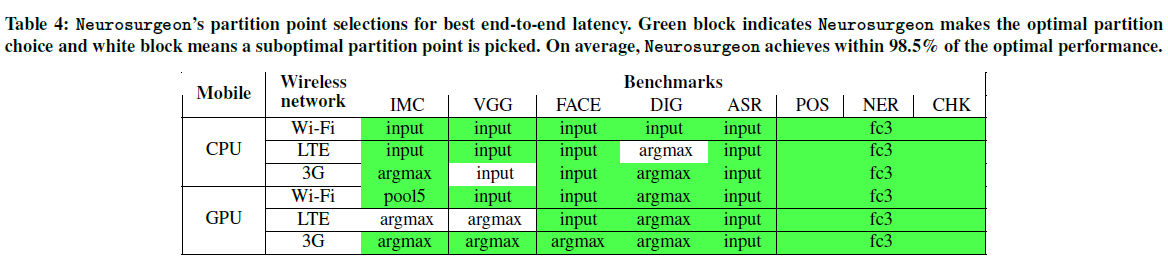
划分点选择——表4总结了Neurosurgeon在48种配置(即8个基准、3种无线网络类型、移动CPU和GPU)的延迟优化选择的划分点。绿色格子表示Neurosurgeon何时选择最佳划分点并达到最佳加速,而白色格子表示Neurosurgeon何时选择次优划分点。Neurosurgeon从48种配置中选出44种配置的最佳划分点。预测失误的发生是因为划分点及其相关性能彼此非常接近,因此Neurosurgeon的延迟预测中的微小差异会改变选择。在所有的基准和配置中,Neurosurgeon在最佳加速的98.5%内实现延迟加速。
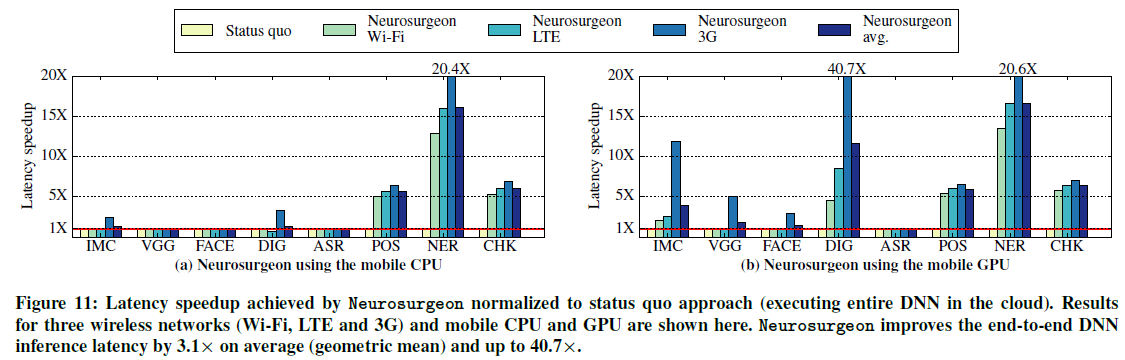
延迟改善——图11显示Neurosurgeon在Wi-Fi、LTE和3G上的8个基准上相对于目前方法的延迟改善。图11a显示Neurosurgeon在配备CPU的移动平台上应用时的延迟改善,图11b显示具有GPU的移动平台。对于CV应用,Neurosurgeon为24例中的20例确定了最佳划分点,并实现了显著的延迟加速,特别是当移动GPU可用时。对于NLP应用程序,Neurosurgeon甚至在Wi-Fi可用的情况下也能实现显著的延迟加速。对于ASR,Neurosurgeon成功地识别出最好是完全在服务器上执行DNN,因此Neurosurgeon的表现与该特定基准的现状类似。在所有的基准和配置中,Neurosurgeon平均达到3.1倍的延迟加速,比目前方法最多高出40.7倍。
6.2 Energy Improvement
划分点选择——表5总结了Neurosurgeon确定的最佳移动能量划分点。Neurosurgeon从48种配置中选出44种配置的最佳划分点。对于次优选择,Neurosurgeon的平均能耗比当前方法低24.2%。
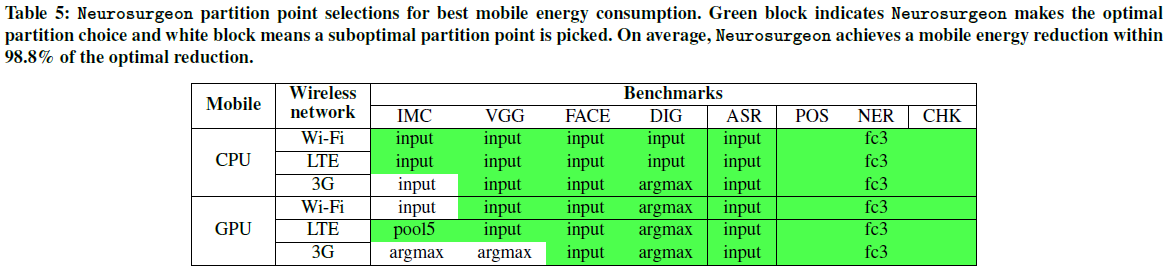
能源改善——图12显示了Neurosurgeon实现的移动能源消耗,并将其标准化为当前方法。图12a和12b分别显示了仅限CPU的移动平台和配备GPU的移动平台的结果。在优化最佳能源消耗时,Neurosurgeon的移动能源平均减少了59.5%,最多比当前方法减少了94.7%。与延迟的改善类似,当移动平台配备GPU时,大多数基准测试的能耗降低也更高。
6.3 Comparing Neurosurgeon to MAUI
在本节中,我们将Neurosurgeon与MAUI[34]进行比较,MAUI[34]是一个通用的转移框架。注意,MAUI是以控制为中心的,对代码区域(函数)进行推理和决策,而Neurosurgeon是以数据为中心的,根据数据拓扑结构进行划分决策,即使调用了相同的代码区域(函数),数据拓扑结构也可能不同。
图13显示了Neurosurgeon在执行8个DNN基准测试时(平均在三种无线网络类型中)标准化为MAUI所实现的延迟加速。图13a显示了将MAUI和Neurosurgeon应用于仅限CPU的移动平台时的结果,图13b显示了在配备GPU的移动平台上的结果。在这个实验中,我们假设对于MAUI,程序员已经最优地注释了需要传输的最小程序状态。

图13显示Neurosurgeon在计算机视觉应用上的表现明显优于MAUI。对于NLP应用,Neurosurgeon和MAUI都正确地认为移动设备上的本地计算是最优的。然而,MAUI对于更复杂的场景(例如VGG、FACE、DIG和ASR)做出了错误的转移选择。这是因为MAUI依赖于某个DNN层类型的过去调用来预测该层类型的未来调用的延迟和数据大小,从而导致预测失误。这种以控制为中心的预测机制不适用于DNN层,因为同一类型层的延迟和数据大小在一个DNN中可能有很大的不同,Neurosurgeon的DNN分析步骤和预测模型正确地捕捉了这种变化。例如,在VGG中,第一和第二卷积层的输入数据大小明显不同:conv1.1为0.57MB,conv1.2为12.25MB。对于移动CPU和LTE,MAUI决定在conv1.2之前转移DNN,这是由于DNN的预测失误,上载了大量数据,导致其速度比现有方法慢了20.5倍。同时,Neurosurgeon成功地发现,在这种情况下,最好完全在云中执行DNN,从而获得与目前方法相似的性能,并比MAUI快了20.5倍。
6.4 Network Variation
在这一部分中,我们评估Neurosurgeon对现实世界测量的无线网络变化的弹性。在图14中,顶部的图显示了一段时间内T-Mobile LTE网络的测量无线带宽。底部的图显示了当前方法和Neurosurgeon在移动CPU平台上执行AlexNet(IMC)的端到端延迟。底部的图注释是Neurosurgeon的动态执行选择,分为本地、远程或划分。目前的方法很容易受到网络变化的影响,因此在低带宽阶段应用程序的延迟会显著增加。相反,Neurosurgeon通过改变划分选择,根据可用带宽调整数据传输量,成功地减轻了大变化的影响,并提供一致的低延迟。

6.5 Server Load Variation
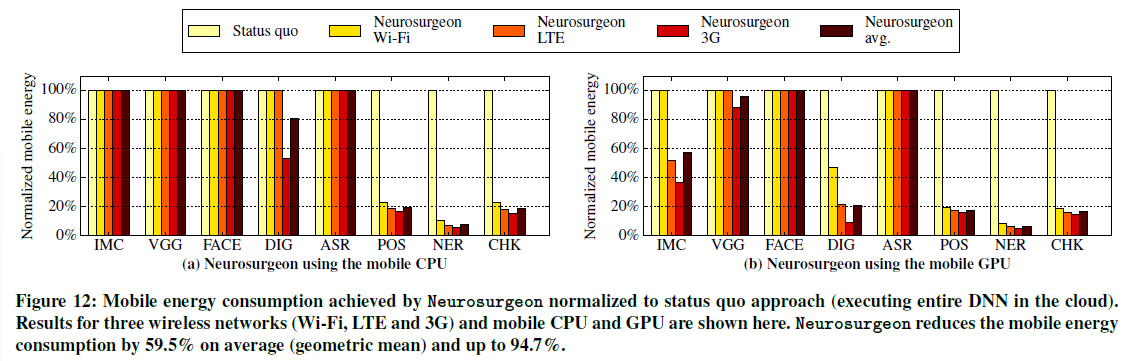
在本节中,我们将评估Neurosurgeon如何在服务器负载变化时做出动态决策。数据中心通常会经历日间负载模式,高服务器利用率导致DNN查询的服务时间增加。Neurosurgeon根据空闲期间定期ping服务器得到的当前服务器负载水平来确定最佳划分点,从而避免了高用户需求和由此产生的高负载造成的长延迟。
图15显示了随着服务器负载的增加,通过当前方法和Neurosurgeon实现的AlexNet(IMC)端到端延迟。移动设备配有CPU,并通过Wi-Fi传输数据。如图所示,当前方法不能动态地适应不同的服务器负载,因此在服务器负载高的情况下性能会显著下降。随着服务器接近峰值负载水平,当前方法的端到端延迟从105ms增加到753ms。另一方面,在考虑服务器负载的情况下,Neurosurgeon动态地调整划分点。在图15中,两条垂直虚线表示Neurosurgeon改变其选择的点:从低负载时的完全在云端执行,到中等负载时在移动端和云端之间划分DNN,最后在峰值负载时完全转移到移动端。无论服务器负载如何,Neurosurgeon将执行图像分类的端到端延迟保持在380ms以下,通过考虑服务器负载及其对服务器性能的影响,Neurosurgeon始终提供最佳的延迟,而不考虑服务器负载的变化。
6.6 Datacenter Throughput Improvement
Neurosurgeon将部分或全部计算从云上传到移动设备,以改善端到端的延迟并降低移动能耗。这种新的计算范式减少了数据中心所需的计算,从而缩短了查询服务时间,提高了查询吞吐量。在本节中,我们将评估Neurosurgeon在这方面的有效性。我们使用BigHouse[38]来比较当前方法和Neurosurgeon之间的数据中心吞吐量。传入的DNN查询平均由基准套件中的8个DNNs组成。我们将DNN查询的平均服务时间与Google web搜索的查询分布相结合来计算查询的到达率。
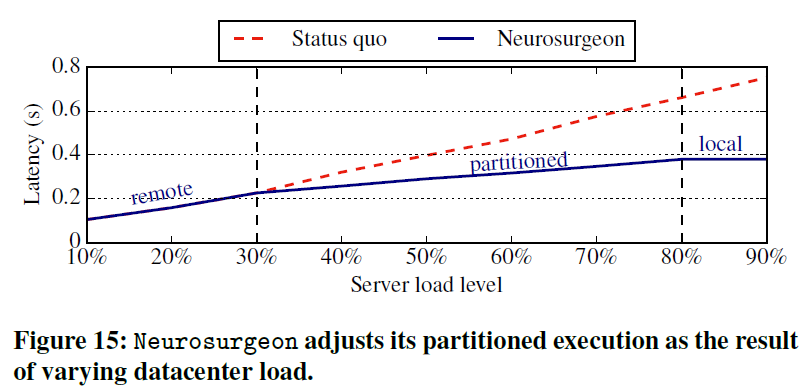
图16显示了神经外科医生实现的数据中心吞吐量改进,该改进与在服务器上执行整个计算的基线现状方法标准化。每个集群显示给定无线网络类型的结果。在每一个集群中,第一个条代表了当前的仅云方法,而其他四个条代表了具有不同组成的移动硬件的神经外科医生。例如,“30%移动GPU用户”表示30%的传入请求来自配备GPU的移动设备,而其余70%来自仅配备CPU的设备。
当移动客户端通过快速Wi-Fi网络连接到服务器时,Neurosurgeon的平均吞吐量提高了1.04倍。随着无线连接向LTE和3G的转变,其吞吐量的提高变得更加显著:LTE的吞吐量提高了1.43倍,3G的吞吐量提高了2.36倍,Neurosurgeon调整了其划分选择,随着无线连接质量的降低,DNN计算的大部分被转移到移动设备上。因此,数据中心的平均请求查询服务时间缩短,吞吐量提高。我们还观察到,随着带有GPU的移动设备百分比的增加,Neurosurgeon增加了从云端到移动端的计算负载,从而提高了数据中心的吞吐量。
7. Related Work
以前的研究工作集中在将计算从移动设备转移到云上。在表6中,我们比较了Neurosurgeon和属性最相关的技术,包括是否有大量的数据传输开销、以数据为中心还是以控制为中心的划分、低的实时开销、是否需要特定于应用程序的分析以及是否需要程序员的注释。

除了这些关键区别之外,计算划分框架还必须对何时转移计算进行预测,预测的正确性决定了应用程序的最终性能改进。COMET[35]在线程的执行时间超过预定义阈值时转移线程,忽略任何其他信息(要传输的数据量、可用的无线网络等)。Odessa[36]只考虑部分函数的执行时间和数据需求,而不考虑整个应用程序,做出计算划分决策。CloneCloud[37]为同一函数的所有调用做出相同的转移决策。MAUI[34]的转移决策机制更好,因为它分别对每个函数调用进行预测,并在选择转移哪个函数时考虑整个应用程序。然而,MAUI不适用于Neurosurgeon执行的计算划分,原因有很多:1)MAUI需要为每个单独的应用程序执行一个分析步骤,而执行DNN划分需要进行预测。Neurosurgeon根据DNN拓扑结构进行决策,而无需任何实时分析。2)MAUI是以控制为中心,对代码区域(功能)进行决策,而神经外科医生根据数据拓扑结构进行划分决策,即使执行相同的代码区域(功能),数据拓扑结构也可能不同。在一个DNN中,给定类型的层(即使映射到同一个函数)可以具有显著不同的计算和数据特性。3)Neurosurgeon只传输正在处理的数据,而不是传输所有程序状态。4)MAUI要求程序员注释他们的程序,以确定哪些方法是“可转移的”。
除了之前研究数据中心系统的利用率和效率的工作[39-52]外,人们越来越关注为深度神经网络工作负载构建大型数据中心系统。为了更好地处理DNN计算,已经为数据中心提出了各种加速器,如GPUs、ASICs和FPGAs[9、53-55]。在设计适用于移动边缘的紧凑型DNN方面也有研究做出了努力。微软和谷歌在移动平台上探索用于语音识别的小规模DNNs[56,57]。MCDNN[58]提出生成替代DNN模型,以权衡性能/能量的准确性,并选择在云端或移动端执行。本文研究了移动设备和云之间的智能协作,以在不牺牲DNNs的高预测精度的前提下,实现传统的只使用云计算的大规模DNNs,从而减少延迟和能耗。
8. Conclusion
作为当今智能应用的重要组成部分,深度神经网络传统上是在云端执行的。在这项工作中,我们检验了这种纯云处理的当前方法的有效性,并表明将输入数据传输到服务器并远程执行DNN并不总是最优的。我们研究了8种DNN体系结构的计算和数据特性,包括计算机视觉、语音和自然语言处理应用,并给出了神经网络中不同点的划分计算的权衡。基于这些见解,我们开发了Neurosurgeon,一个能够在移动设备和云之间以神经网络层的粒度自动划分DNN的系统。Neurosurgeon适应各种DNN架构、硬件平台、无线连接和服务器负载水平,并选择最佳延迟和最佳移动能耗的划分点。在8个基准测试中,与纯云处理相比,Neurosurgeon的平均改善为3.1倍,最高可达40.7倍;移动能耗平均降低59.5%,最高可达94.7%;数据中心吞吐量平均提高1.5倍,最高可达6.7倍。