0. 背景:
1. 本文重點在於xpath在python爬蟲中的使用方法,有關概念性的所有問題將不會提及
2. 本文將涉及的python語法,HTML相關知識,requests庫的使用方法也不會做額外的說明
3. 本文只講述xpath的最簡單使用,其進階使用方法本文不做涉及(有機會在以後的文章中說)
1. 基礎知識:
1.1. 安裝
安裝xpath使用命令安裝即可
pip install lxmlii /: 從當前節點直接選擇子節點
//: 從當前節點選取子孫節點
.: 選取當前節點
..:選取當前節點的父親節點
@選取屬性
2. 在實際應用中學習:
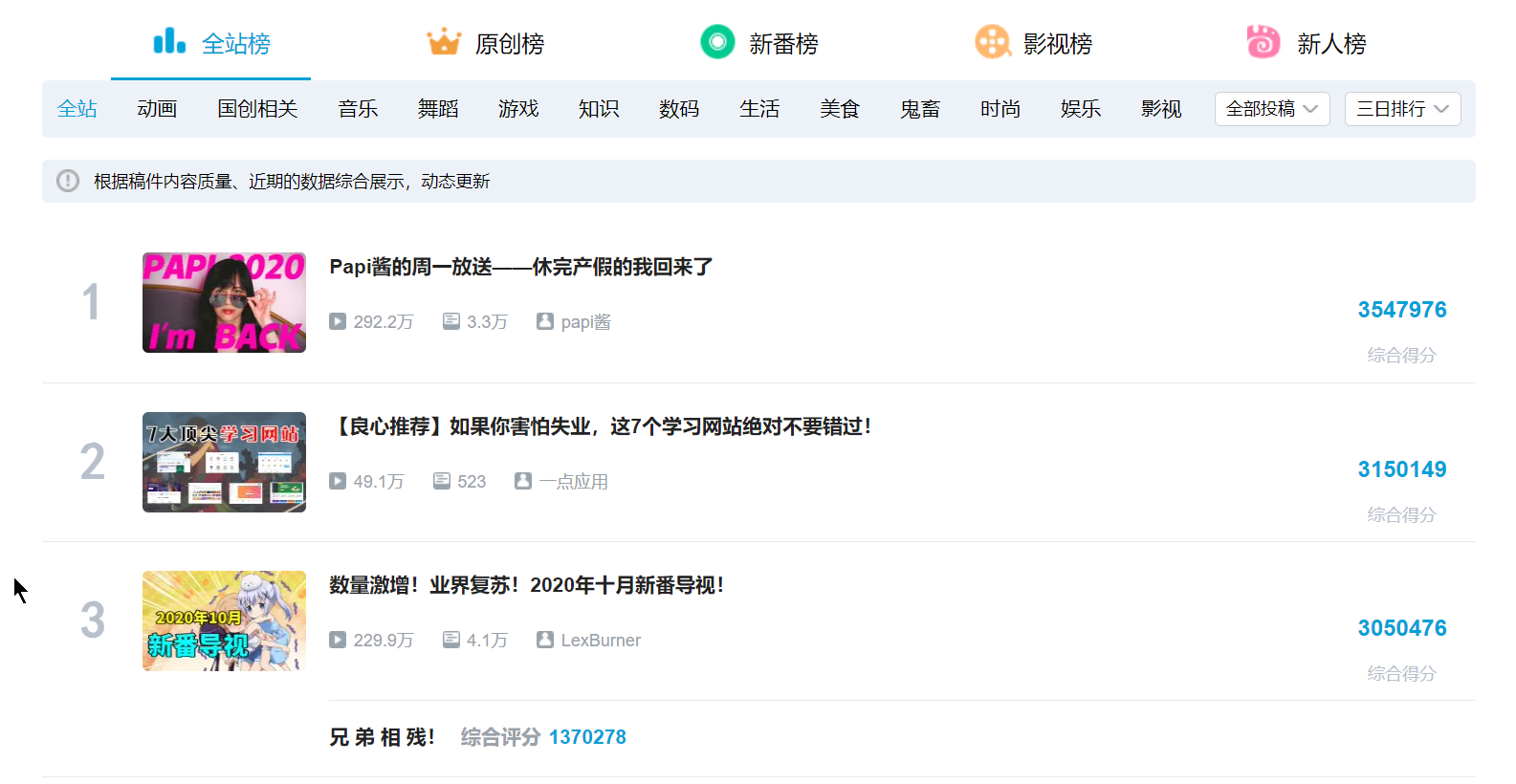
這裡我們以B站排行榜為爬取對象進行學習(因為B站對爬蟲很友好).下面即是我們將要爬取的頁面.
2.0. 導入必要的庫
import requests from lxml import etree
2.1. 發起請求,獲取頁面數據:
url = 'https://www.bilibili.com/ranking' try: res = requests.get(url) res.raise_for_status()
res.encoding = res.encoding if res.encoding == res.apparent_encoding else res.apparent_encoding src = res.text except: print('Check your code, please!!')
2.3. 頁面數據解析
使用etree對源碼進行解析,十分簡單,上面已經將獲得的源碼存入src,現在只需要將其傳遞給函數etree.HTML函數即可
html = etree.HTML(src)
如果是本地文件,則使用如下解析方式,只需要把path換成文件路徑即可
html = etree.parse('path', etree.HTMLParser())
2.4. 獲取特定數據
數據解析好了,現在需要提取數據.
1. 獲取頁面的標題:
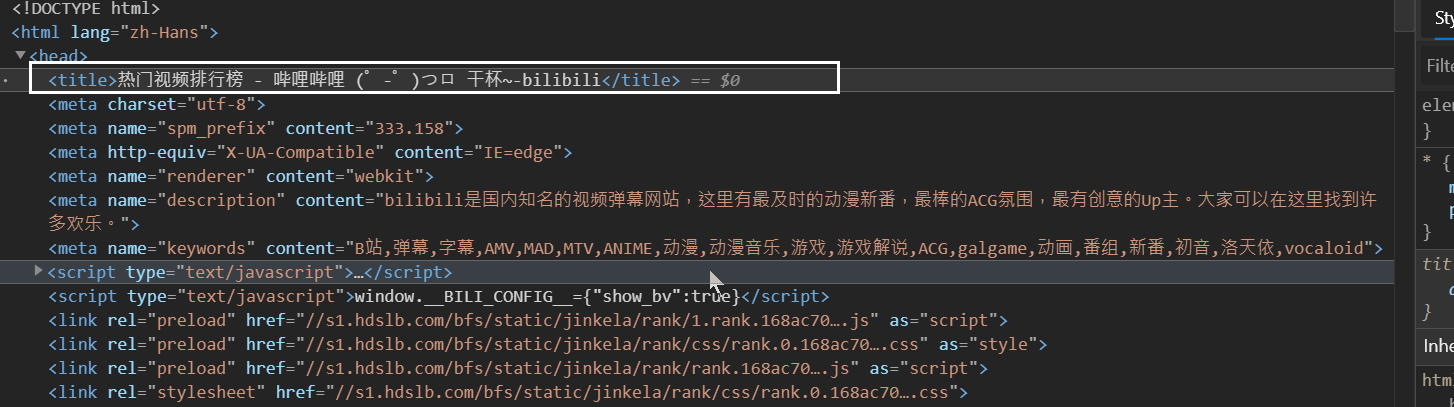
title = html.xpath('/html/head/title/text()')
如果輸出title的值就是: ['热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili']
解釋:
提取數據就是在xpath函數函數當中填入賽選條件(表達式),那麼這個表達式是什麼意思呢?我們先對照在1.2當中的內容發現:
可以發現括號內的表達式應該是:
在當前頁面下搜索html節點,然後在html節點下面搜索head節點,接著在hrad節點下面搜索title節點,然後獲取它的內容
ps: text()是獲取文本的含義
是不是很簡單?不管你找什麼內容,知道知道它在文本中的什麼地方,都可以通過這種方式找到.
如果你覺得用眼睛看不過來,可以在瀏覽器中使用鼠標右鍵打開元素檢查(inspect),然後找到要找的標籤,並且鼠標右鍵單擊標籤,然後複製其xpath代碼,最後粘貼到括號當中即可.
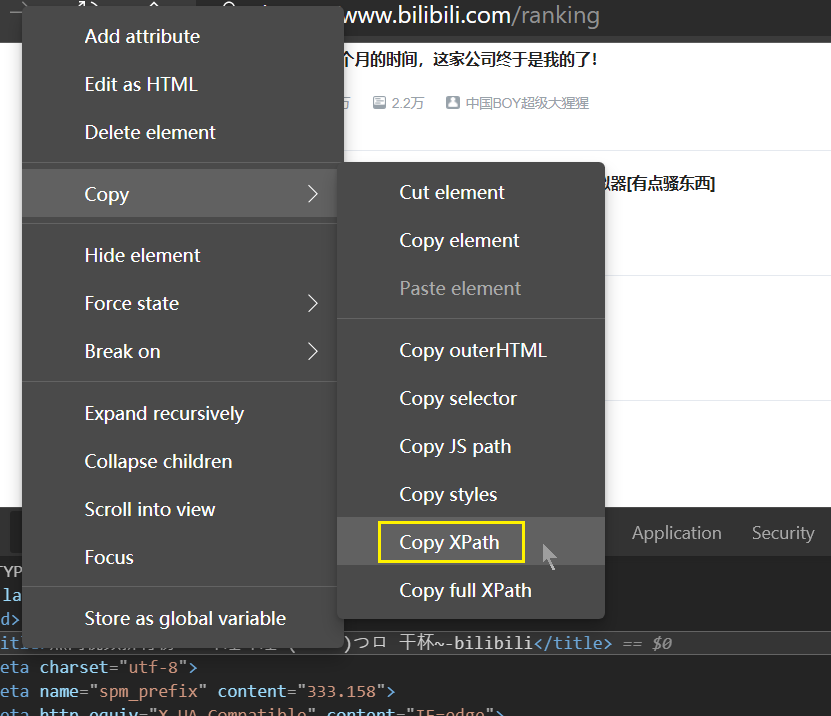
複製的結果:
/html/head/title
2. 提取所有熱門視屏的標題:
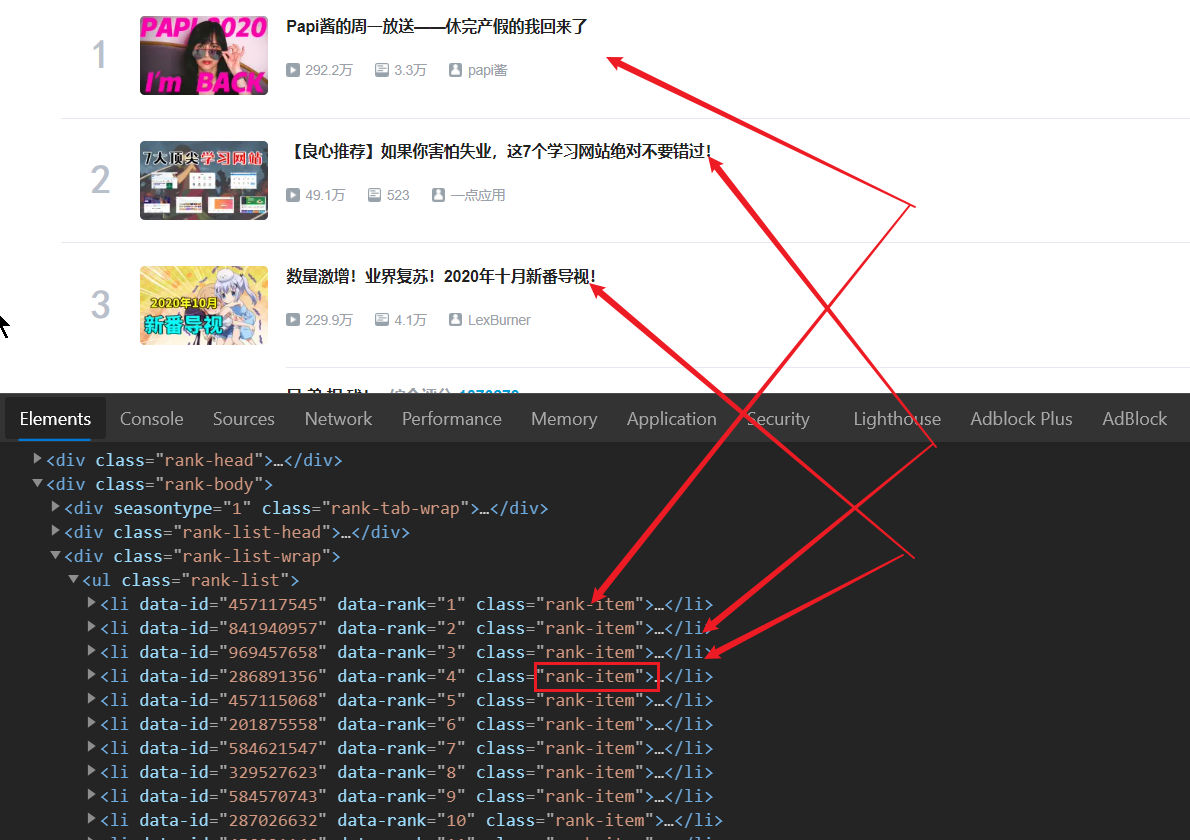
我們先觀察一下,發現其實每一條視頻都對應著html中的一個li標籤,而這些標籤都有一個相同的class屬性.所以想要賽選出這些li標籤不一定非要像第一次那樣一層一層的往下找(雖然沒問題,但是會讓表達式冗長),我們可以通過class屬性來直接過濾.這也就是我們要學的東西,利用屬性進行篩選.
vtitile = html.xpath('//li[@class = "rank-item"]')
這樣我們就已經獲得了這些所有li標籤(裡可以輸出len(vtitile)查看li的個數,如果是100那麼就是正確的,如果不是少了說明有的標籤沒有取到,說明賽選條件不對,如果多了,說明篩選條件過寬,有些沒有被過濾掉--因為B站的熱門視屏是100個,所以才是100,其他情況見機行事),
現在我們已經取得這個這些標籤,那麼要怎麼獲取視屏的標題呢?我們將標籤展開來看:
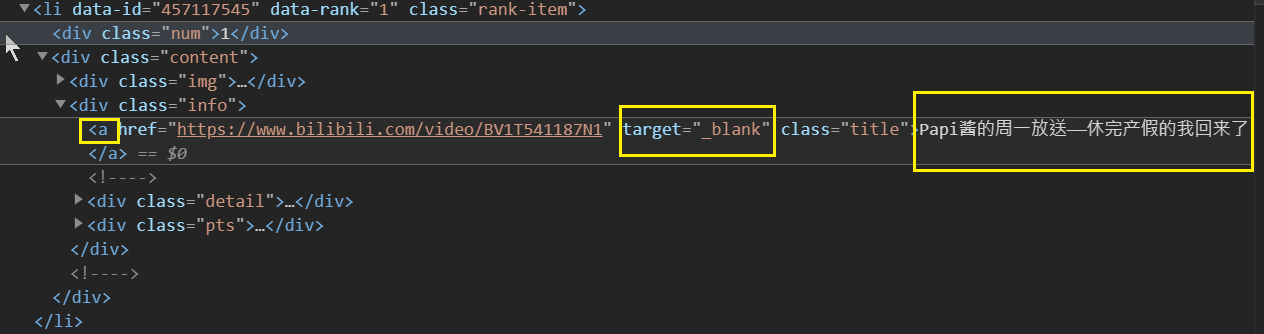
發現標題是在li標籤的一個a標籤中,這個a標籤還有一個名為target屬性,所以我們在上面的基礎上再次篩選:
vtitile = html.xpath('//li[@class = "rank-item"]//a[@target = "_blank"]/text()')
然後你輸出vtitile就能得到所有視屏的標題.
3. 獲取B站的關鍵字:
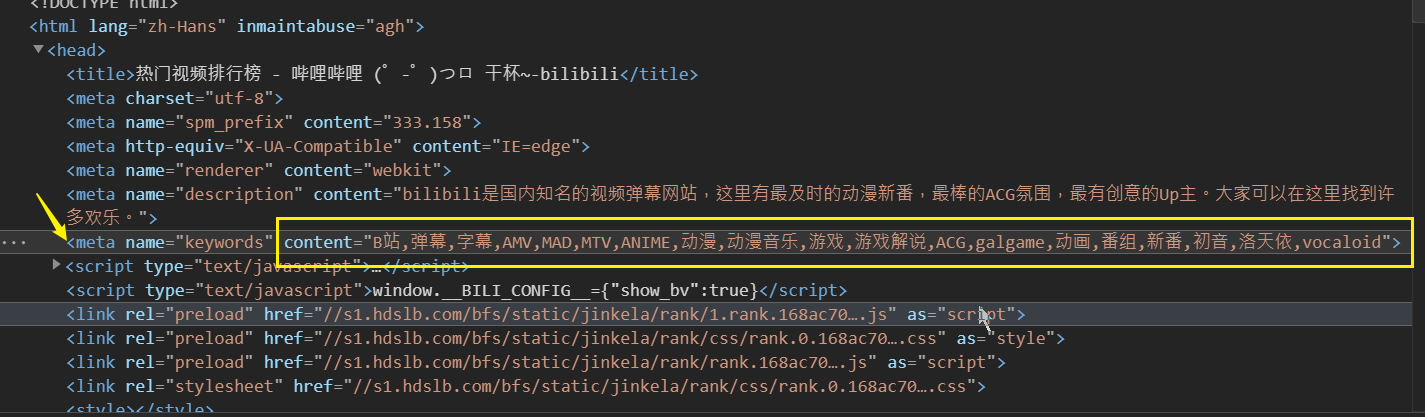
如圖,B站的關鍵字都在一個名為keywords的meta標籤的content屬性中,所以我們這次只需要獲取這個屬性的內容即可.
- 我們先找到這個標籤,由於其層級高,所以直接使用絕對路徑搜索即可
- 由於有多個meta標籤,所以依舊需要使用屬性進行篩選
- 最後即可獲屬性
keyword = html.xpath('/html/head/meta[@name = "keywords"]/@content')
你只需要@你需要的屬性就能就能獲取的對應的值
3. 最後:
三個超級簡單的小案例,掌握xpath的2個基本作用:
- 獲取指定節點(標籤)的文本內容
- 獲取指定節點的屬性值
但是這樣已經能夠滿足你的絕大多數需求,想要深入學習可以自己找一些相關資料.