一个Spark应用开发的简单例子
这个实验楼上的项目题目是某年《高校云计算应用创新大赛》里的最后一道题,题目是莎士比亚文集词频统计并行化算法。下面是我通过实验楼的教程的学习记录。
我需要做的准备工作
复习编程模型
Spark 上开发的应用程序都是由一个driver programe构成,这个所谓的驱动程序在 Spark 集群通过跑main函数来执行各种并行操作。集群上的所有节点进行并行计算需要共同访问一个分区元素的集合,这就是 RDD(RDD resilient distributed dataset)弹性分布式数据集。RDD 可以存储在内存或磁盘中,具有一定的容错性,可以在节点宕机重启后恢复。RDD 可以从文件系统或 HDFS 中的文件创建,也可以从 Scala 集合中创建。
在这个项目里面编程的步骤是:
- 提取数据到 RDD 中,在本实验中我们将莎士比亚文集和停词表文件转换成 RDD。
- 转换(transformations)操作,将已存在的数据集转换成新的数据集,例如 map。转换是惰性的,不会立刻计算结果,仅仅记录转换操作应用的目标数据集,当动作需要一个结果时才计算。在本实验中我们需要转换文集 RDD 和停词表 RDD。
- 动作(actions):数据集计算后返回一个值给驱动程序,例如 reduce。本实验中需要对统计词频 map 的结果进行 reduce 操作。
项目准备
题目的具体描述
在给定的莎士比亚文集上(多个文件),根据规定的停词表,统计出现频度最高的 100 个单词。
实现后的程序应该满足下列要求:输入指定文件夹下的所有莎翁文集文件,停词表中出现的单词不计算词频,输出结果为出现频次最高的 100 个单词。输出文件中每个单词一行
下面是数据集和那个“停词表”的下载资源
啥是停词表
人类语言包含很多功能词。与其他词相比,功能词没有什么实际含义。最普遍的功能词是限定词(“the”、“a”、“an”、“that”、和“those”),这些词帮助在文本中描述名词和表达概念,如地点或数量。介词如:“over”,“under”,“above” 等表示两个词的相对位置。
这些功能词的两个特征促使在搜索引擎的文本处理过程中对其特殊对待。第一,这些功能词极其普遍。记录这些词在每一个文档中的数量需要很大的磁盘空间。第二,由于它们的普遍性和功能,这些词很少单独表达文档相关程度的信息。如果在检索过程中考虑每一个词而不是短语,这些功能词基本没有什么帮助。
在信息检索中,这些功能词的另一个名称是:停用词(stopword)。称它们为停用词是因为在文本处理过程中如果遇到它们,则立即停止处理,将其扔掉。将这些词扔掉减少了索引量,增加了检索效率,并且通常都会提高检索的效果。停用词主要包括英文字符、数字、数学字符、标点符号及使用频率特高的单汉字等。
也就是说,这是一个为了提高信息检索的效率而产生的概念。通过停用那些出现频率极高但对于信息检索却没有什么用处或者含义的代词介词等,以达到提升信息检索的效率的目的。
资源下载
复制停词表和莎士比亚文集两个链接的链接地址,在Linux直接用wget命令下载,还是蛮方便的。
也有可能是人家实验楼在线环境的服务器网速很快,所以我觉得很方便吧。说不定过两天我在自己电脑上做,速度就会卡成一坨shi
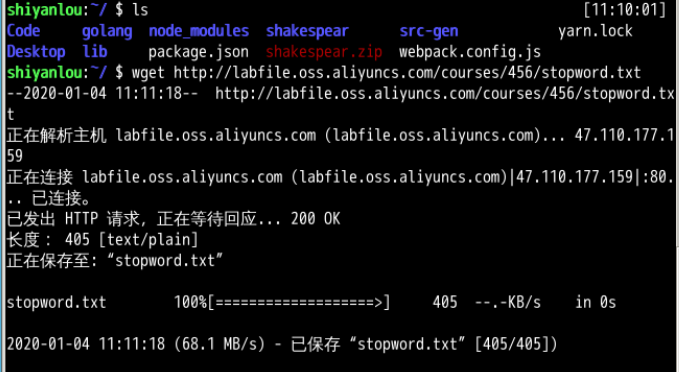
上面这么做,到后面是要把文件移到hadoop用户的文件夹下面的,因为这个环境里面spark是基于hdfs系统的。
最好的办法还是先切换到hadoop用户,然后再wget,但是因为我做的少,这次就忘了。
开搞
初始化_spark启动_创建基本对象_创建RDD
先在hadoop用户下,切到spark的sbin目录里,运行startmaster脚本,然后获得spark主节点的参数,再使用主节点的参数运行脚本启动从节点。
然后运行spark-shell
在 Spark Shell 中引入 SparkContext 和 SparkConf 类:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
Spark 程序中首先需要创建 SparkConf 对象,包含一系列的应用信息,例如 appName(应用程序名),master(主节点的 URL)。
然后使用 SparkConf 对象创建 SparkContext,SparkContext 可以让 Spark 知道如何连接 Spark 集群。
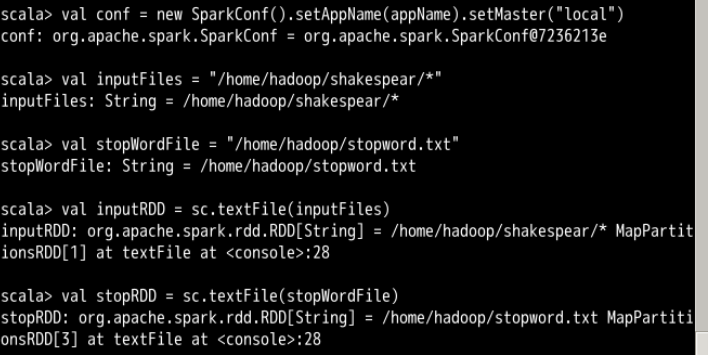
首先,创建conf对象,指定APPname和主节点路径


然后刚才在文件系统里面已经下载好了莎士比亚文集和那个停词表,并且已经解压好了那个莎士比亚文集
sparkshell在启动时就已经创建了一个sc对象,使用这个sc对象调用textFile函数从文件系统分别创建莎士比亚文集的Rdd和停词表的RDD
val inputFiles = "/home/hadoop/shakespear/*"
val stopWordFile = "/home/hadoop/stopword.txt"
val inputRDD = sc.textFile(inputFiles)
val stopRDD = sc.textFile(stopWordFile)
 ## 处理非单词的符号和停词表中的单词
### 非单词
除了题目里面要求的停词表之外,有一些非单词的内容也要排除在词频统计的范围之外,比如说:制表符、反斜线、句号、逗号、竖线 |、中括号、问号、破折号、叹号、分号
这些内容应该被空格替换掉,然后我们才能用空格当分隔符来统计单词。
教程当中给出的解决方案是:在flatMap中传入自定义的方法replaceAndSplit。
在做这里的时候,我搜索了一下map和flatmap的区别,我觉得可以理解成flatmap是在map的基础上进行扁平化操作,就是说按照我们的要求做了map之后,flatmap还要再进行一步操作把map的结果合并到一个数据集合里面也就是“扁平化”。
言归正传,实现replaceAndSplit,然后让flatMap根据replaceAndSplit执行操作的代码是这样的:
```
val targetList: Array[String] = Array[String](""" ().,?[]!;|""")
## 处理非单词的符号和停词表中的单词
### 非单词
除了题目里面要求的停词表之外,有一些非单词的内容也要排除在词频统计的范围之外,比如说:制表符、反斜线、句号、逗号、竖线 |、中括号、问号、破折号、叹号、分号
这些内容应该被空格替换掉,然后我们才能用空格当分隔符来统计单词。
教程当中给出的解决方案是:在flatMap中传入自定义的方法replaceAndSplit。
在做这里的时候,我搜索了一下map和flatmap的区别,我觉得可以理解成flatmap是在map的基础上进行扁平化操作,就是说按照我们的要求做了map之后,flatmap还要再进行一步操作把map的结果合并到一个数据集合里面也就是“扁平化”。
言归正传,实现replaceAndSplit,然后让flatMap根据replaceAndSplit执行操作的代码是这样的:
```
val targetList: Array[String] = Array[String](""" ().,?[]!;|""")
def replaceAndSplit(s: String): Array[String] = {
for(c <- targetList)
s.replace(c, " ")
s.split("s+")
}
val inputRDDv1 = inputRDD.flatMap(replaceAndSplit)
字符串类型的对象targetList里面包含了我们要替换掉的所有字符
然后在实现的函数体里面,s这个字符串代表莎士比亚文集所创建的那个RDD,对s这个字符串进行遍历的时候如果遇到targetList里面对应的字符
则使用replace方法将非单词字符c替换成为空格
最后,用split方法,按照空格对单词进行分割。split方法的参数形式有两种,但是第一参数都是一个正则表达式,这里的话,使用了第一种单参的形式,只传入了一个正则表达式
这个正则表达式“\s+”的含义很明确,就是1到多个空格,所以说最后是按照空格来对单词进行分割。
然后如下图所示,我们获得一个新的RDD对象inputRDDv1,这个RDD里面没有了非单词符号
<img src = "https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104153149984-1600350007.png" width="40%" height="40%">
### 停词表的处理
刚才,其实已经新建了一个停词表的RDD了,并且停词表的数据源是有空行的。教程里用trim方法去掉了空行最后获得了一个紧凑的停词表列表
val stopList = stopRDD.map(x => x.trim()).collect()
<img src = "https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104154359362-1942050493.png" width="40%" height="40%">
再然后,用rdd的filter方法,过滤掉停词表列表里面的单词,然后把结果赋值给一个新的rdd inputRddv2
<img src = "https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104154753272-1396472452.png" width="40%" height="40%">
这样,就可以把这个没有非单词字符和停词表单词的RDDv3变成一个键值对RDD了,键值对的内容是(单词,次数)
<img src = "https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104155222014-14641027.png" width="40%" height="40%">
## 合并键值对rdd
之前生成的键值对rdd里面的键是每个单词,在没有reduce的情况下,每个键的值都是1,把相同的键后面的1加到一起,最后就能够得到每个单词和它对应的个数
val inputRDDv4 = inputRDDv3.reduceByKey(_ + _)
inputRDDv4.saveAsTextFile("/tmp/v4output")
<img src="https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104155832249-695809095.png" width="40%" height="40%">
## 对结果进行排序并存储
教程里面这一部分非常巧妙,rdd自带的方法里面是有一个sortByKey方法的,这个方法顾名思义是按照key进行排序,但是之前的结果里频次是在值的位置不是键的位置,所以中间经过了一次键和值交换位置的操作。
我想到过,上面生成键值对的时候,如果函数参数x=>(x,1)写成x=>(1,x),这里做起来或许就会方便一些。但是,实际上,这样是行不通的,如果要统计频次,必然要通过reduceByKey来做加和,而像我这样写就会让所有键都是“1”,并且“值”位置上面的单词也不能做加和。
所以到这里一定是先交换(x,num)里面键和值的位置,然后使用sortByKey进行排序。
排序完成之后,我们要的只是单词,不需要频次,然后就又做了一次交换,让单词变回了“键”,然后调用keys这个成员就能够得到一个只包含按词频降序排列的单词列表的RDD
val inputRDDv5 = inputRDDv4.map(x => x.swap) //交换
val inputRDDv6 = inputRDDv5.sortByKey(false) //参数false表示降序排序
val inputRDDv7 = inputRDDv6.map(x => x.swap).keys //去除了旧rdd的频次信息生成一个新的rdd
val top100 = inputRDDv7.take(100) //获取最上面的100个单词
<img src="https://img2018.cnblogs.com/blog/1296641/202001/1296641-20200104161745840-2078697180.png" width="40%" height="40%">
最后对上面的结果进行存储
val outputFile = "/tmp/result"
val result = sc.parallelize(top100)
result.saveAsTextFile(outputFile)
# 实验楼教程以外的参考资料
[spark中map与flatMap的区别](https://www.cnblogs.com/wbh1000/p/9846401.html)
[正则表达式手册](https://tool.oschina.net/uploads/apidocs/jquery/regexp.html)
[菜鸟工具 正则表达式在线测试](https://c.runoob.com/front-end/854)
[split函数](https://www.cnblogs.com/davidhaslanda/p/4050471.html)