最近重读《集体智慧编程》,这本当年出版的介绍推荐系统的书,在当时看来很引领潮流,放眼现在已经成了各互联网公司必备的技术。
这次边阅读边尝试将书中的一些Python语言例子用C#来实现,利于自己理解,代码贴在文中方便各位园友学习。由于本文可能涉及到的与原书版权问题,请第三方不要以任何形式转载,谢谢合作。
第三部分 搜索和排名
全文搜索引擎
全文搜索引擎的作用是在大量文档中搜索一系列单词,并根据文档与搜索单词的相关度对结果进行排名。
搜索引擎的组成
-
搜集文档,可能来自互联网,也可能来自固定数量的文档。
-
为搜集文档建立索引。
-
通过查询返回一个经过排序的文档。这个过程最关键的就是文档的排序方法。
构建搜索引擎
首先构造一个爬虫类的“壳子”。后面逐渐完善其中的方法:
public class Crawler : IDisposable
{
private HttpClient _httpClient;
private IDbConnection _connection;
private static readonly HashSet<string> IgnoreWords
= new HashSet<string>(new [] {"the","of","to","and","a","in","is","it"});
//构造函数,接收数据库名作为参数
public Crawler(string dbname)
{
_httpClient = new HttpClient();
_connection = GetConn(dbname);
}
//辅助函数,用于获取条目Id,且如果条目不存在,就将其加入数据库中
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
return 0;
}
//为每个网页建立索引
public async Task AddtoIndex(string url, HtmlDocument soup)
{
Console.WriteLine($"Indexing {url}");
}
//从一个HTML网页提取文字(不带html标签)
public string GetTextOnly(HtmlDocument soup)
{
return null;
}
//分词
public List<string> SeparateWords(string text)
{
return null;
}
//如果Url已经建立索引,则返回true
public bool IsIndexed(string url)
{
return false;
}
//添加一个关联两个网页的链接
public void AddLinkref(string urlFrom, string urlTo, string linkText)
{
}
//从一小组网页开始进行广度优先搜索,直至某一给定深度,期间为网页建立索引
public async Task Crawl(List<string> pages, int depth = 2)
{
throw new NotImplementedException();
}
public async Task<HtmlDocument> GetHtmlDoc(string url)
{
return null;
}
//创建数据库表
public void CreateIndexTables()
{
}
public static string UrlJoin(string urlBase, string urlRel)
{
return null;
}
public IDbConnection GetConn(string dbname)
{
return null;
}
public void Dispose()
{
_connection.Close();
}
}
这其中还包含一些管理数据库连接的代码,以及在建立索引时需要忽略的单词列表。
爬虫程序
对于C#来说,抓取网页HttpClient是绝佳的选择。
HttpClient可以使用nuget来安装,在NuGet管理器中搜索"httpclient",名为Microsoft.Net.Http的项即为HttpClient库。
抓取网页代码很简单:
var url = "http://xxx.com"; var httpClient = new HttpClient(); var content = await httpClient.GetStringAsync(url);
HttpClient在每次释放时都会断开Tcp连接,所以为了节约性能,尽量把HttpClient作成单例。
抓取网页后另一个非常重要的步骤是分析Html的内容,对于C#来说可以采用Html Agility Pack这个库。安装Html Agility Pack也很简单,在Nuget中搜索HtmlAgilityPack,或者直接使用Install-Package HtmlAgilityPack。
我们首先实现其中的爬虫类中的Crawl方法。
public async Task Crawl(List<string> pages, int depth = 2)
{
for (int i = 0; i < depth; i++)
{
var newpages = new List<string>();
foreach (var page in pages.ToList()) //虽然不是在集合内部修改的集合,但是不加ToList()生成新集合,程序依然会报错
{
var doc = await GetHtmlDoc(page);
if (doc == null) continue;
await AddtoIndex(page, doc);
var links = doc.DocumentNode.Descendants("a");
foreach (var link in links)
{
var attr = link.Attributes["href"];
if (attr != null && !attr.Value.StartsWith("#"))
{
var url = UrlJoin(page, attr.Value);
if (url.Contains("'"))
continue;
if (string.IsNullOrEmpty(url))
continue;
url = url.Split('#')[0];
if (url.StartsWith("http") && !IsIndexed(url))
newpages.Add(url);
var linkText = link.InnerText;
AddLinkref(page, url, linkText);
}
}
}
pages.Clear();
pages.AddRange(newpages);
}
}
通过代码可以看出,其提取网页中的所有Url,并将这些Url加入一个集合,并使用这个集合进行下一次迭代。代码中IsIndexd的调用可以避免对Url重复索引。目前可以使用如下的代码对爬取过程进行测试。
var pagelist = new List<string>()
{
"https://en.wikipedia.org/wiki/Computer_programming"
};
var crawler = new Crawler("searchindex.db3");
crawler.Crawl(pagelist,depth:2).Wait();
建立索引
这一步中为全文索引建立数据库。索引包含所有不同的单词、这些单词所在的文档及单词在文档中出现的位置。这一步的关键就是分词函数,这个函数的作用是通过任何非字母的符号将大段文本分隔为单个单词。
建立的索引需要保存在数据库中,在示例中使用SQLite来保存索引。在C#中使用SQLite也非常容易,首先配置下config文件中的system.data一节中的DbProviderFactories节。
<configuration> <system.data> <DbProviderFactories> <remove invariant="System.Data.SQLite"/> <add name="SQLite Data Provider" invariant="System.Data.SQLite" description=".NET Framework Data Provider for SQLite" type="System.Data.SQLite.SQLiteFactory, System.Data.SQLite" /> </DbProviderFactories> </system.data> </configuration>
.NET平台的SQLite库已经支持EntityFramework,但这个示例中还是使用传统的ADO.NET的方式,为了代码写起来更简介,同时使用了Dapper。如果不需要使用Entity Framework,则只需要安装Sqlite Core类库即可:
Install-Package System.Data.SQLite.Core
创建SQLite链接的方法如下:
public IDbConnection GetConn(string dbname)
{
DbProviderFactory fact = DbProviderFactories.GetFactory("System.Data.SQLite");
DbConnection cnn = fact.CreateConnection();
cnn.ConnectionString = $"Data Source={dbname}";
cnn.Open();
return cnn;
}
存储索引的数据库Schema如下:
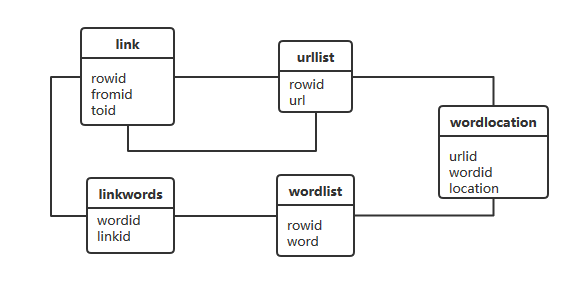
其中:
-
urllist: 保存已经经过索引的URL列表
-
wordlist: 保存单词列表
-
wordlocation: 保存单词在文档中所处位置的列表
-
link: 此表记录了一个URL到另一个URL的关系
-
linkwords: 记录了哪些单词与链接相关
rowid为所有SQLite表都有的字段,所有在创建表时无需再显式指定这个字段
创建SQLite数据库的代码如下:
public void CreateIndexTables()
{
using (var trans = _connection.BeginTransaction())
{
try
{
trans.Connection.Execute("create table urllist(url)");
trans.Connection.Execute("create table wordlist(word)");
trans.Connection.Execute("create table wordlocation(urlid,wordid,location)");
trans.Connection.Execute("create table link(fromid integer,toid integer)");
trans.Connection.Execute("create table linkwords(wordid,linkid)");
trans.Connection.Execute("create index wordidx on wordlist(word)");
trans.Connection.Execute("create index urlidx on urllist(url)");
trans.Connection.Execute("create index wordurlidx on wordlocation(wordid)");
trans.Connection.Execute("create index urltoidx on link(toid)");
trans.Connection.Execute("create index urlfromidx on link(fromid)");
trans.Commit();
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
trans.Rollback();
}
}
}
使用下面的代码可以建立存储索引的数据库:
var crawler = new Crawler("searchindex.db3");
crawler.CreateIndexTables();
在网页查找单词
第一步是把Html中的Tag去除仅保留文本,通过Html Agility Pack可以很容易的完成这个工作。
public string GetTextOnly(HtmlDocument soup)
{
if (soup == null) return string.Empty;
return soup.DocumentNode.InnerText;
}
Html Agility Pack的
DocumentNode.InnerText属性不能完美的处理<script>中的内容,但是对于我们的示例影响不大。
第二步就是进行分词,前文已经提到了分词的作用,下面只是列出这个最基本的分词方法的代码:
//分词
public List<string> SeparateWords(string text)
{
return Regex.Split(text, "\W")
.Where(s => s.Length > 1)
.Select(s => s.ToLower()).ToList();
}
对于英文这样的语言,提取词干也是很重要的一个处理。提取词干是指将单词的复数,时态变化转为原本的形式。而对于像中文这样的语言分词就是一个非常庞大的话题了。
这个简单的分词算法无法很好的处理C#, C++这样的单词。处理这个需要更好的算法。
加入索引
这一步来实现AddtoIndex方法,这个方法获取Html页面中的纯文本,并进行分词。然后建立单词与Url的关系(即向wordlocation写入数据)。
public async Task AddtoIndex(string url, HtmlDocument soup)
{
if (IsIndexed(url)) return;
Console.WriteLine("Indexing " + url);
// 获取每个单词
var text = GetTextOnly(soup);
var words = SeparateWords(text);
// 得到URL的id
var urlid = GetEntryId("urllist", "url", url);
// 将每个单词与该url关联
for (int i = 0; i < words.Count; i++)
{
var word = words[i];
if (IgnoreWords.Contains(word)) continue;
var wordid = GetEntryId("wordlist", "word", word);
_connection.Execute(@"insert into wordlocation(urlid,wordid,location)
values (@urlid, @wordid, @i)", new { urlid, wordid, i });
}
}
下面要实现的就是上面函数中调用的GetEntryId方法:
public int GetEntryId(string table, string field, string value, bool createnew = true)
{
var id = _connection.Query<int>($"select rowid from {table} where {field}='{value}'").FirstOrDefault();
if (id == 0)
{
var lastrowid = _connection
.ExecuteScalar<int>($"insert into {table} ({field}) values ('{value}');SELECT last_insert_rowid();");
return lastrowid;
}
return id;
}
最后再实现IsIndexed函数。该函数判断网页是否已经加入索引数据库(且是否有单词被索引)
public bool IsIndexed(string url)
{
url = url.Replace("'", "\'");
var u = _connection
.QueryFirstOrDefault<int>($"select rowid from urllist where url='{url}'");
if (u > 0)
{
//检查它是否已经被检索过
var v = _connection.Query($"select * from wordlocation where urlid={u}");
if (v.Any())
return true;
}
return false;
}
至此为止,索引数据库就构建完成。可以使用下面代码测试这个数据库是否可用:
var rowids = _connection.Query<int>("select rowid from wordlocation where wordid=1");
Console.WriteLine(string.Join(",",rowids));
查询
完成上面的步骤后,我们已经得到了一个包含一部分网页的索引数据库。下面开始完成搜索部分,我们创建一个名为Searcher的类,这个类的结构如下:
public class Searcher
{
private IDbConnection _connection;
public Searcher(string dbname)
{
_connection = GetConn(dbname);
}
public Tuple<List<List<int>>, List<int>> GetMatchRows(string q){ }
public Dictionary<int, float> GetScoredList(List<List<int>> rows, List<int> wordids){ }
public string GetUrlName(int id){ }
public void Query(string q){ }
public Dictionary<int, float> FrequencyScore(List<List<int>> rows){ }
public Dictionary<int, float> LocationScore(List<List<int>> rows){ }
public Dictionary<int, float> DistanceScore(List<List<int>> rows){ }
public Dictionary<int, float> InboundLinkScore(List<List<int>> rows){ }
public Dictionary<int, float> PageRankscore(List<List<int>> rows){ }
public Dictionary<int, float> NnScore(List<List<int>> rows,List<int> wordids){ }
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids){ }
public Dictionary<int, float> LinkTextScore(List<List<int>> rows, List<int> wordids){ }
public Dictionary<int, float> NormalizeScores(Dictionary<int, float> scores, bool smallIsBetter = false){ }
public IDbConnection GetConn(string dbname)
{
DbProviderFactory fact = DbProviderFactories.GetFactory("System.Data.SQLite");
DbConnection cnn = fact.CreateConnection();
cnn.ConnectionString = $"Data Source={dbname}";
cnn.Open();
return cnn;
}
public void Dispose()
{
_connection.Close();
}
}
我们将逐个完成其中的方法。首先是GetMatchRows方法,这个方法接受一个查询字符串为参数,把查询字符串拆分为多个单词,然后在wordlocation表中查找包含这些单词的URL,然后返回包含所有这些单词的URL。
public Tuple<List<List<int>>,List<int>> GetMatchRows(string q)
{
//构造查询的字符串
var fieldlist = "w0.urlid";
var tablelist = "";
var clauselist = "";
List<int> wordids=new List<int>();
//根据空格拆分单词
var words = q.Split(new[] {' '}, StringSplitOptions.RemoveEmptyEntries);
int tablenumber = 0;
foreach (var word in words)
{
//获取单词的Id
var wordrow = _connection.QueryFirstOrDefault<int>($"select rowid from wordlist where word='{word}'");
if (wordrow != 0)
{
var wordid = wordrow;
wordids.Add(wordid);
if (tablenumber > 0)
{
tablelist += ",";
clauselist += " and ";
clauselist += $"w{tablenumber - 1}.urlid=w{tablenumber}.urlid and ";
}
fieldlist += $",w{tablenumber}.location as loc{ tablenumber}";
tablelist += $"wordlocation w{tablenumber}";
clauselist += $"w{tablenumber}.wordid={wordid}";
++tablenumber;
}
}
//根据各个分组,建立查询
var fullquery = $"select {fieldlist} from {tablelist} where {clauselist}";
var rows = _connection.Query(fullquery).ToList().Select(r =>
{
var rowDic = (IDictionary<string, object>)r;
var intLst = new List<int>();
intLst.Add(Convert.ToInt32(rowDic["urlid"]));
for (int i = 0; i < tablenumber; i++)
{
intLst.Add(Convert.ToInt32(rowDic[$"loc{i}"]));
}
return intLst;
}).ToList();
return Tuple.Create(rows,wordids);
}
这个方法主要的实现是在拼接一个SQL语句。对于两个单词(Id分别为10和17)生成的查询语句为:
select w0.urlid, w0.location as loc1, w1.location as loc2 from wordlocation w0, wordlocation w1 where w0.wordid=10 and w0.urlid=w1.urlid and w1.wordid=17
这个SQL的效果是查找两个单词共同存在的URL,并返回两个单词的位置。
可以用下面的测试代码来测试这个搜索:
var searcher = new Searcher("searchindex.db3");
var result = searcher.GetMatchRows("functional programming");
foreach (var wl in result.Item1)
{
Console.Write($"({wl[0]},{wl[1]},{wl[2]})");
}
上面的查找可能会出现多个结果,我们对结果的排序顺序就是被检索时的顺序。后续我们会介绍不能的方法对搜索结果进行排名。
-
基于内容的排名法(Content-based ranking):根据网页的内容,利用可行的度量方式对查询结果进行判断。
-
外部回指链接排名法(Inbound-link ranking):利用站点的链接结果来决定查询结果中各项内容的重要程度。
-
通过考查人们在搜索时对搜索结果的实际点击情况来逐步改善搜索排名。
基于内容的排名
这一部分我们按单词频度、文档位置和单词距离三个维度来按内容进行排名。
首先我们添加一个方法,这个方法接受查询请求,将获取到的行集置于字典中,并以格式化列表的形式显示输出:
public Dictionary<int,float> GetScoredList(List<List<int>> rows, List<int> wordids)
{
var totalscores = rows.Select(r=>r[0]).Distinct().ToDictionary(r => r, r => 0f);
var weights = GetWeights(rows, wordids);
foreach (var tuple in weights)
{
var weight = tuple.Item1;
var scores = tuple.Item2;
foreach (var tsKey in totalscores.Keys.ToList())
{
totalscores[tsKey] += weight * scores[tsKey];
}
}
return totalscores;
}
其中GetWeights()这个获取排序权重的函数如下:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>();
}
在后面的小节中我们会扩展这个方法中的实现,以添加相关度相关的算法。
接着添加几个辅助方法,主要是最终展示查询结果的Query方法以及其所调用的方法。
public void Query(string q)
{
var matchRows = GetMatchRows(q);
var rows = matchRows.Item1;
var wordids = matchRows.Item2;
var scores = GetScoredList(rows, wordids);
var rankedscores = new SortedList<float, int>(new RankComparer());
foreach (var score in scores)
{
rankedscores.Add(score.Value,score.Key);
}
foreach (var scoreKvp in rankedscores.Take(10))
{
Console.WriteLine($"{scoreKvp.Key} {GetUrlName(scoreKvp.Value)}");
}
}
class RankComparer : IComparer<float>
{
public int Compare(float x, float y)
{
if (x == y)//这样可以让SortedList保存重复的key
return 1;
return y.CompareTo(x);
}
}
public string GetUrlName(int id)
{
return _connection.QueryFirstOrDefault<string>($"select url from urllist where rowid={id}");
}
使用如下测试代码可以第一次完整的测试的查询结果,当然这个结果没有经过任何排名。
var searcher = new Searcher("searchindex.db3");
searcher.Query("functional programming");
下面的几部分我们将实现几种排名方法。
归一化函数
这一部分介绍的所有评价方法返回的都是包含URL Id与评价值的字典。由于有的评价方法分值越大越好,有的方法分值越少越好。所以我们需要一种归一化处理方法使不能评价方法的值域与变化方向相同。
归一化方法接收一个包含Id与评价值的字典,并返回一个带有相同Id,而评价值介于0和1之间的新字典(最佳结果对应值为1)。下面是归一化方法的代码,还是比较好理解的:
public Dictionary<int, float> NormalizeScores(Dictionary<int, float> scores, bool smallIsBetter = false)
{
var vsmall = 0.00001f; //避免被0除
if (smallIsBetter)
{
var minScore = scores.Values.Min();
return scores.ToDictionary(s => s.Key, s => minScore / Math.Max(vsmall, s.Value));
}
else
{
var maxScore = scores.Values.Max();
if (maxScore == 0)
maxScore = vsmall;
return scores.ToDictionary(s => s.Key, s => s.Value / maxScore);
}
}
单词频度
位于查询条件中的单词在文档中出现的次数可以用来判断单词与文档的相关程度。比如要搜索functional,我们更希望得到是内容包含多个functional这个词的网页。实现单词频度的统计函数很简单,就是在我们之前的查询结果的基础上统计下包含该单词的同一个网页的数量并排序即可。代码如下:
public Dictionary<int, float> FrequencyScore(List<List<int>> rows)
{
var counts = new Dictionary<int, float>();
foreach (var row in rows)
{
if (counts.ContainsKey(row[0]))
counts[row[0]] += 1f;
else
counts.Add(row[0],1f);
}
return NormalizeScores(counts);
}
我们将之前GetScoredList方法调用的的GetWeights方法的改为如下实现:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f, FrequencyScore(rows))//1.0f表示FrequencyScore这种方法的相似度权重
};
}
单词在文档位置
靠近文档开始处的单词可能更与文档主题有关。正好我的索引中也保存了单词在文档中的位置,利用这个信息可以按照查询单词在网页中出现的位置对网页进行排序。
public Dictionary<int, float> LocationScore(List<List<int>> rows)
{
var locations = rows.Select(r => r[0]).Distinct().ToDictionary(r => r, r => 1000000f);
foreach (var row in rows)
{
var loc = row.Skip(1).Sum();
if (loc < locations[row[0]])
locations[row[0]] = loc;
}
return NormalizeScores(locations, smallIsBetter: true);
}
方法中对每一条查询记录中所有查询单词的位置进行求和,然后比较位置和的大小。归一化函数的参数smallIsBetter被设为true,表示位置和越小相关度越高。
把GetWeights方法的实现改为可以测试通过单词位置进行优先级排序的算法:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f,LocationScore(rows))
};
}
测试执行的代码不变。
上面介绍的两种方法不能说哪种最优,对于不同的场合可以选择不同的方法,也可以将两种方法结合并通过调整两种方法的权重来获得最佳的结果。结合两种方法只需要把GetWeights方法实现改为如下:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f, FrequencyScore(rows))
Tuple.Create(1.5f,LocationScore(rows)) //这个例子下,我们让位置拥有更高的权重
};
}
单词距离
查询条件中的多个单词如果如果在文档中位置靠的近则说明这些单词与文档的相关度更高。同样我们用索引中保存的单词的位置信息来实现这个算法。
public Dictionary<int, float> DistanceScore(List<List<int>> rows)
{
//如果只有一个单词,则所有网页的得分一样
if(rows[0].Count<=2)
return rows.Select(r => r[0]).Distinct().ToDictionary(r => r, r => 1f);
var mindistance = rows.Select(r => r[0]).Distinct().ToDictionary(r => r, r => 1000000f);
foreach (var row in rows)
{
var dist = row.Skip(2).Select((r,i)=>Math.Abs(r-row[i+1])).Sum();
if (dist < mindistance[row[0]])
mindistance[row[0]] = dist;
}
return NormalizeScores(mindistance, smallIsBetter: true);
}
由于同样是对索引中位置信息进行操作,所以DistanceScore方法和LocationScore方法看起来有些神似。区别在于DistanceScore方法是将每两个单词位置的距离差求和。
可以按前述方法单独测试DistanceScore方法,或着把之前三个方法相结合:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f, FrequencyScore(rows))
Tuple.Create(1.5f,LocationScore(rows))
Tuple.Create(1.8f,DistanceScore(rows))
};
}
利用外部回指链接评价页面优先级
之前介绍的三种方法都是利用页面本身的信息来评估搜索词与网页的关联程度。这一部分我们使用的方法是考察外部哪些网页指向了当前页面,且这些外部网页对当前页面的评价如何,通过这些信息来评价当前网页。这种方法对于过滤存在垃圾内容的网页很有用,因为很少会有第三方的网页指向这些存在垃圾内容的网页。
我们之前在建立索引时,通过AddLinkref方法在link表保存了网页间的指向关系。同时linkwords表还保存了链接文本单词与页面Url间的关系。这部分我们就通过这些关系来实现外部链接辅助评估的几种算法。
简单计数
处理外部链接最为简单的做法就是统计所有链接到当前页面的外部链接的数量,并将这个数量作为针对网页的度量。通过描述可以看出实现这个工作并不复杂:
public Dictionary<int, float> InboundLinkScore(List<List<int>> rows)
{
var uniqueUrls = rows.Select(r => r[0]).Distinct().ToList();
var inboundCount = uniqueUrls.ToDictionary(
u => u,
u => (float)_connection.ExecuteScalar<int>($"select count(*) from link where toid={u}"));
return NormalizeScores(inboundCount);
}
代码和描述的一致,通过link表中记录查找链接到当前页面的外部页面的数量。
PageRank算法
上一节的简单计数方法存在的一个问题就是对于所有外部链接,我们给予其相同的权重的值。这样恶意用户可能建立许多垃圾网页指向当前页面来提高当前页面的排名。而解决这个问题的方法就是给予外部链接不同的权重值,这一节介绍的PageRank就是这样一个算法。
PageRank是以Google创始人Larry Page的名字来命名,该算法为每个网页赋予一个指示网页重要程度的评价值。当今PageRank算法或其变体已被大部分搜索网站采用。
我们通过一个小的例子来描述PageRank算法的过程。通过PageRank算法的名字可以看出,这个算法要求的就是一个Rank,也就是我们给网页的评分。假设有A、B、C和D四个页面,其中B、C和D指向A。B、C和D的PageRank已知(后面会介绍这个初始值如何从无到有出现),求A的PageRank。B和C除了指向A外还分别指向另外三个和四个页面,D只指向A自己。
如果我们用PR(X)表示页面X的PageRank,用LNK(X)表示X页面上所有向外指向的链接的数量,上面的问题可以表示为已知PR(B)=0.5, PR(C)=0.7, PR(D)=0.2, LNK(B)=4, LNK(C)=5, LNK(D)=1,求PR(A)。
在计算过程中还有两个很重要的常数分别为:PR初始最小值和阻尼系数,前者我们取0.15,后者取0.85。至于阻尼系数是怎么来的,见下面的引用栏。
有了上面这些信息我们可以使用如下公式计算PR(A):
PR(A) = 0.15 + 0.85 * ( PR(B)/LNK(B) + PR(C)/LNK(C) +PR(D)/LNK(D) )
计算很简单,最后可以得到PR(A)=054525
通过公式可以看出虽然页面D的本身的PageRank较低,但由于其只指向A这一个页面,所以其对A的PageRank贡献最多。
PageRank是一种模拟用户通过不断点击链接在页面间跳转的算法。而现实中可能用户点击到一定数目的链接后就会离开而不再继续,这个阻尼系数就是模拟这个用户点击一定数量链接后停止的行为。
在上面的例子中页面B、C和D都有一个初始的PageRank,那这个初始值是怎么来的呢?方法就是先将所有页面的都设置为任意一个初始值(例子中都设为1,无论设置什么值对最终的计算结果没有影响),然后使用这些初始值反复计算这些页面的PageRank,经过一定次数的迭代,这些页面的PageRank会趋近其真实值。迭代次数视页面数量来定(一般页面数量越多需要的迭代次数应该越多),对于之前索引文件中那些页面,20次迭代应该足够。
下面就来实现这个计算初始PageRank值的方法(这个算法其实就是用代码实现之前介绍的那个公式),这个方法被写在Crawler中:
public void CalculatePageRank(int iterations = 20)
{
_connection.Execute("drop table if exists pagerank");
_connection.Execute("create table pagerank(urlid primary key, score)");
//初始化所有url,将其PageRank设为1
_connection.Execute("insert into pagerank select rowid, 1.0 from urllist");
for (int i = 0; i < iterations; i++)
{
Console.WriteLine($"Iterations {i+1}");
var urlids = _connection.Query<int>("select rowid from urllist");
foreach (var urlid in urlids)
{
var pr = 0.15f;
//循环遍历指向当前网页的所有其他网页
var fromids = _connection.Query<int>($"select distinct fromid from link where toid={urlid}");
foreach (var linker in fromids)
{
//得到链接对应网页的PageRank值
var linkingpr =
_connection.QueryFirstOrDefault<float>($"select score from pagerank where urlid={linker}");
//查询链接对应网页所有href的数目
var linkingcount =
_connection.ExecuteScalar<int>($"select count(*) from link where fromid={linker}");
pr += 0.85f*(linkingpr/linkingcount);//能进入这个循环,linkingcount就不会为0
}
_connection.Execute($"update pagerank set score={pr} where urlid={urlid}");
}
}
}
执行如下代码可以给所有页面计算初始值:
var crawler = new Crawler("searchindex.db3");
crawler.CalculatePageRank();
这个算法内部的循环次数较多,且有较多的数据库查询,所有执行会较慢,一般在10min以上。还好我们只需要在查询前预先执行一次就好。
下面的方法(Crawler中)可以查询到上面计算结果中PageRank最高的3个页面(Id)及其PageRank。
public void TopPage()
{
var tops = _connection.Query("select * from pagerank order by score desc").Take(3).ToList();
foreach (var cur in tops)
Console.WriteLine($"{cur.urlid} - {cur.score}");
}
通过上面的方法,我们在索引数据库中加入了各页面的PageRank值。下面我们就可以实现方法来通过PageRank对搜索结果进行排序。我们在Searcher中添加如下方法:
public Dictionary<int, float> PageRankScore(List<List<int>> rows)
{
//由于本例中pagerank表与urllist表的urlid相同,构建pagerank dic可以简化为这样
var pageranks = _connection.Query("select urlid, score from pagerank").ToList()
.ToDictionary(r => (int)r.urlid, r => (float)r.score);
var maxrank = pageranks.Values.Max();
var normalizedscores = NormalizeScores(pageranks.ToDictionary(pr => pr.Key, pr => pr.Value / maxrank));
return normalizedscores;
}
我们在查询排名中加入计算PageRank的方法:
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f,LocationScore(rows)),
Tuple.Create(1.0f, FrequencyScore(rows)),
Tuple.Create(1.0f, PageRankScore(rows))
};
}
利用链接文本
除了前面介绍的方法,还可以根据指向某一网页的链接文本来决定网页的相关程度。因为,大多数时候指向该网页的链接文本包含的信息可能比网页本身的内容更有使用价值。主要是链接文本中的内容更简要,更概括。
实现代码如下:
public Dictionary<int, float> LinkTextScore(List<List<int>> rows, List<int> wordids)
{
var linkscores = rows.Select(r => r[0]).Distinct().ToDictionary(r => r, r => 0f);
foreach (var wordid in wordids)
{
var cur = _connection.Query(@"select link.fromid, link.toid from linkwords, link
where wordid=@wordid and linkwords.linkid = link.rowid", new { wordid });
foreach (var c in cur)
{
var fromid = (int) c.fromid;
var toid = (int)c.toid;
if (linkscores.ContainsKey(toid))
{
var pr = _connection.QueryFirstOrDefault<float>(@"select score from pagerank where urlid=@fromid", new {fromid});
linkscores[toid] += pr;
}
}
}
var maxscore = linkscores.Values.Max();
var normalizedscores = NormalizeScores(linkscores.ToDictionary(pr => pr.Key, pr => pr.Value / maxscore));
return normalizedscores;
}
方法参数wordids是搜索字符串包含的所有单词的Id列表,上面的算法会查找链接文本中包含这些搜索单词的链接,如果这些链接指向了搜索结果中的页面,则把这些链接的源页面的PageRank加入到对应的结果页面的评价值中。如果链接到当前页面的外部链接的文本大都包含搜索单词,则页面的评分会很高,否则页面的评分会很低,甚至是0。这种评估方法适合与前文所述其它方法结合使用。
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f,LocationScore(rows)),
Tuple.Create(1.0f, FrequencyScore(rows)),
Tuple.Create(1.0f, PageRankScore(rows)),
Tuple.Create(1.0f, LinkTextScore(rows,wordids))
};
}
如上面这样实现的GetWeights函数。现实场景中,也常是根据不同的需要结合不同的排名方法并调整排名方法的权重,来获得期望的效果。
从点击中学习
这一部分要介绍的内容是通过用户对搜索结果的点击持续性的收集反馈,并根据用户对搜索结果的偏好来改进搜索结果排名。
为了实现这个目标,需要构建一个人工神经网络,向其提供:
-
查询单词
-
搜索结果
-
用户的点击决策
来加以训练。一旦网络经过不同查询项的训练,就可以利用其来改进搜索结果排序(使结果更贴近用户实际点击情况)。
点击跟踪网络设计
神经网络都是由一组节点构成(神经元),且彼此相连。神经网络有多种不同类型。
本节介绍的网络称为多层感知机(Multilayer Perceptron, MLP)网络。这类网络由多层神经元构成,其中第一层(输入层)神经元接受输入,最后一层(输出层)神经元给予输出。在本例中输入和输出分别为用户输入的查询单词和包含权重的Url列表。
神经网络可以有多个中间层,当前例子中只使用一个层。这类中间层无法与外界交互,所以也被称为隐藏层。中间层的第一个工作就是对用户的输入进行组合。
我们将收集到的每一个搜索词作为神经网络查询输入层的一个节点。当新的搜索触发输入层的相应节点后,输入层的节点会根据训练数据激活相应中间层节点,进一步中间层的节点在得到一定量的输入后会触发输出端并激活输出层的节点从而给出最终结果。
随着训练数据逐步加入,上面过程得到结果会更加准确。
训练数据存储
我们在之前的索引数据库基础上进一步完善用于神经网络搜索的存储结构。我们添加如下三张表:
-
存储隐藏层数据的hiddennode表
-
存储输入层到隐藏层节点连接关系的wordhidden表
-
存储隐藏层到输出层节点连接关系的hiddenurl表
所有神经网络相关的代码我们实在在一个名为SearchNet的类中,类中代码的数据访问部分实现和Search类相同。
首先是创建前述三张表的MakeTables()方法:
public void MakeTables()
{
_connection.Execute("create table hiddennode(create_key)");
_connection.Execute("create table wordhidden(fromid, toid,strength)");
_connection.Execute("create table hiddenurl (fromid,toid,strength)");
}
接着需要实现的是GetStrength()方法,这个方法用于返回从输入层到隐藏层以及从隐藏层到输出层的联系的强度。由于这个层之前的联系只有在使用数据训练之后才会产生,如果遇到查询不存在的联系则返回一个默认值。对于输入层到隐藏层的联系,如果不存在返回-0.2,也就是说如果查询的词没有经过训练,会对最终结果有负面影响。而对于从隐藏层到输出层的联系默认值为0。
public float GetStrength(int fromid, int toid, int layer)
{
string table;
if (layer == 0) table = "wordhidden";
else table = "hiddenurl";
var res = _connection.QueryFirstOrDefault<float?>
($"select strength from {table} where fromid={fromid} and toid={toid}");
if (!res.HasValue)
{
if (layer == 0) return -0.2f;
if (layer == 1) return 0f;
}
return res.Value;
}
另一个名为SetStrength的方法用于查询联系是否存在,并创建联系或更新联系强度。这个方法将用于训练神经网络的代码。
public void SetStrength(int fromid, int toid, int layer, float strength)
{
string table;
if (layer == 0) table = "wordhidden";
else table = "hiddenurl";
var res = _connection.QueryFirstOrDefault<int?>
($"select rowid from {table} where fromid={fromid} and toid={toid}");
if (!res.HasValue)
{
_connection.Execute($@"insert into {table} (fromid,toid,strength)
values ({fromid},{toid},{strength})");
}
else
{
var rowid = res.Value;
_connection.Execute($@"update {table} set strength={strength}
where rowid={rowid}");
}
}
大部分神经网络再使用前都会初始化好各个层的节点以及联系并给予适度的训练。
而在我们的例子中,我们把这个过程放在每次查询过程中。如果传入的查询是一组从未出现的单词组合,下面展示的GenerateHiddenNode方法就会在隐藏层中创建节点,并创建输入层到隐藏节点以及隐藏节点到输出层的联系,并给予联系以默认值。
public void GenerateHiddenNode(List<int> wordids, List<int> urls)
{
if (wordids.Count > 3) return;
//检查是否已经为这组单词建好了一个节点
var createkey = string.Join("_", wordids.OrderBy(w => w));
var res = _connection.QueryFirstOrDefault<int?>(
$"select rowid from hiddennode where create_key = '{createkey}'");
//如果不存在则建立
if (!res.HasValue)
{
var hiddenid = _connection.ExecuteScalar<int>(
$@"insert into hiddennode (create_key) values ('{createkey}');
SELECT last_insert_rowid();");
//设置默认权重
foreach (var wordid in wordids)
SetStrength(wordid, hiddenid, 0,1.0f/wordids.Count);
foreach (var urlid in urls)
SetStrength(hiddenid,urlid,1,0.1f);
}
}
完成这一小步后,下面先来进行测试以保证后面可以顺利进行。
var myNet = new SearchNet("searchindex.db3");
myNet.MakeTables();
int wWorld = 101, wRiver=102,wBank=103;
int uWorldBank=201, uRiver=202, uEarth = 203;
var wordids = new List<int> {wWorld, wBank};
var urlids = new List<int> {uWorldBank, uRiver, uEarth};
myNet.GenerateHiddenNode(wordids, urlids);
myNet.ShowHiddens();
public void ShowHiddens()
{
var wordHiddens = _connection.Query("select * from wordhidden");
foreach (var wh in wordHiddens)
Console.WriteLine($"({wh.fromid}, {wh.toid}, {wh.strength})");
var hiddenUrls = _connection.Query("select * from hiddenurl");
foreach (var hu in hiddenUrls)
Console.WriteLine($"({hu.fromid}, {hu.toid}, {hu.strength})");
}
我们新建了数据表,使用一些数据初始化了一些隐藏层节点及层之间的联系,并使用测试代码展示了数据库中创建的联系。
下面我们将编写用于查询的代码,查询代码会接收一组单词作为输入并根据神经网络中联系的强度计算输入的Url的分值。
查询前的准备工作
在执行查询前,我们先要在对象中构造出用于查询的一些数据。这些数据就是一次查询的输入单词对应的输入节点、查询结果对应的输出节点以及其中涉及的隐藏节点和联系。
首先是获取所有隐藏节点的方法:
public List<int> GetAllHiddenIds(List<int> wordids, List<int> urlids)
{
var l1 = new HashSet<int>();
foreach (var wordid in wordids)
{
var cur = _connection.Query<int>($"select toid from wordhidden where fromid = {wordid}");
l1.UnionWith(cur);
}
foreach (var urlid in urlids)
{
var cur = _connection.Query<int>($"select fromid from hiddenurl where toid={urlid}");
l1.UnionWith(cur);
}
return l1.ToList();
}
接着在SearchNet中添加一些字段,用于存储我们上文提到的用于训练的数据。
private List<int> _wordids; private List<int> _hiddenids; private List<int> _urlids; private List<float> _ai; private List<float> _ah; private List<float> _ao; private List<List<float>> _wi; private List<List<float>> _wo;
下面方法的注释中,会看到这些字段表示什么意思。这个方法也正式用于初始化这些字段的值。
public void SetupNetwork(List<int> wordids, List<int> urlids)
{
//值列表
_wordids = wordids;
_hiddenids = GetAllHiddenIds(wordids, urlids);
_urlids = urlids;
//节点输出
_ai = ArrayList.Repeat(1.0f, _wordids.Count).Cast<float>().ToList();
_ah = ArrayList.Repeat(1.0f, _hiddenids.Count).Cast<float>().ToList();
_ao = ArrayList.Repeat(1.0f, _urlids.Count).Cast<float>().ToList();
//建立权重矩阵
_wi = _wordids
.Select(w=>_hiddenids.Select(h=>GetStrength(w,h,0)).ToList())
.ToList();
_wo = _hiddenids
.Select(h => _urlids.Select(u => GetStrength(h, u, 1)).ToList())
.ToList();
}
反双曲正切变换函数 - Tanh()
我们选择使用反双曲正切变换函数来计算输入对于一个节点的影响程度。这个函数的图像如下所示:

这是一类S型函数,这一类型的函数的特征就是函数图象呈现S形状。神经网络几乎都是使用S型函数计算神经元的输出。从图像中可以看出在X值(节点的输入值)到达2之前,Y轴数值(节点输出)会迅速增长,而当X值到达2以后,Y轴值趋于1,并几乎不再发生变化。
下面实现FeedForward方法使用上面介绍的函数计算隐藏层和输出层节点的输出,最终给出结果。
public List<float> FeedForward()
{
//查询单词是仅有的输入(这一步好像有点多余)
for (int i = 0; i < _wordids.Count; i++)
_ai[i] = 1.0f;
//隐藏层节点的活跃程度
for (int j = 0; j < _hiddenids.Count; j++)
{
var sum = 0f;
for (int i = 0; i < _wordids.Count; i++)
sum = sum + _ai[i]*_wi[i][j];
_ah[j] = (float)Math.Tanh(sum);
}
//输出层节点活跃程度
for (int k = 0; k < _urlids.Count; k++)
{
var sum = 0f;
for (int j = 0; j < _hiddenids.Count; j++)
sum = sum + _ah[j] * _wo[j][k];
_ao[k] = (float)Math.Tanh(sum);
}
return _ao.ToList();
}
方法中节点的输入来自上一层所有有关联的节点的输出乘以联系的强度的和,这个和经过Tanh()计算便得到了节点的输出。我们的例子中只有一个隐藏层,但上述方法可以扩展到多个隐藏层。
到此,我们再实现一个简短的方法,构造神经网络并针对一组输入给出查询结果:
public List<float> GetResult(List<int> wordids, List<int> urlids)
{
SetupNetwork(wordids,urlids);
return FeedForward();
}
测试代码也很简单:
var myNet = new SearchNet("searchindex.db3");
int wWorld = 101, wRiver=102,wBank=103;
int uWorldBank=201, uRiver=202, uEarth = 203;
var wordids = new List<int> {wWorld, wBank};
var urlids = new List<int> {uWorldBank, uRiver, uEarth};
var result = myNet.GetResult(wordids, urlids);
Console.WriteLine(string.Join(",",result));
结果中,对于每个Url网络给出的输出结果都是相同的值,这是因为我们还未对网络进行任何训练。
下面就来对网络进行训练
反向传播法训练网络
之所以称为反向传播法,是因为对神经网络的训练是通过给神经网络提供一些实际生活中真实的结果,由结果反向对网络中的联系的权重进行修改。
在训练过程中我们传入了输出层的输出,而要使一个节点得到期望的输出,唯一的方法就是修改该节点的的输入和。
为了确定如何改变总的输入,需要知道Tanh方法在当前输出级别上的斜率。当输出接近0时,斜率会非常大,而当输出结果接近-1或1时,改变输入对输出的影响就越来越小。可以用下面的方法来计算针对任何输出值的斜率。
public float Dtanh(float y)
{
return 1.0f - y*y;
}
具体计算步骤如下:
对于输出层每个节点:
-
计算节点当前输出结果与期望结果之间的差距
-
利用
Dtanh()方法确定节点的总输入需要的改变量。 -
改变外部联系的强度值,其值与当前强度和学习速率(没理解书上这个指啥)成一定比例。
对于隐藏层中的节点:
-
将每个输出链接的强度值乘以其目标节点所需的改变量,再累加求和,从而改变节点的输出结果。
-
使用
Dtanh函数确定节点的总输入所需的改变量。 -
改变每个输入链接的强度值,其值与链接的当前强度及学习速率成一定比例。
算法具体实现如下:
public void BackPropagate(List<float> targes, float N = 0.5f)
{
//计算输出层的误差
var out_deltas = ArrayList.Repeat(0.0f, _urlids.Count).Cast<float>().ToList();
for (int k = 0; k < _urlids.Count; k++)
{
var error = targes[k] - _ao[k];
out_deltas[k] = Dtanh(_ao[k])*error;
}
//计算隐藏层的误差
var hidden_deltas = ArrayList.Repeat(0.0f, _wordids.Count).Cast<float>().ToList();
for (int j = 0; j < _hiddenids.Count; j++)
{
var error = 0f;
for (int k = 0; k < _urlids.Count; k++)
error += out_deltas[k]*_wo[j][k];
hidden_deltas[j] = Dtanh(_ah[j]) * error;
}
//更新输出权重
for (int j = 0; j < _hiddenids.Count; j++)
{
for (int k = 0; k < _urlids.Count; k++)
{
var change = out_deltas[k]*_ah[j];
_wo[j][k] += N*change;
}
}
//更新输入权重
for (int i = 0; i < _wordids.Count; i++)
{
for (int j = 0; j < _hiddenids.Count; j++)
{
var change = hidden_deltas[j] * _ai[i];
_wi[i][j] += N * change;
}
}
}
本质上来说,算法就是设置一个有误差的结果,然后用真实的结果去逐渐消除这些误差。
有了上面的方法,剩余的方法就是建立神经网络并使用反向传播算法进行训练。
public void TrainQuery(List<int> wordids, List<int> urlids, int selectedUrl)
{
//如有必要,生成一个隐藏节点
//GenerateHiddenNode(wordids, urlids);
SetupNetwork(wordids,urlids);
FeedForward(); //在训练前执行下此方法,使节点当前的输出结果存入字段中
var targets = ArrayList.Repeat(0.0f, _urlids.Count).Cast<float>().ToList();
targets[urlids.IndexOf(selectedUrl)] = 1.0f;
BackPropagate(targets);
UpdateDatabase();
}
下面的测试代码中,我们进行一次训练,并再次尝试查询。
var myNet = new SearchNet("searchindex.db3");
int wWorld = 101, wRiver=102,wBank=103;
int uWorldBank=201, uRiver=202, uEarth = 203;
var wordids = new List<int> {wWorld, wBank};
var urlids = new List<int> {uWorldBank, uRiver, uEarth};
myNet.TrainQuery(wordids,urlids,uWorldBank);
var result = myNet.GetResult(wordids, urlids);
Console.WriteLine(string.Join(",", result));
可以看到,由于经过训练,这次得到的评分不再是相同的。由于我们的训练数据指定uWorldBank为期望的结果,所以在最终的查询结果中uWorldBank对应的分值会高很多。
训练
前面的测试代码中,我们只进行了简单的训练。现在我们看看经过详细的训练后神经网络可以展线的能力。
var myNet = new SearchNet("searchindex.db3");
int wWorld = 101, wRiver=102,wBank=103;
int uWorldBank=201, uRiver=202, uEarth = 203;
var urlids = new List<int> {uWorldBank, uRiver, uEarth};
for (int i = 0; i < 30; i++)
{
myNet.TrainQuery(new List<int> { wWorld, wBank }, urlids, uWorldBank);
myNet.TrainQuery(new List<int> { wRiver, wBank }, urlids, uRiver);
myNet.TrainQuery(new List<int> { wWorld }, urlids, uEarth);
}
var result = myNet.GetResult(new List<int> { wWorld, wBank }, urlids);
Console.WriteLine(string.Join(",", result));
result = myNet.GetResult(new List<int> { wRiver, wBank }, urlids);
Console.WriteLine(string.Join(",", result));
result = myNet.GetResult(new List<int> { wBank }, urlids);
Console.WriteLine(string.Join(",", result));
代码中我们进行多次训练,并使用不同的查询来测试神经网络的结果。
与搜索引擎结合
上面的示例中,我们提供的训练数据都是手工编写的,对于大规模的训练这肯定是不现实的。
我们可以使用前文搜索引擎中反馈的数据来进行训练,可以将Searcher类中的Query方法改成如下样子来返回训练数据需要的wordids和urlids。
public Tuple<List<int>, List<int>> Query(string q)
{
var matchRows = GetMatchRows(q);
var rows = matchRows.Item1;
var wordids = matchRows.Item2;
var scores = GetScoredList(rows, wordids);
var rankedscores = new SortedList<float, int>(new RankComparer());
foreach (var score in scores)
{
rankedscores.Add(score.Value, score.Key);
}
foreach (var scoreKvp in rankedscores.Take(10))
{
Console.WriteLine($"{scoreKvp.Key} {GetUrlName(scoreKvp.Value)}");
}
return Tuple.Create(wordids,
rankedscores.Take(10).Select(r => r.Value).ToList());
}
另外训练数据需要的用户实际点击链接的数据(TrainQuery方法需要的第三个参数)则需要通过其他方式来获取,这个不是本文的重点,略去不提。
有了这三样数据就可以调用TrainQuery方法进行训练。
经过一段时间的运行,我们就会得到一个拥有足够可靠数据的神经网络用于对搜索引擎的查询结果进行评价。
我们在Searcher类中添加一个基于神经网络对查询结果进行评分的方法:
public Dictionary<int, float> NnScore(List<List<int>> rows, List<int> wordids)
{
var myNet = new SearchNet("searchindex.db3");
//获得要给由唯一Url Id构成的有序列表
var urlids = rows.Select(r => r[0]).Distinct().ToList();
var nnres = myNet.GetResult(wordids, urlids);
var scores = nnres.Select((n, i) => Tuple.Create(urlids[i], n)).ToDictionary(t => t.Item1, t => t.Item2);
return NormalizeScores(scores);
}
这个方法可以被加入GetWeights()方法,独立或与其他方法结合来对查找结果进行评分。
public List<Tuple<float, Dictionary<int, float>>> GetWeights(List<List<int>> rows, List<int> wordids)
{
return new List<Tuple<float, Dictionary<int, float>>>()
{
Tuple.Create(1.0f,LocationScore(rows)),
Tuple.Create(1.0f, PageRankscore(rows)),
Tuple.Create(1.0f, NnScore(rows,wordids))
};
}
到此这一部分就算结束了。本文主要介绍了索引数据库,搜索引擎,神经网络三大构件的设计与实现方法。