最近读了读图灵的《.NET2.0模式开发实战》,里面介绍了一种不常见的设计模式Pipes-and-Filters模式,整体讲解还是很不错,但是配书的代码你的程序组织很乱,无法正常调试。到网上寻找,在CodeProject上发现一篇介绍此模式的文章,看了后感觉不错,而且代码可以正常运行。空闲时间将其翻译了一下,E文不好朋友可以参考一下,E文好的朋友移步原文。同时文中也提到了《Foundations of Object-Oriented Programming Using .NET 2.0 Patterns》有此书的朋友看书即可,两者大致相同。本文还介绍了Decorator模式及这两种模式之间的关系,李大哥的文章已经把Decorator模式讲的很明白了,这部分的翻译省略,只翻译两种模式关系部分!
搜索关键字 – 管道与过滤器模式(Pipes-and-Filters)与装饰模式(Decorator)之间的关系
Bashiiui著
本文介绍Pipes and Filters与Decorator两种设计模式的实现。
介绍
本文介绍了使用Pipes-and-Filters模式与Decorator模式来实现一个简单问题的方法,并探索他们可能存在的联系。
Pipes-and-Filters模式的意图
Pipes-and-Filters模式给系统现有组件提供了一种处理数据流(过滤)及将传送数据的相邻组件(管道)连接起来的结构。这种架构提供了可重用性,可维护性,并将系统进程中拥有不同的,易识别的,独立但有些复杂的任务分离。
Pipes-and-Filters模式的使用被限制在过滤器的处理顺序是以自然顺序强制定义的系统中。该模式应用到的问题应该可以自然的分解为一系列一定程度上独立的任务。在管道模式中,这些一定程度上独立的任务正代表了管道的处理阶段。管道的结构是静态的,且连续的阶段之间的迭代是有规律的且有松散的同步性。管道是完成一个业务功能的步骤/任务的定义。每一步可能包括读写确认"管道状态"的数据,也有可能要访问一个外部服务。每一个步骤中需要异步调用一个服务,管道可以等待直到响应数据返回(如果响应数据是被期待的),如果响应数据对继续下面的处理不是必需的,则会继续处理管道中下一个任务。
在以下场合会使用管道模式:
-
你可以指定一系列已知的/确定的步骤的顺序
-
你不需要等待每一步中的异步响应
-
你需要所有的下游组件可以检验并操作来自上游组件的数据(反之不成立)
管道模式的优势在于:
-
它强化了顺序处理过程。
-
可以很容易的将其包装成一个原子事务。
管道模式存在以下缺点:
-
管道模式对于覆盖业务逻辑中的所有问题这样的情况还过于简单,尤其是对于需要以一种复杂的方式扩展的业务逻辑执行的服务集合。
-
由于其顺序处理的特性,它不能处理有附加条件的构造,循环,及其它流控制逻辑。
背景
过滤器
过滤器是管道的处理单元。一个过滤器可能会丰富,改进,处理或改变输入数据的格式。
-
它会以由输入数据流中集中或提取信息并将其特定的信息传输给输出流的方式来优化数据。
-
在将输入数据传给输出流之前,它将其转化到一个新的格式。
-
当然它可以处理将丰富,优化,转化格式合起来的操作。过滤器可以是主动的(这种情况更常见)或被动的。
-
一个主动式过滤器运行在一个单独的进程或线程上。它动态的由数据输入流提取数据并将转换完成的数据送到输出流中。
-
一个被动的过滤器被以下列方式调用而激活:
-
作为一个函数,一个由过滤器输出流获取数据的操作。
-
作为一个过程,一个将输出数据送入过滤器的操作。
-
管
管是数据源到第一个过滤器,过滤器之间及最后一个过滤器和数据接收器这些链接之间的连接器。作为必须的,一个管同步这些动态的元素从而它们连接在一起。
数据
数据源是一个给系统提供输入数据的实体(如文件或输入设备)它即可以主动的将数据送入管道中,也可以当收到请求时被动的提供数据。
数据接收器
数据接收器是一个在管道末端收集数据的实体,它可以动态地由最后一个过滤器获取数据,也可以被动的相应最后一个过滤器的请求。
具体实现
我们可以考虑实现泛型过滤器作为一个处理数据的组件。IComponent基础接口定义如下:
1 public interface IComponent<T> 2 { 3 bool Process(T t); 4 }
整个例子中,我使用'T'作为泛型类型的参数。输入输出流所使用的接口为InputStream和OutputStream。
1 public interface InputStream<T> : IEnumerable<T> 2 { 3 bool Available(); 4 T Read(); 5 ulong Read(out T[] Data, ulong offset, ulong length); 6 void Reset(); 7 void Skip(ulong offset); 8 } 9 10 public interface OutputStream<T> 11 { 12 void Flush(); 13 void Write(T data); 14 void Write(T[] Data); 15 void Write(T[] Data, ulong offset, ulong length); 16 } 17 18 public interface IStreamingControl<T> 19 { 20 InputStream<T> Input 21 { 22 get; 23 set; 24 } 25 OutputStream<T> Output 26 { 27 get; 28 set; 29 } 30 31 InputStream<T> FactoryInputStream(); 32 OutputStream<T> FactoryOutputStream(); 33 }
现在,定义具体实现类StreamingControlImpl来实现IstreamingControl如下:
1 public class StreamingControlImpl<T> : MarshalByRefObject, IStreamingControl<T> where T : new() 2 { 3 #region BridgedStreams implementation of InputStream, and OutputStream 4 [Serializable] 5 public class BridgedStreams : InputStream<T>, OutputStream<T> 6 { 7 T[] _buffer = new T[0]; 8 ulong _currIndex; 9 ulong _afterLastWrittenIndex; 10 11 public BridgedStreams() 12 { 13 _currIndex = 0; 14 _afterLastWrittenIndex = 0; 15 } 16 17 public bool Available() 18 { 19 if (_currIndex < _afterLastWrittenIndex) 20 { 21 return true; 22 } 23 else 24 { 25 return false; 26 } 27 } 28 public T Read() 29 { 30 if (_currIndex < _afterLastWrittenIndex) 31 { 32 _currIndex++; 33 return _buffer[_currIndex - 1]; 34 } 35 else 36 { 37 throw new System.IO.EndOfStreamException(); 38 } 39 } 40 public ulong Read(out T[] data) 41 { 42 ulong size = _afterLastWrittenIndex - _currIndex; 43 data = new T[size]; 44 for (ulong c1 = _currIndex; c1 < _afterLastWrittenIndex; c1++) 45 { 46 data[c1 - _currIndex] = _buffer[c1]; 47 } 48 return size; 49 } 50 public ulong Read(out T[] data, ulong offset, ulong length) 51 { 52 if (_afterLastWrittenIndex - offset > length) 53 { 54 length = _afterLastWrittenIndex - offset; 55 } 56 data = new T[length]; 57 for (ulong c1 = offset; c1 < offset + length; c1++) 58 { 59 data[c1 - offset] = _buffer[c1]; 60 } 61 return length; 62 } 63 public void Reset() 64 { 65 _currIndex = 0; 66 } 67 public void Skip(ulong offset) 68 { 69 if (offset > _afterLastWrittenIndex) 70 { 71 _currIndex = _afterLastWrittenIndex; 72 } 73 else 74 { 75 _currIndex = offset; 76 } 77 } 78 79 public void Flush() 80 { 81 _currIndex = 0; 82 _afterLastWrittenIndex = 0; 83 return; 84 } 85 private void Resize(ulong length) 86 { 87 if (length >= (ulong)_buffer.Length) 88 { 89 T[] temp; 90 91 if (_buffer.Length == 0) 92 { 93 temp = new T[length * 2]; 94 } 95 else 96 { 97 temp = new T[_buffer.Length * 2]; 98 } 99 for (int c1 = 0; c1 < _buffer.Length; c1++) 100 { 101 temp[c1] = _buffer[c1]; 102 } 103 _buffer = temp; 104 } 105 } 106 public void Write(T data) 107 { 108 Resize(_currIndex + 1); 109 _buffer[_currIndex] = data; 110 _currIndex++; 111 if (_currIndex > _afterLastWrittenIndex) 112 { 113 _afterLastWrittenIndex = _currIndex; 114 } 115 return; 116 } 117 public void Write(T[] data) 118 { 119 foreach (T item in data) 120 { 121 Write(item); 122 } 123 return; 124 } 125 public void Write(T[] data, ulong offset, ulong length) 126 { 127 Skip(offset); 128 for (ulong c1 = 0; c1 < length; c1++) 129 { 130 Write(data[c1]); 131 } 132 return; 133 } 134 public System.Collections.IEnumerator GetEnumerator() 135 { 136 for (ulong c1 = 0; c1 < _afterLastWrittenIndex; c1++) 137 { 138 yield return _buffer[c1]; 139 } 140 } 141 public override string ToString() 142 {/* 143 MemoryTracer.Start(this); 144 MemoryTracer.Variable("CurrIndex", _currIndex); 145 MemoryTracer.Variable("LastWrittenIndex", _afterLastWrittenIndex); 146 MemoryTracer.Variable("Buffer size", _buffer.Length); 147 MemoryTracer.StartArray("Buffer content"); 148 for (ulong c1 = 0; c1 < _afterLastWrittenIndex; c1++) 149 { 150 MemoryTracer.Variable("item", _buffer[c1].ToString()); 151 } 152 MemoryTracer.EndArray(); 153 return MemoryTracer.End();*/ 154 return "Bash"; 155 } 156 157 158 #region IEnumerable<T> Members 159 160 IEnumerator<T> IEnumerable<T>.GetEnumerator() 161 { 162 for (ulong c1 = 0; c1 < _afterLastWrittenIndex; c1++) 163 { 164 yield return _buffer[c1]; 165 } 166 } 167 168 #endregion 169 } 170 #endregion 171 172 private InputStream<T> _inputStream; 173 private OutputStream<T> _outputStream; 174 public virtual InputStream<T> Input 175 { 176 get 177 { 178 return _inputStream; 179 } 180 set 181 { 182 _inputStream = value; 183 } 184 } 185 public virtual OutputStream<T> Output 186 { 187 get 188 { 189 return _outputStream; 190 } 191 set 192 { 193 _outputStream = value; 194 } 195 } 196 public virtual InputStream<T> FactoryInputStream() 197 { 198 return new BridgedStreams(); 199 } 200 public virtual OutputStream<T> FactoryOutputStream() 201 { 202 return new BridgedStreams(); 203 } 204 } 205 206 public interface IComponentStreaming<T> : IComponent<StreamingControlImpl<T>> where T : new() 207 { 208 bool Process(InputStream<T> input, OutputStream<T> output); 209 } 210 211 public abstract class InputSource<T> : StreamingComponentBase<T> where T : new() 212 { 213 public const bool isOutputSink = false; 214 215 public abstract bool Process(OutputStream<T> output); 216 217 public override bool Process(InputStream<T> input, OutputStream<T> output) 218 { 219 foreach (T t in input) 220 output.Write(t); 221 222 return Process(output); 223 } 224 } 225 226 public abstract class OutputSink<T> : StreamingComponentBase<T> where T : new() 227 { 228 public const bool isOutputSink = true; 229 public abstract bool Process(InputStream<T> input); 230 231 public override bool Process(InputStream<T> input, OutputStream<T> output) 232 { 233 return Process(input); 234 } 235 }
我们有两种处理类型可选择:顺序处理和管道处理。用异步方式将组件连接在一起允许此链条中每一个单元在自己的线程或进程中来执行。当一个单元完成一个过滤器的处理,它可以将数据送到输出流并直接开始处理另一个数据,它不需要等待随后的组件读取并处理数据。这允许多种的数据消息在进入它们各自独立的阶段时被同时处理。例如,下一个消息可以被加密。我们称这种配置为处理管道,因为消息经过过滤器正如液体流过一个管道。与严格的顺序处理过程相比较,管道处理模型可以极大的提升系统的吞吐量。这里我们仅讨论顺序处理模型。
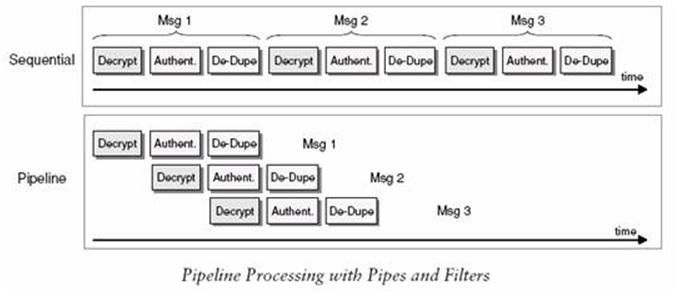
管道接口定义如下:
1 public interface IPipeline<T> 2 { 3 void AddLink(IComponent<T> link); 4 bool Process(T t); 5 }
LinearPipeline实现了IPipeline接口,以顺序方式处理过滤器。在处理过滤器的规则上有两种方式,通过以下枚举定义:
1 public enum OPTYPE { AND, OR };
如果管道中任一个过滤器的处理发生错误并且/或者返回false,处理会停止而不再执行上述的过滤器,并且管道会返回false到调用程序,在AND操作符方式下进行的管道处理如下:
1 if (_optype == OPTYPE.AND) 2 { 3 result = true; 4 foreach (IComponent<T> link in _links) 5 { 6 if (!link.Process(t)) 7 { 8 result = false; 9 break; 10 } 11 } 12 }
如果管道中任何过滤器的处理都返回true,则管道返回true给调用程序。管道继续处理每一个过滤器而不管当前处理的过滤器返回的结果,在OR操作符方式下进行的管道处理如下:
1 if (_optype == OPTYPE.OR) 2 { 3 result = false; 4 foreach (IComponent<T> link in _links) 5 { 6 if (link.Process(t)) 7 { 8 result = true; 9 //break; 10 } 11 } 12 }
不同的过滤器完成不同的工作,因此被实现为不同的类。下面是管道中5个过滤器的列表:
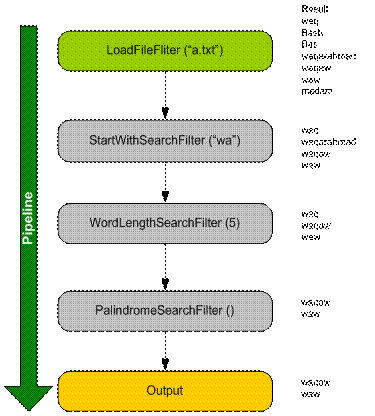
-
LoadFileFilter由一个文件(或者可能是一个文件序列)中以字符串的形式读入程序文本(如,源代码)并识别出一连串的记号。由于IO操作较慢,一次读入一个字符不是很高效的,因此,我们可以使用StreamReader来一次读取整个文件。Tokens类是一个迭代的符号化器,其使用逗号或分号和空格来将输入划分为符号。
-
StartWithSearchFilter从LoadFileFilter获取数据流,过滤出并接收以作为参数传入的关键字打头的单词。
-
WordLengthSearchFilter接收StartWithSearchFilter的数据流,过滤并接收长度小于或等于作为参数传入的最大允许值的单词。
-
PlaindromeSearchFilter接收WordLengthSearchFilter的数据流并过滤出自然形成回文的单词。
-
Output用来将结果显示给用户。
下面的类描述了LoadFileFilter任务的实现:
1 internal class LoadFileFliter : InputSource<Item> 2 { 3 private string _path; 4 5 public LoadFileFliter(string path) 6 { 7 _path = path; 8 } 9 public override bool Process(OutputStream<Item> output) 10 { 11 try 12 { 13 if (File.Exists(_path)) 14 { 15 string buffer; 16 // Create an instance of StreamReader to read from a file. 17 // The using statement also closes the StreamReader. 18 using (StreamReader sr = new StreamReader(_path)) 19 { 20 buffer = sr.ReadToEnd(); 21 } 22 23 buffer = buffer.Replace("\r\n", " "); 24 Tokens Tokenizer = new Tokens(buffer, new char[] { ' ', ';', ',' }); 25 foreach (string Token in Tokenizer) 26 { 27 if (Token == string.Empty) continue; 28 29 System.Diagnostics.Debug.Write(Token); 30 output.Write(new Item(Token)); 31 } 32 return true; 33 } 34 else 35 throw new Exception("File could not be read"); 36 } 37 catch (Exception ex) 38 { 39 System.Diagnostics.Debug.Write(ex.Message); 40 } 41 42 return false; 43 } 44 }
由于每一个过滤器都暴露了一个非常简单的接口,它由进入其的管道获取消息,处理消息,并将结果发布到输出管道。管道将一个过滤器连接到下一个,由一个过滤器向下一个发送输出消息。因为,所有的组件使用相同的外部接口。
通过将组件连接到不同的管道,它们可以构成不同的解决方案,我们可以添加新的过滤器,移除现有的,或者以一个新的顺序重新安排它们 – 这些都不需要改变过滤器本身。下面是一个主要的Invoke类,它定义了过滤器的执行顺序并将其放入管道中处理。
1 public static void Invoke() 2 { 3 LinearPipeline<StreamingControlImpl<Item>> pipeline = new LinearPipeline<StreamingControlImpl<Item>>(OPTYPE.OR); 4 5 pipeline.AddLink(Factory<Item>.CreateLoadFile(@"a.log")); 6 pipeline.AddLink(Factory<Item>.CreateStartWithSearch("wa")); 7 pipeline.AddLink(Factory<Item>.CreateWordLengthSearch(8)); 8 pipeline.AddLink(Factory<Item>.CreatePalindromeSearch()); 9 pipeline.AddLink(Factory<Item>.CreateOutput()); 10 11 StreamingControlImpl<Item> controldata = new StreamingControlImpl<Item>(); 12 bool done = pipeline.Process(controldata); 13 if (done) 14 System.Diagnostics.Debug.Write("All filters processed successfully"); 15 }
当读入文件并标记它来准备数据流时,我想使用内建的string类型作为类型参数,但是使用StreamingControlImpl<string>会产生一个编译错误,这是由于继承层次中的每个上面等级的泛型约束where T : new()要求"string"类型有一个无参的构造函数。由于string类型不具有无参构造函数且它是一个密封类,我们不能创建一个继承自string的类。要解决这个问题而不引入is-a关系,我们可以实现一个拥有has-a关系的新类Item,并使用Item.Next属性获取值!没什么大不了的:
1 internal class Item 2 { 3 private string _text = null; 4 public string Text 5 { 6 get { return _text; } 7 set { _text = value; } 8 } 9 public Item() 10 { 11 _text = string.Empty; 12 } 13 public Item(string t) 14 { 15 _text = t; 16 } 17 }
下面的类图解释了Pipes and Filters模式的整个概念:
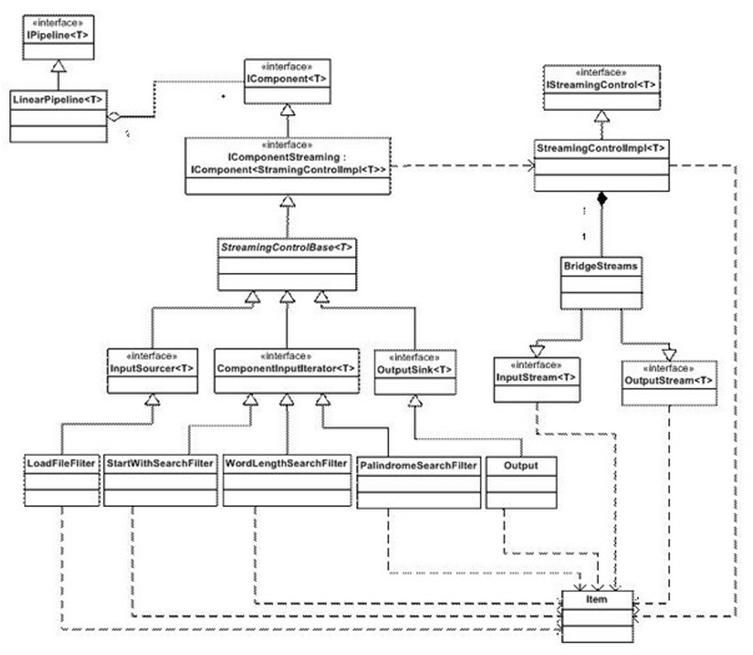
本类图visio源文件下载
Pipes and Filters模式的缺点
Pipes-and-filters模式存在以下缺点[Buschmann]:
-
共享状态信息的操作昂贵且不灵活。信息必须经过编码传递并解码。
-
通过并行处理获得效率通常是种错觉。数据传输,同步及上下文切换的开销会很高,非增量过滤器,如Unix sort,会成为系统的一个瓶颈。
-
数据转换开销。过滤器间使用单一数据管道通常意味着会发生大量的数据格式转换,例如,二进制与字符型格式之间的数字转换问题。
-
错误处理。通常很难检测到Pipes-and-Filters系统中发生的错误,由错误中恢复甚至更困难。
比较
Pipes-and-Filters的好处
Pipes-and-filters模式有以下好处[Buschmann]:
-
灵活地更换过滤器。可以很容易的将两个有着相同接口,工作方式相同的过滤器互换。
-
重组的灵活性。配置一个管道使其包含新的过滤器或者以不同的顺序使用相同的过滤器容易实现,如下所示:
1 pipeline.AddLink(Factory<Item>.CreateLoadFile(@"c:\a.log")); 2 pipeline.AddLink(Factory<Item>.CreateStartWithSearch("wa")); 3 pipeline.AddLink(Factory<Item>.CreateWordLengthSearch(9)); 4 pipeline.AddLink(Factory<Item>.CreatePalindromeSearch()); 5 pipeline.AddLink(Factory<Item>.CreateOutput()); 6 pipeline.Process();
-
过滤器元素的可重用性。过滤器重组的简易增大了过滤器的可重用性。如果环境使它们可以轻松连接起来,这些小且活动的过滤器元素通常很容易被重用。
-
快速实现管道原型。交换和重组的灵活性,可重用的简单性使快速创建原型系统变为可能。
-
并行处理提升效率。因为活动的过滤器运行在不同的进程或线程上,Pipes and Filters系统可以利用多处理器的优势。通过以AND和OR操作符实现一个管道,它也可以处理SPLIT和JOIN操作符。
-
管道中的过滤器可以是一个子管道。管道结构可以包括两个管道,主管道和子管道。例如,主管道包括step 1到step 5,子管道包括step 3-1, step 3-2和step 3-3。特别地,主管道中的step 3有两个角色:它是主管道中普通的一步,同时它也是包含子步骤的一个子管道,如下:

装饰模式的优势
装饰模式有如下好处:
-
灵活地更换具体装饰者。可以很容易地将一个具体装饰者换成另一个。
-
重组的灵活性。重新配置一个调用客户端来指定一组新的职责或者以不同的顺序使用相同职责。如下所示:
1 IComponent<Item> S = new FileLoader(".log"); 2 S = new StartWithSearch(S, "wa"); 3 S = new WordLengthSearch(S, 5); 4 S = new PalindromeSearch(S); 5 S = new Output(S); 6 S.Process();
-
具体装饰者的重用。职责重组的简便促进了具体装饰者的重用。
-
快速实现管道原型。交换和重组的灵活性,可重用的简单性使快速创建原型系统变为可能。
-
并行处理提高效率。我也不清楚此处是否可以利用多线程实际的将不同的职责放到独立的线程中去处理。我认为并行处理是Pipes-and-Filters的一个额外的优点。
-
职责实现是线性的。尽管职责实现是线性的,简单的,考虑到嵌套或者函数性的子管道可能引起保持引用方面的复杂和困难,并且扩展性也会使人头痛。
结论
促使我的基本思想是一方面动态安排过滤器,另一方面职责(包装器)的动态可插拔能力。如果在Pipes and Filters中我不讨论并行管道处理,你会看到顺序处理的Pipes and Filters会很好的映射到Decorator模式。所以在下面场景中它们是有关联的模式,在Pipes and Filters中,管是无状态的,引导数据流穿过多个过滤器,同时过滤器作为流修改器处理输入流并将结果输出流送到下一个过滤器的管中。在Decorator模式中,我们可以将装饰者看作过滤器。
本文中涉及的代码可以在原文章页面下载。