Geo-localization论文阅读3
文章目录
1. Lending Orientation to Neural Networks for Cross-view Geo-localization
CVPR2019
1.1 Thinkings
现存的深度学习方法都是最大化正确pair中两幅图像representations的相似度,同时最小化unpair的两幅图像rpresentations的相似度。但是,本论文从一个简单的场景出发,即人类在森林迷路了,如果只能使用纸质地图,他该如何定位自己在纸质地图中的位置呢?首先,一般人类的做法是旋转纸质地图,让纸质地图的朝向和他现在的朝向一致再进行位置的定位。本篇论文也是受此启发,提出了orientation对于geo-localization的重要性,并显示地将orientation信息加入神经网络进行学习。
总体来说,这篇论文的contributions主要在以下几点:
- 使用一个比较简答且有效的方式将逐像素的朝向信息整合进神经网络用于cross-view localization。
- 一个全新能够同时学习图像外表和朝向信息的孪生神经网络。
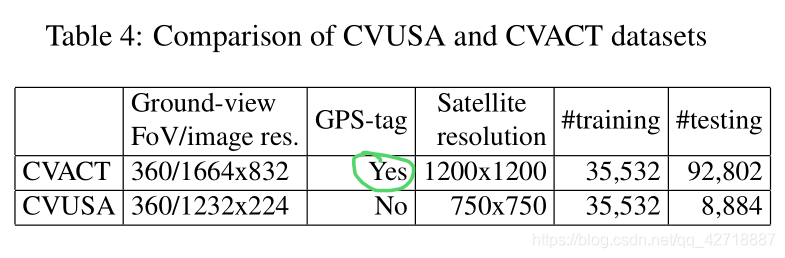
- 贡献了一个大尺度的cross-view image benchmark,CVACT。这个benchmark有GPS-tag。
1.2 Principle Analysis
要理解整篇文章的原理,只需要理解两点:1. 怎么参数化逐像素的朝向信息;2. 怎么把参数化后的朝向信息加入神经网络的学习之中。
1.2.1 参数化朝向信息
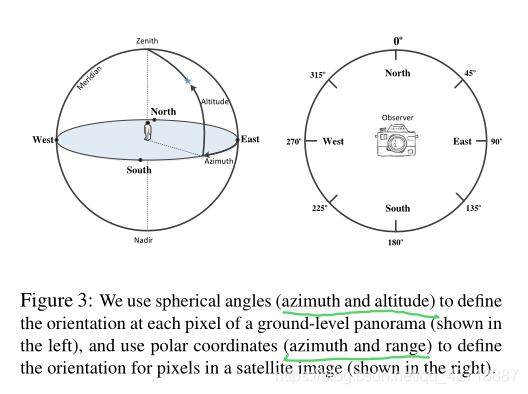
对于街景图像来说,作者采用了球面角(azimuth, altitude),即(方位角,仰角)。方位角的取值范围为[0°, 360°],仰角的范围为[-90°, 90°]。
对于空视图像来说,作者采用了极坐标系描述orientation,即(方位角,半径)。公式如下:
θ
i
=
a
r
c
t
a
n
2
(
x
i
,
y
i
)
(1)
heta_i = arctan2(x_i, y_i) ag{1}
θi=arctan2(xi,yi)(1)
r
i
=
x
i
2
+
y
i
2
(2)
r_i = sqrt{x_i^2 + y_i^2} ag{2}
ri=xi2+yi2(2)
作者就这样,逐像素地将地面全景图像和空视图像全部标注上了orientation。一张图像对应了一个2通道的orientation map,本论文叫做U-V maps。
1.2.2 Inject Orientation Information
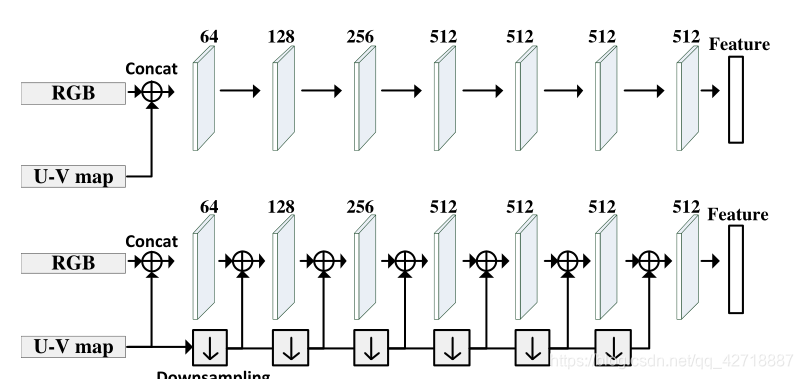
本论文展示了两种inject orientation information的方法:上面那种就是直接把3通道RGB和2通道U-V map进行一个concatenate操作,得到一个5通道的输入;下面那种就是先把3通道RGB和2通道U-V map进行一个concatenate操作,得到5通道输入后,再在其下采样的过程中不断与U-V map的下采样feature进行concatenate。
1.3 Benchmark
本论文的贡献除了上述加入朝向信息进行geo-localization,还创建一个大尺度的cross-view dataset——CVACT,密集地覆盖了Canberra。这个数据集卫星图像分别率达到了0.12m,并且有些图像还是一对多,下表是这个数据集和CVUSA的对比: