具体见官网:http://doris.apache.org/master/zh-CN/sql-reference/sql-statements/Data%20Manipulation/ROUTINE%20LOAD.html#description
下面是个人测试例子:
1.创建DB
CREATE TABLE IF NOT EXISTS user ( siteid INT DEFAULT '10', citycode SMALLINT, username VARCHAR(32) DEFAULT '', pv BIGINT SUM DEFAULT '0' ) AGGREGATE KEY(siteid, citycode, username) DISTRIBUTED BY HASH(siteid) BUCKETS 10 PROPERTIES("replication_num" = "1");
2.准备数据 (kafka topic --doris)
pls input topic:doris pls input msg:6|12|pp|123 send over !!! pls input msg:7|32|ww|231 send over !!! pls input msg:8|12|ee|213 send over !!! pls input msg:
3.导入数据到doris sea.user:任务标示(唯一) columus:列名
CREATE ROUTINE LOAD sea.user ON user COLUMNS TERMINATED BY "|", COLUMNS(siteid,citycode,username,pv) PROPERTIES( "desired_concurrent_number"="1", "max_batch_interval"="20", "max_batch_rows"="300000", "max_batch_size"="209715200") FROM KAFKA( "kafka_broker_list"="192.168.18.129:9092", "kafka_topic"="doris", "property.group.id"="gid", "property.clinet.id"="cid", "property.kafka_default_offsets"="OFFSET_BEGINNING");
1) OFFSET_BEGINNING: 从有数据的位置开始订阅。
2) OFFSET_END: 从末尾开始订阅
3.1 查看routine load状态
SHOW ALL ROUTINE LOAD FOR sea.user;
3.1.1 显示 example_db 下,所有的例行导入作业(包括已停止或取消的作业)。结果为一行或多行。
use example_db;
SHOW ALL ROUTINE LOAD;
Ⅴ).查看routine load状态 SHOW ALL ROUTINE LOAD FOR datasource_name.kafka_load; Ⅵ).常用routine load命令 a).暂停routine load PAUSE ROUTINE LOAD FOR datasource_name.kafka_load; b).恢复routine load RESUME ROUTINE LOAD FOR datasource_name.kafka_load; c).停止routine load STOP ROUTINE LOAD FOR datasource_name.kafka_load; d).查看所有routine load SHOW [ALL] ROUTINE LOAD FOR datasource_name.kafka_load; e).查看routine load任务 SHOW ROUTINE LOAD TASK datasource_name.kafka_load; Ⅶ).查看数据 SELECT * FROM datasource_name.table_name LIMIT 10;
4.查看数据
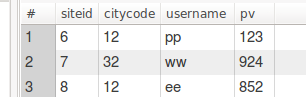
官网:
example:
4. 简单模式导入json CREATE ROUTINE LOAD example_db.test_json_label_1 ON table1 COLUMNS(category,price,author) PROPERTIES ( "desired_concurrent_number"="3", "max_batch_interval" = "20", "max_batch_rows" = "300000", "max_batch_size" = "209715200", "strict_mode" = "false", "format" = "json" ) FROM KAFKA ( "kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092", "kafka_topic" = "my_topic", "kafka_partitions" = "0,1,2", "kafka_offsets" = "0,0,0" ); 支持两种json数据格式: 1){"category":"a9jadhx","author":"test","price":895} 2)[ {"category":"a9jadhx","author":"test","price":895}, {"category":"axdfa1","author":"EvelynWaugh","price":1299} ]
说明: 1)如果json数据是以数组开始,并且数组中每个对象是一条记录,则需要将strip_outer_array设置成true,表示展平数组。
2)如果json数据是以数组开始,并且数组中每个对象是一条记录,在设置jsonpath时,我们的ROOT节点实际上是数组中对象。
6. 用户指定根节点json_root CREATE ROUTINE LOAD example_db.test1 ON example_tbl COLUMNS(category, author, price, timestamp, dt=from_unixtime(timestamp, '%Y%m%d')) PROPERTIES ( "desired_concurrent_number"="3", "max_batch_interval" = "20", "max_batch_rows" = "300000", "max_batch_size" = "209715200", "strict_mode" = "false", "format" = "json", "jsonpaths" = "["$.category","$.author","$.price","$.timestamp"]", "strip_outer_array" = "true", "json_root" = "$.RECORDS" ) FROM KAFKA ( "kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092", "kafka_topic" = "my_topic", "kafka_partitions" = "0,1,2", "kafka_offsets" = "0,0,0" );
json数据格式:
{ "RECORDS": [ { "category": "11", "title": "SayingsoftheCentury", "price": 895, "timestamp": 1589191587 }, { "category": "22", "author": "2avc", "price": 895, "timestamp": 1589191487 }, { "category": "33", "author": "3avc", "title": "SayingsoftheCentury", "timestamp": 1589191387 } ] }