推荐官网文档: https://www.elastic.co/guide/en/logstash/current/index.html
3.31.1 Logstash介绍
Logstash(ELK技术栈中的一员,用于数据的采集,使用ruby来开发)
Logstash是一个具有实时管道功能的开源数据收集引擎,Logstash可以动态地将来自不同数据源的数据统一起来,并将数据规范化为你选择的目的地,清理和大众化你的所有数据,用于各种高级下游分析和可视化用例。
虽然Logstash最初推动了日志收集方面的创新,但是它的功能远远超出了这个用例,任何类型的事件都可以通过大量的输入、过滤器和输出插件来丰富和转换,使用许多原生编解码可以进一步简化摄取过程。Logstash通过利用大量和多种数据来提高你的洞察力。
3.31.2 Input组件介绍
input ~>对接数据源的 ,与Flume框架中agent中的source功能类似
标准输入 stdin{}
input{ stdin{ add_field => {"key" => "value"} #向事件添加一个字段 codec => "plain" #默认是line, 可通过这个参数设置编码方式 tags => ["std"] #添加标记 type => "std" #添加类型 id => 1 #添加一个唯一的ID, 如果没有指定ID, 那么将生成一个ID enable_metric => true #是否开启记录日志, 默认true } } # stdin官方参考: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-stdin.html
文件输入 file{}
input{ file{ path => ["/var/log/nginx/access.log", "/var/log/nginx/error.log"] #处理的文件的路径, 可以定义多个路径 exclude => "*.zip" #匹配排除 sincedb_path => "/data/" #sincedb数据文件的路径, 默认<path.data>/plugins/inputs/file codec => "plain" #默认是plain,可通过这个参数设置编码方式 tags => ["nginx"] #添加标记 type => "nginx" #添加类型 discover_interval => 2 #每隔多久去查一次文件, 默认15s stat_interval => 1 #每隔多久去查一次文件是否被修改过, 默认1s start_position => "beginning" #从什么位置开始读取文件数据, beginning和end, 默认是结束位置end } } # file官方参考: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-file.html
TCP/UDP输入 tcp/udp{}
input{ tcp{ port => 8888 #端口 mode => "server" #操作模式, server:监听客户端连接, client:连接到服务器 host => "0.0.0.0" #当mode为server, 指定监听地址, 当mode为client, 指定连接地址, 默认0.0.0.0 ssl_enable => false #是否启用SSL, 默认false ssl_cert => "" #SSL证书路径 ssl_extra_chain_certs => [] #将额外的X509证书添加到证书链中 ssl_key => "" #SSL密钥路径 ssl_key_passphrase => "nil" #SSL密钥密码, 默认nil ssl_verify => true #核实与CA的SSL连接的另一端的身份 tcp_keep_alive => false #TCP是否保持alives } } input{ udp{ buffer_size => 65536 #从网络读取的最大数据包大小, 默认65536 host => 0.0.0.0 #监听地址 port => 8888 #端口 queue_size => 2000 #在内存中保存未处理的UDP数据包的数量, 默认2000 workers => 2 #处理信息包的数量, 默认2 } } # tcp官方参考: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-tcp.html # udp官方参考: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-udp.html
syslog输入 syslog{}
input{ syslog{ host => 0.0.0.0 #监听地址, 默认0.0.0.0 port => "8888" #端口 } } # syslog官方参考: https://www.elastic.co/guide/en/logstash/current/plugins-inputs-syslog.html
3.31.3 Filter组件介绍
filter ~> 对数据进行清洗,过滤的, 与Flume框架中intercepter类似,属于source组件,不属于一个单独的组件
Filter的使用
filter的处理,目前我们的需求是需要对字符串进行key-value的提取
1、使用了mutate中的split,能通过分割符对分本处理。 2、通过grok使用正则对字符串进行截取处理。 3、使用kv 提取所有的key-value
input { file{ path => "/XXX/syslog.txt" start_position => beginning codec => multiline{ patterns_dir => ["/XX/logstash-1.5.3/patterns"] pattern => "^%{MESSAGE}" negate => true what => "previous" } } } filter{ mutate{ split => ["message","|"] add_field => { "tmp" => "%{[message][0]}" } add_field => { "DeviceProduct" => "%{[message][2]}" } add_field => { "DeviceVersion" => "%{[message][3]}" } add_field => { "Signature ID" => "%{[message][4]}" } add_field => { "Name" => "%{[message][5]}" } } mutate{ split => ["tmp",":"] add_field => { "tmp1" => "%{[tmp][1]}" } add_field => { "Version" => "%{[tmp][2]}" } remove_field => [ "tmp" ] } grok{ patterns_dir => ["/XXX/logstash-1.5.3/patterns"] match => {"tmp1" => "%{TYPE:type}"} remove_field => [ "tmp1"] } kv{ include_keys => ["eventId", "msg", "end", "mrt", "modelConfidence", "severity", "relevance","assetCriticality","priority","art","rt","cs1","cs2","cs3","locality","cs2Label","cs3Label","cs4Label","flexString1Label","ahost","agt","av","atz","aid","at","dvc","deviceZoneID","deviceZoneURI","dtz","eventAnnotationStageUpdateTime","eventAnnotationModificationTime","eventAnnotationAuditTrail","eventAnnotationVersion","eventAnnotationFlags","eventAnnotationEndTime","eventAnnotationManagerReceiptTime","_cefVer","ad.arcSightEventPath"] } mutate{ split => ["ad.arcSightEventPath",","] add_field => { "arcSightEventPath" => "%{[ad.arcSightEventPath][0]}" } remove_field => [ "ad.arcSightEventPath" ] remove_field => [ "message" ] } } output{ kafka{ topic_id => "rawlog" batch_num_messages => 20 broker_list => "10.3.162.193:39192,10.3.162.194:39192,10.3.162.195:39192" codec => "json" } stdout{ codec => rubydebug } }
3.31.4 Output组件介绍
output ~> 定制数据处理之后的目的地, 与Flume框架中agent中的sink功能类似
输出到file
配置conf: input{ file{ path => "/usr/local/logstash-5.6.1/bin/spark-test-log.log" type => "sparkfile" start_position => "beginning" } } filter{ grok{ patterns_dir => '/usr/local/logstash-5.6.1/patterns/selfpattern' match => ["message", "%{DATE:date} %{SKYTIME:time} %{LOGLEVEL:loglevel} %{WORD:word}"] } } output{ file{ path => "/tmp/%{+YYYY.MM.dd}-%{host}-file.txt" } }
3.31.5 Logstash与Flume比较
Logstash Flume (三个组件组织成agent)
input source
output sink
各个组件之间的buffer channel (数据缓存的媒介,是:内存,文件)
filter (过滤采集后的数据 ) source中的拦截器
Flume初体验
Flume的配置比较繁琐,source,channel,sink的关系在配置文件里面交织在一起,没有Logstash那么简单明了。
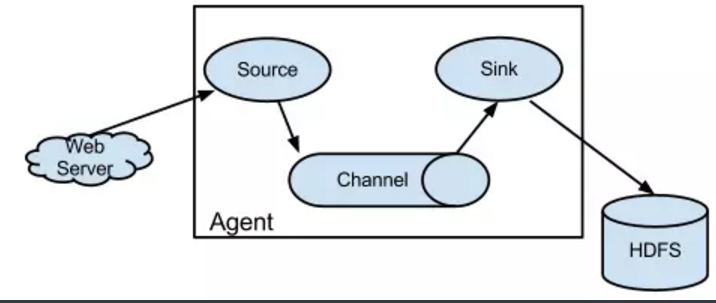
Flume与Logstash相比,有如下特点:
Logstash比较偏重于字段的预处理;而Flume偏重数据的传输;
Logstash有几十个插件,配置灵活;FLume则是强调用户的自定义开发(source和sink的种类也有一二十个,相对而言,channel就比较少)。
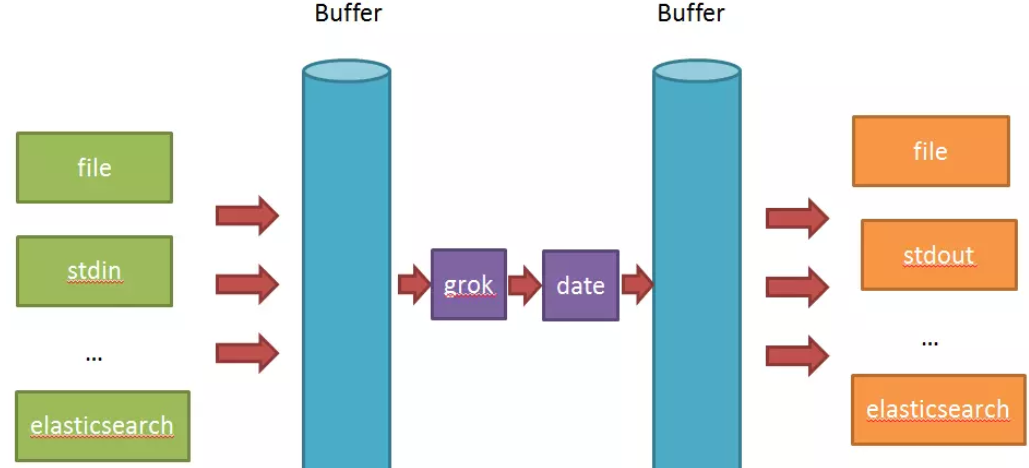
Logstash的input和filter还有output之间都存在buffer,进行缓冲;Flume直接使用channel做持久化(可以理解为没有filter,但是可以配置interceptor)
而Logstash中:
①input负责数据的输入(产生或者说是搜集,以及解码decode);
②Filter负责对采集的日志进行分析,提取字段(一般都是提取关键的字段,存储到elasticsearch中进行检索分析);
③output负责把数据输出到指定的存储位置(如果是采集agent,则一般是发送到消息队列中,如kafka,redis,mq;如果是分析汇总端,则一般是发送到elasticsearch中);
④在Logstash比较看重input,filter,output之间的协同工作,因此多个输入会把数据汇总到input和filter之间的buffer中。filter则会从buffer中读取数据,进行过滤解析,然后存储在filter于output之间的Buffer中。当buffer满足一定的条件时,会触发output的刷新。
在Flume中:
①source 负责与Input同样的角色,负责数据的产生或搜集(一般是对接一些RPC的程序或者是其他的flume节点的sink)
②channel 负责数据的存储持久化(一般都是memory或者file两种)
③sink 负责数据的转发(用于转发给下一个flume的source或者最终的存储点——如HDFS)
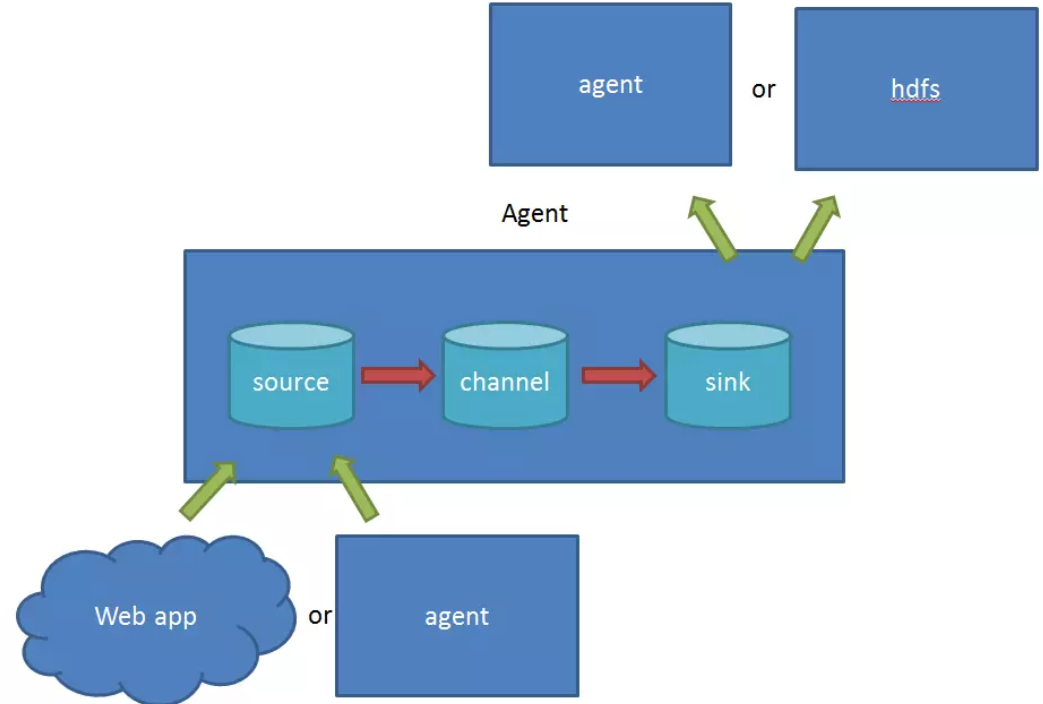
Flume比较看重数据的传输,因此几乎没有数据的解析预处理。仅仅是数据的产生,封装成event然后传输。传输的时候flume比logstash多考虑了一些可靠性。因为数据会持久化在channel中(一般有两种可以选择,memoryChannel就是存在内存中,另一个就是FileChannel存储在文件种),数据只有存储在下一个存储位置(可能是最终的存储位置,如HDFS;也可能是下一个Flume节点的channel),数据才会从当前的channel中删除。这个过程是通过事务来控制的,这样就保证了数据的可靠性。不过flume的持久化也是有容量限制的,比如内存如果超过一定的量,也一样会爆掉。
3.31.6 Logstash的安装
①下载安装包 https://www.elastic.co/guide/en/logstash/current/index.html 首先下载logstash,上传到服务器
logstash是用JRuby语言开发的,所以要安装JDK
②解压: tar -zxvf logstash-6.5.3.tar.gz -C 指定的目录
③修改logstash核心的执行文件 在bin目录下,有一个可执行的文件logstash,需要添加参数:(可以先不用设置,报错的话再设置) LS_JAVA_OPTS="-server -Xms256m -Xmx512m -XX:PermSize=128m -XX:MaxPermSize=256m"
④验证安装是否成功: a) bin/logstash -e 'input { stdin {} } output { stdout{} }' ~> 启动需要等一会儿 Are you ready? { "@version" => "1", "message" => "Are you ready?", "host" => "JANSON01", "@timestamp" => 2019-03-29T07:54:36.874Z } 最近有些郁闷... { "@version" => "1", "message" => "最近有些郁闷...", "host" => "JANSON01", "@timestamp" => 2019-03-29T07:54:56.093Z }
说明:高版本的logstash,日志输出的格式(若是stdout),默认格式就是rubydebug。
旧版本的logstash,输出的格式形如: JANSON01 2018-12-26T07:09:04.336Z are you ok
b)启动后,通过jps命令,可以查看到名为Logstash的进程名
3.31.7 Logstash运行
案例1:使用logstash收集控制台上的录入,并使用rubydebug日志输出格式,输出到控制台上。./logstash -e 'input { stdin {} } output { stdout{codec => rubydebug} }'
案例2:使用logstash收集控制台上的录入,将结果输出到控制台上;且输出到Elastisearch索引库中(es单机版)。./logstash -e 'input { stdin {} } output { elasticsearch {hosts => ["JANSON01:9200"]} stdout{} }'
注意:
①索引库的名字?默认:logstash-年.月.日
②默认的type的名字是:doc
案例3:使用logstash收集控制台上的录入,将结果输出到控制台上;且输出到Elastisearch索引库中(es集群版,可以提高logstash输出数据的健壮性,不容易丢失。相当于:开启了重试机制)。./logstash -e 'input { stdin {} } output { elasticsearch {hosts=>["JANSON02:9200", "JANSON03:9200"]} stdout{} }'
注意:
①若是搭建了es集群,向集群中的某台es服务器写入数据,也会自动从该服务器同步到别集群中别的es服务器上。
②若是搭建了真实的es集群,建议向集群中多个节点写入(本质上也是向一台可用的es服务器中写入,该es服务器宕机了,才会选择其他es服务器)。
案例4:使用logstash收集控制台上的录入,将结果输出到控制台上;且输出到kafka消息队列中。./logstash -e 'input { stdin {} } output { kafka { topic_id => "test" bootstrap_servers => "JANSON01:9092,JANSON02:9092,JANSON03:9092"} stdout{codec => rubydebug} }'
注意: ①前提: a)开启zookeeper集群 zkServer.sh start b)开启kafka集群 kafka-server-start.sh -daemon /opt/kafka/config/server.properties c)手动创建主题 i)查询kafka集群中所有的主题 [root@JANSON03 ~]# kafka-topics.sh --list --zookeeper JANSON01:2181,JANSON02:2181,JANSON03:2181 Hbase Spark __consumer_offsets bbs gamelogs gamelogs-rt hadoop hive spark test ii) 运行的效果: [root@JANSON03 ~]# kafka-console-consumer.sh --topic test2 --zookeeper JANSON01:2181 --from-beginning Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]. 2019-03-29T08:40:16.312Z JANSON01 要采集数据到kafka集群中了哦 2019-03-29T08:42:50.852Z JANSON01 Kafka, Are you ok? ②若目的地是kafka,需要指定主题名 a)主题若是存在,直接使用 b)若不存在,会自动创建,但是,只有一个分区,一个副本 c) 从数据安全性的角度考虑,建议手动新建主题,设置多个副本 ③bootstrap_servers参数用于指定kafka集群的配置信息。 ④elk技术栈中,只有elasticsearch进程需要在普通用户下启动,别的进程可以在普通用户下启动,也可以是root用户
a) bin/logstash -e 'input { stdin {} } output { stdout{} }' ~> 启动需要等一会儿 Are you ready?{ "@version" => "1", "message" => "Are you ready?", "host" => "JANSON01","@timestamp" => 2019-03-29T07:54:36.874Z}最近有些郁闷...{ "@version" => "1", "message" => "最近有些郁闷...", "host" => "JANSON01","@timestamp" => 2019-03-29T07:54:56.093Z