MapReduce与spark
MapReduce: 操作单一,只有map,reduce spark:提供多种操作:过滤,分组,排序....

(一)spark生态环境:
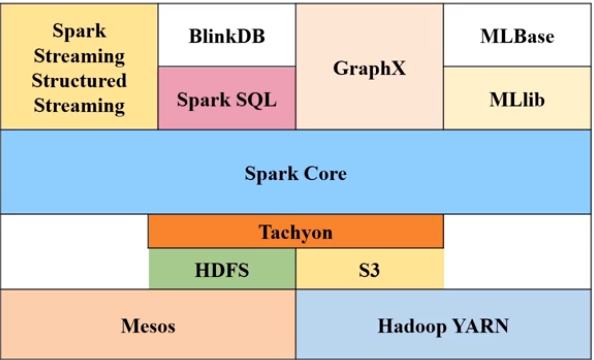
- Mesos和YARN都是资源调度管理器
- HDFS:分布式系统存储组件
- S3:亚马逊提供的云端的简单的存储服务
- Tachyon:基于内存的分布式文件系统
- Spark Core:复杂批量数据处理,取代MapReduce Hive
- Spark Streaming:满足实时数据流毫秒级计算需求,基于RDD数据抽象
- Structured Streaming:满足特定场景下的实时数据流毫秒级流计算需求,基于DataFrame数据抽象(在spark 2.2之后成为正式版)
- Spark SQL:满足历史数据交互式查询分析需求
- GraPhx:满足图计算需求
- MLlib:满足机器学习需求;机器学习算法库,可以直接调用算法接口;历史数据的数据挖掘需求
(二)运行架构
- RDD(弹性分布式数据集):最核心的数据抽象;提供高度受限的共享内存模型(只读)
- DAG(有向无环图):反映RDD之间的依赖关系
- Executor(进程):节点上派生多线程运行任务
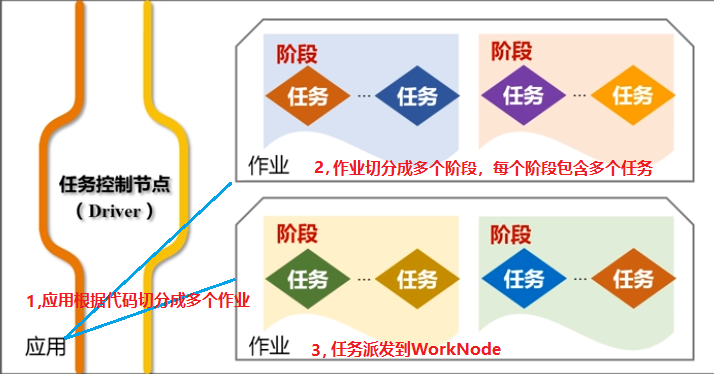
- application(应用程序):用户写的程序
- Job(作业):切分为多个阶段
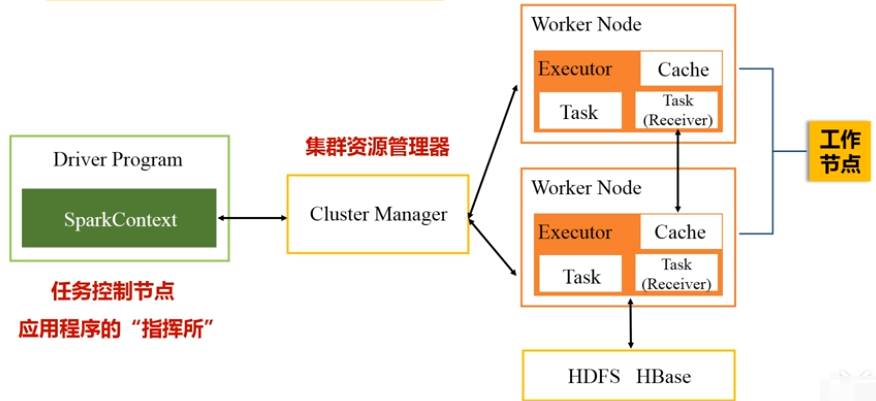
- 结构:
7,关键词之间关系:
(三)运行流程:
1,应用程序发到主节点,Driver(指挥所)派生出SparkContext对象(指挥官);
2,SparkContext会申请资源管理器,把作业分成不同阶段并把每个阶段的任务调度到不同的工作节点(Worker Node)上执行。监控所有过程;
3,资源管理器收到请求后会分配内存资源,启动Executor 进程(驻留在工作节点上)派生多个线程;
4,SparkContext会将代码中的对RDD的操作转换为RDD的依赖关系,根据依赖关系构建DAG图,将DAG图发送到DAG Scheduler组件;
5,DAG Scheduler把DAG分解成多个Stage(阶段);Stage发到Task Scheduler(根据工作节点上的Executor的申请分发任务到与数据对应的工作节点),计算程序发到数据相关的工作节点;
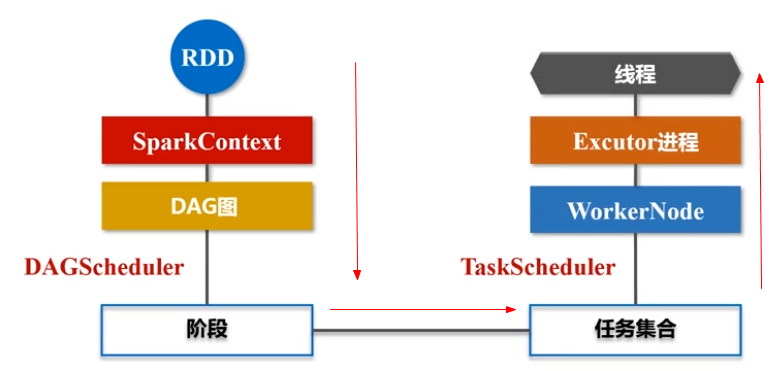
6,Executor把结果反馈到Task Scheduler------->DAG Scheduler--------->SparkContext做最后的处理(返回给用户或HDFS);

(四)RDD概述:
1,RDD运行原理:提供抽象的数据结构,根据依赖关系生成DAG图,形成流水线,在内存中操作,避免操作磁盘数据
2,RDD:只读的分区集合(不同的分区到不同的机器并行处理);操作时,将原来的RDD转换生成新的RDD
3,RDD操作:分为动作类型操作和转换类型操作;转换类型操作:只记录转换的轨迹,不发生计算。(一次只能对一整个RDD进行粗粒度操作,不支持细粒度操作),scala
的接口提供简单操作(转换,过滤,排序,Map,Reduce)
4,图示:
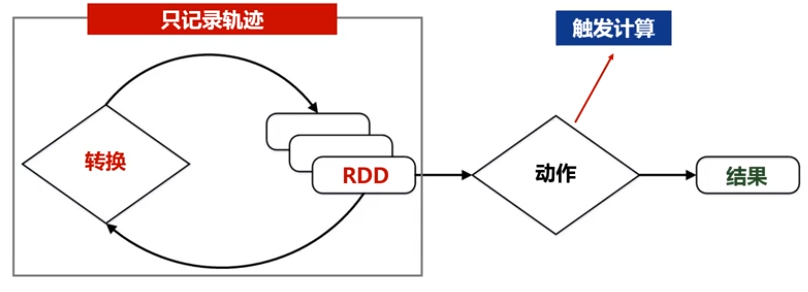
提供容错机制,恢复数据简单:

5,RDD的依赖关系:窄依赖(不划分阶段);宽依赖(划分多个阶段,递归算法划分);根据Shuffle操作判断,如果存在Shuffle操作(洗牌)就是宽依赖
例如:单词统计操作中,Map操作后会进行Shuffle操作,将相同的单词放入一个Reduce中。
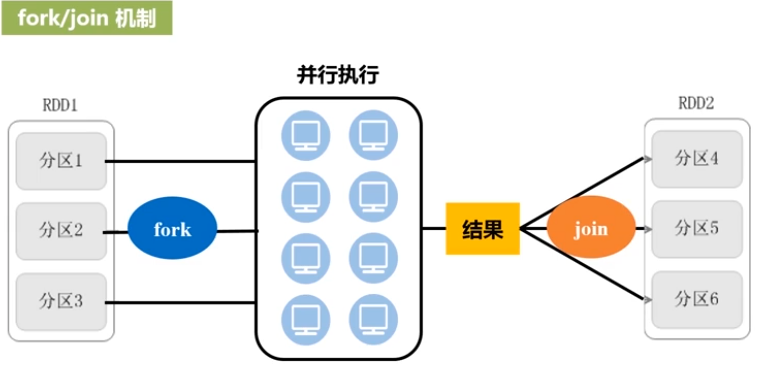
窄依赖:父RDD对应子RDD的关系:一对一或多对一;不涉及数据转换;可以进行流水线优化(优化原理:fork/join机制;并行执行任务的框架)
宽依赖:父RDD对应子RDD的关系:一对多;涉及数据转换;不可以进行流水线优化(当发生shuffle操作时会进行对磁盘的读写操作)

(五)Spark安装
spark-2.1.0-hadoop-2.6版:下载地址:http://d3kbcqa49mib13.cloudfront.net/spark-2.1.0-bin-hadoop2.6.tgz
安装单机教程:http://dblab.xmu.edu.cn/blog/1307-2/