本文请结合《索引,索引优化,mysql索引失效场景》食用。(https://www.cnblogs.com/lpeng94/p/12546455.html)
监控项:
- 网络相关
- Bytes_received
- Bytes_sent
- TPS:Transaction Per Second,每秒事务处理量
- Com_commit
- Com_rollback
- 连接相关
- created_tmp_disk_use
- connections
- connection_errors_max_connections
- threads_created
-
负载相关
- innodb_rows_deleted
- innodb_rows_inserted
- innodb_rows_read #异常高时,说明系统处理了过多的行。此时要去找SQL。而SQL在的地方:慢查询里或show processlist里。
- innodb_rows_updated
- sort_rows
-
QPS: Query Per Second,每秒查询率
- Queries
- Com_delete
- Com_insert
- Com_insert_select
- Com_select
- Com_update
- 内存相关
- innodb_buffer_pool_pages_data
- innodb_buffer_pool_pages_free
- innodb_buffer_pool_pages_dirty
- IO相关
- innodb_buffer_pool_pages_flushed #flushed 忽然高起来,说明是写的问题。比如logfile过小之类的
- innodb_buffer_pool_wait_free
- innodb_data_reads
- innodb_log_waits
- 锁相关
- innodb_row_lock_waits
- 排序相关
- sort_merge_passes
- SQL相关
- select_full_join
- select_scan
- 慢查询相关
- slow_queries
优化整理思路
1、OS操作系统层面监控主要的资源消耗
- io:io负载是否过量(iostat 1 -x)
- cpu:多个cpu是否繁忙
- (mpstat -A 1 #能够看到每颗cpu)
- (vmstat 1 #能看整体的)
- 内存: 内存是否消耗殆尽,产生了swap
- 网络:带宽
2、mysql数据库层面监控
注:OS底层只能说明出来io很高,mysql层面可以具体的告诉我们是哪些具体的原因导致的。
(1)负载突然增加
表现:tps、qps忽然增加。
(2)tps、qps并没增加,但是处理行数的系统负载突然增加
表现:innodb_rows_read 高
说明糟糕的sql出现了 #此值等于sql实际处理的行数。处理的行数就是负载。
什么是糟糕的sql?:
- ①正在慢的sql
show full processlist G ;explain 看sql的执行计划 ;
模拟执行这个sql:explain SQL语句 for update; 看结构。然后执行sql,看执行的时间(1s就不正常了)!
- ②已经慢的sql -> slow-log里
- ③全表扫描的sql
(3)写负载忽然增加
- ①是否有异常的dml
表现:负载相关参数的row_deleted、rows_inserted、rows_updated 会很高。 可能的原因:批量的增删改、异常的checkpoint。
- ②logfile过小
- ③电池是否异常
对于慢sql,有两个执行步骤。
- ①执行计划的显示和排错
- ②模拟执行sql
导流的方式来进行压力测试(网络层面tcp copy)
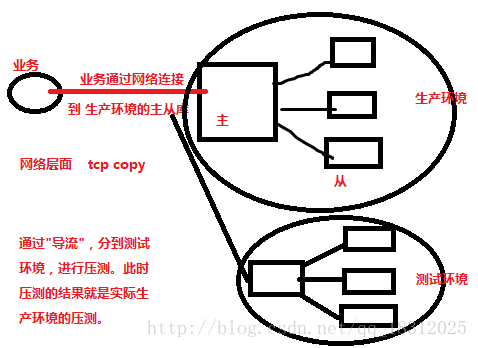
对于select语句来说,可以直接执行;
对于dml:
- ①insert 和 insert select
eg:insert into t1 select * from t2 where id<1000;
(慢在select)
[select * from t1 where id<1000;]- ②delete …where
eg:delete from t1 where id < 1000; (实质还是要先找到,才能删)- ③update …where
eg:update t1 set name='abc' where id <1000;
[select * from t1 where id<1000;]select语句的执行顺序和负载点分析
explain select ... from stock where s_i_id = 65534 and s_w_id = 1 for update;如何判断一个SQL很糟糕
- ①explain执行计划判断
id:查询序号即为sql语句执行的顺序
select_type:select类型
[ simple 它表示简单的select,没有union和子查询;primary 最外面的select,在有子查询的语句中,最外面的select查询就是primary;union union语句的第二个或者说是后面那一个;dependent union UNION中的第二个或后面的SELECT语句,取决于外面的查询;union result]
- table:访问哪个表
- type:连接类型(all、ref……)(重要且难)
- possible_keys:访问这张表有哪些列可以选
- key:最后走了哪个索引列
- key_len:索引列的长度
- rows:这条sql实际要访问的行数;
- extra:回表,用了什么。

(会访问97934行,然后才返回4行(我们预测的),所以是个糟糕的sql)

(访问10行,返回4行,效果很好)
- ②执行判断
- 1.看执行时间
- 2.看实际访问行数
show table status like ''%t1%;
#能看一个表有多少行
show index from stock;
#看表的 索引、列、card(基数,即列的值数,越高越好)
Cardinality:这个列有238778个值。假设这个表一共有95万行,而s_i_id 这个列有23万个值。即:一个值有 4 行 –>
select * from 这个列 where … 平均返回4行
show create table stock G
desc stock;
优化查询:
添加索引
在生产中添加索引的风险:
- ①产生锁(如果表大的话,一个alter语句可能要好几天才完成)
- ②执行时间可能非常长,资源消耗非常大
慢查询
看慢sql的时候可以去看slow sql 的日志。慢查询的sql都在里面存着。
慢查询日志会很大,怎么看?
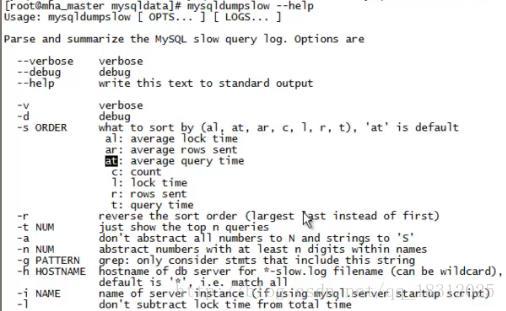
mysqldumpslow 选项 slowmysql.log
- -r:反序排序
- -t 10:显示前10个
- -s:按什么来排序
- -t:按查询时间(即显示出来的是最慢的几条,往下查询时间依次递减)
- -r:按处理的行数
- -l:按锁的时间
- -c:按count
- -al:按平均锁的时间
- -ar:按平均处理的行数
- -at:按平均查询时间(默认是at)
经典的工具
- explain命令
- show create table 命令
- show indexes 命令
- show table status命令
- show status命令
- show variables 命令