0.PTA得分截图

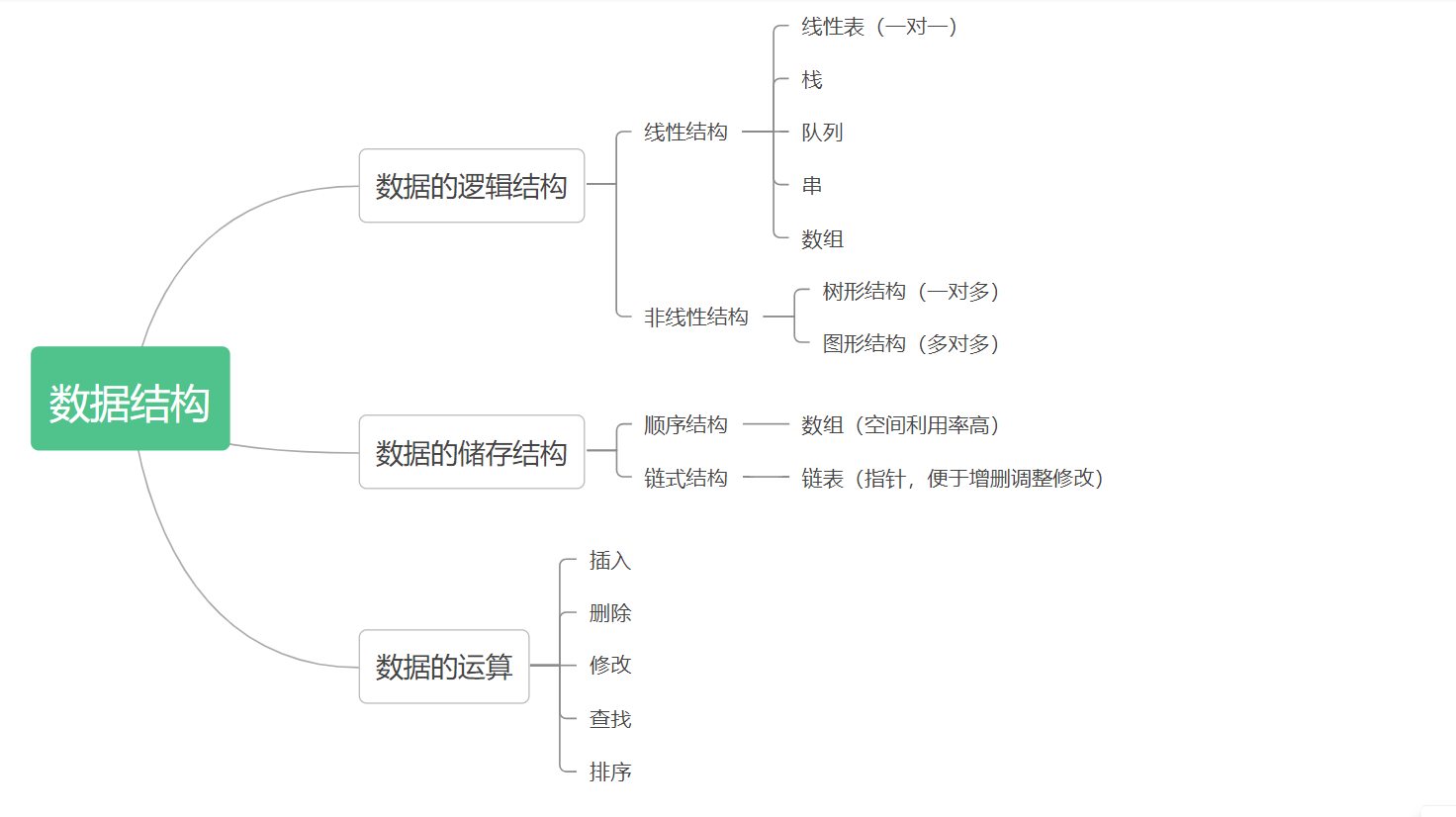
1.本周学习总结
1.1 总结线性表内容
·线性表是具有相同数据类型的 n (n>= 0)个数据元素的有限序列
·当 n = 0 时,该线性表是一个空表。
·一般表示如下:
· L = ( a1 , a2 , a3 , ... ,a(n) )
·其中,a1 是唯一的 “ 第一个 ” 数据元素,又称为表头元素;a(n) 是唯一的 “ 最后一个 ” 数据元素,
又称为表尾元素。除了第一个元素外,每个元素有且仅有一个直接前驱。除最后一个元素外 ,每个元素
有且仅有一个直接后继。
·线性表的特点:
·表中元素的个数有限。
·表中元素具有逻辑上的顺序性,在序列中各元素排序有其先后次序
·表中元素都是数据元素,每一个元素都是单个元素
·表中元素的数据类型都相同,这意味着每一个元素占有相同大小的存储空间
·表示元素具有抽象性,即仅讨论元素间的逻辑关系,不考虑元素究竟是什么内容
·线性表是一种逻辑结构,表示元素之间一对一的相邻关系
顺序表的基本操作
顺序表的结构体定义
typedef struct
{
int data[max];
int length;//表长
}Sqlist;
单链表结点定义
typedef struct LNode
{
int data; //存放结点数据域
struct LNode *next; //指向后继结点的指针
}LNode; //定义单链表结点类
分配内存
N=new LNode;
free(A)
建立顺序表
void FoundSlist(SeqList &L)
{//创建顺序表,给data初步赋值
int n;
cin >> n;//定义长度
for(int i=0;i<n;i++)
{
cin >>L->data[i];//输入数据
}
}
插入数据
·插入流程:
移动
插入
修改长度
int InsertSlist(SeqList &L,int i,Datatype x)//在表的第i个位置上插入一个值为 x 的新元素
{
int j;
for(j=L->last;j>=(i-1);j--)
{
L->data[j+1]=L->data[j];//查找插入位置
}
L->data[i-1]=x;//插入x
L->last++;//增加长度
return 1;
}
删除数据x
·基本操作:
删除操作
删除元素
修改长度
int Deletelist(SeqList &L,int i)//删除是指在表的第i个位置上删除一个元素
{
int j;
for(j=i;j<=L.last;j++)
{
L->data[j-1]=L->data[j];//查找删除数据
}
L->last--;//数据长度减
return 1;
}
链表
基本分类
·链表一般分为:
·单向链表
·双向链表
·环形链表
基本概念
·链表实际上是线性表的链式存储结构,与数组不同的是,它是用一组任意的存储单元来存储线性
表中的数据,存储单元不一定是连续的,
·链表的长度不是固定的(链表数据的这一特点使其可以非常的方便地实现节点的插入和删除操作)
·链表的每个元素称为一个节点,每个节点都可以存储在内存中的不同的位置,为了表示每个元素
与后继元素的逻辑关系,以便构成“一个节点链着一个节点”的链式存储结构。
·链表的每个节点都包含两个部分,第一部分称为链表的数据区域,用于存储元素本身的数据信息,
一般用data表示。
·第二部分是一个结构体指针,称为链表的指针域,用于存储其直接后继的节点信息,一般用next
表示,next的值实际上就是下一个节点的地址,当前节点为末节点时,next的值设为空指针
链表的结构体定义
#include <iostream>
using namespace std;
typedef int ElemType;
typedef struct LNode //定义单链表结点类型
{
ElemType data;
struct LNode *next;//指向后继结点
} LNode,*LinkList;
头插法
每一次都将s值得节点插向最前端
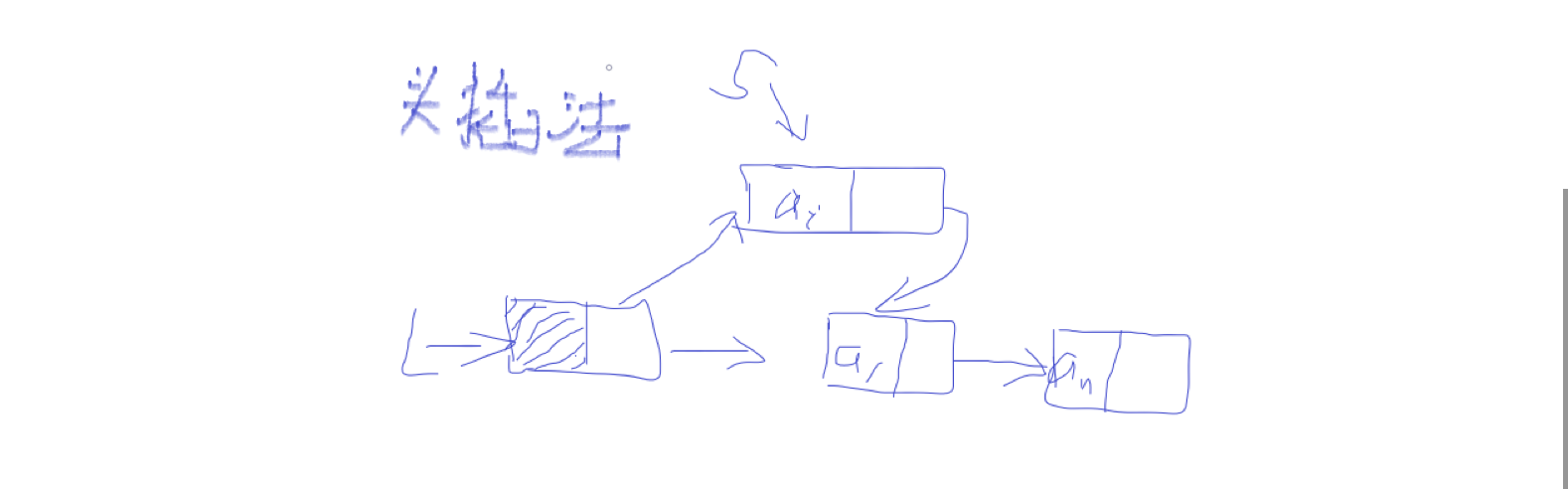
void HeadCreatList(List &L) //头插法建立链表
{
List s; //不用像尾插法一样生成一个终端节点。
L->next = NULL;
for (int i = 0; i < 10; i++)
{
s = new LNode;//s指向新申请的节点
s->data = i;//用新节点的数据域来接受i
s->next = L->next; //将L指向的地址赋值给S;(头插法与尾插法的不同之处主要在此,
s所指的新节点的指针域next指向L中的开始节点)
L->next = s; //头指针的指针域next指向s节点,使得s成为开始节点。
}
}
头插法的关键主要在于最后的两句
s->next = L->next;
L->next = s;
·创建第一个结点
*执行第一次循环时,第一次从堆中开辟一块内存空间给s,此时需要做的是将第一个结点与 L
连接起来。而我们前面已经说过,单链表的最后一个结点指向的是 NULL。
*因此插入第一个结点时,我们需要将头指针指向的 next 赋给新创建的结点的 next , 这
样第一个插入的结点的 next 指向的就是 NULL。 接着,我们将数据域,也就是 s 的地址
赋给 L->next, 这时 L->next 指向的就是新创建的 s的地址。而 L 指向的就是 NULL。
·接着我们创建第二个结点
*因为使用的头插法,因此新开辟的内存空间需要插入 头指针所指向的下一个地址,也就是新开
辟的 s 需要插入 上一个 s 和 L 之间。 第一个结点创建之后,L->next 的地址是 第一个
s 的地址。 而我们申请到新的一块存储区域后,需要将 s->next 指向 上一个结点的首地址,
而新s的地址则赋给 L->next。 因此也就是 s->next = L->next 。
这样便将第一个结点的地址赋给了新创建地址的 next 所指向的地址。后两个结点就连接起来。
*接下来再将头结点的 next 所指向的地址赋为 新创建s 的地址。 L->next =s,这样就将头结
点与新创 建的结点连接了起来。 此时最后一个结点,也就是第一次创建的结点的数据域为0,
指针域为 NULL。
尾插法
每次将所插的节点s指向末端

void TailCreatList(List *L) //尾插法建立链表
{
List s, r;//s用来指向新生成的节点。r始终指向L的终端节点。
r = L; //r指向了头节点,此时的头节点是终端节点。
for (int i = 0; i < 10; i++)
{
s = new LNode;//s指向新申请的节点
s->data = i; //用新节点的数据域来接受i
r->next = s; //用r来接纳新节点
r = s; //r指向终端节点
}
r->next = NULL; //元素已经全部装入链表L中 //L的终端节点指针域为NULL,L建立完成
}
尾插法关键语句
r->next = s;
r = s;
·尾插法创建第一个结点
*刚开始为头结点开辟内存空间,因为此时除过头结点没有新的结点的建立,接着将头结点的指针域
s->next 的地址赋为 NULL。因此此时,整个链表只有一个头结点有效,因此 head此时既是头结
点,又是尾结点。因此将头结点的地址赋给尾结点 r 因此:r = head。 此时r 就是 head,
head 就是 r。 r->next 也自然指向的是 NULL。
·尾插法创建第二个结点
*创建完第一个结点之后,我们入手创建第二个结点。 第一个结点,r 和 head 共用一块内存空间。
现在从堆中心开辟出一块内存给 s,将s的数据域赋值后,此时 end 中存储的地址是 head 的地
址。此时,r->next 代表的是头结点的指针域,因此 r->next = s代表的就是将上一个,也就
是新开辟的 s 的地址赋给 head 的下一个结点地址。
*此时,r->next 的地址是新创建的 s的地址,而此时r 的地址还是 head 的地址。 因此 r = s,这
条作用就是将新建的结点 s 的地址赋给尾结点 r。 此时 r 的地址不再是头结点,而是新建的结点 s。
链表的删除
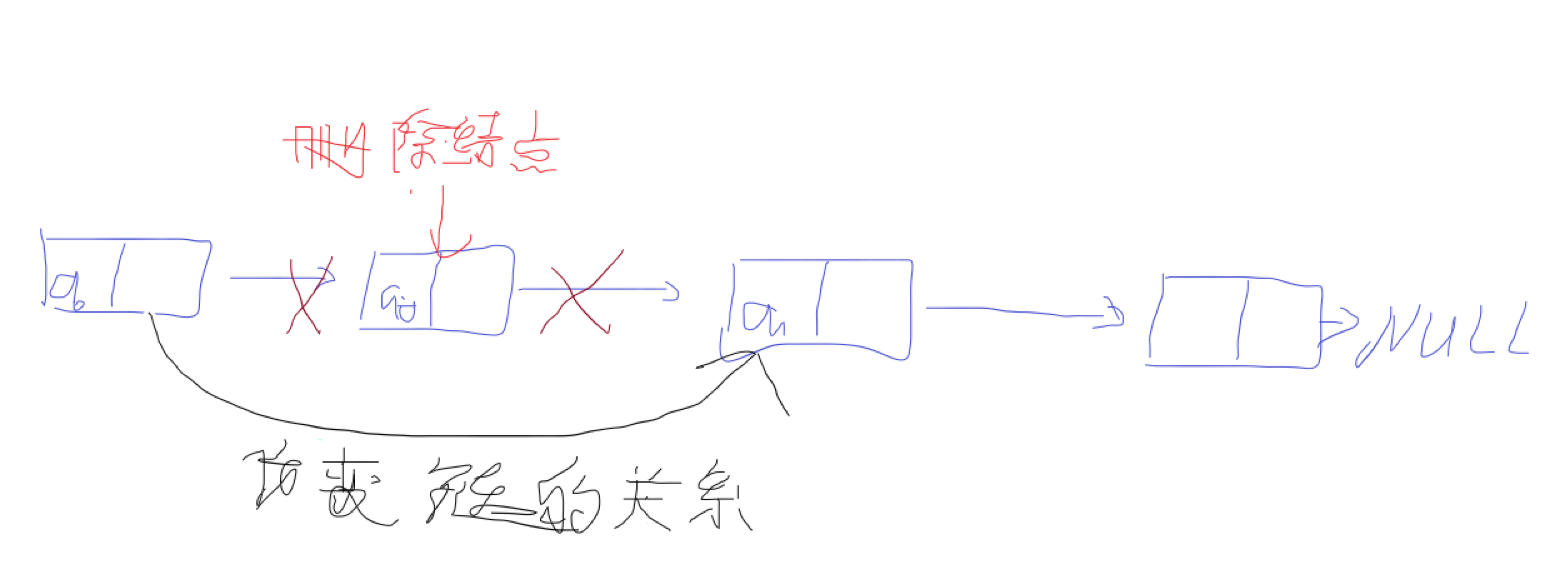
假设p为指向a的指针,则只需将p的指针域next指向原来p的下一个结点的下一个结点即可,即:
p->next=p->next->next;
完整的删除操作是:
q=p->next;
p->next = p->next->next;
查找链表C(带头结点)中是否存在一个值为x的结点,若存在,则删除该结点并返回1,否则返回0
int findAndDelete(LNode &L,int x)
{
LNode *p,*q;
p = L;
while(p->next!=NULL) //循环找到要删除结点的前一个结点
{
if(p->next->data == x)
break;
p = p->next;
}
if(p->next == NULL)
return 0;
else
{
q = p->next;
p->next = q->next;
return 1;
}
}
本周总结
这周学习了线性表,它有两种存储方式,一种顺序储存,用的是数组,另一种是链式存储,用的是链表。
线性表是一对一的结构,可以作为存放数据的容器,而且可以用它的基本操作来完成更复杂的功能。线性
表是n个数据元素的有限序列,主要分为顺序存储结构和链式存储结构,有优点也有缺点,准确把握其特
点在应用时会方便精准很多。逻辑关系上相邻的两个元素在物理位置上也相邻。线性表的优点:随机存取
表中任一元素,它的存储位置可用一个简单、直观的公式来表示。缺点:作插入或删除操作时,需移动大
量元素。
区间删除数据
题目


提交列表

·第一次提交是没有考虑到链表的长度,导致程序出现崩溃的问题,最后加上L->length = 0这一语句才解决
·最后在输出时没有考虑链表为空的问题,导致答案错误
链表倒数第m个数
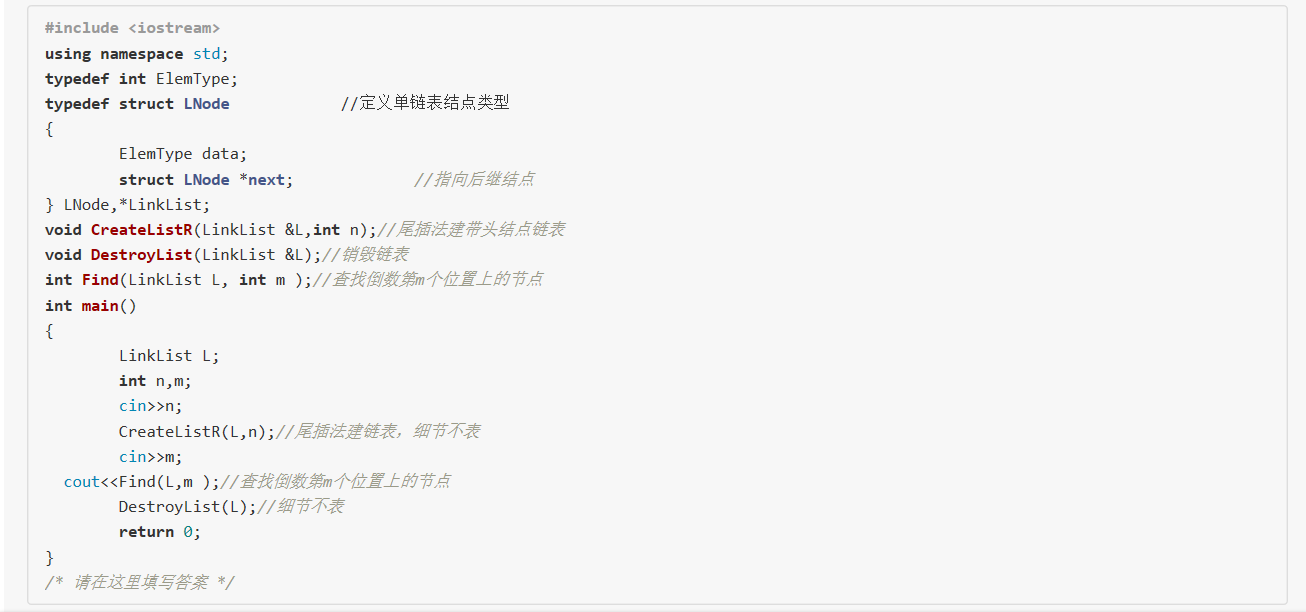
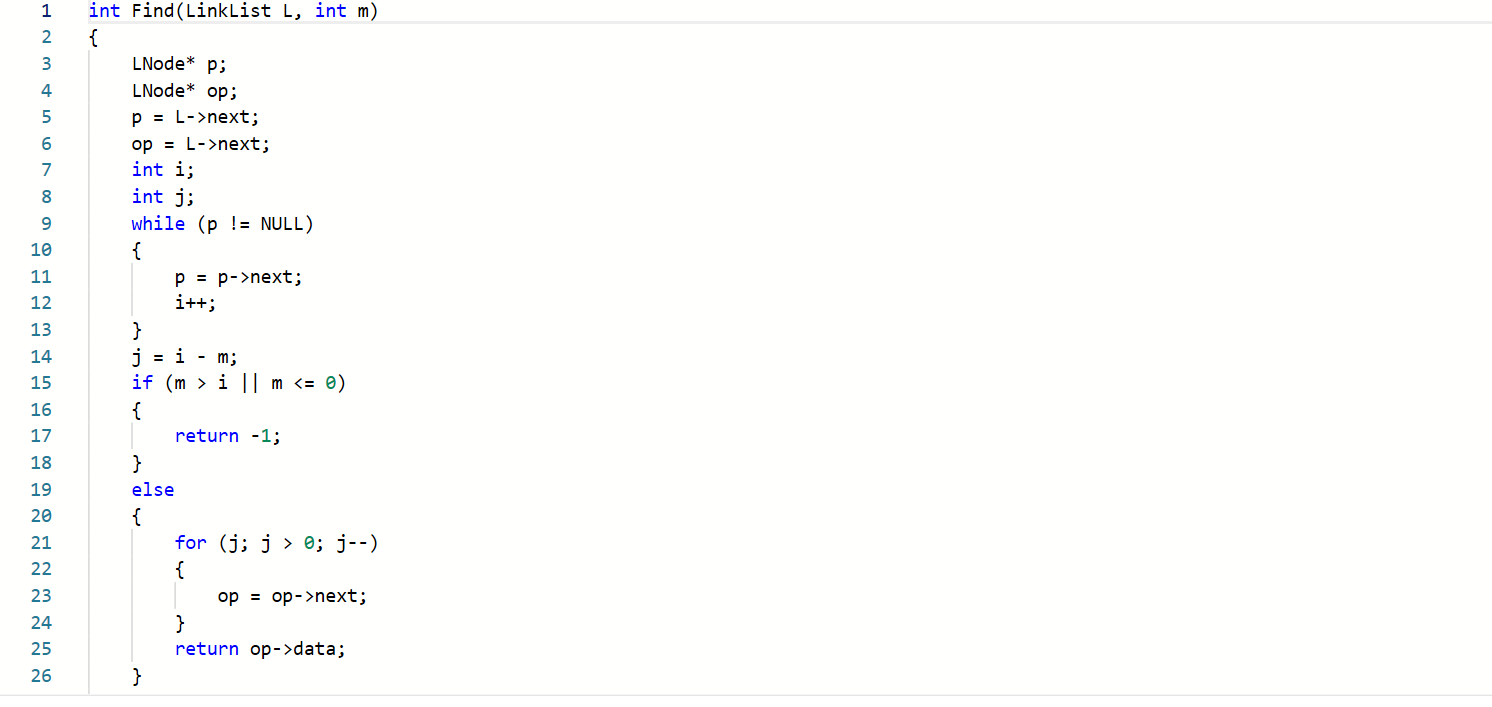
提交列表

·在位置无效的一个测试点过不了
解决:没有考虑到无效的位置可能是负数的可能性,只考虑到会不会超过数据个数
·指针的位置没有控制好,循环到野指针去了
解决:控制一下循环,如果遇到p->next==NULL就停止
有序链表合并

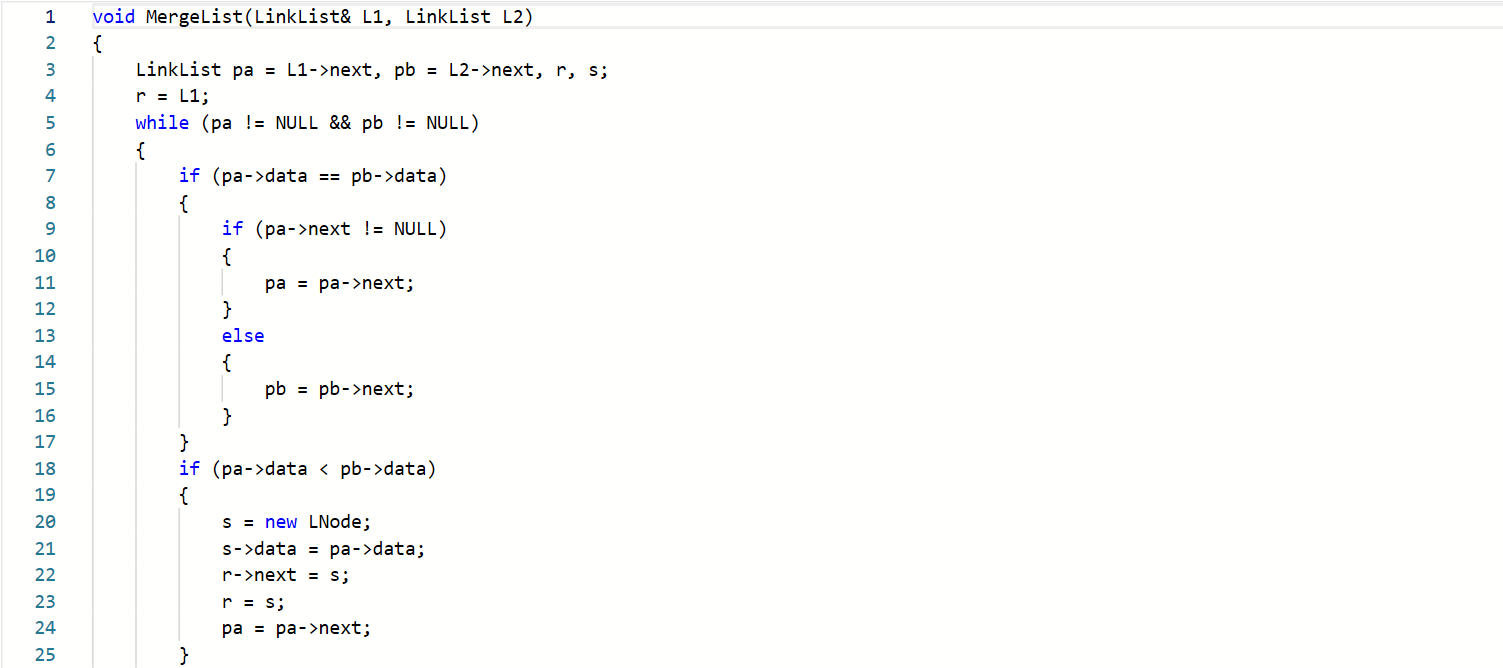


阅读代码
环形链表


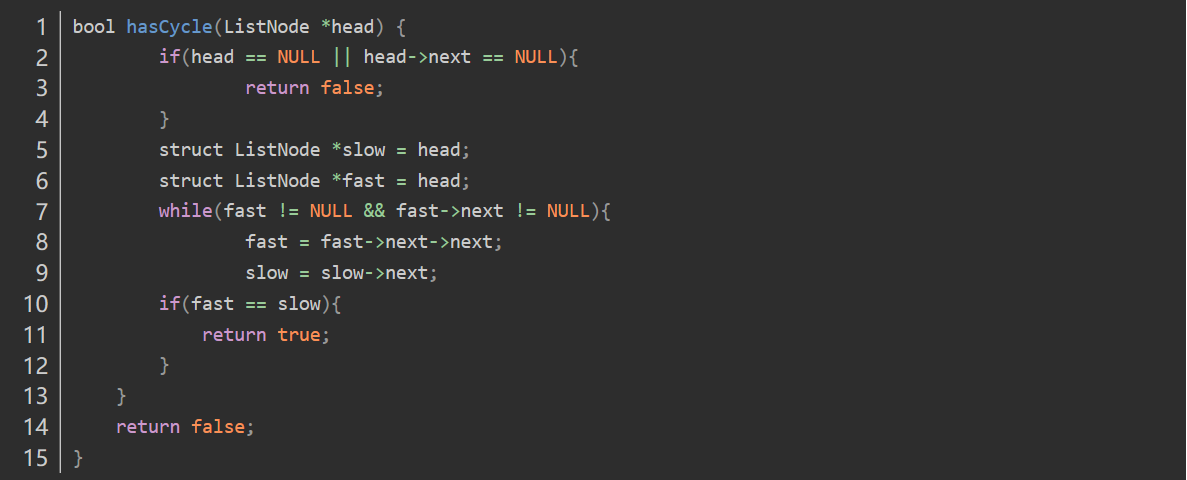
代码设计思路
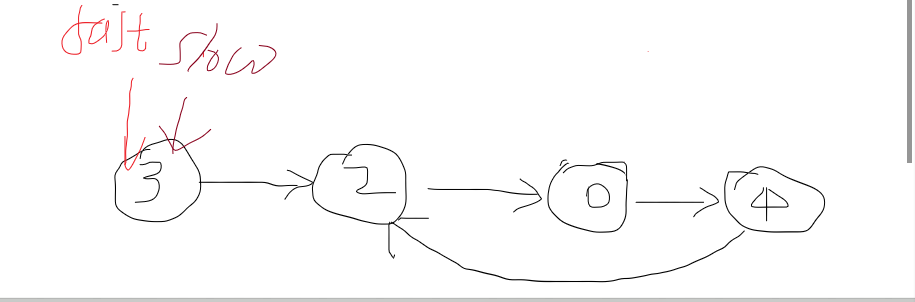
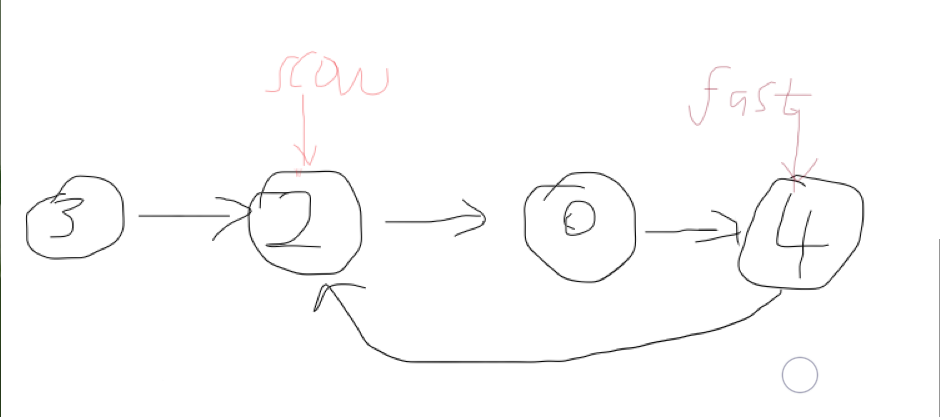
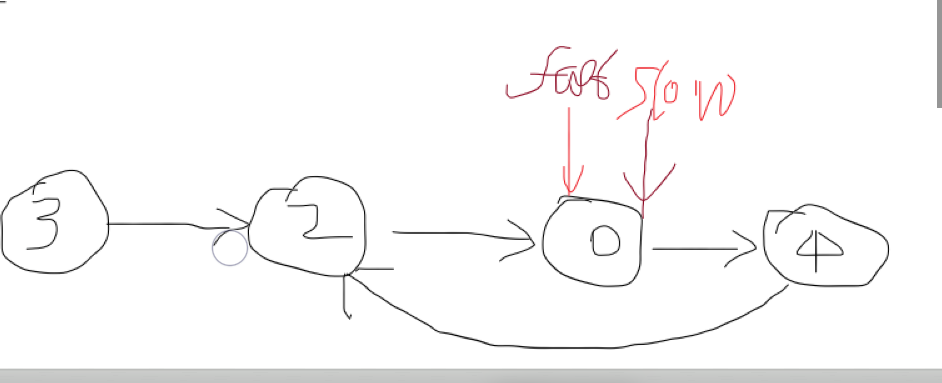
*****
时间复杂度:O(n)
空间复杂度:O(1)
*****
该题的伪代码
if 为空表 then
返回false
else
while (fast不为空且fast的下一结点亦不为空)
then
fast向前移动两个结点
slow向前移动一个结点
if( faster和slower相遇 )
then
返回true
end if
返回false