唯一索引额外功能
为了便于说明,我们创建一个简单的表t,如下:

我在这个表的字段a上创建了唯一索引,字段b上面没有索引,表里初始化两行数据,分别是(1, 1)和(2, 1)。假设我现在要执行一个新的插入语句:

就会报错:

如果我现在要给字段b上加上一个唯一索引,可以这么执行:

同样会报错:

也就是说,MySQL的唯一索引,同时起到了唯一约束的作用,这个作用体现在两个方面:
1. 在有唯一索引的字段,不能插入跟已经存在的数据重复的行;
2. 在有重复行的字段上,不能创建唯一索引。
这个还是比较好理解的,然后你就会对这篇文章的标题表示疑问:既然是约束,那大不了在创建唯一索引的时候就失败好了,怎么会导致丢数据呢?
这个问题要从加索引的代价说起。
加索引的代价
在MySQL的老版本里,由于加索引和加字段是会锁表的,这个期间表上不能更新,因此不能直接在业务库上操作。不过从5.6版本开始,MySQL已经支持了online DDL特性,也就是在加索引和加字段的过程中,这个表是可以正常读写的。
虽然不会影响读写业务,但是在大表是加索引还存在另一个问题,就是会导致主备延迟。如果一个加索引命令在主库上执行30分钟,那么这个命令传到从库,也要执行30分钟。这样就会导致从库有30分钟的延迟。
如果是用的MySQL5.6及之后的版本,并且操作的是小表,比如加索引的执行时间不超过5分钟,由于不会导致明显的延迟,是可以直接在线执行的。当然我还是会建议你在低峰期执行这个操作。
pt-ost加索引
那你会问了,如果是大表加索引,怎么解决这个延迟的问题呢?这时候就要介绍到在线加字段的工具了,比如percona的工具pt-ost,这里的ost就是onlineschema change的简称。(其实更常用的还有gh-ost,今天我们先不展开)
先介绍一下 pt-ost的流程,假设我要给前面的表t的字段b上加一个唯一索引,执行流程是这样的:
1. 创建一个临时表,记为 t’,t’跟t的表结构一样,只是在字段b上多了一个唯一索引;这时候t’是一个空表,因此字段b上的唯一索引是肯定可以创建成功的;
2. 从表t中一行行读出数据,写入到t’中,这个过程称为全量阶段;
3. 如果在全量阶段中,表t上有更新数据,会用触发器写入到t’中,这个过程称为增量阶段。
4. 增量阶段完成后,表t和t'交换表名,用户看到的表t就是加完索引的表,然后再把现在的t'表删掉。
这个工具把一个加索引的大操作,改成了几个小操作来执行,可以解决主备延迟的问题。
不过你一定发现了,全量阶段有问题。t’上字段b已经有了唯一索引,在插入第一行数据(1,1)的时候是没问题的,但是插入第二行数据(2,1)的时候,就违反了唯一索引的约束,插入语句会报错。
下图的状态2表示了这个过程。
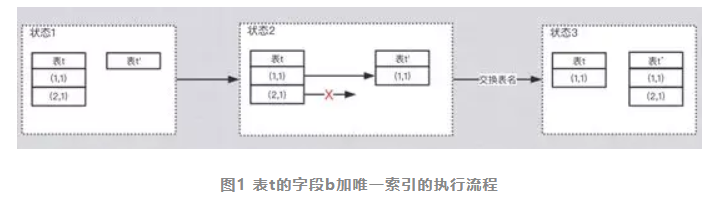
但是,pt工具会忽略这个错误,继续执行后面的流程,这样全量阶段结束后,表t'里就少了一行,交换表名后,用户就会看到,丢了数据。
pt-ost的check-unique-key-change参数
这么严重的一个bug,官方当然还是要处理的,在pt-ost3.0版本里面,增加了一个参数check-unique-key-change。
看这个参数名的字面意思,好像是在加唯一索引之前会判断一下这个操作是否会丢数据。
实际上是不是这样呢?我们来看一个例子。假设我现在在一个空表上用pt-ost工具加一个唯一索引,执行的命令如下:

这个命令的意思是,在test库的lewis表的字段c1上,创建一个唯一索引,这里我省略了连接信息。
虽然现在这个表是空表,但执行这个命令仍然会报错,报错的截图如下:
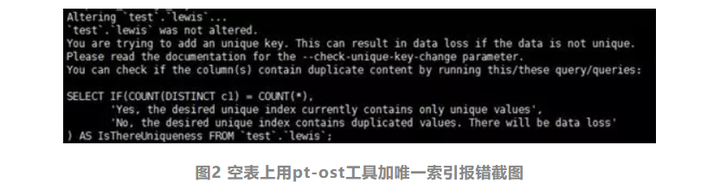
输出的提示里说明,发现你要创建一个唯一索引,所以工具退出。
而如果在上面的命令中增加一个参数 --nocheck-unique-key-change,这个命令就能执行成功。
这时候你一定有些怀疑了,这个参数看来并没有真的去检查数据是否重复?你一定很容易设计一个实验,在test库的lewis表插入两行完全相同的数据,然后执行pt-ost工具,并且带上参数--nocheck-unique-key-change。这时候命令能够成功执行,并且丢了一行数据。
有了上面这三个对照实验,你现在知道了这个参数的设计逻辑:pt-ost工具知道它在创建唯一索引的时候,可能会导致数据丢失。因此默情况下,只要发现你要用这个工具来创建唯一索引,就直接报错返回。
而使用这个功能的正确姿势如下:
1. 首先你要先确保要加唯一索引的字段上没有重复值。这个判断逻辑,工具并不会帮你做,但是在提示中给了方法,就是用count(distinct(c1))的值来判断。
a. 如果值等于表的行数,表示没有重复值;
b. 如果值小于表的行数,表示有重复值;
2. 有重复值你就不要创建唯一索引了;
3. 如果确认没有重复值,就明确带上--nocheck-unique-key-change这个参数,来执行创建唯一索引的命令。
这个命令在判断是否创建唯一索引的时候,实现的逻辑上还有一个bug,我们会用另外一篇文章来说明。
小结
接下来,我们来总结一下今天的主要内容:
1. MySQL的InnoDB表加普通索引和唯一索引的时候,支持在线加索引,不会阻塞线上的读写操作;
2. 如果表不大,可以在几分钟之内执行完成加索引操作,可以在低峰期直接加,效果更快;
3. 直接在表上加唯一索引是没有风险的,如果字段上存在重复值,加索引语句会报错;
4. 如果要用pt-ost工具加唯一索引,要主动先确认要加唯一索引的字段上没有重复值,否则可能会导致丢数据。