首先初始化表和数据
1 create table t_student( 2 Id INT, 3 Name varchar(100), 4 Score int, 5 ClassId INT 6 ); 7 8 insert into t_student values (1,'A',75,1); 9 insert into t_student values (2,'B',78,2); 10 insert into t_student values (3,'C',74,1); 11 insert into t_student values (4,'D',85,2); 12 insert into t_student values (5,'E',80,1); 13 insert into t_student values (6,'F',82,2); 14 insert into t_student values (7,'G',98,1); 15 insert into t_student values (8,'H',90,2); 16 insert into t_student values (9,'I',90,2); 17 18 ---班级表 19 CREATE TABLE t_class( 20 Id int, 21 Name nvarchar(100) 22 ); 23 24 insert into t_class values (1,'一班'); 25 insert into t_class values (2,'二班'); 26
一:首先我们先举个例子来认识一下over的庐山真面目
现在我们的需求是查询出来两个班级的前三名可以通过以下:
之前我的想法是根据分数排序然后取三条,后面发现如果分数一致的话,比如有3个人并列第一名,则这样的写法就完全不满足需求,所以我们可以通过over开窗函数来实现上面的要求
SELECT * FROM ( SELECT Name ,Score ,ClassId ,RANK() OVER ( PARTITION BY classid ORDER BY score DESC ) ScoreRank FROM t_student) AS s WHERE s.ScoreRank < 4;
得到的结果如下:

注意:
1:sqlserver中的From (字表)的时候一定要As,否则报语法错误
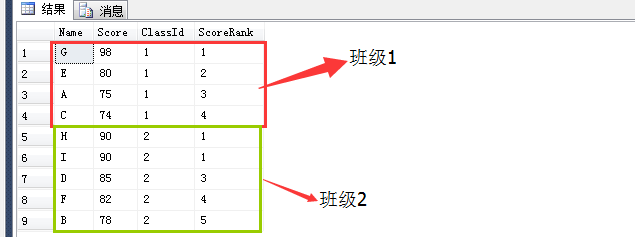
2:RANK() 这个指的是为每一组的行生成一个序号,与ROW_NUMBER()不同的是如果按照ORDER BY的排序,如果有相同的值会生成相同的序号,并且接下来的序号是不连序的。例如两个相同的行生成序号3,那么接下来会生成序号5。
3:Rank() Over(PARTITION BY classid ORDER BY score DESC )是指的先根据classid分组,然后再根据score分数倒叙排列,则是指的分组后生成Rank的序列化号
单单执行 SELECT Name ,Score ,ClassId ,RANK() OVER ( PARTITION BY classid ORDER BY score DESC ) ScoreRank FROM t_student会出现下面的结果:
二:Over的一些语法与用法
语法结构:OVER( [ PARTITION BY ... ] [ ORDER BY ... ] )
1 、partition by 字段名字A:子句进行分组,partition by是固定的分组语法;
2、order by 字段名字B:子句进行排序,order by 是固定的排序语法。
比如我们上面的例子就是用到了partition by classid 和 order by score这样的用法了,注意:如果联合使用指的意思是:先分组然后再排序
OVER()函数不能单独使用,必须跟在 排名函数( ROW_NUMBER、DENSE_RANK、RANK、NTILE) 或 5种聚合函数(SUM、MAX、MIN、AVG、COUNT)后边。
三:排名开窗函数
语法结构:排名函数() OVER ( [ <partition_by字段> ] <order_by字段> )
注意:在排名开窗函数中必须使用ORDER BY语句

下面分别介绍一下各个排名函数的用法和效果
1、ROW_NUMBER():为每一组的行记录按顺序生成一个唯一的行号。这个用的最多的是不连续的Id上下分页,重新生成id,也就是一行会生成一个连续的id值,如下:
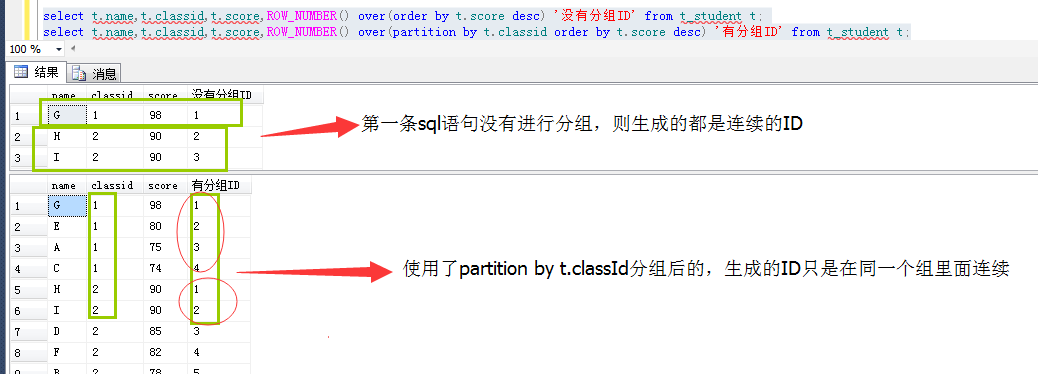
注意:如果是分组,则每个组里面的id是连续的
2、RANK()也为每一组的行生成一个序号,与ROW_NUMBER()不同的是如果按照ORDER BY的排序,如果有相同的值会生成相同的序号,并且接下来的序号是不连序的。例如两个相同的行生成序号3,那么接下来会生成序号5。
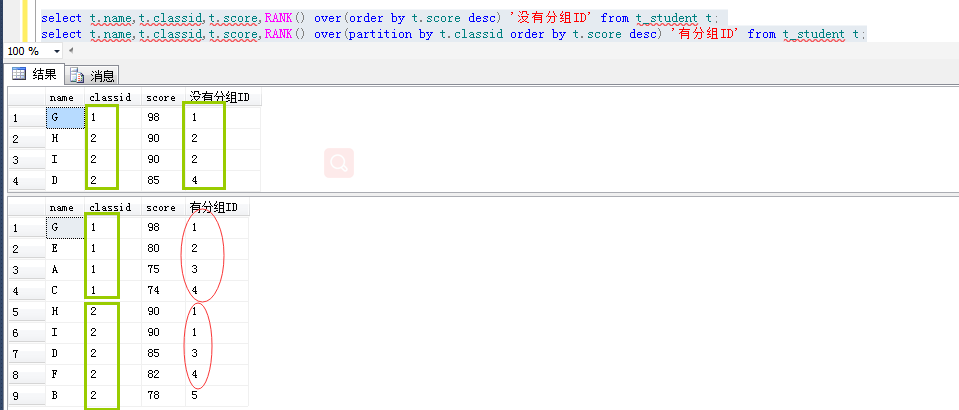
3、DENSE_RANK()和RANK()类似,不同的是如果有相同的序号,那么接下来的序号不会间断。也就是说如果两个相同的行生成序号3,那么接下来生成的序号还是4。

4、NTILE (integer_expression) 按照指定的数目将数据进行分组,并为每一组生成一个序号。

四:聚合开窗函数
语法结构:聚合函数( ) OVER ( [ partition by 字段] [order by 字段]) ,其中【partition by 字段】和【order by 字段】是可选择的
1:Max聚合函数

2:sum聚合函数

3:count聚合函数
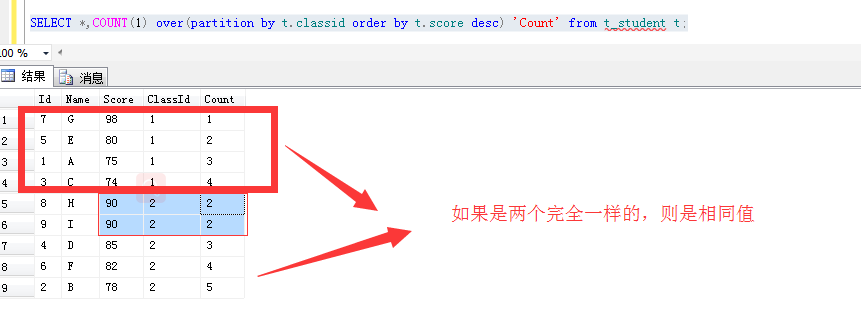
下面的min和avg都是类似,暂时不举例了!
另外开窗函数和聚合函数的不同之处是:开窗函数对于每个组返回多行,而聚合函数对于每个组只返回一行