一、程序测试
(1)用一个try-except 语句来测试我上篇博客中对篮球比赛的预测
什么是try-except 语句?
try-except 语句(以及其更复杂的形式)定义了进行异常监控的一段代码, 并且提供了处理异常的机制.
最常见的 try-except 语句语法如下所示,它由try块和except块 (try_suite 和 except_suite )组成, 也可以有一个可选的错误原因。首先尝试执行 try 子句, 如果没有错误, 忽略所有的 except 从句继续执行,如果发生异常, 解释器将在这一串处理器(except 子句)中查找匹配的异常。
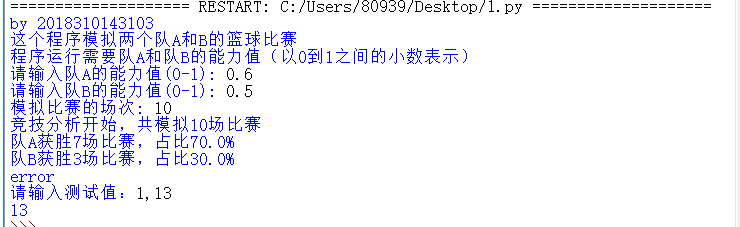
def gameover(a,b): if a>=11 and (a-b)>=2: print(a) if b>=11 and (b-a)>=2: print(b) try: gameover() except: print("error") a,b=eval(input("请输入测试值:")) gameover(a,b)
测试图如下:
二.requests库的运用
1.爬虫的基本框架是获取HTML页面信息,解析页面信息,保存结果,requests模块是用于第一步获取HTML页面信息; requests库用于爬取HTML页面,提交网络请求,基于urllib,但比urllib更方便。
2.安装requests库
打开命令行,输入
pip install requests
即可安装
3.下面介绍一些requests库的基本用法
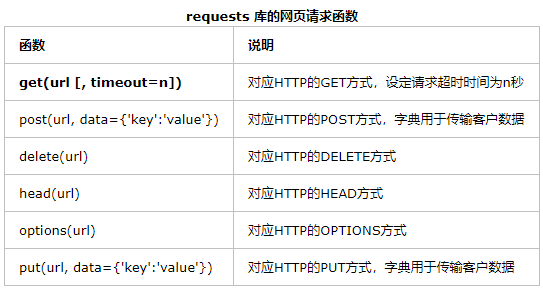
get方法,它能够获得url的请求,并返回一个response对象作为响应。
常见的HTTP状态码:200 - 请求成功,301 - 资源(网页等)被永久转移到其它URL,404 - 请求的资源(网页等)不存在,500 - 内部服务器错误。

3.牛刀小试
1.用request库爬取百度网页内容,并且打印20次
代码实现如下
1 import requests 2 def gethtmltext(url): 3 try: 4 r=requests.get(url,timeout=30) 5 r.raise_for_status() 6 r.encoding='utf-8' 7 return r.text 8 except: 9 return "" 10 11 url="https://www.so.com" 12 for i in range(20): 13 print(gethtmltext(url))
结果如图所示
4.实例
我们现在用requests库访问360搜索主页20次,并获取一些信息
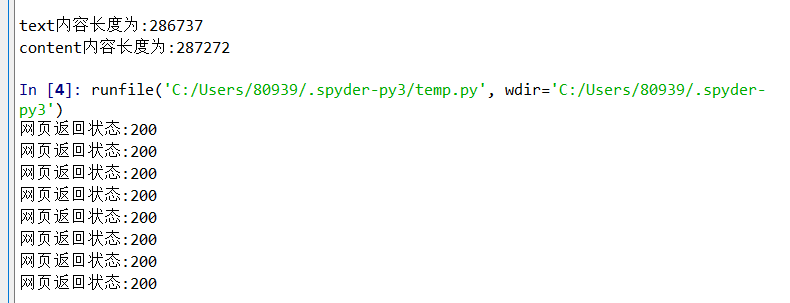
import requests for i in range(20): r = requests.get("https://www.so.com")#360搜索主页 print("网页返回状态:{}".format(r.status_code)) print("text内容为:{}".format(r.text)) print(" ") print("text内容长度为:{}".format(len(r.text))) print("content内容长度为:{}".format(len(r.content)))
结果如图所示:
四、