1、什么是scrapyd
Scrapyd是一个服务,用来运行scrapy爬虫的。
它允许你部署你的scrapy项目以及通过HTTP JSON的方式控制你的爬虫。
官方文档:http://scrapyd.readthedocs.org/
2、安装scrapyd和scrapyd-client
pip install scrapyd(服务器)
pip install scrapyd-client(客户端)
安装完成后,在python安装目录的Scripts的文件下有一个scrapyd.exe,在命令行窗口执行后,可以通过访问http://127.0.0.1:6800,进入
一个很简单的页面,
执行scrapyd这个命令行,表示服务开启了,

在浏览器中访问这个服务,
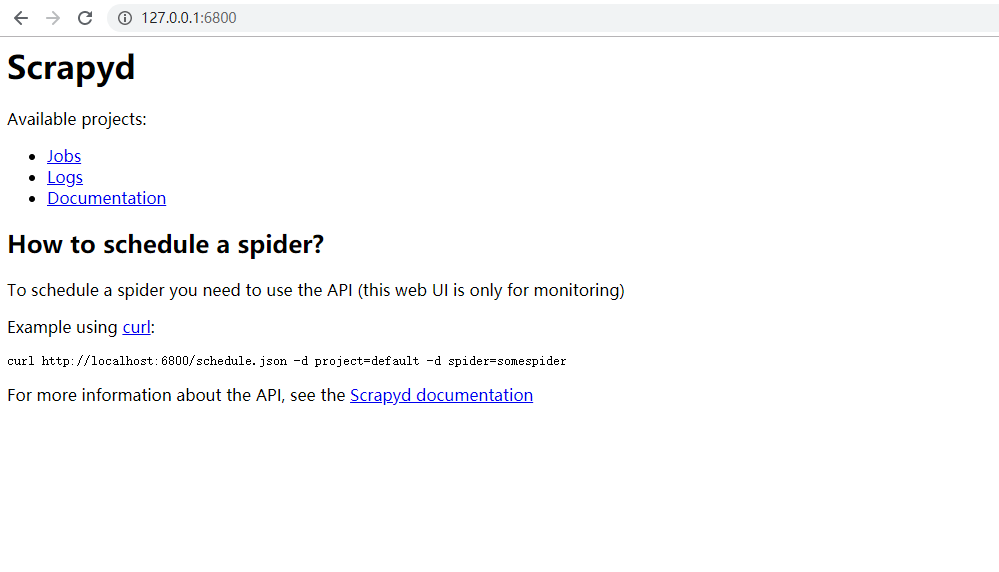
上面表示服务端安装成功,现在来安装测试客户端,安装好后,执行scrapyd-deploy来测试是否安装成功,

执行失败,我们来看一下Python的Scripts下面是否有一个scrapyd-client.exe命令,
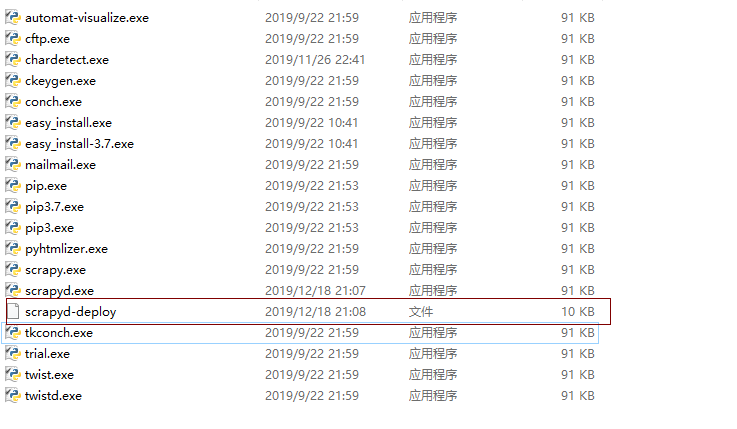
从图片中看到里面有一个scrapyd-deploy文件,但不是可执行文件,打开后发现这个文件是一个包含Python代码的文件,所以要是让它
执行,要不用Python解释器来执行这个文件,要不就是把它编译为可执行文件两种方式。
第一种方式:
在这个文件夹里创建scrapyd-deploy.bat文件,并在里面输入:
@echo off C:Users18065AppDataLocalProgramsPythonPython37-32python.exe C:Users18065AppDataLocalProgramsPythonPython37-32Scriptsscrapyd-deploy %*
第二行第一个路径是python解释器的绝对路径,第二路径是scrapyd-deploy文件的绝对路径,然后再来执行scrapyd-deploy命令

这样就表明安装成功了
第二种方式:
用可以将python源文件编译为scrapyd-deploy.exe可执行程序的模块pyinstaller
3、上传爬虫项目
在上传之前必须修改一下配置文件,将scrapy.cfg中的url注释掉
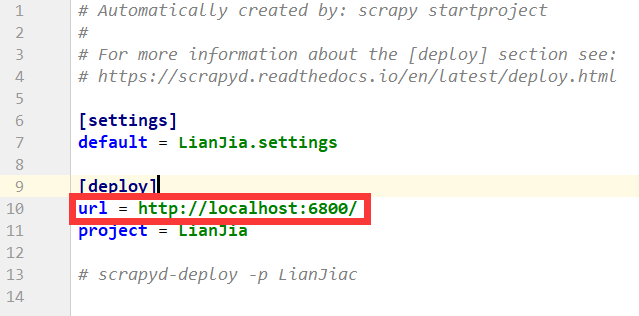
注释掉后,就可以开始正式上传了,上传时必须要在爬虫项目文件中,
执行

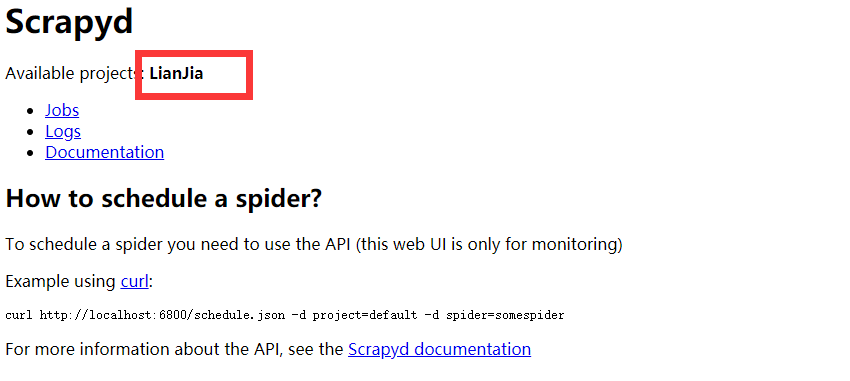
4、运行爬虫项目
上传过后就可以在命令行窗口开始启动爬虫了
启动命令:
启动后,就可以看到在开启服务的那个命令行窗口不断出现scrapy项目运行时的数据,在http://127.0.0.1:6800/jobs页面显示
爬虫运行信息,在http://127.0.0.1:6800/logs/页面显示运行日志
5、关闭爬虫项目
关闭命令: