Python urlparse模块
urlparse 模块简介
urlparse模块用于把url解析为各个组件,支持file,ftp,http,https,imap,mailto,mms,news,nntp,prospero,rtsp,sftp,shttp,sip,svn+ssh,telnet等几乎所有的形式,在Python3中,该模块放置在urllib.parse中了。
函数说明
1.urlparse()函数
>>> from urllib.parse import urlparse
>>> urls = urlparse('https://www.cnblogs.com/fuhj02/archive/2010/12/07/1898557.html')
>>> urls
ParseResult(scheme='https', netloc='www.cnblogs.com', path='/fuhj02/archive/2010/12/07/1898557.html', params='', query='', fragment='')
>>> dir(urls)
['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__module__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmul__', '__setattr__', '__sizeof__', '__slots__', '__str__', '__subclasshook__', '_asdict', '_encoded_counterpart', '_fields', '_hostinfo', '_make', '_replace', '_source', '_userinfo', 'count', 'encode', 'fragment', 'geturl', 'hostname', 'index', 'netloc', 'params', 'password', 'path', 'port', 'query', 'scheme', 'username']
>>> urls.hostname
'www.cnblogs.com'
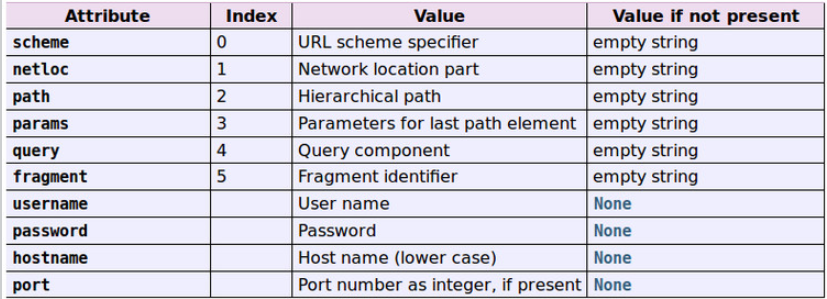
该函数将一个url字符串分解为6个元素,以元组的形式返回。这与URL的一般结构相关:scheme://netloc//path;parameters?query#fragment解析得到的每个元素都是一个字符串,有的元素可能为空,除了返回这6个元素外,返回的对象还包含了一些属性:username、password、hostname、port等,我们可以通过Python的内置函数dir()来查看其具有的属性和方法。
注意:若要得到正确的nerloc值,url必须以//开头,否则会被归到path值里去。例如:
>>> another = urlparse('www.cnblogs.com/fuhj02/archive/2010/12/07/1898557.html')
>>> another
ParseResult(scheme='', netloc='', path='www.cnblogs.com/fuhj02/archive/2010/12/07/1898557.html', params='', query='', fragment='')
其实,返回的结果是tuple子类的一个实例,该类具有如下的只读属性:
2.urlunparse()函数
>>> from urllib.parse import urlunparse
>>> urlunparse(urls)
'https://www.cnblogs.com/fuhj02/archive/2010/12/07/1898557.html'
该函数作用是把urlparse()分解的元素再拼合还原为一个url,该函数的参数可以是任意的六元组。
3.urlsplit()函数
>>> from urllib.parse import urlsplit
>>> urlsplit('https://www.cnblogs.com/fuhj02/archive/2010/12/07/1898557.html')
SplitResult(scheme='https', netloc='www.cnblogs.com', path='/fuhj02/archive/2010/12/07/1898557.html', query='', fragment='')
该函数与urlparse()类似,不过返回的是一个5元素的元组,不包括params。
4.urlunsplit()函数,此函数是将urlsplit函数分解的元素再组合起来。
5.urljoin()函数
>>> from urllib.parse import urljoin
>>> urljoin('http://www.baidu.com', 'wenku.faq.html')
'http://www.baidu.com/wenku.faq.html'
该函数基于一个base url和另外一个url构造一个绝对url,如上所示。注意:如果参数中的url为绝对路径的URL(即以//或scheme://开始),那么url的hostname和scheme将会出现在结果中,如下所示:
>>> urljoin('https://www.baidu.com/', 'https://blog.csdn.net/timeless_go/article/details/78489716')
'https://blog.csdn.net/timeless_go/article/details/78489716'
>>> urljoin('http://wiki.huihoo.com/wiki/', 'OpenERP#.E5.AE.89.E8.A3.85')
'http://wiki.huihoo.com/wiki/OpenERP#.E5.AE.89.E8.A3.85'
其余方法不再挨着介绍,直接查看源代码即可。