在机器学习算法中,为了优化损失函数loss function ,我们往往采用梯度下降算法来进行优化。举个例子:
线性SVM的得分函数和损失函数分别为:

一般来说,我们是需要求损失函数的最小值,而损失函数是关于权值矩阵的函数。为了求解权值矩阵,我们一般采用数值求解的方法,但是为什么是梯度呢?
在CS231N课程中给出了解释,首先我们采用
策略1:随机搜寻(不太实用),也就是在一个范围内,任意选择W的值带入到损失函数中,那个损失函数值最小就取谁,这个很不实用。
策略2:随机局部搜索 ,就是在W值的附近,指定一个小方向,沿着这个小方向改变W,将改变方向后的W带入损失函数进行判断。具体步骤是对于一个当前W,我们每次实验和添加δW′,然后看看损失函数是否比当前要低,如果是,就替换掉当前的W。这个方向不明确
策略3 顺着梯度下滑 和策略2对比,实际上上述小方向指定了,也就是说δW′应该等于stepsize*|grad|
然而,为什么是梯度方向呢?上一张图解释:
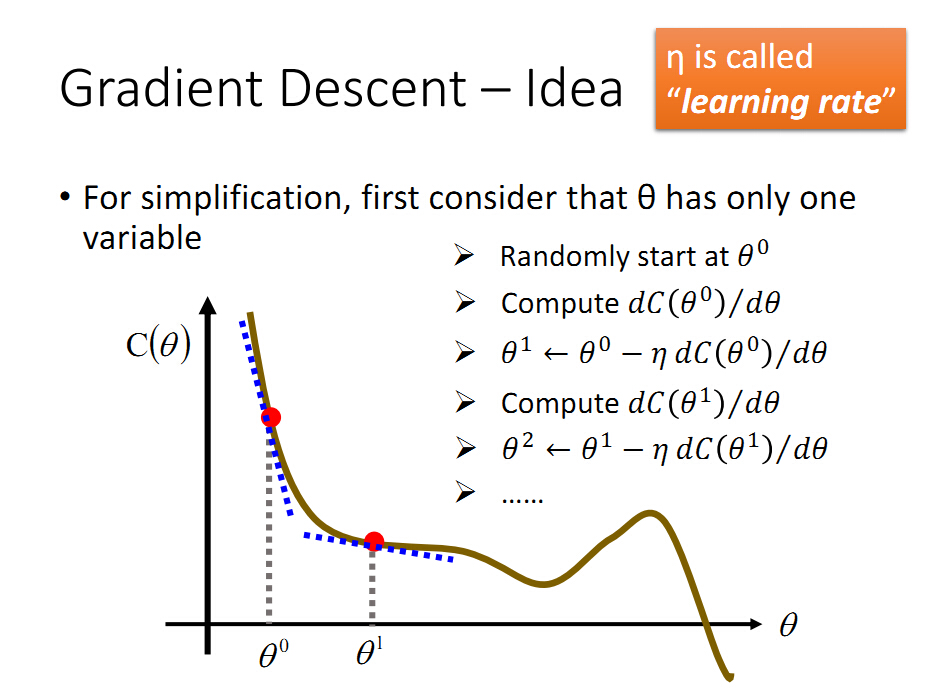
C(θ)是损失函数,θ是权值,为了得到在那个θ下C(θ)最小。一般选取初始点θ0,然后依据上面的搜索策略对θ0进行变更,
但是到底是向前还是向后运动呢?当我们知道图像后,很明显是向前运动,才能使得损失函数变小,但是在我们不知道图像的时候,梯度/导数会告诉我们答案。根据上图可知,在θ0点处的导数,也就是斜率是负的,为了减小损失函数,一般是沿着斜率的负方向运动,也就是
θ1=θ0-ηdc(θ0)/d(θ)
相当于θ1比θ0向正方向运动,也就是向前运动,满足我们的判断。
到此,我们可以看出,梯度下降的方法的步骤就是选择权值一个初始点,然后对权值进行小范围的迭代更新,然而小范围更新的方向为损失函数
对权值选择点的导数负方向,这样就能保证损失函数逐渐取得最小值。
比较三种梯度下降法:批量梯度下降法(Batch Gradient Descent,简称BGD)、随机梯度下降法(Stochastic Gradient Descent,简称SGD)和
小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)
设特征有n+1维度,对应特征向量是X0-XN,系数向量是θ0-θN
每一个特征向量为x(i) ,一共有M个特征向量,或者说M个数据。
BGD:最原始的梯度下降,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:

SGD:由于批量梯度下降法在更新每一个参数时,都需要所有的训练样本,所以训练过程会随着样本数量的加大而变得异常的缓慢。
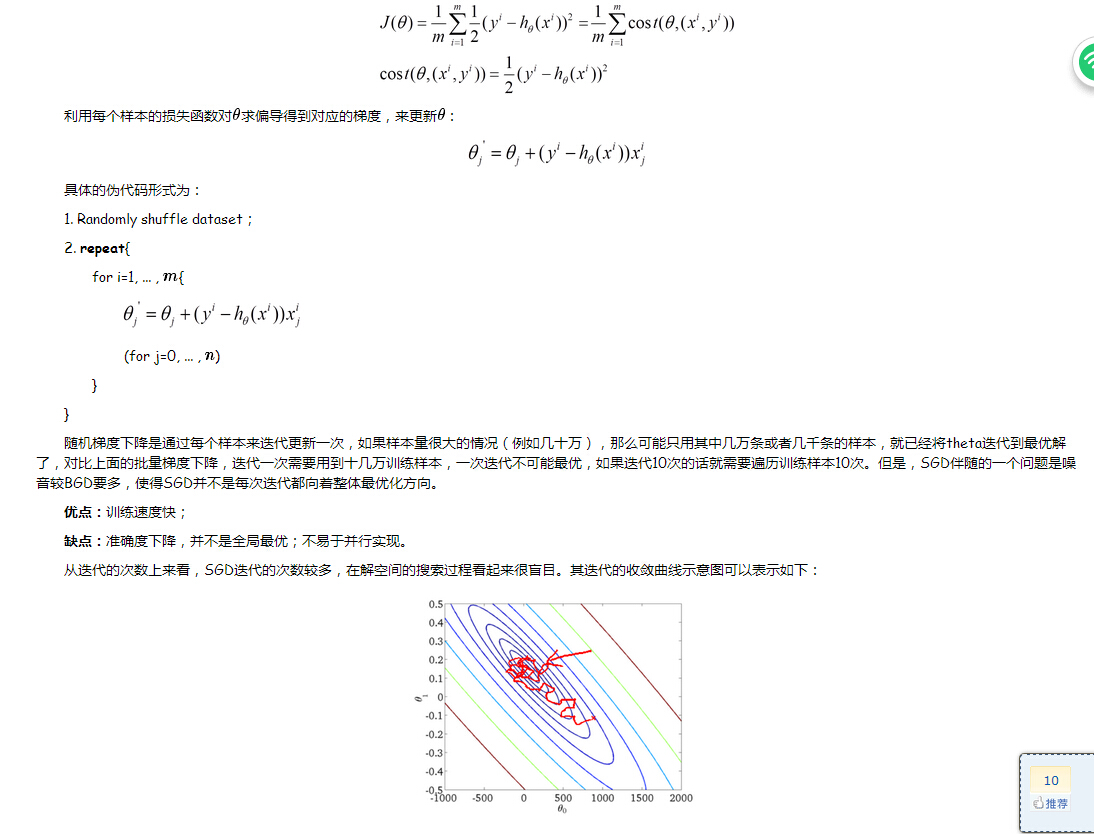
实际上,这个只是把上面的1-M所有的数据求和去掉了,也就是来一个数据更新一次。
MBGD:是一个折中的方案,也就是说M太大了,1太小了,自己定义一个batch值来更新数据,每多少个batch值更新一下权值。

显而易见,只是把上面的M换成了10.