下图是要用到的数据集,反映了从1984到2016年的失业率的变化
1.导入可视化模块import matlibplot.pyplot as plt, 函数plt.plot(x, y)确定折线图的点,x是由这些点的x坐标组成的列表,y是由这些点的y坐标组成
的列表。plt.show()显示图像,plt.xlabel()给x轴命名,plt.xticks()可以设置x坐标刻度点旋转指定角度,plt.title()给折线图命名
下面的代码是以上函数的应用
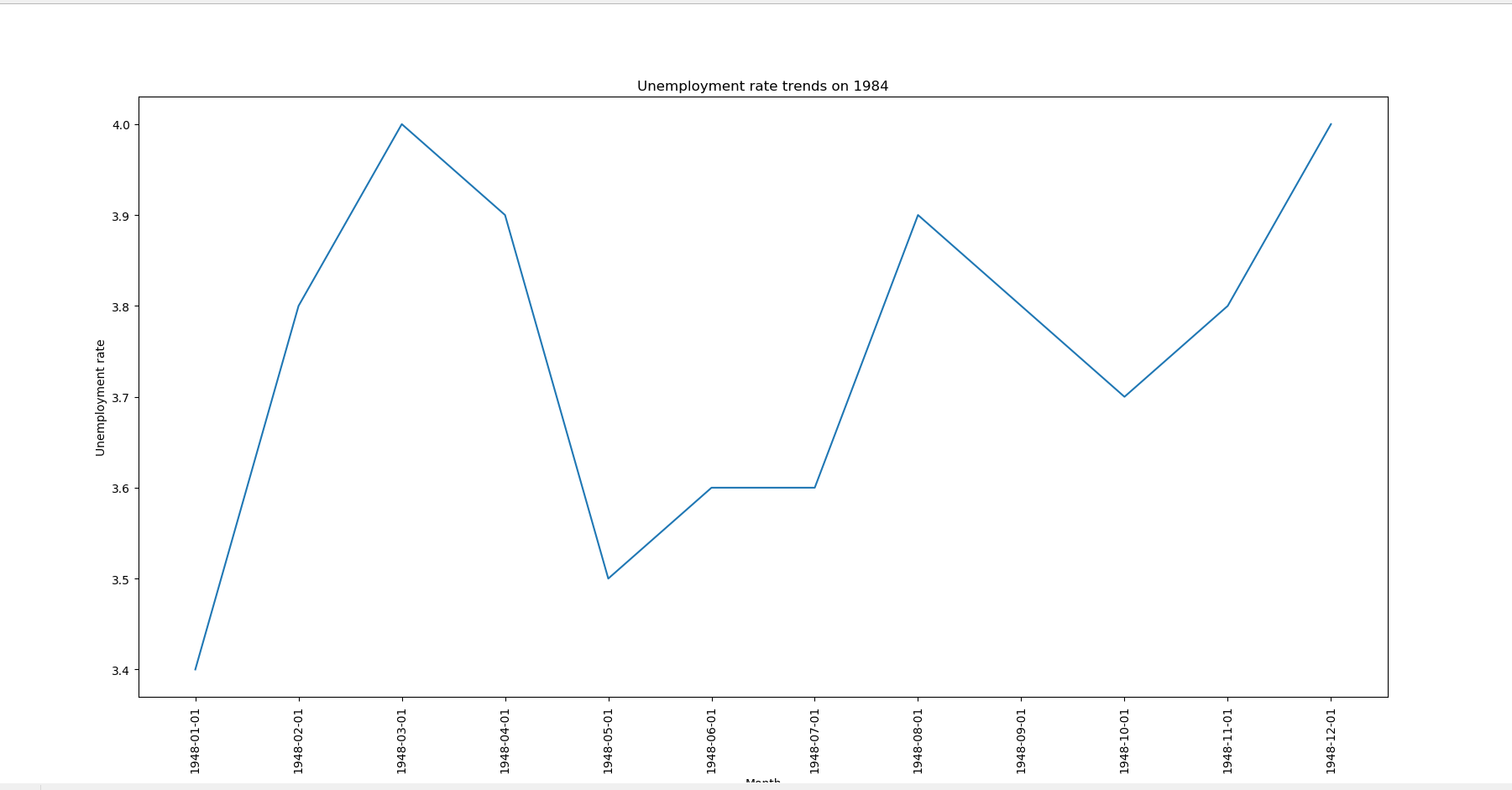
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 #画出1984年失业率折线图 5 unrated = pd.read_csv("C:/学习/python/hello/UNRATE.csv") 6 first_twelve = unrated.head(12) 7 8 x_series = first_twelve["DATE"] 9 y_series = first_twelve["VALUE"] 10 11 plt.xticks(rotation=90) 12 plt.xlabel("Month") 13 plt.ylabel("Unemployment rate") 14 15 plt.title("Unemployment rate trends on 1984") 16 17 plt.plot(x_series, y_series) 18 plt.show()
运行结果如下
2.通过plt.subplot(n, m, x)在一个figure中添加多个子图, n和m表示子图的布局,分别代表行数和列数,x表示从左往右,从上往下数的第x个子图
下面的代码提供了该函数使用实例
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 plt.figure(figsize=(20, 16)) 6 ax1 = plt.subplot(2, 3, 1) 7 ax2 = plt.subplot(2, 3, 2) 8 ax3 = plt.subplot(2, 3, 3) 9 ax5 = plt.subplot(2, 3, 5) 10 plt.show()
运行结果如下
3.下面的代码是在一个坐标轴中画多个折线图的示例
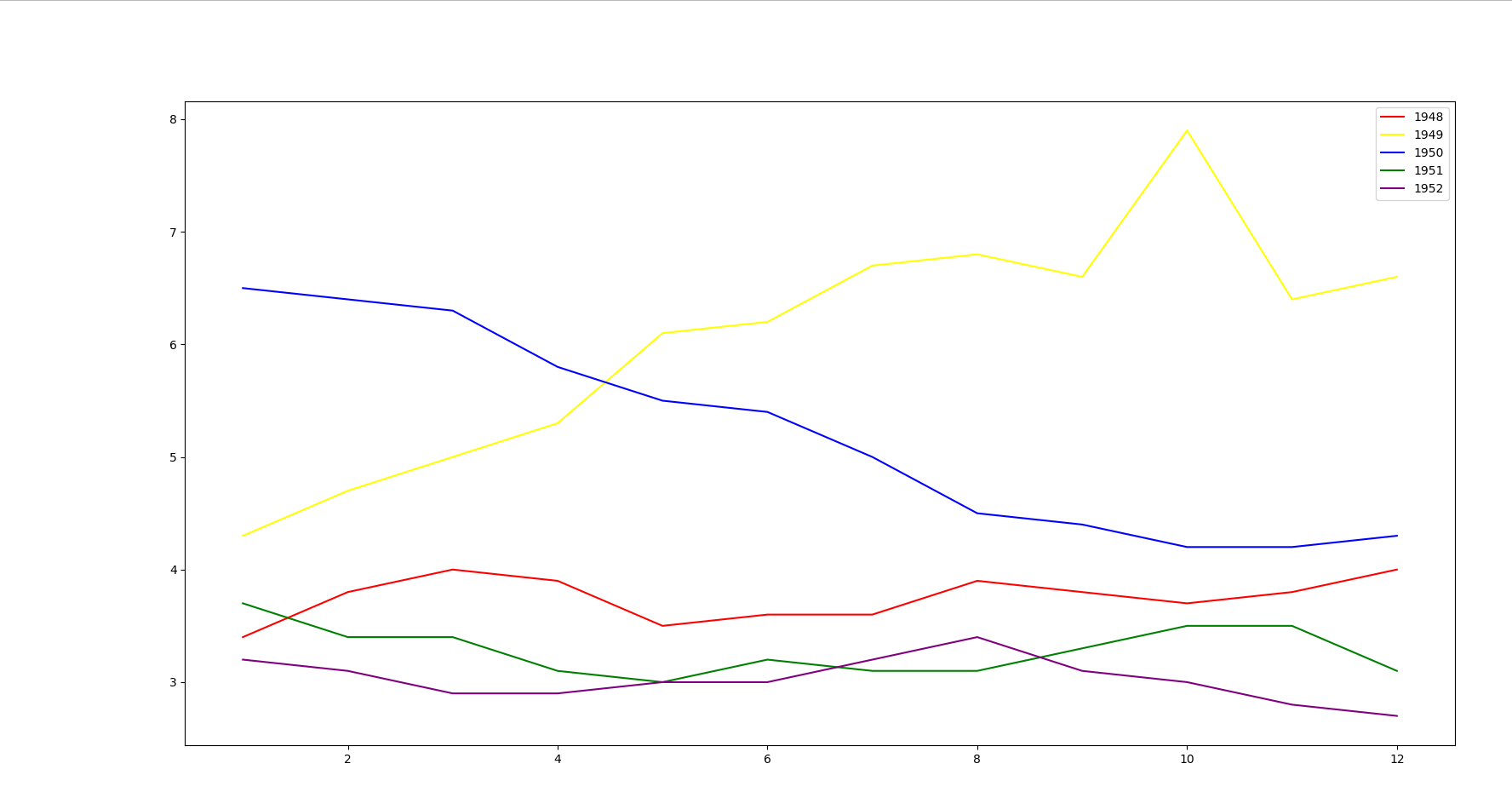
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 unrated = pd.read_csv("C:/学习/python/hello/UNRATE.csv") 6 unrated["DATE"] = pd.to_datetime(unrated["DATE"]) 7 color = ["red", "yellow", "blue", "green", "purple"] 8 plt.figure(figsize=(20, 16)) 9 for i in range(5): 10 sub_unrated = unrated.loc[i*12:(i+1)*12-1] 11 sub_unrated_x = sub_unrated['DATE'].dt.month 12 sub_unrated_y = sub_unrated["VALUE"] 13 label = 1948+i 14 plt.plot(sub_unrated_x, sub_unrated_y, color=color[i], label=label) 15 plt.legend(loc="best") 16 plt.show()
运行结果如下
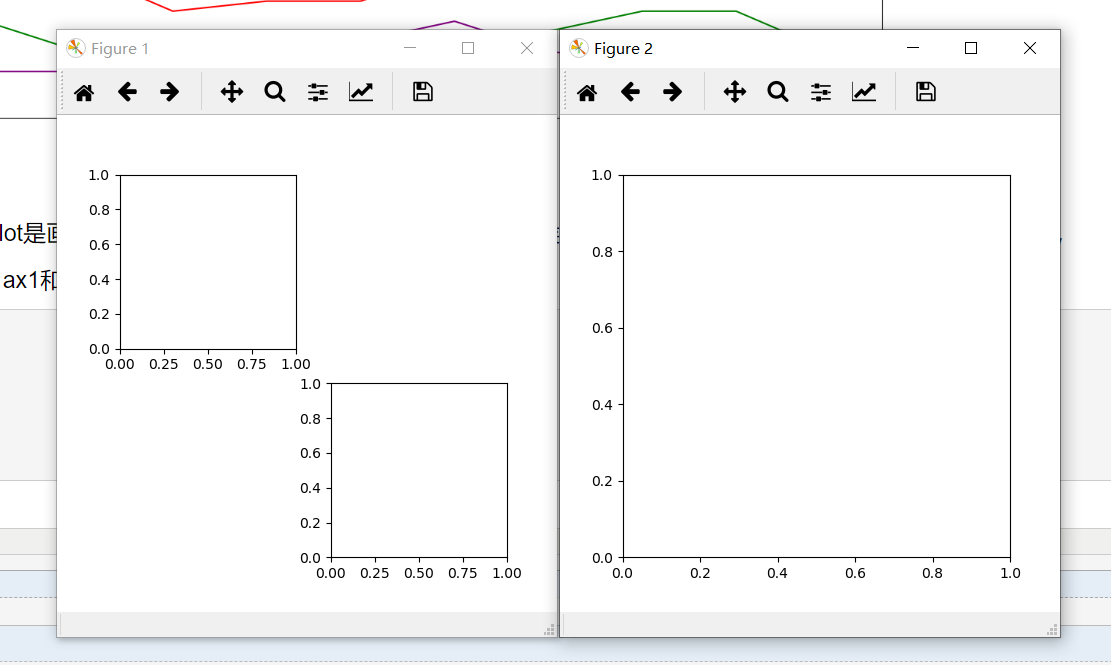
4.figure和subplot的定义顺序决定了subplot是画在哪个figure中。当代码中定义了多个figure时候,紧接着该figure定义的subplot才画在该figure中,
如下代码所示,定义了figure1和figure2,ax1和ax2在figure1中,ax在figure2中。
1 plt.figure(figsize=(20, 16)) 2 ax1 = plt.subplot(2,2,1) 3 plt.figure(figsize=(14, 12)) 4 ax = plt.subplot(1, 1, 1) 5 6 plt.show()
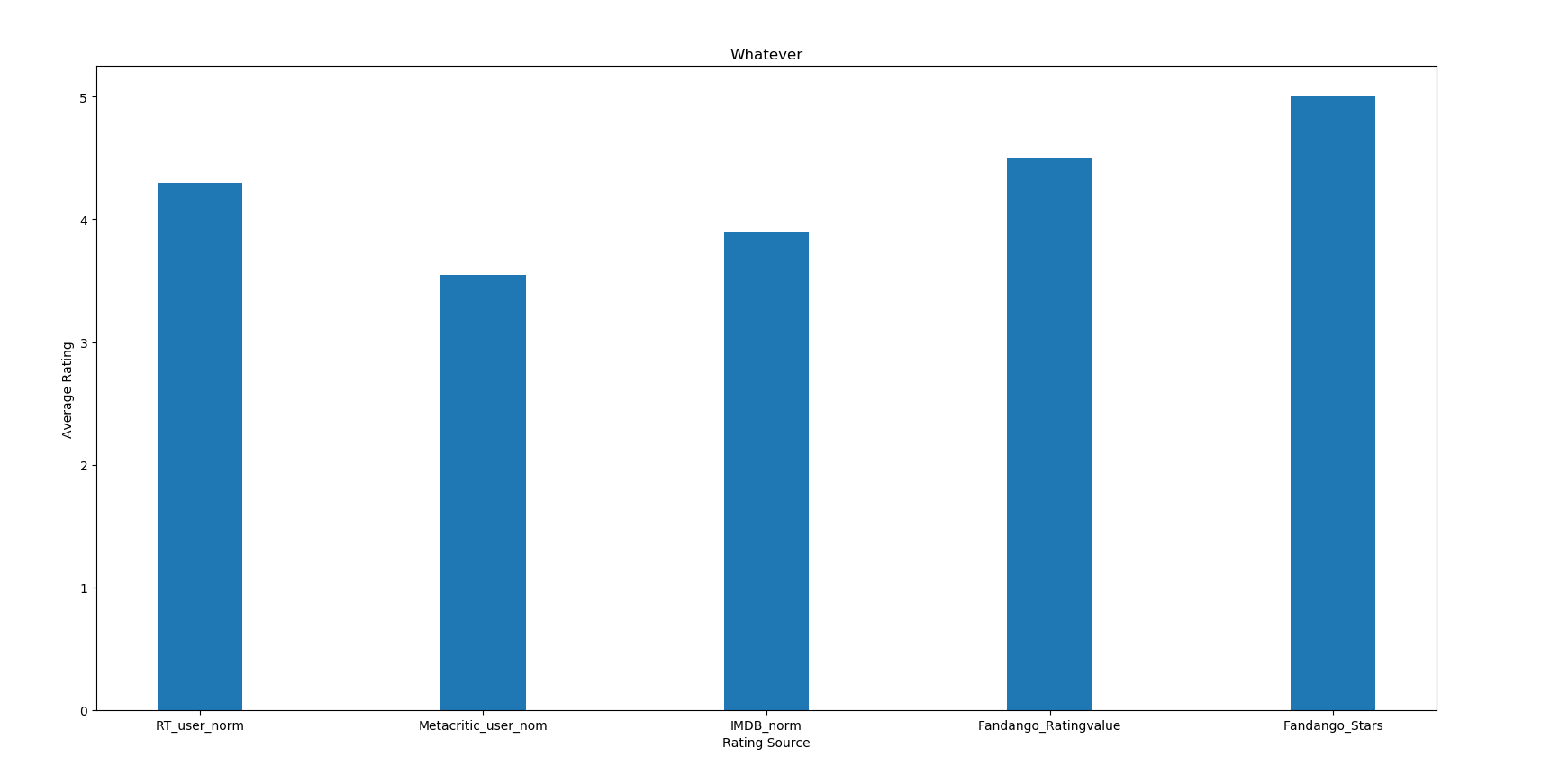
5.用matplotlib画条形图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv")
cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
norm_reviews = reviews[cols]
num_cols = ["RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"]
bar_height = norm_reviews.loc[0, num_cols].values #第一部电影的评价,注意利用loc索引某一行的用法,可以添加第二维
bar_position = 1 + np.arange(5) #arange返回的是ndarray类型,range返回的是list类,使用arange需要用numpy
plt.figure(figsize=(10, 10))
ax = plt.subplot(1, 1, 1)
ax.bar(bar_position, bar_height, 0.3) #bar_position是条形图的x坐标(中点坐标),bar_height是高,0.3是宽
#设置x坐标刻度
tick_positions = range(1, 6)
ax.set_xticks(tick_positions)
ax.set_xticklabels(num_cols)
#设置x轴和y轴名称
ax.set_xlabel("Rating Source")
ax.set_ylabel("Average Rating")
ax.set_title("Whatever")
plt.show()
运行结果如下
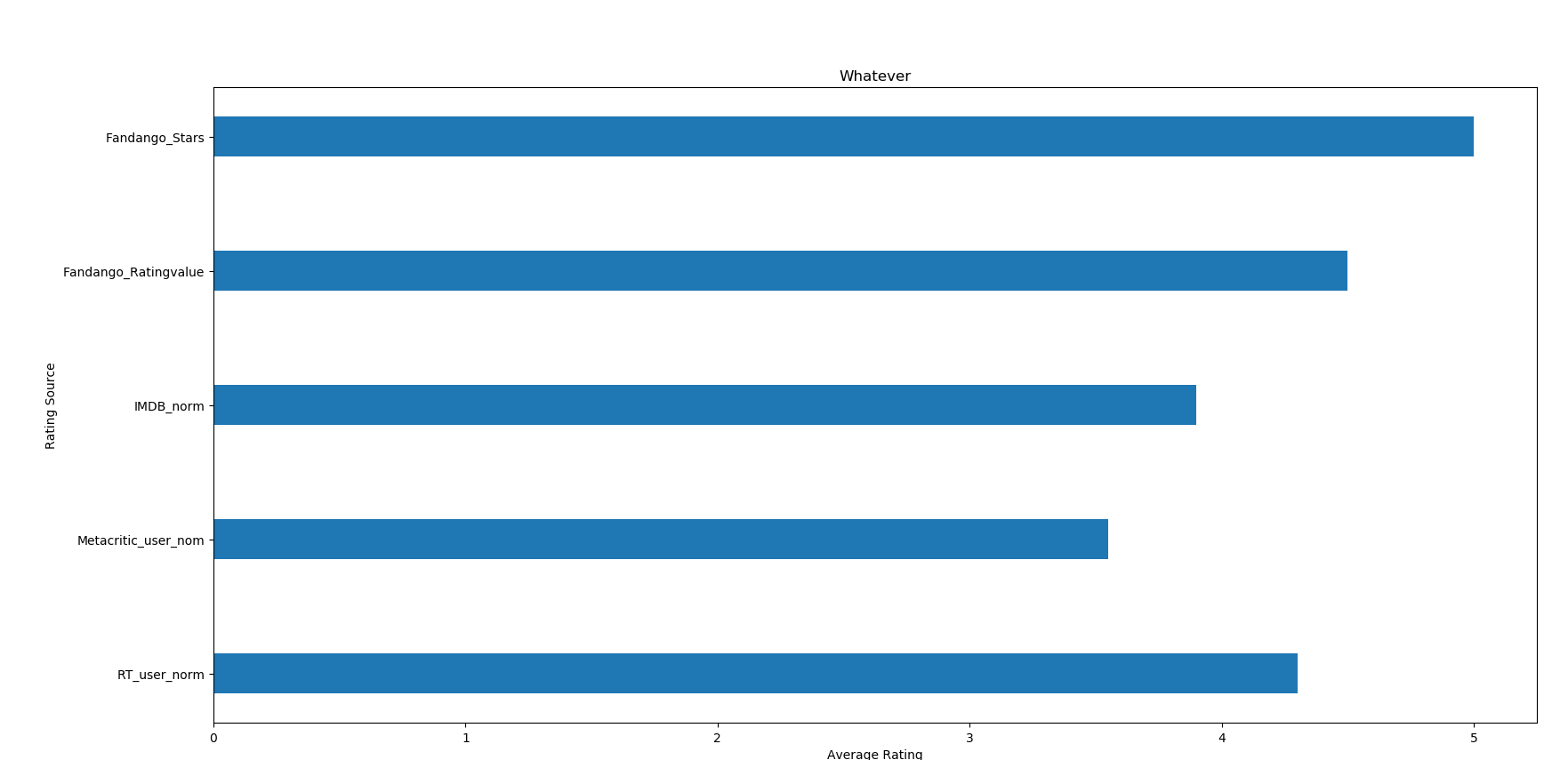
将上面的代码改变几处,就会成为横着的条形图了。代码如下所示(改动之处用白底红字加粗下划线标出来了)
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 6 cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"] 7 norm_reviews = reviews[cols] 8 9 num_cols = ["RT_user_norm", "Metacritic_user_nom", "IMDB_norm", "Fandango_Ratingvalue", "Fandango_Stars"] 10 bar_height = norm_reviews.loc[0, num_cols].values #第一部电影的评价,注意利用loc索引某一行的用法,可以添加第二维 11 12 bar_position = 1 + np.arange(5) #arange返回的是ndarray类型,range返回的是list类,使用arange需要用numpy 13 plt.figure(figsize=(10, 10)) 14 ax = plt.subplot(1, 1, 1) 15 ax.barh(bar_position, bar_height, 0.3) #bar_position是条形图的x坐标(中点坐标),bar_height是高,0.3是宽 16 #设置x坐标刻度 17 tick_positions = range(1, 6) 18 ax.set_yticks(tick_positions) 19 ax.set_yticklabels(num_cols) 20 21 #设置x轴和y轴名称 22 ax.set_ylabel("Rating Source") 23 ax.set_xlabel("Average Rating") 24 ax.set_title("Whatever") 25 plt.show()
运行结果如下
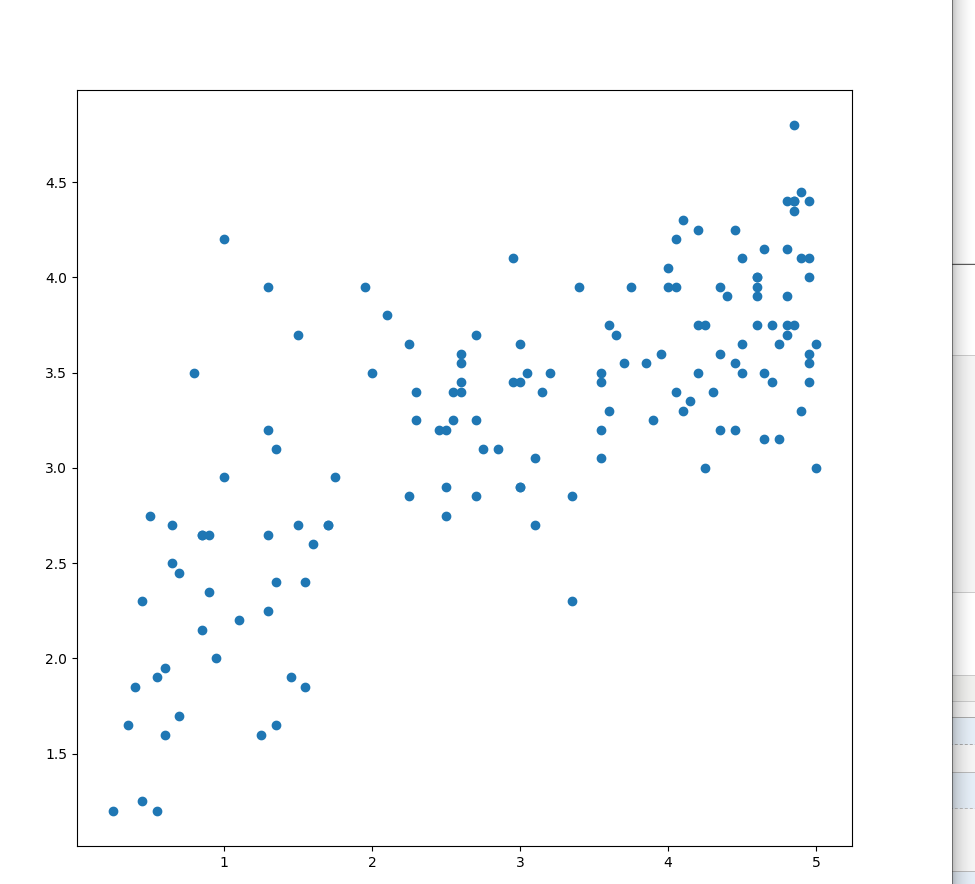
6.画散点图
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 6 plt.figure(figsize=(10,10)) 7 ax = plt.subplot(1, 1, 1) 8 ax.scatter(reviews["RT_norm"], reviews["Metacritic_user_nom"]) 9 plt.show()
运行结果如下
7.设a是Series类型,b = a.value_counts()可以得到a的一个频数统计,b是Series结构,b的index是a的值,b的value是该值出现的频数。
如下代码所示
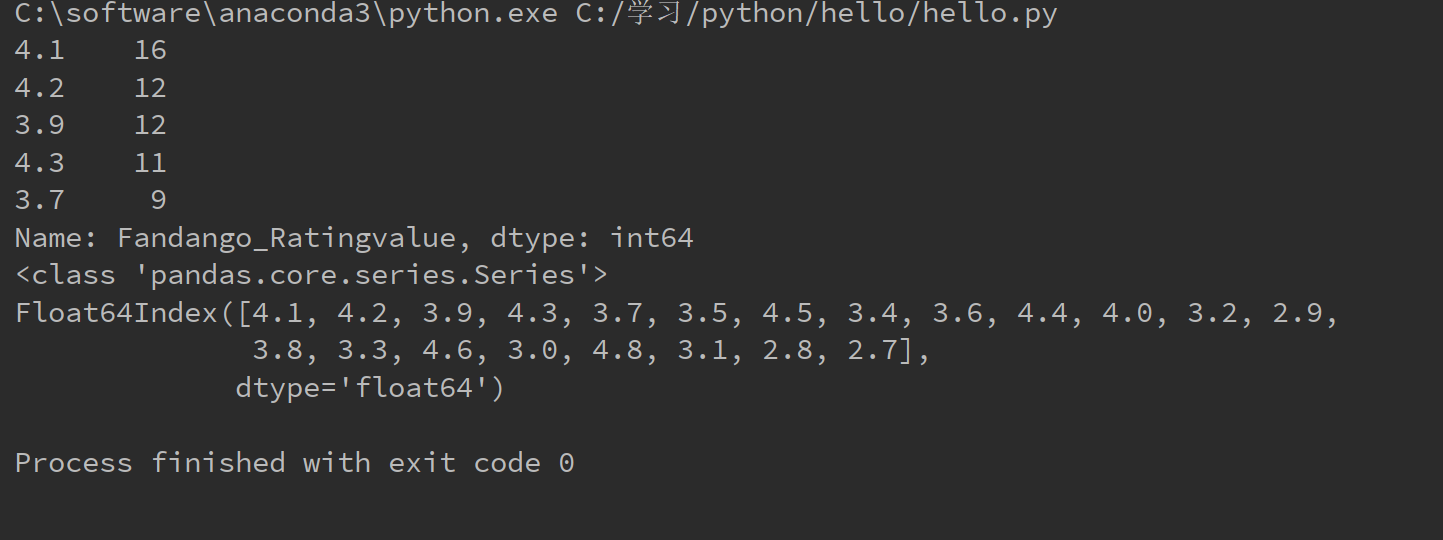
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 6 cols = ["FILM", "RT_user_norm", "Metacritic_user_nom", "Fandango_Ratingvalue"] 7 norm_reviews = reviews[cols] 8 #fandango_distribution是Series结构,index是原来的列的值,value是该值出现的频率 9 fandango_distribution = norm_reviews["Fandango_Ratingvalue"].value_counts() 10 print(fandango_distribution.head(5)) 11 print(type(fandango_distribution)) 12 print(fandango_distribution.index)
运行结果如下
8.我们来画直方图
1 import pandas as pd 2 import numpy as np 3 import matplotlib.pyplot as plt 4 5 reviews = pd.read_csv("C:/学习/python/hello/fandango_score_comparison.csv") 6 cols = ["FILM", "RT_user_norm", "Metacritic_user_nom","IMDB_norm", "Fandango_Ratingvalue"] 7 norm_reviews = reviews[cols] 8 plt.figure(figsize=(10, 10)) 9 ax = plt.subplot(1, 1, 1) 10 ax.hist(norm_reviews["RT_user_norm"], bins=20) #参数bins表示直方图的x轴分成多少区间 11 12 plt.show()
运行结果如下