理论部分
概述
- 感知主要发生在我们的意识之外,在大脑专门的视觉、听觉和其他感官模块中。当感知信息达到意识时,它已经被高层次的特征修饰过了。
- 感知根本不是微不足道的事情。要了解它,我们必须着眼于感知模块是如何运作的
- 卷积神经网络(CNN)起源于对大脑的视觉皮层的研究
视觉皮层的架构
- 视觉皮层神经元有一个小的局部接受野,这就意味着它们只对视野的局部区域内的视觉刺激做出反应。不同神经元的接受野可能会重复,它们一起平铺在整个视觉区域中
- 两个神经元可能有相同的接受野,但是作用于不同的方向
- 高阶神经元基于相邻的低阶神经元的输出,这种强大的组织结构可以检测到视觉区域内的所有复杂模式
卷积层
- 为什么不简单地使用具有全连接层的深度神经网络来执行图像识别任务呢?尽管这对于较小的图像效果很好,但是由于需要大量的参数,因此对于较大的图像无能为力。CNN使用部分连接层和权重共享解决了此问题
- CNN的最重要的构建块是卷积层:第一卷积层的神经元不会连接到输入图像中的每个像素,而只与其接受野内的像素相连接,反过来,第二卷积层的每个神经元仅连接到位于第一层中的一个小矩阵内的神经元。这种架构允许网络集中在第一个隐藏层的低阶特征中,然后在下一个隐藏层中将它们组装成比较高阶的特征
- 到目前为止,我们研究的所有多层神经网络都具有由一长列神经元组成的层,我们必须将输入图像展平为一维,然后再将其输入到神经网络中。在CNN中,每一层都以2D表示,这使得将神经元与其相应的输入进行匹配变得更加容易
- padding和stride
\[为了使层的高度和宽度与上一层相同,通常在输入周围添加0,这称为0填充\\
也可以通过隔出接受野的方式来将较大的输入层连接到较小的层,\\
这大大降低了模型的计算复杂度。从一个接受移到另一个接受野的距离称为步幅。\\
位于上层第i行、第j列的神经元与位于第i*s_h到i*s_h+f_h-1行、\\
第j*s_w到j*s_w+f_w-1列的上一层神经元的输出连接\\
其中f_h为接受野的垂直边长,f_w为接受野的水平边长、\\
s_h和s_w分别为垂直步幅和水平步幅
\]
- 滤波器
- 神经元的权重可以表示为一小幅图像,其大小相当于接受野的大小,这称为滤波器(或卷积核)
- 使用相同滤波器的充满神经元的层会输出一个特征图,该图突出显示图像中最激活滤波器的区域,当然,你不必手动定义滤波器:相反,在训练过程中,卷积层将自动学习对其任务最有用的滤波器,而上面的层将学习把它们组合成更复杂的模式
- 堆叠多个特征图
- 实际上卷积层具有多个滤波器(你可以决定多少个)并为每个滤波器输出一个特征图。它在每个特征图中每个像素有一个神经元,给定特征图中的所有神经元共享相同的参数(即相同的权重和偏差项)。不同特征图中的神经元使用不同的参数。神经元的接受野与先前描述的相同,但是它扩展到了所有先前层的特征图。简而言之,卷积层将多个可训练的滤波器同时应用于其输入,从而使其能够检测出输入中任何位置的多个特征
- 特征图中所有的神经元共享相同的参数,大大减少了模型中参数的数量。CNN一旦学会了在一个位置识别模式,就可以在其他任何位置识别模式。相反,常规DNN学会了在一个位置识别模式,它就只能在那个特定位置识别它
- 输入图像也由多个子层组成:每个颜色通道有一个子层。通常有三种:红色、绿色和蓝色(RGB)。灰度图像只有一个通道,但是某些图像可能具有更多通道,例如有额外光频率(例如红外)的卫星图像
- 请注意,位于同一行i和列j中但位于不同特征图中的所有神经元都连接到上一层中完全相同的神经元输出
- 计算卷积层中神经元的输出
\[z_{i,j,k}=b_k+\sum^{f_h-1}_{u=0}\sum^{f_w-1}_{v=0}\sum^{f_{n^{'}}-1}_{k^{'}=0}x_{i^{'},j^{'},k^{'}}w_{u,v,k^{'},k}\\
其中:\left\{\begin{matrix}
i^{'}=i*s_h+u\\
j^{'}=j*s_w+v
\end{matrix}\right .\\
其中:\\
z_{i,j,k}是位于卷积层(第l层)的特征图k中第i行j列中的神经元输出\\
s_h和s_w是垂直步幅和水平步幅,f_h和f_w是接受野的高度和宽度,\\
f_{n^{'}}是上一层(l-1)层中特征图的数量\\
x_{i^{'},j^{'},k^{'}}是位于第l-1层、第i^{'}行j^{'}列、特征图k^{'}的神经元输出\\
b_k是特征图k(在l层中)的偏置项。你可以将其视为用于调整特征图k整体亮度的旋钮\\
w_{u,v,k^{'},k}是层l的特征图k中任何神经元与其位于u行v列和特征图k^{'}的输入之间的连接权重
\]
- TensorFlow实现
- 在TensorFlow中,每个输入图像通常表示为形状为[height, width, channels]的3D张量。小批量表示为形状为[mini batch size, height, width, channels]的4D张量。卷积层的权重表示为形状为[fh, fw, fn', fn]的4D张量。卷积层的偏置项简单表示为形状[fn]的一维张量
- tf.nn.conv2d(images, filters, strides=1, padding='SAME')
- images是输入的小批量(4D张量)
- filter是要应用的一组滤波器(4D张量)
- strides等于1,但也可以说包含四个元素的一维度组,其中中间两个元素是垂直步幅和水平步幅(sh和sw)。第一个元素和最后一个元素必须等于1。它们可能有一天用于指定批处理步幅或(跳过某些实例)和通道步幅(跳过某些上一层的特征图或通道)
- padding必须为"SAME"或"VALID"
- 如果设置为"SAME",则卷积层在必要时使用0填充。将输出大小设置为输入神经元的数量除以步幅(向上取整)所得的值。当strides=1时,层的输出将具有与其输入相同的空间尺寸(宽度和高度),因此命名为"same"
- 如果设置为"VALID",则卷积层将不使用零填充,并且可能会忽略输入图像底部和右侧的某些行和列,具体取决于步幅
- 内存需求
- 在推理期间(即对新实例进行预测时),只要计算量下一层,就可以释放由前一层占用的RAM,因此你只需要两个连续的RAM。但是在训练过程中,需要保留正向传播过程中计算出的所有内容以供反向传播,因此所需的RAM量至少是所有层所需的RAM总量
池化层
- 池化层的目标是对输入图像进行下采样(即缩小),以便减少计算量、内存使用量和参数数量(从而降低过拟合的风险)
- 池化层中的每个神经元都连接到位于一个小的矩形接受野中的上一层中有限数量的神经元的输出。你必须像以前一样定义其大小、步幅和填充类型。但是池化神经元没有权重,它所做的全部工作就是使用聚合函数(例如最大值或均值)来聚合输入
- 池化层通常独立地作用于每个输入通道,因此输出深度与输入深度相同
- 除了减少计算量、内存使用量和参数数量之外,最大池化层还为小变换引入了一定程度的不变性。通过在CNN中每隔几层插入一个最大池化层,就可以在更大范围内获得某种程度的变换不变性。而且最大池化提供了少量的旋转不变性和轻微的尺度不变性
- 最大池化也有一些缺点:首先,它显然是非常具有破坏性的;在某些应用中,不变性是不可取的
- 最大池化层和平均池化层可以沿深度维度而不是空间维度执行,尽管这并不常见。这可以使CNN学习各种特征的不变性,CNN可以类似的学会对其他任何东西的不变性:厚度、亮度、偏斜、颜色,等等
- 全局平均池化层的工作原理非常不同:它所做的是计算整个特征图的均值(这就像使用与输入有相同空间维度的池化内核的平均池化层)。这意味着它每个特征图和每个实例只输出一个单值。尽管这是极具破坏性的(特征图中的大多数信息都丢失了),但它可以用作输出层
CNN架构
- 典型的CNN架构堆叠了一些卷积层(通常每个卷积层都跟随一个ReLU层),然后是一个池化层,然后是另外几个卷积层(+ReLU),然后是另一个池化层,以此类推。随着卷积网络的不断发展,图像变得越来越小,但由于卷积层的存在,图像通常也越来越深(即具有多个特征图)。在堆栈的顶部添加了一个常规的前馈神经网络,该网络由几个全连接层(+ReLU)组成,最后一层输出预测(例如输出估计类别概率的softmax层)
- 一个常见的错误是使用太大的卷积核。例如与其使用具有5*5内核的卷积层,不如使用具有3*3内核的两层:它使用较少的参数并需要较少的计算,并且通常性能会更好。第一个卷积层是一个例外:它具有较大的内核(例如5*5),步幅通常为2或更大,这将减少图像的空间维度而不会丢失太多信息,由于输入图像通常只有三个通道,因此不需要太多的计算量
- 请注意,随着CNN向输出延伸,滤波器的数量会增加:增长是有意义的,因为低层特征的数量通常很少(例如小圆圈、水平线),但是由很多不同的方法可以将它们组合成更高层次的特征。通常的做法是在每个池化层之后将滤波器的数量加倍:由于池化层将每个空间维度除以2,所以我们能负担得起对下一层特征数量加倍而不必担心参数数量、内存使用量或计算量的暴增
- LeNet-5
- 最广为人知的CNN架构
- AlexNet
- 与LeNet-5相似,只是更大和更深,它是第一个将卷积层直接堆叠在一起的方法,而不是将池化层堆叠在每个卷积层之上
- 为了减少过拟合,作者使用了两种正则化技术:首先,他们在训练期间对F9层和F10层的输出使用了dropout率为50%的dropout技术;其次,他们通过随机变化训练图像的各种偏移量、水平翻转以及更改亮度条件来执行数据增强
- 数据增强通过生成每个训练实例的许多变来人为地增加训练集的大小,这减少了过拟合,使之称为一种正则化技术
- AlexNet还在C1和C3的ReLU之后以及使用归一化步骤,称为局部响应归一化(LRN):最强激活神经元会抑制位于相邻特征图中相同位置的其他神经元(在生物神经元中已观察到这种竞争性激活)。这鼓励不同的特征图的专业化,将它们分开并迫使它们探索更广泛的特征,从而最终改善泛化能力
- GoogLeNet
- 由于该网络比以前的CNN更深以及被称为盗梦空间(inception)模块的使用能使GoogLeNet比以前的架构更有效地使用参数
- inception模块具有带1*1内核的卷积层的目的,这些层肯定不会识别任何特征,因为它们一次只能看到一个像素:
- 尽管它们无法识别空间特征,但它们可以识别沿深度维度的特征
- 它们输出比输入更少的特征图,因此它们充当了瓶颈层,这意味着它们降低了维度。这减少了计算量和参数数量,加快了训练速度,并提高了泛化能力
- 每对卷积层([1*1和3*3]和[1*1和5*5])就像一个强大的卷积层,能够识别更复杂的模式。实际上这对卷积层不是在整个图像上扫描简单的线性分类器(就像单个卷积层一样),而是在整个图像上扫描了两层神经网络
- ResNet
- ResNet(残差网络)证明了一个趋势:模型变得越来越深,参数越来越少。能够训练这种深层网络的关键是使用跳过连接(也称为快捷连接):馈入层的信号也将添加到位于堆栈上方的层的输出中
- 当训练神经网络时,目标是使其称为目标函数h(x)的模型。如果将输入x添加到网络的输出(即添加跳过连接),则网络将被迫建模f(x)=h(x)-x而不是h(x)。这称为残差学习。初始化常规神经网络时,其权重接近零,因此网络仅输出接近零的值。如果添加跳过连接,则生成的网络仅输出其输入的副本。换句话说,它首先对恒等函数建模,如果目标函数与恒等函数相当接近(通常是这种情况),这会大大加快训练速度
- 借助跳过连接,信号可以轻松地在整个网络中传播。深度残差网络可以看作是残差单元(RU)的堆栈,其中每个残差单元都是具有跳过连接的小型神经网络
- Xception
- 它融合了GoogLeNet和ResNet的思想,但是它用称为深度方向可分离卷积层(或简称为可分离卷积层)的特殊类型替换了inception模块。虽然常规卷积层使用的滤波器试图同时识别空间模式(例如椭圆形)和跨通道模式(例如,嘴+鼻子+眼睛=脸),但可分离的卷积层的强烈假设是空间模式和跨通道模式可以单独建模。因此它由两部分组成:第一部分为每个输入特征图应用一个空间滤波器,然后第二部分专门寻找跨通道模式—它是具有1*1滤波器的常规卷积层
- 由于可分离的卷积层威哥输入通道仅具有一个空间滤波器,因此应避免在通道数量太少的层(例如输入层)之后使用它们。Xception架构从两个常规卷积层开始,但随后的其余部分仅使用可分离卷积层,外加几个最大池化层和通常的最终层(全局平均池化层和一个密集输出层)
- SENet
- inception和ResNet的扩展版本分别称为SE-Inception和SE-ResNet。SENet的增强来自这样一个事实—SENet向原始建构中国的每个单元(即每个inception模块或每个残差单元)添加了一个称为SE快的小型神经网络
- SE块分析其连接的单元的输出,仅专注与深度维度(它不关心任何空间模式),并了解哪一些特征通常最活跃,然后,它使用此信息重新校准特征图,更准确地说,它将降低无关的特征图
- SE块仅由三层组成:全局平均池化层、使用ReLU激活函数的隐藏密基层和使用sigmoid激活函数的密集输出层。全局平均池化层为每个特征图计算平均激活,代表每个滤波器的总体响应;下一层是“挤压”发生的地方:通常比特征图的数目少16倍,这是特征响应分布的低维向量表示(即嵌入),这个瓶颈步骤迫使SE模块学习特征组合的一般表征形式;最后输出层进行嵌入,并输出一个重新校准的向量,每个特征图包含一个数字,每个数字介于0和1之间。然后将特征图与该重新校准的向量相乘,因此不相关的特征按比例缩小,而相关特征(重新校准分数接近1)则不予考虑
分类和定位
- 定位图片中物体可以表示为回归任务:预测物体周围的边界框,一种常见的方法是预测物体中心的水平坐标和垂直坐标,还有其高度和宽度,这意味着我们有四个数字需要预测。它不需要对模型进行太多修改,我们只需要添加具有四个单位的第二个密集输出层(通常在全局平均池化层之上),就可以使用MSE损失对其进行训练
- MSE通常作为成本函数可以很好地训练模型,但是评估模型对边界框的预测能力不是一个很好的指标。最常用的度量指标是“并交比”(IOU):预测边界框和目标边界框的重叠面积除以它们的联合面积
物体检测
- 一种通用的方法是采用经过训练的CNN来对单个物体进行分类和定位,然后将其在图像上滑动
- 全卷积网络(FCN)
- 用卷积层代替CNN顶部的密集层
- 要将密集层转换为卷积层,卷积层中的滤波器数必须等于密集层中的单元数,滤波器大小必须等于输入特征图的大小,并且使用"VALID"填充。步幅为1或更大
- YOLO
- You Only LookOnce
- 语义分割
代码部分
引入
import sys
assert sys.version_info >= (3, 5)
IS_COLAB = 'google.colab' in sys.modules
IS_KAGGLE = 'kaggle_secrets' in sys.modules
import sklearn
assert sklearn.__version__ >= '0.20'
import tensorflow as tf
from tensorflow import keras
assert tf.__version__ >= '2.0'
if not tf.config.list_physical_devices('GPU'):
print('No GPU was detected. CNNs can be very slow without a GPU')
if IS_COLAB:
print('Go to Runtime > Change runtime and select a GPU hardware accelerator.')
if IS_KAGGLE:
print('Go to Settings > Accelerator and select GPU.')
import numpy as np
import os
np.random.seed(42)
tf.random.set_seed(42)
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
PROJECT_ROOT_DIR = '.'
CHAPTER_ID = 'cnn'
IMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, 'images', CHAPTER_ID)
os.makedirs(IMAGES_PATH, exist_ok=True)
def save_fig(fig_id, tight_layout=True, fig_extension='png', resolution=300):
path = os.path.join(IMAGES_PATH, fig_id + '.' + fig_extension)
print('Saving figure', fig_id)
if tight_layout:
plt.tight_layout()
plt.savefig(path, format=fig_extension, dpi=resolution)
def plot_image(image):
plt.imshow(image, cmap='gray', interpolation='nearest')
plt.axis('off')
def plot_color_image(image):
plt.imshow(image, interpolation='nearest')
plt.axis('off')
什么是卷积
import numpy as np
from sklearn.datasets import load_sample_image
china = load_sample_image('china.jpg') / 255
flower = load_sample_image('flower.jpg') / 255
images = np.array([china, flower])
batch_size, height, width, channels = images.shape
filters = np.zeros(shape=(7, 7, channels, 2), dtype=np.float32)
filters[:, 3, :, 0] = 1 # vertical line
filters[3, :, :, 1] = 1 # horizontal line
outputs = tf.nn.conv2d(images, filters, strides=1, padding='SAME')
plt.imshow(outputs[0, :, :, 1], cmap='gray') # plot 1st image's 2nd feature map
plt.axis('off')
plt.show()

for image_index in (0, 1):
for feature_map_index in (0, 1):
plt.subplot(2, 2, image_index * 2 + feature_map_index + 1)
plot_image(outputs[image_index, :, :, feature_map_index])
plt.show()

# 裁剪
def crop(images):
return images[150: 220, 130: 250]
plot_image(crop(images[0, :, :, 0]))
save_fig('china_original', tight_layout=False)
plt.show()
for feature_map_index, filename in enumerate(['china_vertical', 'china_horizontal']):
plot_image(crop(outputs[0, :, :, feature_map_index]))
save_fig(filename, tight_layout=False)
plt.show()


plot_image(filters[:, :, 0, 0])
plt.show()
plot_image(filters[:, :, 0, 1])
plt.show()

卷积层
np.random.seed(42)
tf.random.set_seed(42)
conv = keras.layers.Conv2D(filters=2, kernel_size=7, strides=1, padding='SAME', activation='relu', input_shape=outputs.shape)
conv_outputs = conv(images)
conv_outputs.shape # TensorShape([2, 427, 640, 2])
The output is a 4D tensor. The dimensions are: batch size, height, width, channels. The first dimension (batch size) is 2 since there are 2 input images. The next two dimensions are the height and width of the output feature maps: since padding="SAME" and strides=1, the output feature maps have the same height and width as the input images (in this case, 427×640). Lastly, this convolutional layer has 2 filters, so the last dimension is 2: there are 2 output feature maps per input image.
plt.figure(figsize=(10, 6))
for image_index in (0, 1):
for feature_map_index in (0, 1):
plt.subplot(2, 2, image_index * 2 + feature_map_index + 1)
plot_image(crop(conv_outputs[image_index, :, :, feature_map_index]))
plt.show()

conv.set_weights([filters, np.zeros(2)])
conv_outputs = conv(images)
conv_outputs.shape # TensorShape([2, 427, 640, 2])
plt.figure(figsize=(10, 6))
for image_index in (0, 1):
for feature_map_index in (0, 1):
plt.subplot(2, 2, image_index * 2 + feature_map_index + 1)
plot_image(crop(conv_outputs[image_index, :, :, feature_map_index]))
plt.show()

VALID和SAMEpadding
def feature_map_size(input_size, kernel_size, strides=1, padding='SAME'):
if padding == 'SAME':
return (input_size - 1) // strides + 1
else:
return (input_size - kernel_size) // strides + 1
def pad_before_and_padded_size(input_size, kernel_size, strides=1):
fmap_size = feature_map_size(input_size, kernel_size, strides)
padded_size = max((fmap_size - 1) * strides + kernel_size, input_size)
pad_before = (padded_size - input_size) // 2
return pad_before, padded_size
def manual_same_padding(images, kernel_size, strides=1):
if kernel_size == 1:
return images.astype(np.float32)
batch_size, height, width, channels = images.shape
top_pad, padded_height = pad_before_and_padded_size(height, kernel_size, strides)
left_pad, padded_width = pad_before_and_padded_size(width, kernel_size, strides)
padded_shape = [batch_size, padded_height, padded_width, channels]
padded_images = np.zeros(padded_shape, dtype=np.float32)
padded_images[:, top_pad:height+top_pad, left_pad:width+left_pad, :] = images
return padded_images
kernel_size = 7
strides = 2
conv_valid = keras.layers.Conv2D(filters=1, kernel_size=kernel_size, strides=strides, padding='VALID')
conv_same = keras.layers.Conv2D(filters=1, kernel_size=kernel_size, strides=strides, padding='SAME')
valid_output = conv_valid(manual_same_padding(images, kernel_size, strides))
# Need to call build() so conv_same's weights get created
conv_same.build(tf.TensorShape(images.shape))
# Copy the weights from conv_valid to conv_same
conv_same.set_weights(conv_valid.get_weights())
same_output = conv_same(images.astype(np.float32))
assert np.allclose(valid_output.numpy(), same_output.numpy())
池化层-最大池化层
# 最大池化层
max_pool = keras.layers.MaxPool2D(pool_size=2)
cropped_images = np.array([crop(image) for image in images], dtype=np.float32)
output = max_pool(cropped_images)
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title('Input', fontsize=14)
ax1.imshow(cropped_images[0])
ax1.axis('off')
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title('Output', fontsize=14)
ax2.imshow(output[0])
ax2.axis('off')
save_fig('china_max_pooling')
plt.show()

沿深度维度的池化
class DepthMaxPool(keras.layers.Layer):
def __init__(self, pool_size, strides=None, padding='VALID', **kwargs):
super().__init__(**kwargs)
if strides is None:
strides = pool_size
self.pool_size = pool_size
self.strides = strides
self.padding = padding
def call(self, inputs):
return tf.nn.max_pool(inputs,
ksize=(1, 1, 1, self.pool_size),
strides=(1, 1, 1, self.pool_size),
padding=self.padding)
depth_pool = DepthMaxPool(3)
with tf.device('/cpu:0'):
depth_output = depth_pool(cropped_images)
depth_output.shape # TensorShape([2, 70, 120, 1])
depth_pool = keras.layers.Lambda(lambda X: tf.nn.max_pool(X, ksize=(1, 1, 1, 3),
strides=(1, 1, 1, 3), padding='VALID'))
with tf.device('/cpu:0'):
depth_output = depth_pool(cropped_images)
depth_output.shape # TensorShape([2, 70, 120, 1])
plt.figure(figsize=(12, 8))
plt.subplot(121)
plt.title('Input', fontsize=14)
plot_color_image(cropped_images[0])
plt.subplot(122)
plt.title('Output', fontsize=14)
plot_image(depth_output[0, ..., 0])
plt.axis('off')
plt.show()

平均值池化
avg_pool = keras.layers.AvgPool2D(pool_size=2)
output_avg = avg_pool(cropped_images)
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[2, 1])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title('Input', fontsize=14)
ax1.imshow(cropped_images[0])
ax1.axis('off')
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title('Output', fontsize=14)
ax2.imshow(output_avg[0])
ax2.axis('off')
plt.show()

全局平均池化层
global_avg_pool = keras.layers.GlobalAvgPool2D()
global_avg_pool(cropped_images)
'''
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.2788801 , 0.22507527, 0.20967631],
[0.51287866, 0.4595188 , 0.3342377 ]], dtype=float32)>
'''
output_global_avg2 = keras.layers.Lambda(lambda X: tf.reduce_mean(X, axis=[1, 2]))
output_global_avg2(cropped_images)
'''
<tf.Tensor: shape=(2, 3), dtype=float32, numpy=
array([[0.2788801 , 0.22507527, 0.20967631],
[0.51287866, 0.4595188 , 0.3342377 ]], dtype=float32)>
'''
用CNN处理Fashion MNIST数据集
(X_train_full, y_train_full), (X_test, y_test) = keras.datasets.fashion_mnist.load_data()
X_train, X_valid = X_train_full[:-5000], X_train_full[-5000:]
y_train, y_valid = y_train_full[:-5000], y_train_full[-5000:]
X_mean = X_train.mean(axis=0, keepdims=True)
X_std = X_train.std(axis=0, keepdims=True) + 1e-7
X_train = (X_train - X_mean) / X_std
X_valid = (X_valid - X_mean) / X_std
X_test = (X_test - X_mean) / X_std
X_train = X_train[..., np.newaxis]
X_valid = X_valid[..., np.newaxis]
X_test = X_test[..., np.newaxis]
# 简单说就是把一个函数,和该函数所需传的参数封装到一个class 'functools.partial'的类中,简化以后的调用方式
from functools import partial
DefaultConv2D = partial(keras.layers.Conv2D, kernel_size=3, activation='relu', padding='SAME')
model = keras.models.Sequential([
DefaultConv2D(filters=64, kernel_size=7, input_shape=[28, 28, 1]),
keras.layers.MaxPool2D(pool_size=2),
DefaultConv2D(filters=128),
DefaultConv2D(filters=128),
keras.layers.MaxPool2D(pool_size=2),
DefaultConv2D(filters=256),
DefaultConv2D(filters=256),
keras.layers.MaxPool2D(pool_size=2),
keras.layers.Flatten(),
keras.layers.Dense(units=128, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=64, activation='relu'),
keras.layers.Dropout(0.5),
keras.layers.Dense(units=10, activation='softmax')
])
model.compile(loss='sparse_categorical_crossentropy', optimizer='nadam', metrics=['accuracy'])
history = model.fit(X_train, y_train, epochs=10, validation_data=(X_valid, y_valid))
score = model.evaluate(X_test, y_test)
X_new = X_test[:10]
X_pred = model.predict(X_new)
ResNet-34
DefaultConv2D = partial(keras.layers.Conv2D, kernel_size=3, strides=1, padding='SAME', use_bias=False)
class ResidualUnit(keras.layers.Layer):
def __init__(self, filters, strides=1, activation='relu', **kwargs):
super().__init__(**kwargs)
self.activation = keras.activations.get(activation)
self.main_layers = [
DefaultConv2D(filters, strides=strides),
keras.layers.BatchNormalization(),
self.activation,
DefaultConv2D(filters),
keras.layers.BatchNormalization()
]
self.skip_layers = []
if strides > 1:
self.skip_layers = [
DefaultConv2D(filters, kernel_size=1, strides=strides),
keras.layers.BatchNormalization()
]
def call(self, inputs):
Z = inputs
for layer in self.main_layers:
Z = layer(Z)
skip_Z = inputs
for layer in self.skip_layers:
skip_Z = layer(skip_Z)
return self.activation(Z + skip_Z)
model = keras.models.Sequential()
model.add(DefaultConv2D(64, kernel_size=7, strides=2, input_shape=[224, 224, 3]))
model.add(keras.layers.BatchNormalization())
model.add(keras.layers.Activation('relu'))
model.add(keras.layers.MaxPool2D(pool_size=3, strides=2, padding='SAME'))
prev_filters = 64
for filters in [64] * 3 + [128] * 4 + [256] * 6 + [512] * 3:
strides = 1 if filters == prev_filters else 2
model.add(ResidualUnit(filters, strides=strides))
prev_filters = filters
model.add(keras.layers.GlobalAvgPool2D())
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(10, activation='softmax'))
model.summary()
'''
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_8 (Conv2D) (None, 112, 112, 64) 9408
_________________________________________________________________
batch_normalization (BatchNo (None, 112, 112, 64) 256
_________________________________________________________________
activation (Activation) (None, 112, 112, 64) 0
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 56, 56, 64) 0
_________________________________________________________________
residual_unit (ResidualUnit) (None, 56, 56, 64) 74240
_________________________________________________________________
residual_unit_1 (ResidualUni (None, 56, 56, 64) 74240
_________________________________________________________________
residual_unit_2 (ResidualUni (None, 56, 56, 64) 74240
_________________________________________________________________
residual_unit_3 (ResidualUni (None, 28, 28, 128) 230912
_________________________________________________________________
residual_unit_4 (ResidualUni (None, 28, 28, 128) 295936
_________________________________________________________________
residual_unit_5 (ResidualUni (None, 28, 28, 128) 295936
_________________________________________________________________
residual_unit_6 (ResidualUni (None, 28, 28, 128) 295936
_________________________________________________________________
residual_unit_7 (ResidualUni (None, 14, 14, 256) 920576
_________________________________________________________________
residual_unit_8 (ResidualUni (None, 14, 14, 256) 1181696
_________________________________________________________________
residual_unit_9 (ResidualUni (None, 14, 14, 256) 1181696
_________________________________________________________________
residual_unit_10 (ResidualUn (None, 14, 14, 256) 1181696
_________________________________________________________________
residual_unit_11 (ResidualUn (None, 14, 14, 256) 1181696
_________________________________________________________________
residual_unit_12 (ResidualUn (None, 14, 14, 256) 1181696
_________________________________________________________________
residual_unit_13 (ResidualUn (None, 7, 7, 512) 3676160
_________________________________________________________________
residual_unit_14 (ResidualUn (None, 7, 7, 512) 4722688
_________________________________________________________________
residual_unit_15 (ResidualUn (None, 7, 7, 512) 4722688
_________________________________________________________________
global_average_pooling2d_1 ( (None, 512) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 10) 5130
=================================================================
Total params: 21,306,826
Trainable params: 21,289,802
Non-trainable params: 17,024
_________________________________________________________________
'''
使用预训练模型
model = keras.applications.resnet50.ResNet50(weights='imagenet')
images_resized = tf.image.resize(images, [224, 224])
plot_color_image(images_resized[0])
plt.show()

images_resized = tf.image.resize_with_pad(images, 224, 224, antialias=True)
plot_color_image(images_resized[0])

images_resized = tf.image.resize_with_crop_or_pad(images, 224, 224)
plot_color_image(images_resized[0])
plt.show()

china_box = [0, 0.03, 1, 0.68]
flower_box = [0.19, 0.26, 0.86, 0.7]
images_resized = tf.image.crop_and_resize(images, [china_box, flower_box], [0, 1], [224, 224])
plot_color_image(images_resized[0])
plt.show()
plot_color_image(images_resized[1])
plt.show()

inputs = keras.applications.resnet50.preprocess_input(images_resized * 255)
Y_proba = model.predict(inputs)
Y_proba.shape # (2, 1000)
top_K = keras.applications.resnet50.decode_predictions(Y_proba, top=3)
for image_index in range(len(images)):
print('Image #{}'.format(image_index))
for class_id, name, y_proba in top_K[image_index]:
print(" {} - {:.2s} {:.2f}%".format(class_id, name, y_proba * 100))
print()
'''
Image #0
n03877845 - pa 43.39%
n02825657 - be 43.07%
n03781244 - mo 11.70%
Image #1
n04522168 - va 53.96%
n07930864 - cu 9.52%
n11939491 - da 4.97%
'''
迁移模型
import tensorflow_datasets as tfds
dataset, info = tfds.load('tf_flowers', as_supervised=True, with_info=True)
info.splits # {Split('train'): <SplitInfo num_examples=3670, num_shards=2>}
info.splits['train'] # <SplitInfo num_examples=3670, num_shards=2>
class_names = info.features['label'].names
class_names # ['dandelion', 'daisy', 'tulips', 'sunflowers', 'roses']
n_classes = info.features['label'].num_classes
dataset_size = info.splits['train'].num_examples
dataset_size # 3670
test_set_raw, valid_set_raw, train_set_raw = tfds.load(
'tf_flowers',
split=['train[:10%]', 'train[10%:25%]', 'train[25%:]'],
as_supervised=True
)
plt.figure(figsize=(12, 10))
index = 0
for image, label in train_set_raw.take(9):
index += 1
plt.subplot(3, 3, index)
plt.imshow(image)
plt.title('Class: {}'.format(class_names[label]))
plt.axis('off')
plt.show()

def preprocess(image, label):
resized_image = tf.image.resize(image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
def central_crop(image):
shape = tf.shape(image)
min_dim = tf.reduce_min([shape[0], shape[1]])
top_crop = (shape[0] - min_dim) // 4
bottom_crop = shape[0] - top_crop
left_crop = (shape[1] - min_dim) // 4
right_crop = shape[1] - left_crop
return image[top_crop:bottom_crop, left_crop:right_crop]
def random_crop(image):
shape = tf.shape(image)
min_dim = tf.reduce_min([shape[0], shape[1]]) * 90 // 100
return tf.image.random_crop(image, [min_dim, min_dim, 3])
def preprocess(image, label, randomsize=False):
if randomsize:
cropped_image = random_crop(image)
cropped_image = tf.image.random_flip_left_right(cropped_image)
else:
cropped_image = central_crop(image)
resized_image = tf.image.resize(cropped_image, [224, 224])
final_image = keras.applications.xception.preprocess_input(resized_image)
return final_image, label
batch_size = 32
train_set = train_set_raw.shuffle(10000).repeat()
train_set = train_set.map(partial(preprocess, randomsize=True)).batch(batch_size).prefetch(1)
valid_set = valid_set_raw.map(preprocess).batch(batch_size).prefetch(1)
test_set = test_set_raw.map(preprocess).batch(batch_size).prefetch(1)
plt.figure(figsize=(12, 12))
for X_batch, y_batch in train_set.take(1):
for index in range(9):
plt.subplot(3, 3, index + 1)
plt.imshow(X_batch[index] / 2 + 0.5)
plt.title('Class:{}'.format(class_names[y_batch[index]]))
plt.axis('off')
plt.show()
plt.figure(figsize=(12, 12))
for X_batch, y_batch in test_set.take(1):
for index in range(9):
plt.subplot(3, 3, index + 1)
plt.imshow(X_batch[index] / 2 + 0.5)
plt.title('Class: {}'.format(class_names[y_batch[index]]))
plt.axis('off')
plt.show()

base_model = keras.applications.xception.Xception(weights='imagenet', include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
output = keras.layers.Dense(n_classes, activation='softmax')(avg)
model = keras.models.Model(inputs=base_model.input, outputs=output)
for index, layer in enumerate(base_model.layers):
print(index, layer.name)
'''
0 input_2
1 block1_conv1
2 block1_conv1_bn
3 block1_conv1_act
4 block1_conv2
5 block1_conv2_bn
6 block1_conv2_act
7 block2_sepconv1
8 block2_sepconv1_bn
9 block2_sepconv2_act
10 block2_sepconv2
11 block2_sepconv2_bn
12 conv2d_44
13 block2_pool
14 batch_normalization_36
15 add
16 block3_sepconv1_act
17 block3_sepconv1
18 block3_sepconv1_bn
19 block3_sepconv2_act
20 block3_sepconv2
21 block3_sepconv2_bn
22 conv2d_45
23 block3_pool
24 batch_normalization_37
25 add_1
26 block4_sepconv1_act
27 block4_sepconv1
28 block4_sepconv1_bn
29 block4_sepconv2_act
30 block4_sepconv2
31 block4_sepconv2_bn
32 conv2d_46
33 block4_pool
34 batch_normalization_38
35 add_2
36 block5_sepconv1_act
37 block5_sepconv1
38 block5_sepconv1_bn
39 block5_sepconv2_act
40 block5_sepconv2
41 block5_sepconv2_bn
42 block5_sepconv3_act
43 block5_sepconv3
44 block5_sepconv3_bn
45 add_3
46 block6_sepconv1_act
47 block6_sepconv1
48 block6_sepconv1_bn
49 block6_sepconv2_act
50 block6_sepconv2
51 block6_sepconv2_bn
52 block6_sepconv3_act
53 block6_sepconv3
54 block6_sepconv3_bn
55 add_4
56 block7_sepconv1_act
57 block7_sepconv1
58 block7_sepconv1_bn
59 block7_sepconv2_act
60 block7_sepconv2
61 block7_sepconv2_bn
62 block7_sepconv3_act
63 block7_sepconv3
64 block7_sepconv3_bn
65 add_5
66 block8_sepconv1_act
67 block8_sepconv1
68 block8_sepconv1_bn
69 block8_sepconv2_act
70 block8_sepconv2
71 block8_sepconv2_bn
72 block8_sepconv3_act
73 block8_sepconv3
74 block8_sepconv3_bn
75 add_6
76 block9_sepconv1_act
77 block9_sepconv1
78 block9_sepconv1_bn
79 block9_sepconv2_act
80 block9_sepconv2
81 block9_sepconv2_bn
82 block9_sepconv3_act
83 block9_sepconv3
84 block9_sepconv3_bn
85 add_7
86 block10_sepconv1_act
87 block10_sepconv1
88 block10_sepconv1_bn
89 block10_sepconv2_act
90 block10_sepconv2
91 block10_sepconv2_bn
92 block10_sepconv3_act
93 block10_sepconv3
94 block10_sepconv3_bn
95 add_8
96 block11_sepconv1_act
97 block11_sepconv1
98 block11_sepconv1_bn
99 block11_sepconv2_act
100 block11_sepconv2
101 block11_sepconv2_bn
102 block11_sepconv3_act
103 block11_sepconv3
104 block11_sepconv3_bn
105 add_9
106 block12_sepconv1_act
107 block12_sepconv1
108 block12_sepconv1_bn
109 block12_sepconv2_act
110 block12_sepconv2
111 block12_sepconv2_bn
112 block12_sepconv3_act
113 block12_sepconv3
114 block12_sepconv3_bn
115 add_10
116 block13_sepconv1_act
117 block13_sepconv1
118 block13_sepconv1_bn
119 block13_sepconv2_act
120 block13_sepconv2
121 block13_sepconv2_bn
122 conv2d_47
123 block13_pool
124 batch_normalization_39
125 add_11
126 block14_sepconv1
127 block14_sepconv1_bn
128 block14_sepconv1_act
129 block14_sepconv2
130 block14_sepconv2_bn
131 block14_sepconv2_act
'''
for layer in base_model.layers:
layer.trainable = False
optimizer = keras.optimizers.SGD(learning_rate=0.2, momentum=0.9, decay=0.01)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(train_set, steps_per_epoch=int(0.75 * dataset_size / batch_size), validation_data=valid_set,
validation_steps=int(0.15 * dataset_size / batch_size), epochs=5)
for layer in base_model.layers:
layer.trainable = True
optimizer = keras.optimizers.SGD(learning_rate=0.01, momentum=0.9, nesterov=True, decay=0.001)
model.compile(loss='sparse_categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
history = model.fit(train_set, steps_per_epoch=int(0.75 * dataset_size / batch_size), validation_data=valid_set,
validation_steps=int(0.15 * dataset_size / batch_size), epochs=40)
分类和定位
base_model = keras.applications.xception.Xception(weights='imagenet', include_top=False)
avg = keras.layers.GlobalAveragePooling2D()(base_model.output)
class_output = keras.layers.Dense(n_classes, activation='softmax')(avg)
loc_output = keras.layers.Dense(4)(avg)
model = keras.models.Model(inputs=base_model.input, outputs=[class_output, loc_output])
model.compile(loss=['sparse_categorical_crossentropy', 'mse'], loss_weights=[0.8, 0.2], optimizer=optimizer, metrics=['accuracy'])
def add_random_bounding_boxes(images, labels):
fake_bboxes = tf.random.uniform([tf.shape(images)[0], 4])
return images, (labels, fake_bboxes)
fake_train_set = train_set.take(5).repeat(2).map(add_random_bounding_boxes)
model.fit(fake_train_set, steps_per_epoch=5, epochs=2)
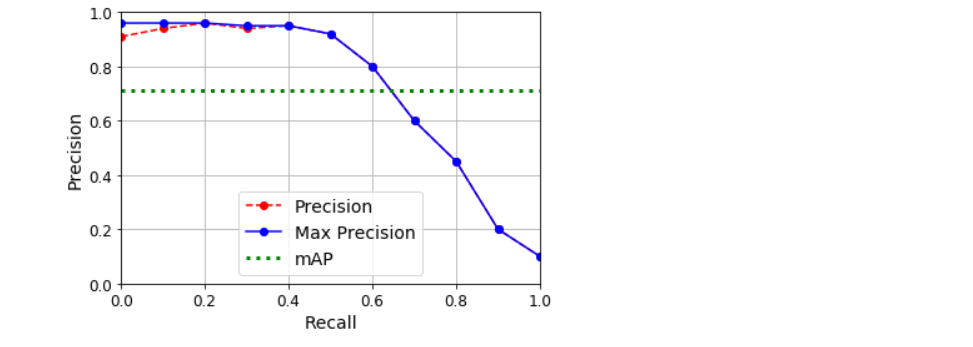
均值平均精度
计算召回率至少为0%时可以获得的最大精度(然后是10%、20%,以此类推, 直至100%),然后计算这些最大精度的平均值。这称为平均精度(AP)指标。当有两个以上类别时,我们可以为每个类别计算AP。然后计算平均AP(mAP)
# 翻转后找累计到当前的最大值并再次翻转
def maximum_precisions(precisions):
return np.flip(np.maximum.accumulate(np.flip(precisions)))
recalls = np.linspace(0, 1, 11)
precisions = [0.91, 0.94, 0.96, 0.94, 0.95, 0.92, 0.80, 0.60, 0.45, 0.20, 0.10]
max_precisions = maximum_precisions(precisions)
mAP = max_precisions.mean()
plt.plot(recalls, precisions, 'ro--', label='Precision')
plt.plot(recalls, max_precisions, 'bo-', label='Max Precision')
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.plot([0, 1], [mAP, mAP], 'g:', linewidth=3, label='mAP')
plt.grid(True)
plt.axis([0, 1, 0, 1])
plt.legend(loc='lower center', fontsize=14)
plt.show()
tf.random.set_seed(42)
X = images_resized.numpy()
conv_transpose = keras.layers.Conv2DTranspose(filters=5, kernel_size=3, strides=2, padding='VALID')
output = conv_transpose(X)
output.shape # TensorShape([2, 449, 449, 5])
def normalize(X):
return (X - tf.reduce_min(X)) / (tf.reduce_max(X) - tf.reduce_min(X))
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=2, width_ratios=[1, 2])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title('Input', fontsize=14)
ax1.imshow(X[0])
ax1.axis('off')
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title('Output', fontsize=14)
ax2.imshow(normalize(output[0, ..., :3]), interpolation='bicubic')
ax2.axis('off')
plt.show()

def upscale_images(images, stride, kernel_size):
batch_size, height, width, channels = images.shape
upscaled = np.zeros((batch_size, (height - 1) * stride + 2 * kernel_size -1, (width - 1) * stride + 2 * kernel_size -1, channels))
upscaled[:, kernel_size - 1:(height - 1) * stride + kernel_size:stride, kernel_size - 1:(width - 1) * stride + kernel_size:stride, :] = images
return upscaled
upscaled = upscale_images(X, stride=2, kernel_size=3)
weights, biases = conv_transpose.weights
reversed_filters = np.flip(weights.numpy(), axis=[0, 1])
reversed_filters = np.transpose(reversed_filters, [0, 1, 3, 2])
manual_output = tf.nn.conv2d(upscaled, reversed_filters, strides=1, padding='VALID')
def normalize(X):
return (X - tf.reduce_min(X)) / (tf.reduce_max(X) - tf.reduce_min(X))
fig = plt.figure(figsize=(12, 8))
gs = mpl.gridspec.GridSpec(nrows=1, ncols=3, width_ratios=[1, 2, 2])
ax1 = fig.add_subplot(gs[0, 0])
ax1.set_title('Input', fontsize=14)
ax1.imshow(X[0])
ax1.axis('off')
ax2 = fig.add_subplot(gs[0, 1])
ax2.set_title('Upscaled', fontsize=14)
ax2.imshow(upscaled[0], interpolation='bicubic')
ax2.axis('off')
ax3 = fig.add_subplot(gs[0, 2])
ax3.set_title('Output', fontsize=14)
ax3.imshow(normalize(manual_output[0, ..., :3]), interpolation='bicubic')
ax3.axis('off')
plt.show()
np.allclose(output, manual_output.numpy(), atol=1e-7) # True
