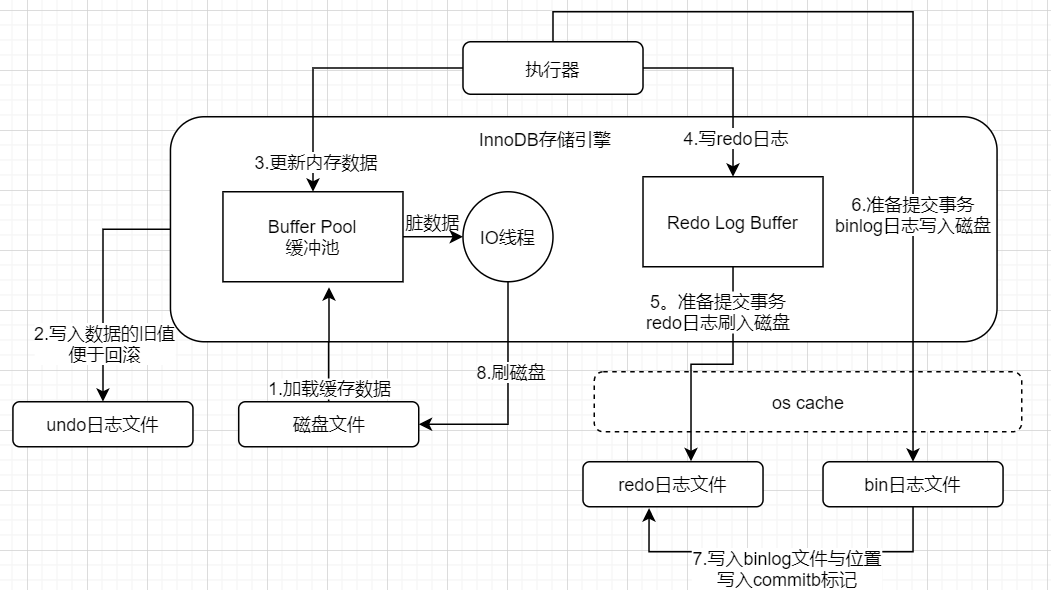
InnoDB存储引擎执行一个更新语句的流程
1.加载数据到缓存中,从磁盘文件加载数据到缓冲池里
2.把旧值写入undo日志文件,便于回滚
3.更新内存数据,也就是更新缓冲池里的数据,此时缓冲池的数据变成了脏数据,也即是说和磁盘文件里的数据不一致了
4.在3步更新后,万一出现系统宕机,缓冲池里的数据会丢失,所以引入redo log来解决,redo log也是先写入内存中的
5.在提交事务时会把redo log buffer的数据写入redo日志文件,从而保证即使系统宕机了也可以从redo日志文件中恢复数据
此时可以会有一个疑问,如果在提交事务前系统宕机了呢?此时缓冲区和redo log buffer的数据不是全丢了吗,数据不是丢失了吗?其实这种情况数据丢失是不要紧的,一个事务没有提交,代表它没有执行成功,此时数据丢失,磁盘文件里的数据还是原来的数据,是正常的,不会有任何问题
把redo日志从redo log buffer里刷入到磁盘文件有几个策略,可以通过innodb_flush_log_at_trx_commit来设置
为0时不刷入磁盘,为1时刷入磁盘,为2时先写入磁盘文件对应的os cache中,然后可能每隔1s刷入磁盘
6.在提交事务时也会更新bin log,它时mysql自己的日志文件,不是InnoDB特有的文件,记录的是偏向逻辑性的日志
bin log刷入磁盘也有几个策略,通过sync_binlog来设置,为0时先写入os cache,为1时直接输入磁盘文件
7.把binlog文件名称和这次更新的位置写入redo log中去,同时redolog也写入一个commit标记,这个做完一个事务就算结束了
这一步的意义是保持redo log日志和binlog日志一致,因为5和6是分开做的,在系统宕机时,它俩都有可能一个完成了一个没完成
8.mysql有一个线程定时的把缓冲区里的数据刷入磁盘