https://www.jianshu.com/p/26513f428ecf
https://blog.csdn.net/fly910905/article/details/87101059
https://cloud.tencent.com/developer/article/1367290
http://www.mycat.io/
Mycat 下载地址,http://dl.mycat.io/1.6-RELEASE/
https://www.cnblogs.com/rangle/p/8176362.html
根据你的版本,我这边选择的是windows的,没有搞虚拟机去玩Linux;
然后开始运行这个Mycat服务,mycat我的感受就是一个虚拟的中间件,他会拦截你的sql,在你的SQL在begin之前帮我们做了很多规则的拆分;
下图是从其他地方贴过来的,大概这个是这么个意思;

比如你要做读写分离,当然还有其他解决方案,你要做水平拆分,或者垂直拆分,他会提供很多规则给你,可以结合自己的业务去看;
下面说下自己在整合的过程中遇到的问题,
首先介绍下myCat的几个目录一个bin,一个config,这两个目录没什么好说的,跟tomcat、redis等都是一样的;
在bin中启动,config配置你的各种策略;
bin中启动的时候一定要用管理者模式启动,直接windows+R启动的模式不是管理者模式,网上有截图

管理员启动的方式,参考百度经验:https://jingyan.baidu.com/article/ceb9fb10b53ab88cac2ba05b.html

上面这个是一种简单的方式,仅供大家参考;
打开的命令界面模式是下面这样的,蓝色的背景哦;
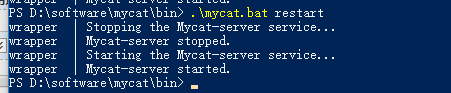
然后启动的日志的话就在logs里面,自己可以去看,在启动的过程中遇到问题的话可以通过日志去查看

下面说下自己遇到的坑:
这个mycat默认的端口是8066,如有端口被占用的话会一直起不来,你需要去杀掉相关进程后再启动;
conf中有3个配置文件一个schema.xml,rule.xml,server.xml
我根据自己的理解简单的说下这个3个文件是干啥的,先从简单的来,
rule.xml里面有格式各样的拆分规则,就是你需要把你的表按照什么规则去拆分,就像java中的一个工厂,里面有各种各样的规则,你要什么就配什么
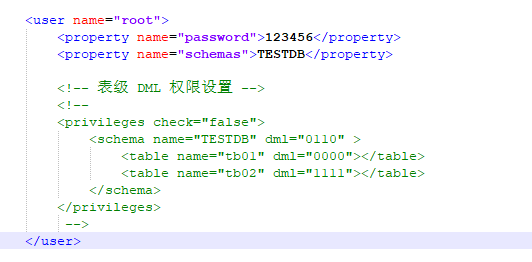
server.xml就是你虚拟的Mycat服务的配置信息,在你项目中jdbc的数据源URL配置的就是这个里面的,包括用户名,密码,我们的应用第一步不是跟数据库直连,而是通过这个mycat代理
进行相应的路由再到具体的业务库;
schema.xml核心配置文件,这个里面需要配置你的表,拆分的业务数据库的信息;
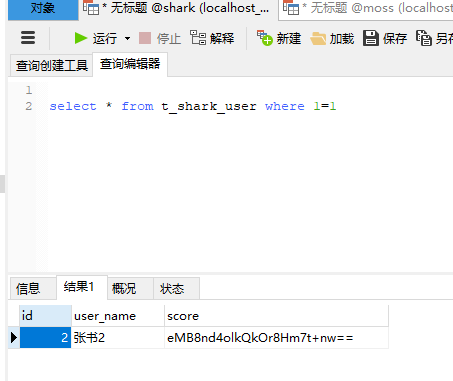
下面贴图给大家看下我的实验结果,两个库,不是一个库中的两个实例,不然好像会有问题!
<?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd"> <mycat:schema xmlns:mycat="http://io.mycat/"> <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100"> <table name="t_shark_user" primaryKey="id" dataNode="dn1,dn2" rule="rule1"/> </schema> <!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743" /> --> <dataNode name="dn1" dataHost="localhost1" database="shark" /> <dataNode name="dn2" dataHost="localhost2" database="test" /> <dataHost name="localhost1" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="localhost:3306" user="root" password="root"> </writeHost> </dataHost> <dataHost name="localhost2" maxCon="1000" minCon="10" balance="0" writeType="0" dbType="mysql" dbDriver="native" switchType="1"> <heartbeat>select user()</heartbeat> <!-- can have multi write hosts --> <writeHost host="hostM1" url="xx.xx.xx.xx:3306" user="test" password="test"> <!-- can have multi read hosts --> <!--<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />--> </writeHost> <!-- <writeHost host="hostS1" url="localhost:3316" user="root" password="123456" /> --> <!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> --> </dataHost> </mycat:schema>
我们在spring的XML直接配置成
url=jdbc:mysql://127.0.0.1:8066/TESTDB
password跟name都mycat的虚拟TESTDB,不是我们实际的数据库,
下面就OK,看效果了

按照ID进行拆分了,大概是这么个情况;
不过现在大多数人都不用Mycat,

shareingJDBC的方案好像是个趋势,感觉Mycat的是个黑盒,出了问题,都不好定位;未完待续