产品描述
这个产品的目的是为了学霸网站提供后台数据获取以及处理操作。在alpha阶段基本调通的基础至上,我们希望在bate版本中加入对于问答对的处理,图片的获取等功能。
预期目标
在alpha阶段,我们受限于时间,基本沿用了上届老旧的代码,所以遇到了很多bug问题,并且因为隐藏很深、缺失文档等原因导致较难调试。并且受限于整体程序框架,很多功能性问题都根本上无法解决。于是在bate版本中,我们选择了完全重构。针对于爬虫,我们抛弃掉alpha中纯手工爬取的方式,采用了crawler4j作为基础框架开发。针对于数据处理,也将上届代码完全拆分,并且将C#语言的代码改写成java(为了与代码整体框架更好的配合),同时计划新增管理网页,可以实现实时看到处理进度以及对于处理程序进行控制,这里采用Bootstrap框架,对于不同分辨率等支持较好。
阶段改进
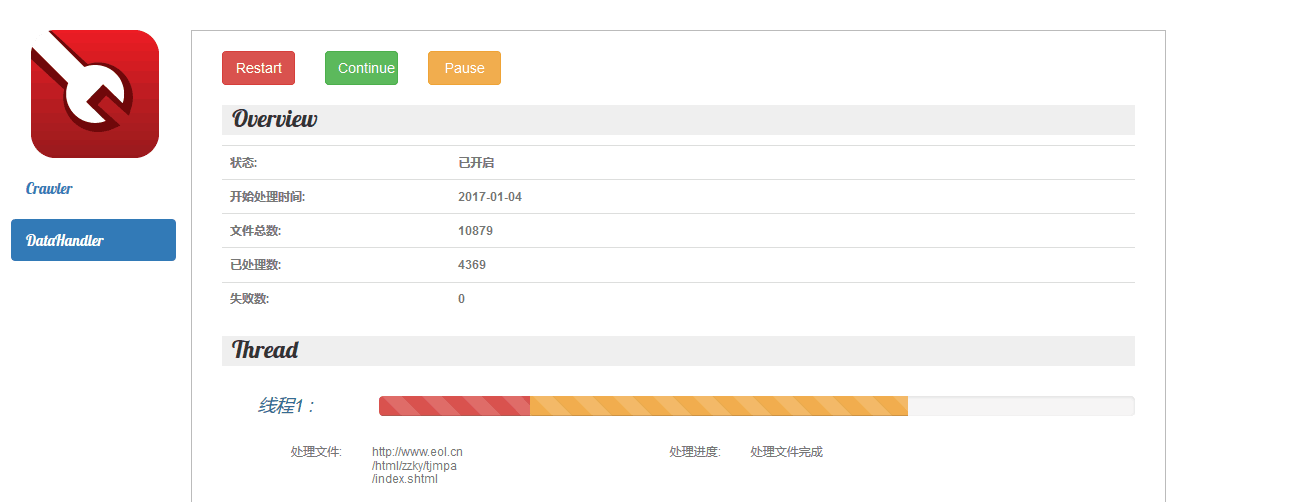
- 无法过滤已爬网站 -> 过滤已爬网站并且可以即时保存
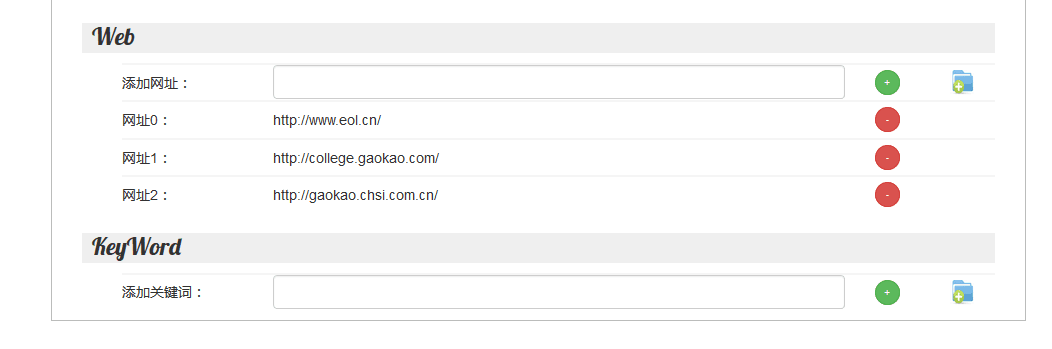
- 爬虫无法停止 -> 支持动态停止以及重启,动态新增种子,同时脱离eclipse运行环境
- 无法爬取word文档、图片等 -> 增加对于word文档、图片爬取的支持
- 中文乱码 -> 中英文支持,并且支持关键词英汉互译
- 两个单独桌面应用 -> 用网页管理的后台应用
- 无法处理问答对 -> 新增对于问答对的专门识别以及处理
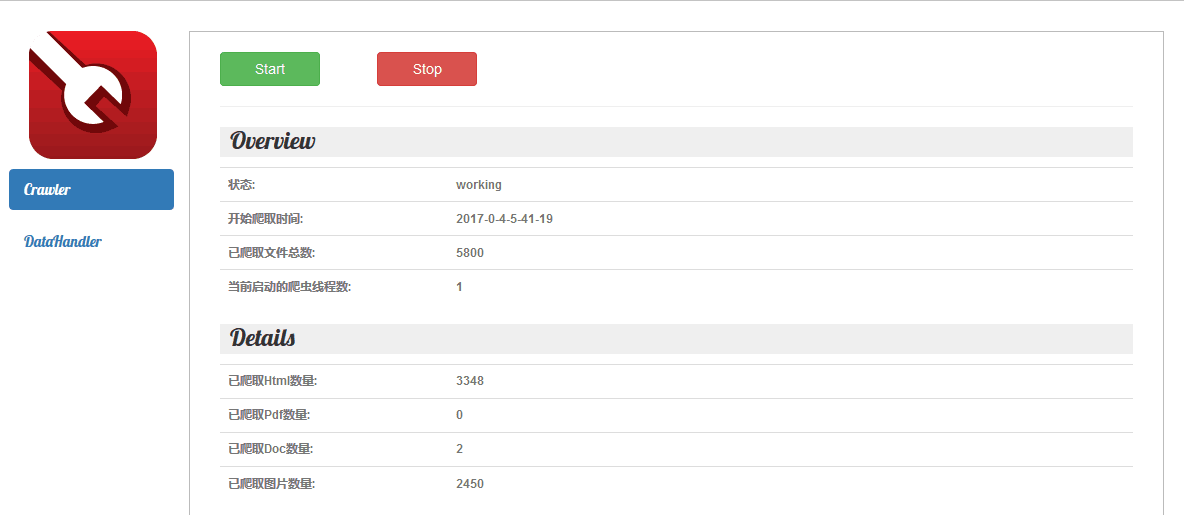
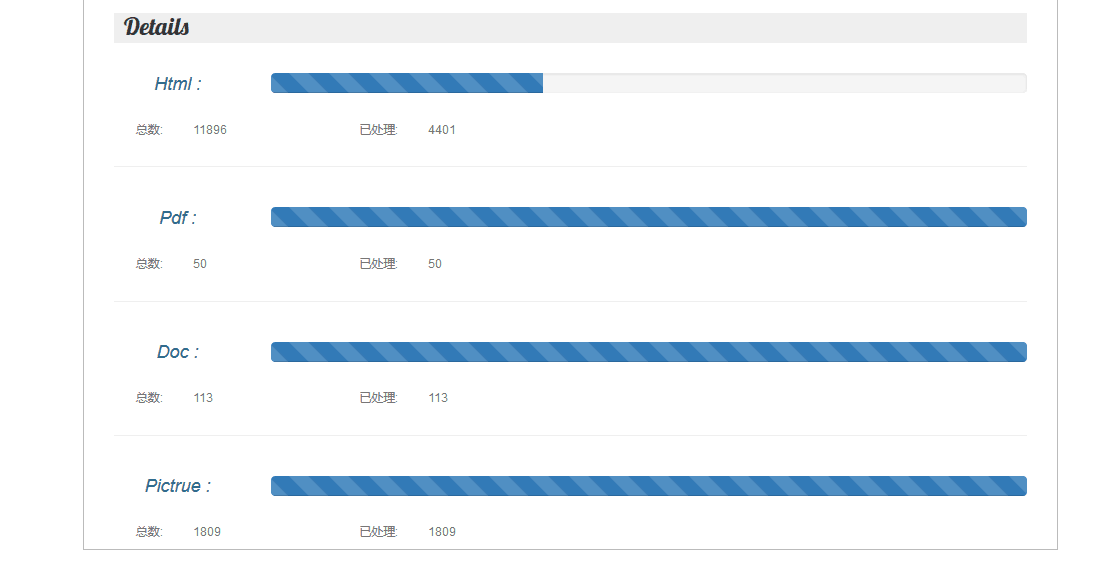
- 数量的累计: 注:以下全部为全新的数据
html:12000
pdf:50
doc:113
image:1800
效果展示

技术亮点
- 交叉编译:在决定用java作为整个程序的核心框架时,为了即满足顶层语言需要,又保留上届劳动成果,使用微软支持更好的C#库类,我们在克服了许多困难之后成功的在程序中使用了很多交叉编译技术。
- 夸服务器交互:因为我们的程序需要跨两个服务器,爬虫与数据库在78,网页以及数据处理在79,所以就涉及到网页对于爬虫程序得控制。最终我们的解决办法是通过特定格式的文件进行爬虫程序的控制以及信息获取。
- 效率改进:为了更直观的说明,可以参考下面的时间对比情况
| 项目 | 改进前 | 改进后 |
|---|---|---|
| 爬虫 | 60-100/h | 1500-2000/h |
| 数据处理 | 1-2min/per | 4-6s/per |
To Do
虽然目前为止我们已经完成了很多的事情,但是仍然有不少的工作是可以后续接着做来让这套系统变得更好的
- 对于cookie的支持还不够完善
- 服务器网络环境的配置使得爬虫顺利运行
- 视频的爬取支持
- 爬虫的关键词筛选
阶段成果
龙威零式_团队项目例会记录_17
龙威零式_团队项目例会记录_18
龙威零式_团队项目例会记录_19
龙威零式_团队项目例会记录_20
龙威零式_团队项目例会记录_21
龙威零式_团队项目例会记录_22
龙威零式_团队项目例会记录_23
龙威零式_团队项目例会记录_24
龙威零式_团队项目例会记录_25
龙威零式_团队项目例会记录_26
龙威零式_团队项目例会记录_27
龙威零式_团队项目例会记录_28
各成员模块接口声明
Beta版本发布说明
Beta版本测试文档
Beta postmortem
学霸数据处理项目之数据处理框架开发者手册
交叉编译总结笔记
TF-IDF算法学习报告
关键词模块部分说明文档
项目管理改进
- 更明确的任务定义
- 更简洁的会议
- 更高效的沟通
- 更多的留存成果
- 更多的成长
收获
- 继往开来
- 耐心加一点点运气
- 软工永远不是一个人的事情