MapReduce对于大数据来说就是一个特别简单的青铜时代,现在我们可能用到的并不多,但是还要学一些,MapReduce用来处理分布式并行计算
对为什么MapReduce被淘汰想了解一些的可以看以下这个 mapreduce为什么被淘汰了?
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种。
简单说MapReduce就是Map 和 Reduce 。 Map就是吧东西分开 Reduce就是把东西合起来 。
拿武侠小说打个比喻,一个人学会一项技能Map,这个技能能够将自己分成无数份,这无数份自己去分开去世界各地学习知识,最后在一个时间节点,所有的分身再通过Reduce技能将每个自己进行融合,获取知识
MapReduce 拥有两个阶段 ,可以理解为这样一个过程,也就是键值对转化的过程(<K1,V1> -> (map) <K2,V2>->(reduce)<K3,V3>)(输入通过TextInputForma进行处理,把每一行转换成键值对)
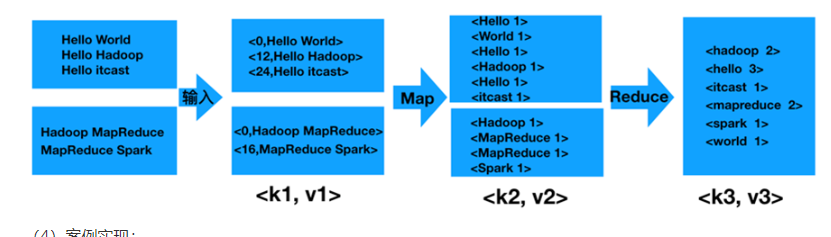
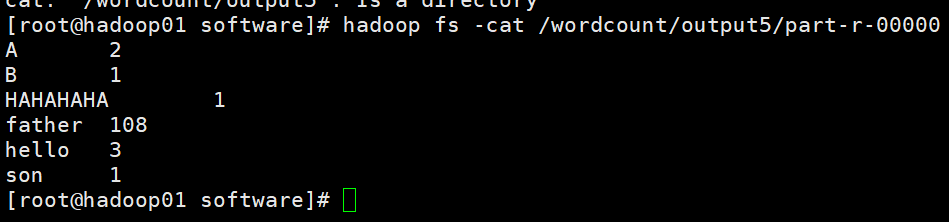
经典案例一:词频统计
(第一次的时候我们也做过一个词频统计,就是108个爸爸和1个儿子的故事,看看这次的统计与上次的词频统计有啥相同有啥不同)
流程就是那么个流程 就上面那个
map对单词进行切割(从源数据文件中逐行读取数据,然后将每一行数据切分成单词,再将单词构造成键值对,最后把键值对发送给reduce)
reduce在将相同的合并(reduce接收键值对,将相同键值汇聚,同时对累加求和,再将键值对输出到HDFS文件中)
这个0 12 24 是偏移量

1.首先在eclipse建一个maven文件(不会的看这个配置 新建maven文件)
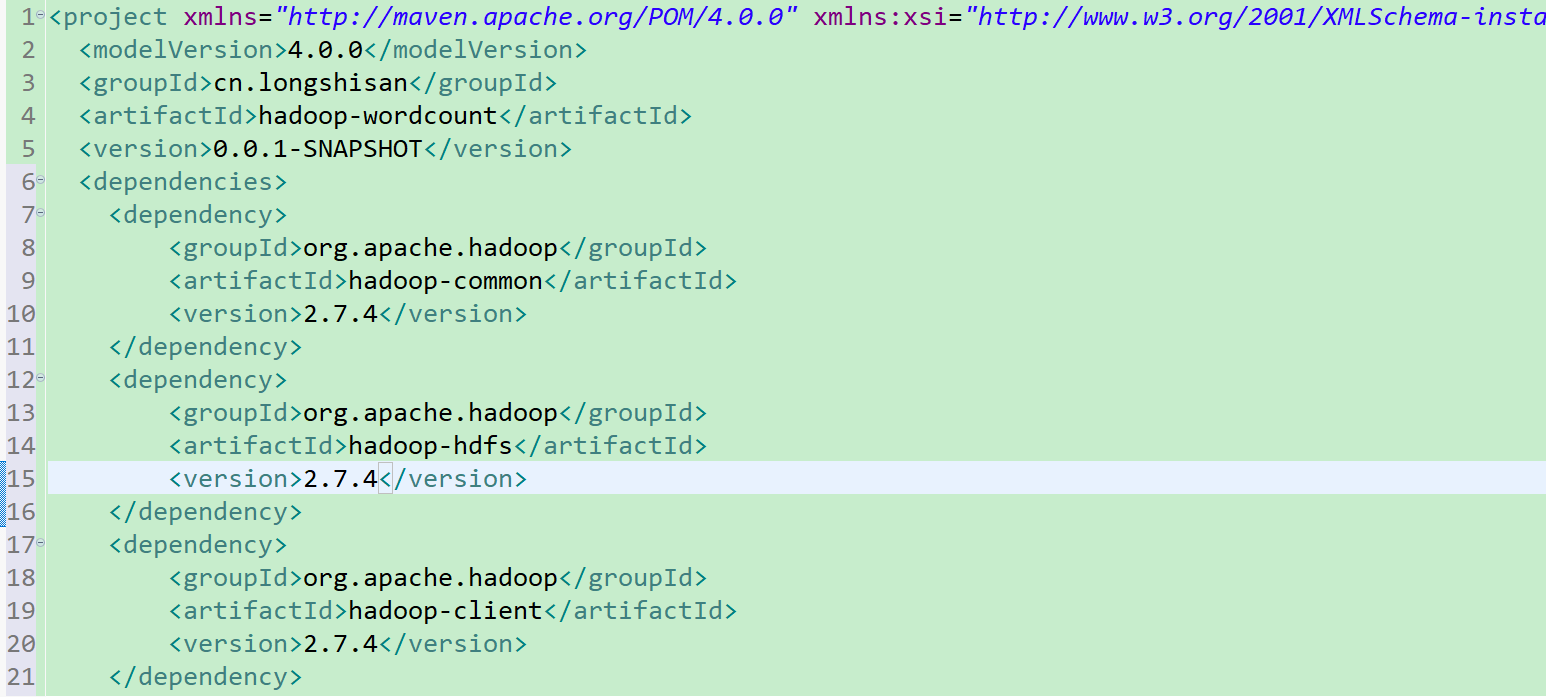
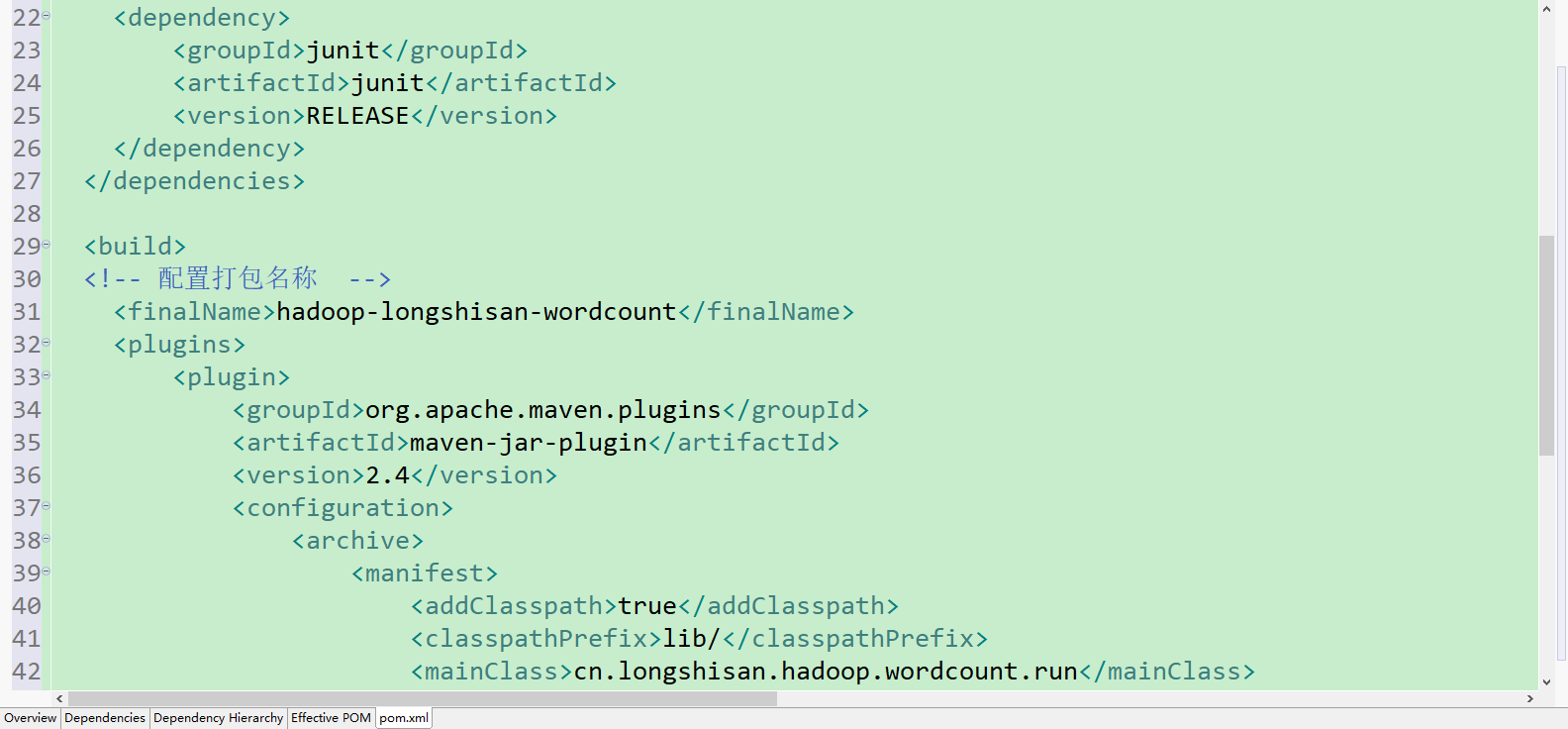
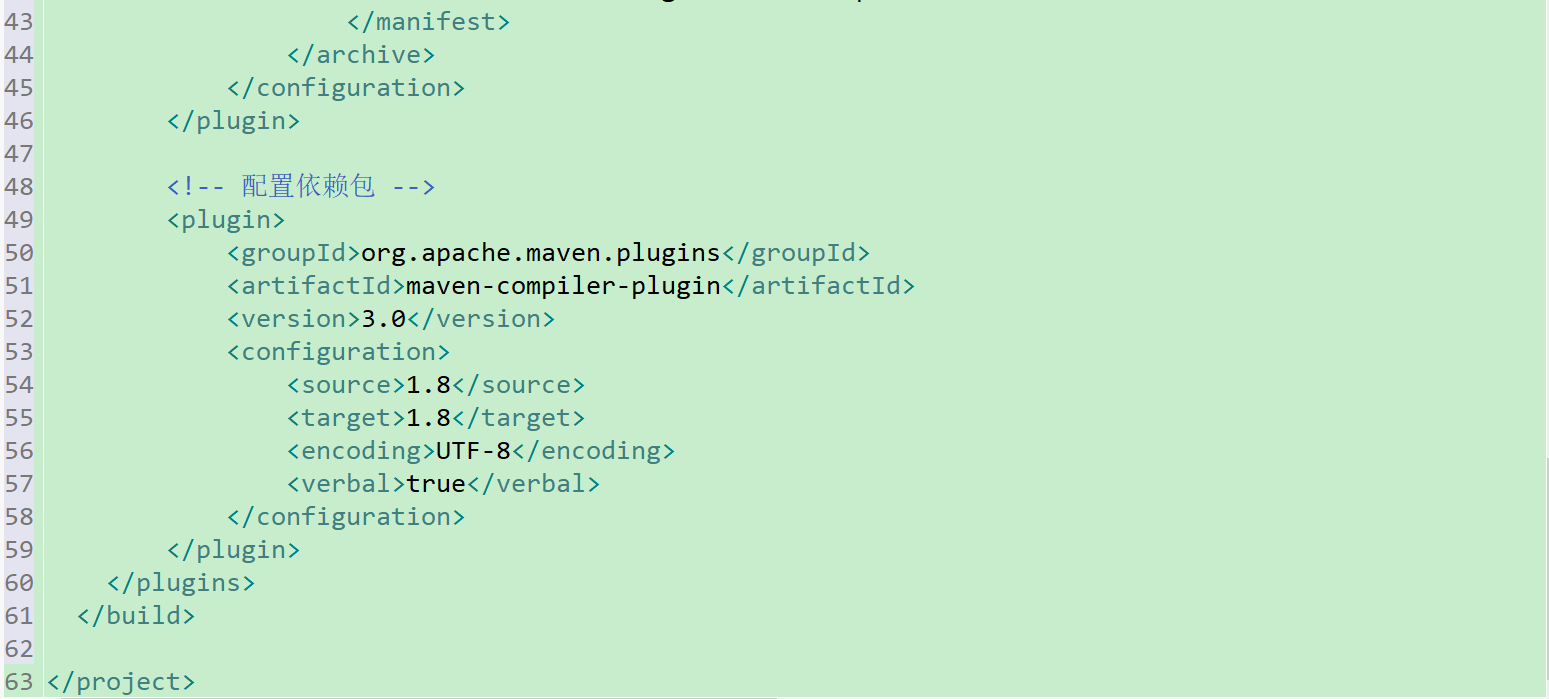
2.建完maven文件之后当然是写配置文件啦,前面还是和上一个项目一样,不一样的地方是这次我们要打成jar包,所以在后面追加了一些配置代码(注意注释代码不是用//,而是用的<!---->)
(看不懂pom文件中标签啥意思? 可以看看这位大佬的解释 Maven-pom-configuration 还可以看看这个加深理解打包 maven打包详情)、
pom.xml代码详情 (在下面标红的地方是下面我们要建的类中的一个,驱动类)(junit是单元测试的jar包)
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.longshisan</groupId>
<artifactId>hadoop-wordcount</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<!-- 配置打包名称 -->
<finalName>hadoop-longshisan-wordcount</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>cn.longshisan.hadoop.wordcount.Run</mainClass>
</manifest>
</archive>
</configuration>
</plugin>
<!-- 配置依赖包 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
<verbal>true</verbal>
</configuration>
</plugin>
</plugins>
</build>
</project>
注:看了一个打包的的解释

3.接下来我们要写一个mapper类,这个类继承Mapper这个类,把它泛型具体化一下
建立一个
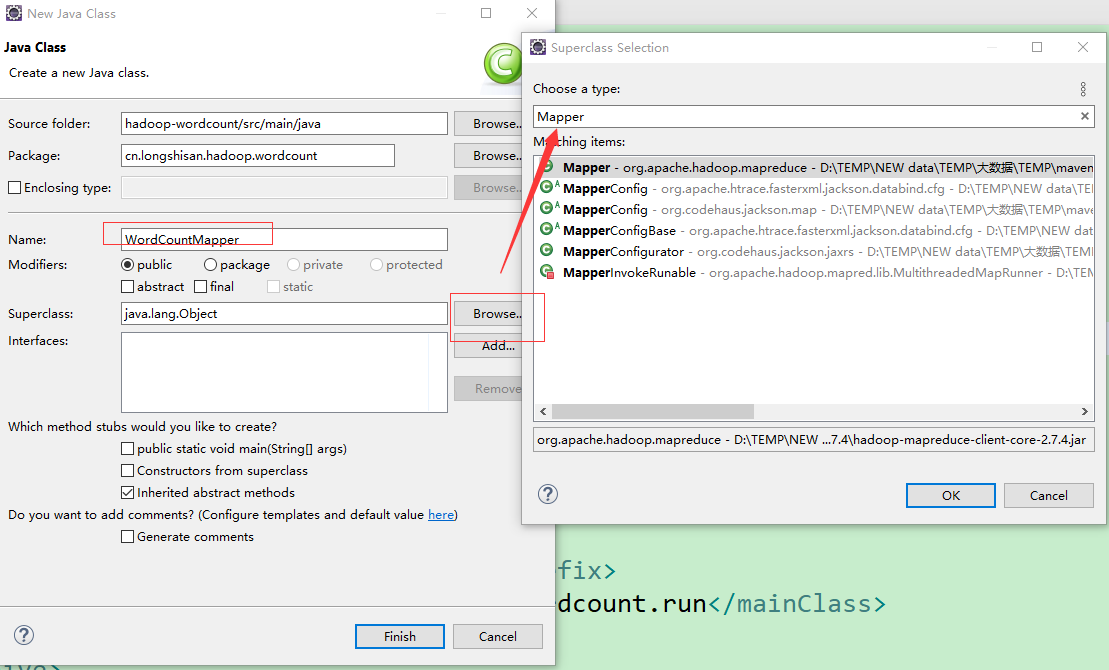

接下来按shift+alt+s 选择这个
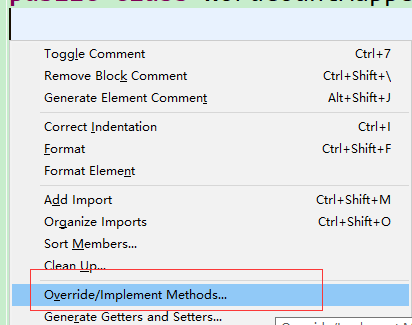
选择map方法
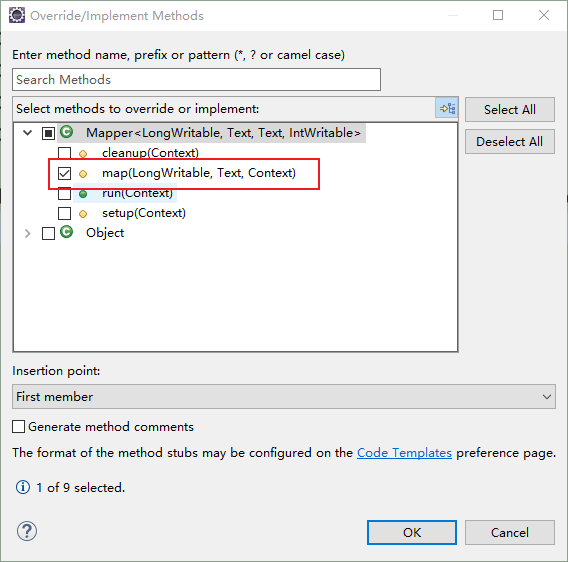
输入:
package cn.longshisan.hadoop.wordcount;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] words = line.split(" ");
for(String word: words) {
context.write(new Text(word),new IntWritable(1));
}
}
}
对15行代码进行解释:创建一个line的string量,来将value的值进行string化
对16行代码进行解释:建立一个string数组,来保存将line通过空格区分的切片的单词
对17行代码进行解释:将words中切片获得单词一个一个拿出来
对18行代码进行解释:将获得的单词用键值对的方式发给reduce(例如这样:<hello,1>)
4.接下来我们要写一个reduce类,这个类继承Reduce这个类,把它泛型具体化一下(具体操作同Map,不再截图)(这个和上面的逻辑挺重要,建议自己打出来)
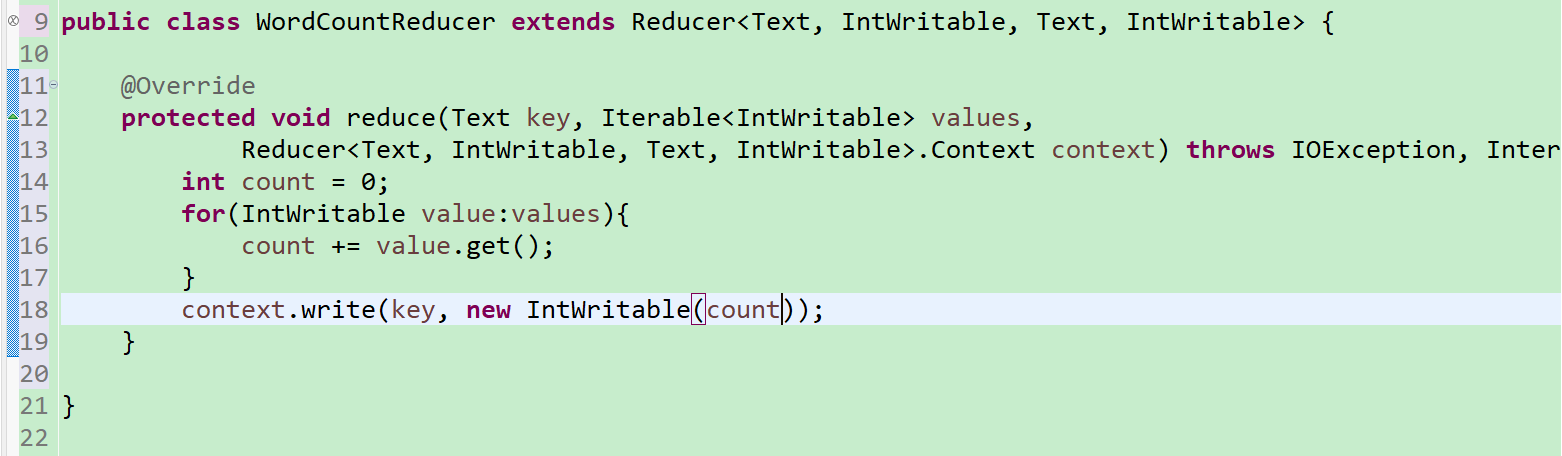
5.接下来我们要写一个Run类,这个类要把那个是mapper,那个是reducer,啥是啥,通过job对象,提交给集群,让集群去运行(也挺简单易懂的吧)
前两句的意思是获取配置信息或者Job对象实例,之后给这个实例设置运行类,Map类,Reduce类,对于前面,告诉啥是啥,下面四行是输入输出,再下面两行是输入文件和输出文件的路径设置,最下面是调用函数执行Job
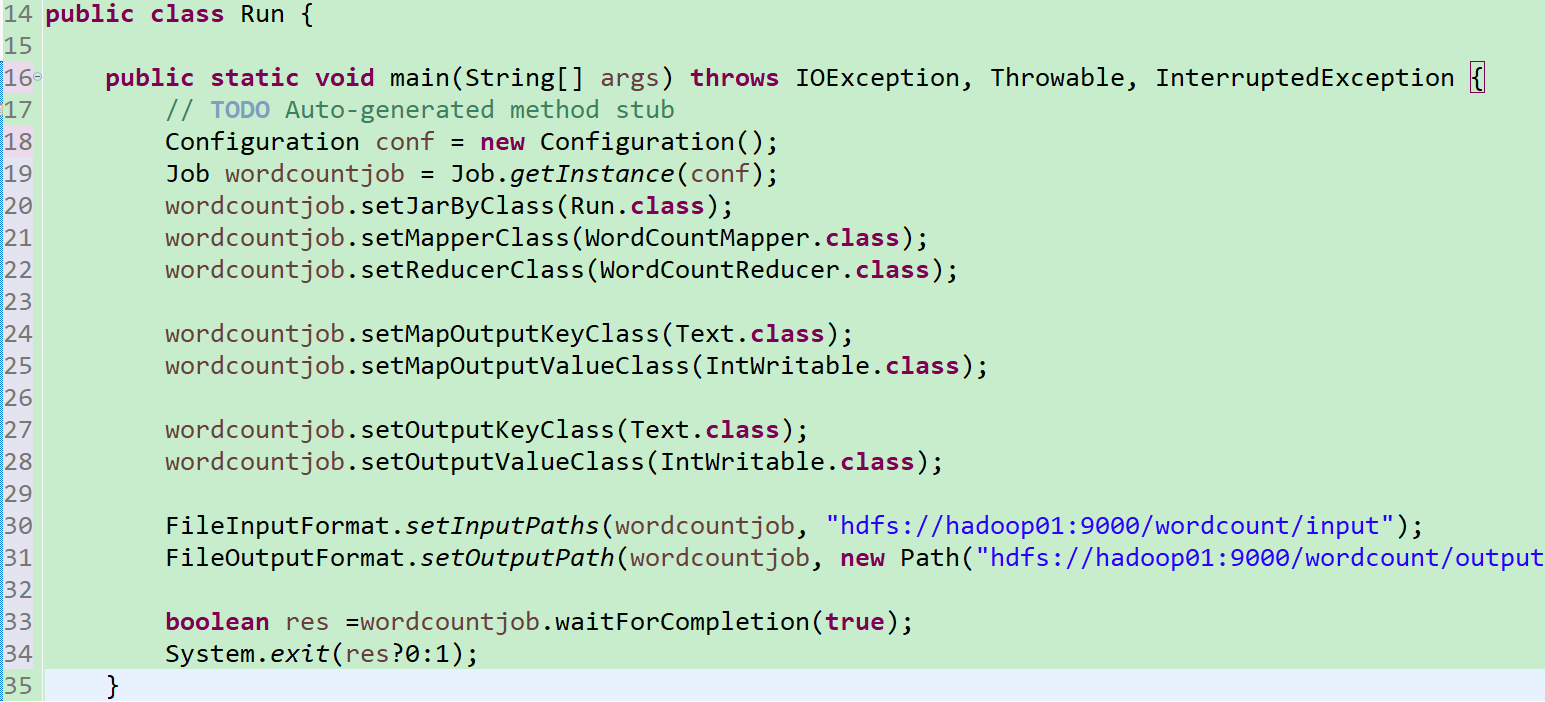
6.将它打成jar包
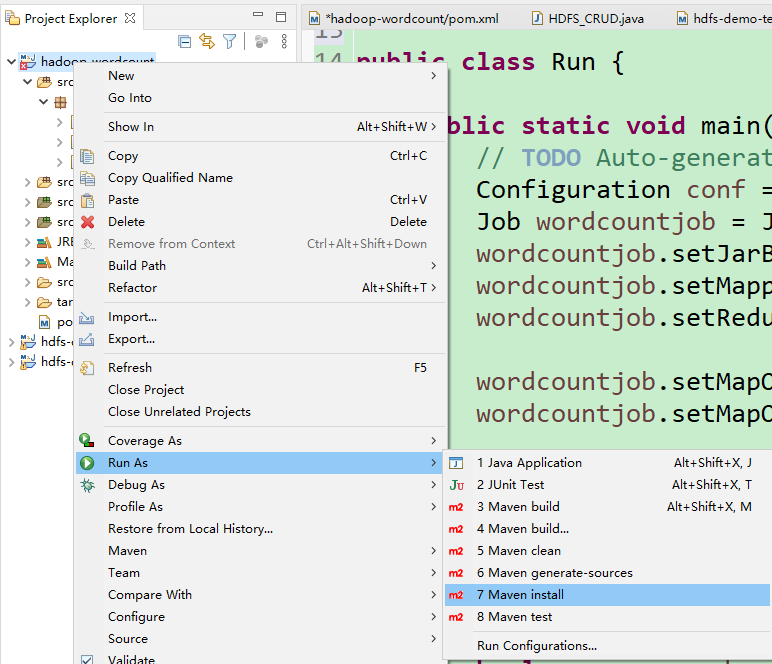
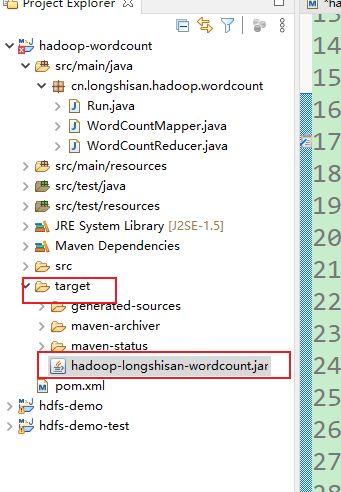
7.jar包都有了,剩下的操作就和第一次一样了,先把jar包传到software下用Xshell
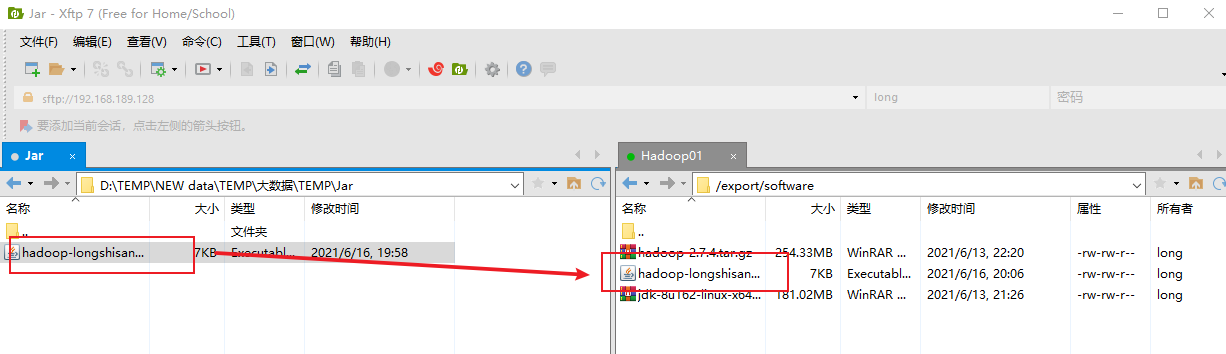

如果wordcount下有output文件夹,记得删掉

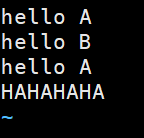
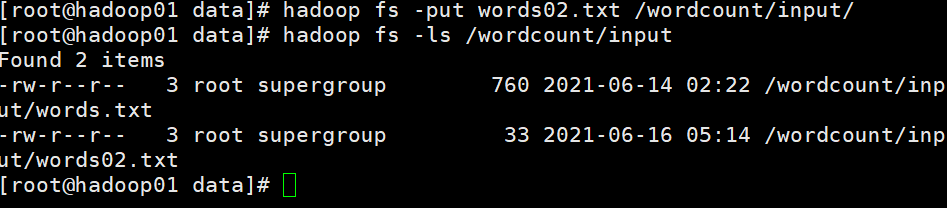
我们再去data下建立一个words02.txt,再把这个文件放在Hadoop的input下,这样就有俩txt文件了,我们再运行一下jar包
再到刚才的jar包路径下就行运行(吐槽一下,这个过程慢了,甚至使我以为失败了。记得关防火墙)

效果:
终于结束了!!!
