1.mysql索引结构b+树
a.首先要说二叉树,二叉查找树,数的结构不用多说,二叉查找树,大概就是几个原则,左边比右边的小,然后保持一个分布均匀,也就是树的高度尽量最小。
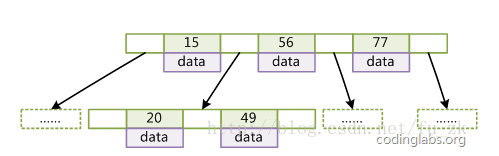
b.b-树,b-树和二叉查找树结构类似,但是每个节(页)点会有多个数据,
c.b+树和b-树最大的区别就是,只有叶子节点存数据。为啥,为了非叶子节点能够存储更多的索引,以便控制树的高度,树的高度决定了io次数,io是非常消耗性能的。
下图b-树
下图b+树
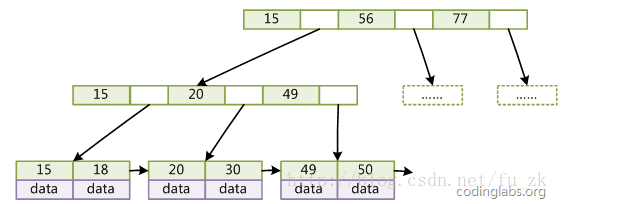
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。范围查找的时候等非常有用。
2.1000万数据的存储结构
在 MySQL 中我们的 InnoDB 页的大小默认是 16k,为16384
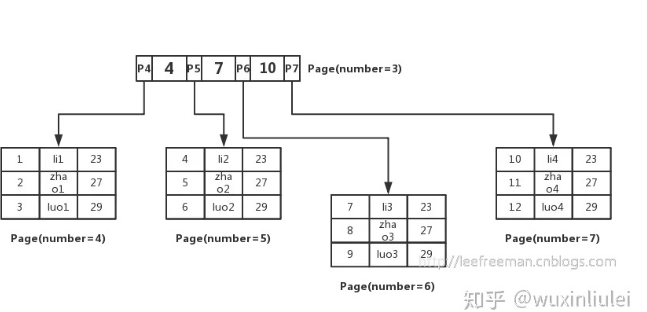
上图只是一个类似图,实际上根节点往往不止这点数据。
一上图2的高度来计算,假设前提是每页装满来算
结论1:根节点能存1170个指针(大概)
一页为16k(16384),我们假设主键 ID 为 bigint 类型,长度为 8 字节,而指针大小在 InnoDB 源码中设置为 6 字节,这样一共 14 字节,我们一个页中能存放多少这样的单元,其实就代表有多少指针,即 16384/14=1170
结论2:一个叶子节点放16行数据
一页为16k,一行用1k来算的行就是16行。
结论3:高度为2的树数据为16*1170
根有1170个指针,一个指针指向一个页,一页有16条数据。
结论4:如果高度为3
1170*1170*13 大概2000w,第一层1170个指针,第二次每个也1170个指针,第三层叶子节点,每页为16行。
mysql不同的存储引擎
https://www.cnblogs.com/tgycoder/p/5410057.html
使用自增主键和uuid
https://blog.csdn.net/chenssy/article/details/108413941
mysql 锁
1.锁分类,表锁,行锁,页锁;共享锁,排他锁;乐观锁,悲观锁
2.innodb在增删改的时候回加上行锁,mysiam不会死锁,表级锁,查询的时候如果有索引会加上锁,如果每页条件,表级锁。
3.死锁。因为innodb的锁是分步获取的,比如事务a中,先获取id=1的数据,然后在获取id=2的数据;b事务中,先获取id=2,然后在获取id=1的数据。a,b事务会分别等待对方释放锁。
4. MVCC.MySQL InnoDB存储引擎,实现的是基于多版本并发控制协议—MVCC(Multi-Version Concurrency Control) MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突
https://blog.csdn.net/qq_38238296/article/details/88362999
1. 优化sql语句;
原则: 1.1 尽量根据主键查询;
1.2 尽量使用单表查询,不要使用关联查询;
1.3 查询时可以使用in,但是绝对不要使用not in;
2. 创建索引;CREATE INDEX 索引名字 ON 表名称 (列名称);[列名称:规定你需要索引的列]。
3. 添加缓存;
例如:mybatis的一、二级缓存;该操作效率低;
redis缓存 / memercache缓存(String);有效的缓解数据库的压力;
4. 使用数据库的读写分离;
5. 定期将历时数据进行转储;
6. 进行分库分表操作(最后的操作);数据库服务器数量和运维都需要花费很多时间和精力
7. 数据库引擎选择