分析函数cube和rollup魅力
首先请看下面例子
1)创建表
create table group_test (group_id int, job varchar2(10), name varchar2(10), salary int);
2)初始化表
insert into group_test values (10,'Coding', 'Bruce',1000);
insert into group_test values (10,'Programmer','Clair',1000);
insert into group_test values (10,'Architect', 'Gideon',1000);
insert into group_test values (10,'Director', 'Hill',1000);
insert into group_test values (20,'Coding', 'Jason',2000);
insert into group_test values (20,'Programmer','Joey',2000);
insert into group_test values (20,'Architect', 'Martin',2000);
insert into group_test values (20,'Director', 'Michael',2000);
insert into group_test values (30,'Coding', 'Rebecca',3000);
insert into group_test values (30,'Programmer','Rex',3000);
insert into group_test values (30,'Architect', 'Richard',3000);
insert into group_test values (30,'Director', 'Sabrina',3000);
insert into group_test values (40,'Coding', 'Samuel',4000);
insert into group_test values (40,'Programmer','Susy',4000);
insert into group_test values (40,'Architect', 'Tina',4000);
insert into group_test values (40,'Director', 'Wendy',4000);
commit;
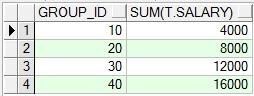
select t.group_id, sum(t.salary) from group_test t group by t.group_id order by 1;
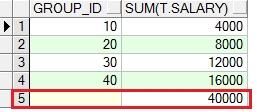
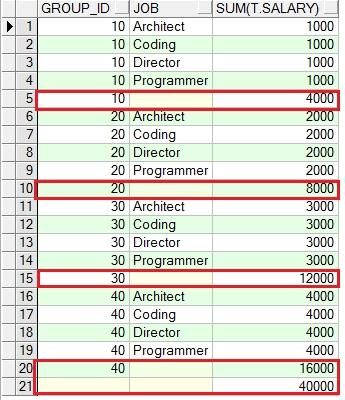
select t.group_id, sum(t.salary) from group_test t group by rollup(t.group_id)order by 1;
4)查看cube函数
select t.group_id, sum(t.salary) from group_test t group by cube(t.group_id)order by 1;
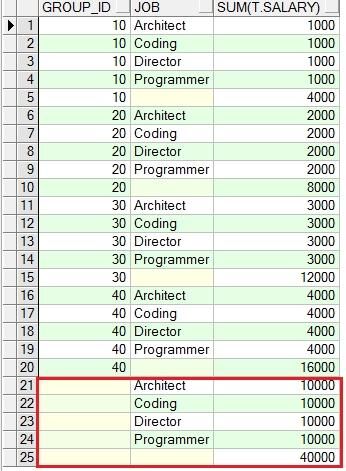
仔细观察两个函数的细微差别
rollup(a,b) 统计列包含:(a,b)、(a)、()
rollup(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a)、()
……以此类推ing……
cube(a,b) 统计列包含:(a,b)、(a)、(b)、()
cube(a,b,c) 统计列包含:(a,b,c)、(a,b)、(a,c)、(b,c)、(a)、(b)、(c)、()
……以此类推ing……
替换成原始的group by字句实际就是union all了不区分ID的一个小汇总。