










1 # Author Qian Chenglong 2 #label 特征的名字 dataSet n个特征+目标 3 4 5 from math import log 6 import operator 7 8 9 '''计算香农熵''' 10 def calcShannonEnt(dataSet): 11 numEntries=len(dataSet) 12 labelCounts={} 13 for featVec in dataSet:#将数据放入字典中,并计算字典中label出现的次数 14 currentLabel=featVec[-1] 15 if currentLabel not in labelCounts.keys(): 16 labelCounts[currentLabel]=0 17 labelCounts[currentLabel]+=1 18 shannonEnt=0.0 19 for key in labelCounts: 20 porb=float(labelCounts[key])/numEntries #每一个label出现的概率 21 shannonEnt-=porb*log(porb,2) 22 return shannonEnt 23 '''熵越高数据越混乱''' 24 25 '''按照指定特征划分数据集''' 26 def splitDataSet(dataSet,axis,value):#待划分数据集,划分数据集的特征的下标,特征的值 27 retDataSet=[] 28 for featVec in dataSet: 29 if featVec[axis]==value: 30 reducedFeatVec=featVec[:axis] #取出除划分依据用的特征以外的值 31 reducedFeatVec.extend(featVec[axis+1:]) 32 retDataSet.append(reducedFeatVec) 33 return retDataSet 34 '''把指定特征的数据取出来''' 35 36 '''遍历所有特征,选择熵最小的划分方式''' 37 def chooseBestFeatureToSplit(dataSet): 38 numFeatures=len(dataSet[0])-1 #获取属性个数,最后一列为label所以-1 39 baseEntropy=calcShannonEnt(dataSet) #数据集的原始熵 40 bestInfoGain=0.0;bestFeature=-1 41 for i in range(numFeatures): 42 featList=[example[i] for example in dataSet] #遍历当前特征的所有属性生成一个列表 i为特征下标 43 uniqueVals=set(featList) #创建一个集合,集合会删除重复的内容 44 newEntropy=0.0 45 for value in uniqueVals: #遍历当前特征的所有值 46 subDataSet=splitDataSet(dataSet,i,value) 47 prob=len(subDataSet)/float(len(dataSet)) 48 newEntropy+=prob*calcShannonEnt(subDataSet) #计算新的熵 49 infoGain=baseEntropy-newEntropy #baseEntropy-newEntropy求熵减,即信息增益 50 if(infoGain>bestInfoGain): 51 bestInfoGain=infoGain 52 bestFeature=i 53 return bestFeature 54 55 '''出现最多的目标及其次数''' 56 def majorityCnt(classList): 57 classCount={} 58 for vote in classList: 59 if vote not in classCount.keys(): 60 classCount[vote]=0 61 classCount[vote]+=1 62 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)#reverse = True 降序 , reverse = False 升序(默认) 63 return sortedClassCount[0][0] 64 65 def createTree(dataSet,labels): 66 classList = [example[-1] for example in dataSet] #目标的列表 67 if classList.count(classList[0]) == len(classList): #所有类别都相同,即只有1个目标 68 return classList[0] #停止继续划分 69 if len(dataSet[0]) == 1: # 用完了所有特征,即只剩最后一个“目标”的时候,遍历完所有实例返回出现次数最多的类别 70 return majorityCnt(classList) 71 bestFeat = chooseBestFeatureToSplit(dataSet) 72 bestFeatLabel = labels[bestFeat] 73 myTree = {bestFeatLabel:{}} #以标签作为关键字创建树 74 del(labels[bestFeat]) #删除已使用的标签 75 featValues = [example[bestFeat] for example in dataSet] 76 uniqueVals = set(featValues) 77 for value in uniqueVals: 78 subLabels = labels[:] #copy all of labels, so trees don't mess up existing labels 79 myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels) 80 return myTree 81 82 '''获取叶节点数目''' 83 def getNumLeafs(myTree): 84 numLeafs=0 85 firstStr=myTree.keys()[0] 86 secondDict=myTree[firstStr] 87 for key in secondDict.keys(): 88 if type(secondDict[key]).__name__=='dict': 89 numLeafs+=getNumLeafs(secondDict[key]) 90 else: numLeafs+=1 91 return numLeafs 92 93 '''获取树的层数''' 94 def getTreeDepth(myTree): 95 maxDepth=0 96 firstStr=myTree.key()[0] 97 secondDict=myTree[firstStr] 98 for key in secondDict.keys(): 99 if type(secondDict[key]).__name__=='dict': 100 thisDepth=1+getTreeDepth(secondDict[key]) 101 else: thisDepth=1 102 if thisDepth>maxDepth: 103 maxDepth=thisDepth 104 return maxDepth 105 106 '''使用决策树的分类函数''' 107 def classify(inputTree,featLabels,testVec): 108 firstStr = inputTree.keys()[0] #字典中的第一个key 109 secondDict = inputTree[firstStr] #第二层字典 110 featIndex = featLabels.index(firstStr) 111 key = testVec[featIndex] 112 valueOfFeat = secondDict[key] 113 if isinstance(valueOfFeat, dict): 114 classLabel = classify(valueOfFeat, featLabels, testVec) 115 else: classLabel = valueOfFeat 116 return classLabel 117 118 '''存储树''' 119 def storeTree(inputTree,filename): 120 import pickle 121 fw = open(filename,'w') 122 pickle.dump(inputTree,fw) 123 fw.close() 124 125 '''加载树''' 126 def grabTree(filename): 127 import pickle 128 fr = open(filename) 129 return pickle.load(fr)
样本内容:
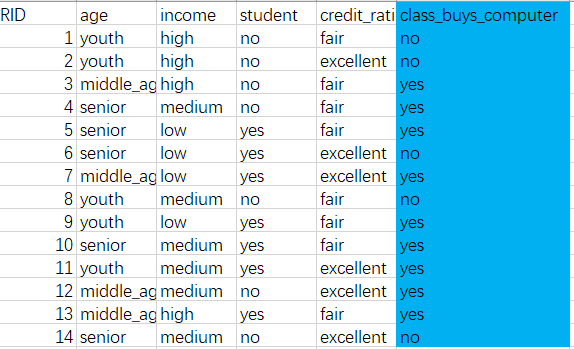
1 from sklearn.feature_extraction import DictVectorizer #sklearn是一个机器学习库 2 import csv #处理csv文件的库 3 from sklearn import tree 4 from sklearn import preprocessing 5 from sklearn.externals.six import StringIO 6 7 # Read in the csv file and put features into list of dict and list of class label 8 allElectronicsData = open('C:/Users/qianc/Desktop/EndNote/AllElectronics.csv','r') 9 reader = csv.reader(allElectronicsData) #读取文件的地址 10 #headers = reader.next() python3.2版本之前的写法 11 headers = next(reader) #读取第一行数据 12 13 # print(reader) 14 # print(headers) 15 16 featureList = [] 17 labelList = [] 18 19 '''数据预处理''' 20 for row in reader: 21 labelList.append(row[len(row)-1]) #取出标签列(最后一列) 22 rowDict = {} 23 for i in range(1, len(row)-1): 24 rowDict[headers[i]] = row[i] 25 featureList.append(rowDict) 26 '''数据预处理''' 27 28 # print(featureList) 29 30 '''将特征文本数据自动转化成数值数据''' 31 vec = DictVectorizer() 32 dummyX = vec.fit_transform(featureList) .toarray() 33 '''将文本数据自动转化成数值数据''' 34 35 # print("dummyX: " + str(dummyX)) 36 # print(vec.get_feature_names()) 37 38 # print("labelList: " + str(labelList)) 39 40 '''将标签文本数据自动转化成数值数据''' 41 lb = preprocessing.LabelBinarizer() 42 dummyY = lb.fit_transform(labelList) 43 '''将标签文本数据自动转化成数值数据''' 44 #print("dummyY: " + str(dummyY)) 45 46 47 '''创建分类器''' 48 # # clf = tree.DecisionTreeClassifier() 默认形式,选择基尼指数作为分类标准 49 clf = tree.DecisionTreeClassifier(criterion='entropy') #选择信息熵作为分类标准 50 clf = clf.fit(dummyX, dummyY) 51 # print("clf: " + str(clf)) 52 # 53 # 54 '''画出决策树''' 55 with open("C:/Users/qianc/Desktop/EndNote/allElectronicInformationGainOri.dot", 'w') as f: 56 f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f) #feature_names=vec.get_feature_names()把之前转化的数据还原回去 57 58 '''新数据 newRowX 的预测''' 59 predictedY = clf.predict(newRowX) 60 print("predictedY: " + str(predictedY))