# Numbers数字分为:int整型,long长整型,float浮点型,complex复数 x1 = 10 x2 = 10.0 print(type(x1),type(x2)) # print()函数,用于输出/打印内容 # type()函数,用于查看数据类型
1、列表(相当于数组)
#创建列表 name_list = ['alex', 'seven', 'eric'] #或 name_list = list(['alex', 'seven', 'eric']) #访问列表里的数据 print(name_list[0])
# 判断值是否属于序列 lst = [1,2,3,4,5,6] a,b = 1,10 print(a in lst) # a 在 lst 序列中 , 如果 x 在 y 序列中返回 True。 print(b not in lst) # b 不在 lst 序列中 , 如果 x 不在 y 序列中返回 True。
# 序列链接与重复 lst1 = [1,2,3] lst2 = ['a','b','c'] print(lst1+lst2) # "+":序列的链接 print(lst1*3,lst2*2) # "*":序列重复
# 步长 lst = [1,2,3,4,5,6,7,8,9,0] print(lst[0:5:2]) # List[i:j:n]代表:索引i - 索引j,以n为步长 print(lst[::2]) # 按照2为步长,从第一个值开始截取lst数据 print(lst[1::2]) # 按照2为步长,从第二个值开始截取lst数据
# 列表与生成器 print(range(5),type(range(5))) # range()是生成器,指向了一个范围 # range(5)代表指向了0,1,2,3,4这几个值 # range(2,5)代表指向了2,3,4这几个值,注意这里不是使用: # range(0,10,2)代表指向了0,2,4,6,8这几个值,最后的2代表步长 lst = list(range(5)) print(lst) # 通过list()函数生成列表
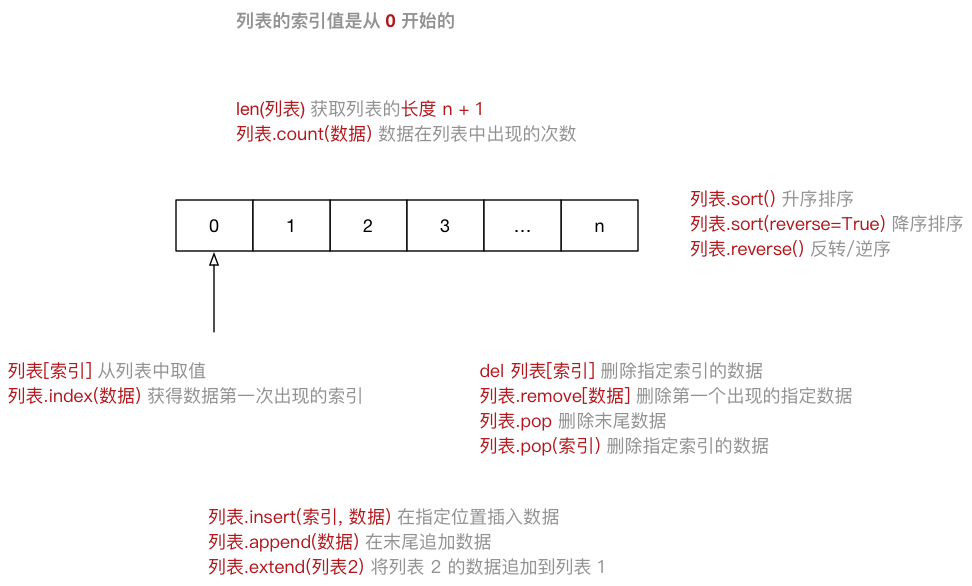
对列表进行切片处理
1)列出所有的元素
>>> names[::]
['&&', 'a', 'b', 'd', 'devilf', 'lebron', 'beijing', 'shandong', 'usa']
2)列出最后一个元素,从中间位置开始,列出后面所有的元素
>>> names[-1]
'usa'
>>> a = int(len(names)/2)
>>> names[a:]
['devilf', 'lebron', 'beijing', 'shandong', 'usa']
复制:copy()
>>> names.copy()
['&&', 'a', 'b', 'd', 'devilf', 'lebron', 'beijing', 'shandong', 'usa']
另外的几种复制的方法:
>>> info = ['name',['a',100]]
>>> n1 = copy.copy(info)
>>> n2 = info[:]
>>> n3 = list(info)
在使用copy.copy()时,需要导入copy模块
这些均是浅copy
例如:

>>> info
['name', ['a', 100]]
>>> n1 = info[:]
>>> n2 = copy.copy(info)
>>> n1
['name', ['a', 100]]
>>> n1[0] = 'devilf'
>>> n2[0] = 'lebron'
>>> n1;n2
['devilf', ['a', 100]]
['lebron', ['a', 100]]
>>> n1[1][1] = 80
>>> n1
['devilf', ['a', 80]]
>>> n2
['lebron', ['a', 80]]
这里可以看到修改n1列表中的值,n2中的值也会跟着改变,这就是浅copy,也就是说,浅copy会复制原列表的内存地址,也就是说,我们修改了n1和n2,就是修改了指向同一内存地址的对象,所以info列表会变化,n1和n2都会变化,例如:
>>> info
['name', ['a', 80]]
应用场景
尽管 Python 的 列表 中可以 存储不同类型的数据,但是在开发中,更多的应用场景是
- 列表 存储相同类型的数据
- 通过 迭代遍历,在循环体内部,针对列表中的每一项元素,执行相同的操作
2、元组
元组一旦创建就不可修改 ,只可读取(因此又叫只读列表)操作有
1、索引 ;2、切片;3、连接;4、重复
1 ages = (11, 22, 33, 44, 55) 2 #或 3 ages = tuple((11, 22, 33, 44, 55))

应用场景
尽管可以使用 for in 遍历 元组 但是在开发中,更多的应用场景是:
- 函数的 参数 和 返回值,一个函数可以接收 任意多个参数,或者 一次返回多个数据
- 格式字符串,格式化字符串后面的 () 本质上就是一个元组
让列表不可以被修改,以保护数据安全
info = ("zhangsan", 18)
print("%s 的年龄是 %d" % info)
3、字典(无序)

person = {"name": "mr.wu", 'age': 18} #或 person = dict({"name": "mr.wu", 'age': 18})
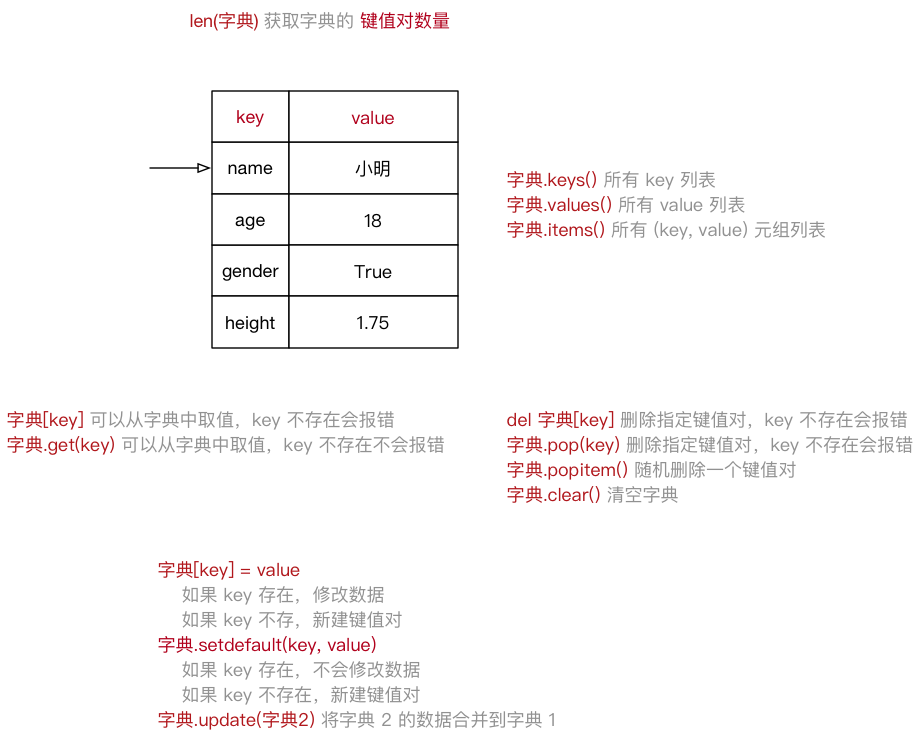
应用场景
尽管可以使用 for in 遍历 字典,但是在开发中,更多的应用场景是:
- 使用 多个键值对,存储 描述一个 物体 的相关信息 —— 描述更复杂的数据信息
- 将 多个字典 放在 一个列表 中,再进行遍历,在循环体内部针对每一个字典进行 相同的处理
card_list = [{"name": "张三",
"qq": "12345",
"phone": "110"},
{"name": "李四",
"qq": "54321",
"phone": "10086"}
]
# 字典的元素遍历 poi = {'name':'shop', 'city':'shanghai', 'information':{'address':'somewhere', 'num':66663333}} for key in poi.keys(): print(key) print('-------') for value in poi.values(): print(value) print('-------') for (k,v) in poi.items(): print('key为 %s, value为 %s' %(k,v)) print('-------') # for函数遍历
4、字符串

1) 判断类型
string.isspace() 如果 string 中只包含空格,则返回 True
string.isalnum() 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True
string.isalpha() 如果 string 至少有一个字符并且所有字符都是字母则返回 True
string.isdecimal() 如果 string 只包含数字则返回 True,全角数字
string.isdigit() 如果 string 只包含数字则返回 True,全角数字、⑴、\u00b2
string.isnumeric() 如果 string 只包含数字则返回 True,全角数字,汉字数字
string.istitle() 如果 string 是标题化的(每个单词的首字母大写)则返回 True
string.islower() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True
string.isupper() 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True
2) 查找和替换
string.startswith(str) 检查字符串是否是以 str 开头,是则返回 True
string.endswith(str) 检查字符串是否是以 str 结束,是则返回 True
string.find(str, start=0, end=len(string)) 检测 str 是否包含在 string 中,如果 start 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回 -1
string.rfind(str, start=0, end=len(string)) 类似于 find(),不过是从右边开始查找
string.index(str, start=0, end=len(string)) 跟 find() 方法类似,不过如果 str 不在 string 会报错
string.rindex(str, start=0, end=len(string)) 类似于 index(),不过是从右边开始
string.replace(old_str, new_str, num=string.count(old)) 把 string 中的 old_str 替换成 new_str,如果 num 指定,则替换不超过 num 次
3) 大小写转换
string.capitalize() 把字符串的第一个字符大写
string.title() 把字符串的每个单词首字母大写
string.lower() 转换 string 中所有大写字符为小写
string.upper() 转换 string 中的小写字母为大写
string.swapcase() 翻转 string 中的大小写
4) 文本对齐
string.ljust(width) 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串
string.rjust(width) 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串
string.center(width) 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串
5) 去除空白字符
string.lstrip() 截掉 string 左边(开始)的空白字符
string.rstrip() 截掉 string 右边(末尾)的空白字符
string.strip() 截掉 string 左右两边的空白字符
6) 拆分和连接
string.partition(str) 把字符串 string 分成一个 3 元素的元组 (str前面, str, str后面)
string.rpartition(str) 类似于 partition() 方法,不过是从右边开始查找
string.split(str="", num) 以 str 为分隔符拆分 string,如果 num 有指定值,则仅分隔 num + 1 个子字符串,str 默认包含 '\r', '\t', '\n' 和空格
string.splitlines() 按照行('\r', '\n', '\r\n')分隔,返回一个包含各行作为元素的列表
string.join(seq) 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
num_str = "0123456789" # 1. 截取从 2 ~ 5 位置 的字符串 print(num_str[2:6]) # 2. 截取从 2 ~ `末尾` 的字符串 print(num_str[2:]) # 3. 截取从 `开始` ~ 5 位置 的字符串 print(num_str[:6]) # 4. 截取完整的字符串 print(num_str[:]) # 5. 从开始位置,每隔一个字符截取字符串 print(num_str[::2]) # 6. 从索引 1 开始,每隔一个取一个 print(num_str[1::2]) # 倒序切片 # -1 表示倒数第一个字符 print(num_str[-1]) # 7. 截取从 2 ~ `末尾 - 1` 的字符串 print(num_str[2:-1]) # 8. 截取字符串末尾两个字符 print(num_str[-2:]) # 9. 字符串的逆序(面试题) print(num_str[::-1])
切片的注意:
指定的区间属于 左闭右开 型 [开始索引, 结束索引) ,从 起始 位开始,到 结束位的前一位 结束(不包含结束位本身)
# 格式化字符:数字格式化的那些坑 m = 3.1415926 print("pi is %f" %m) print("pi is %.2f" %m) # 我只想输出2位小数:%.2f,此处是四舍五入! m = 10.6 print("pi is %i" %m) print("pi is %.0f" %m) # 区别:%i 不四舍五入,直接切掉小数部分 m = 100 print("have fun %+i" %m) print("have fun %.2f" % -0.01) # 显示正号,负号根据数字直接显示 m = 100 print("have fun % i" %m) print("have fun % +i" %m) print("have fun % .2f" %-0.01) # 加空格,空格和正好只能显示一个 m = 123.123123123 print("have fun %.2e" %m) print("have fun %.4E" %m) # 科学计数法 %e %E m1 = 123.123123123 m2 = 1.2 print("have fun %g" %m1) print("have fun %g" %m2) # 小数位数少的时候自动识别用浮点数,数据复杂的时候自动识别用科学计数法
5、数据运算

比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

*按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265
运算符优先级:

详见:http://www.runoob.com/python/python-operators.html