讲准备好的文本文件放到hdfs中

执行 hadoop 安装包中的例子
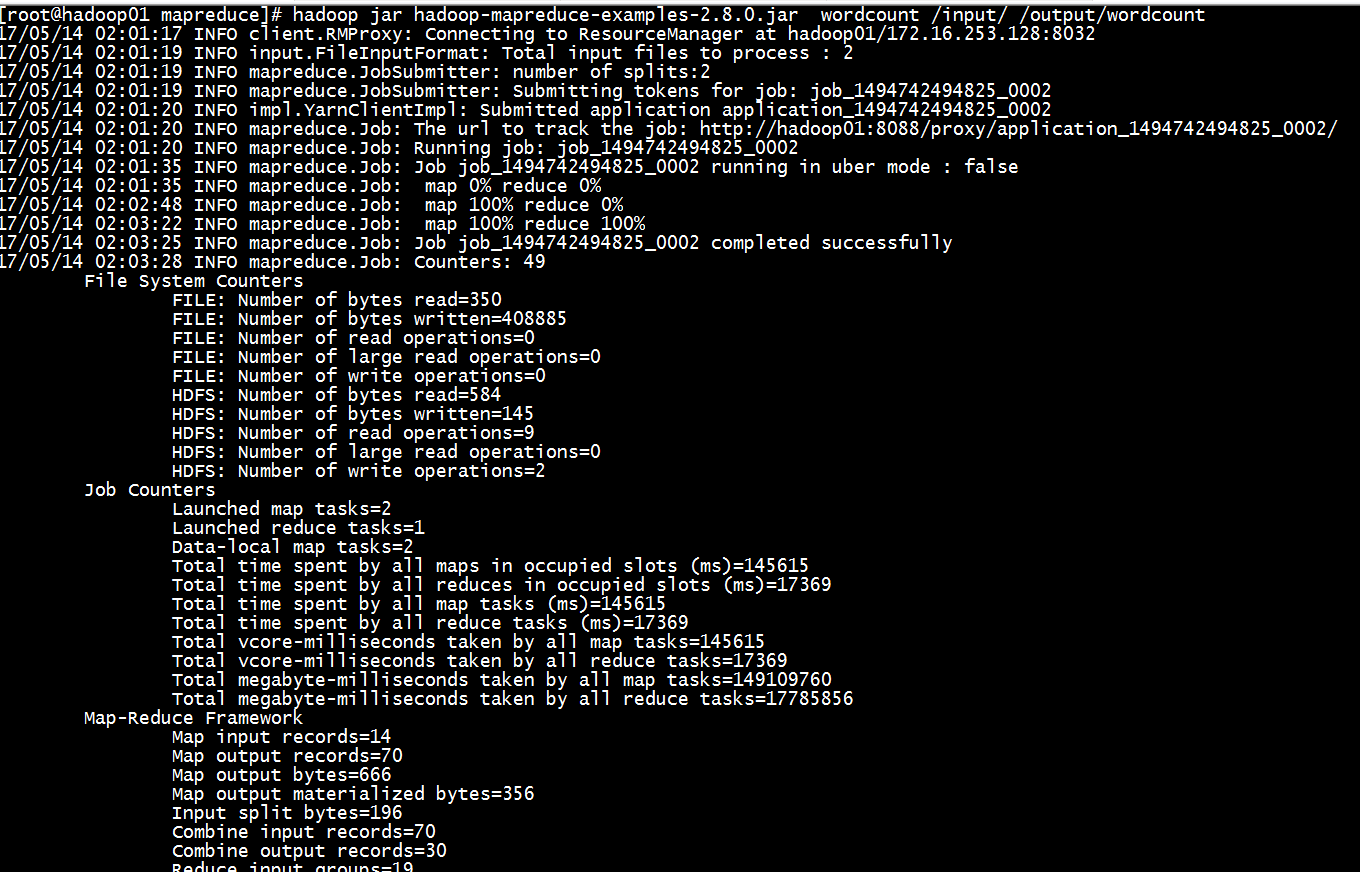
[root@hadoop01 mapreduce]# hadoop jar hadoop-mapreduce-examples-2.8.0.jar wordcount /input/ /output/wordcount
17/05/14 02:01:17 INFO client.RMProxy: Connecting to ResourceManager at hadoop01/172.16.253.128:8032
17/05/14 02:01:19 INFO input.FileInputFormat: Total input files to process : 2
17/05/14 02:01:19 INFO mapreduce.JobSubmitter: number of splits:2
17/05/14 02:01:19 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1494742494825_0002
17/05/14 02:01:20 INFO impl.YarnClientImpl: Submitted application application_1494742494825_0002
17/05/14 02:01:20 INFO mapreduce.Job: The url to track the job: http://hadoop01:8088/proxy/application_1494742494825_0002/
17/05/14 02:01:20 INFO mapreduce.Job: Running job: job_1494742494825_0002
17/05/14 02:01:35 INFO mapreduce.Job: Job job_1494742494825_0002 running in uber mode : false
17/05/14 02:01:35 INFO mapreduce.Job: map 0% reduce 0%
17/05/14 02:02:48 INFO mapreduce.Job: map 100% reduce 0%
17/05/14 02:03:22 INFO mapreduce.Job: map 100% reduce 100%
17/05/14 02:03:25 INFO mapreduce.Job: Job job_1494742494825_0002 completed successfully
17/05/14 02:03:28 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=350
FILE: Number of bytes written=408885
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=584
HDFS: Number of bytes written=145
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=145615
Total time spent by all reduces in occupied slots (ms)=17369
Total time spent by all map tasks (ms)=145615
Total time spent by all reduce tasks (ms)=17369
Total vcore-milliseconds taken by all map tasks=145615
Total vcore-milliseconds taken by all reduce tasks=17369
Total megabyte-milliseconds taken by all map tasks=149109760
Total megabyte-milliseconds taken by all reduce tasks=17785856
Map-Reduce Framework
Map input records=14
Map output records=70
Map output bytes=666
Map output materialized bytes=356
Input split bytes=196
Combine input records=70
Combine output records=30
Reduce input groups=19
Reduce shuffle bytes=356
Reduce input records=30
Reduce output records=19
Spilled Records=60
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=9667
CPU time spent (ms)=3210
Physical memory (bytes) snapshot=330969088
Virtual memory (bytes) snapshot=6192197632
Total committed heap usage (bytes)=259284992
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=388
File Output Format Counters
Bytes Written=145
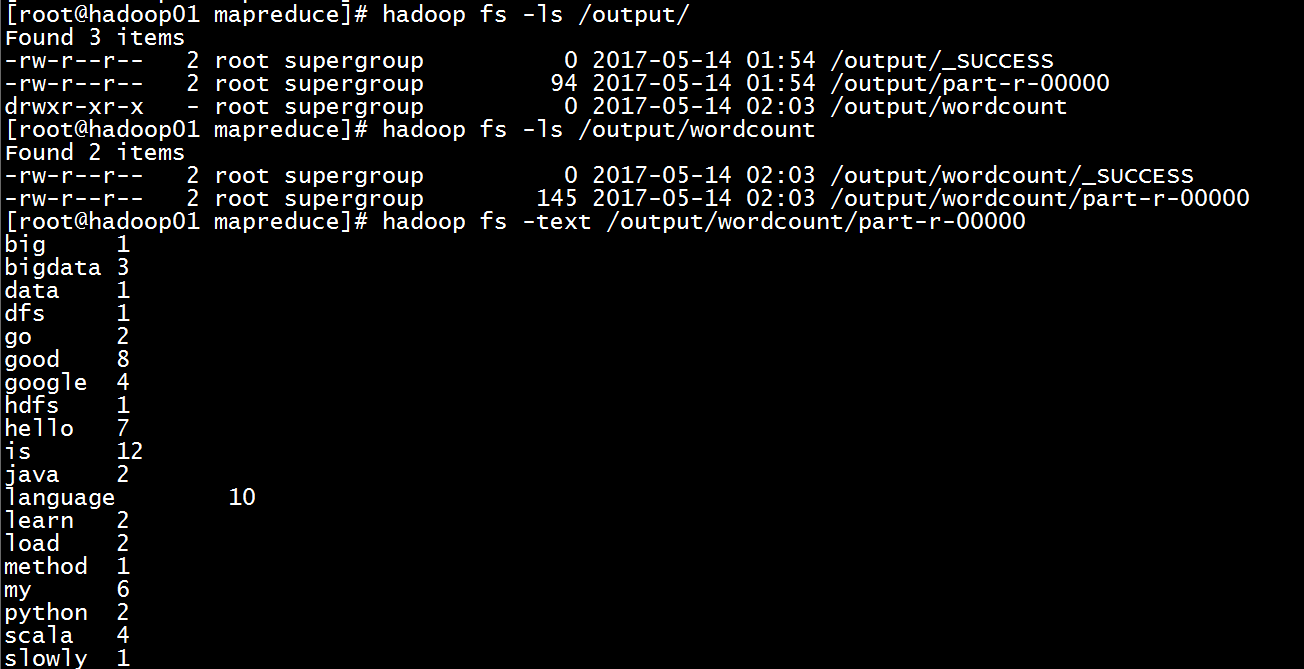
查看执行结果:
自定义wordcount :
package com.xwolf.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
import java.util.Arrays;
/**
* @author xwolf
* @date 2017-05-14 10:42
* @since 1.8
*/
public class WordCount {
static class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable> {
/**
* map方法的生命周期: 框架每传一行数据就被调用一次
* @param key 这一行的起始点在文件中的偏移量
* @param value 这一行的内容
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//读取当前行数据
String line = value.toString();
//将这一行切分出各个单词
String[] words = line.split(" ");
//遍历数组,输出格式<单词,1>
Arrays.stream(words).forEach(e -> {
try {
context.write(new Text(e), new IntWritable(1));
} catch (Exception e1) {
e1.printStackTrace();
}
});
}
}
static class WordCountReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
/**
* 生命周期:框架每传递进来一个kv 组,reduce方法被调用一次
* @param key
* @param values
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//遍历这一组<k,v>的所有v,累加到count中
for(IntWritable value:values){
count += value.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//指定job 的jar
job.setJarByClass(WordCount.class);
//指定map 类
job.setMapperClass(WordCountMapper.class);
//指定reduce 类
job.setReducerClass(WordCountReduce.class);
//设置Mapper类的输出key和value的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置Reducer类的输出key和value的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//指定要处理的数据所在的位置
FileInputFormat.addInputPath(job, new Path(args[0]));
//指定处理完成后的数据存放位置
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}
打包上传至hadoop 集群。
运行出错

出错
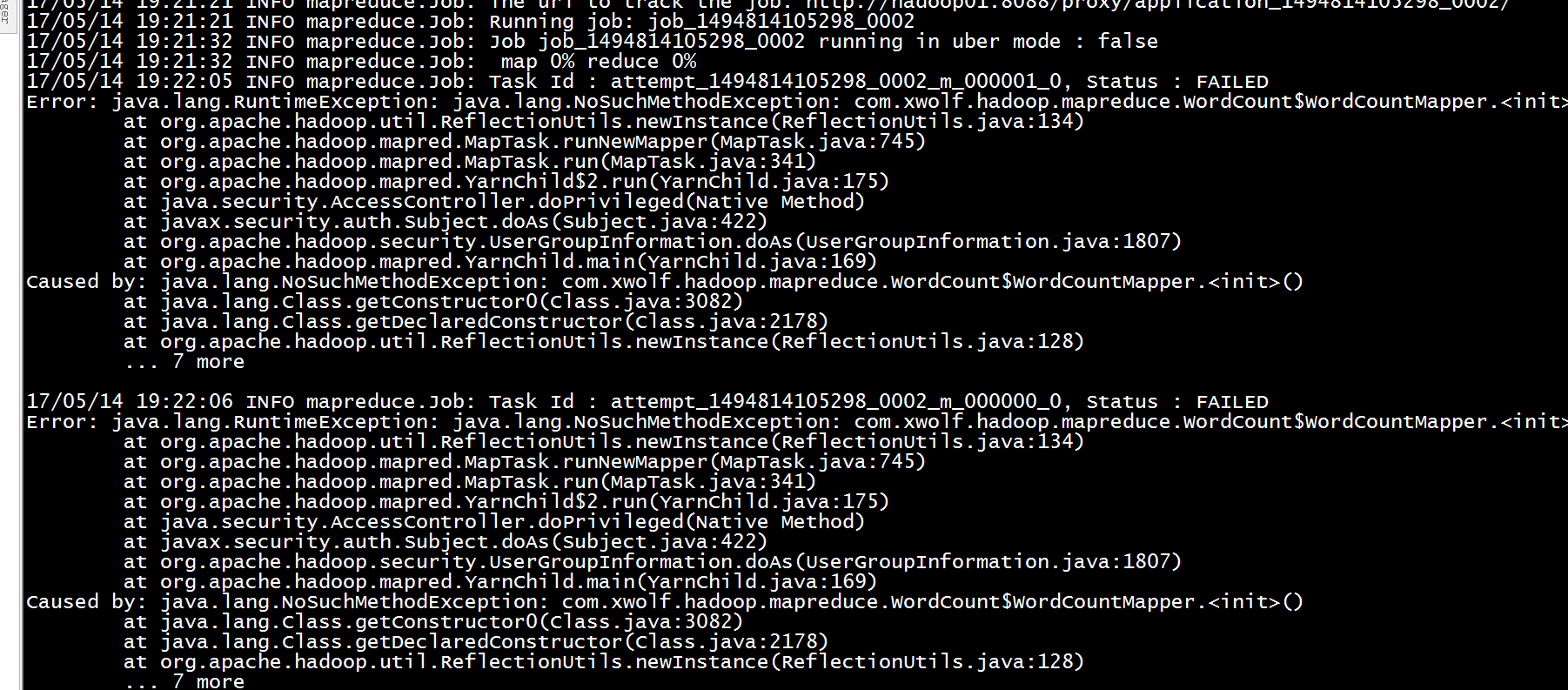
执行mapreduce出现的错,原因是map类和reduce没有加static修饰,因为hadoop在调用map和reduce类时采用的反射调用,内部类不是静态的,没有获取到内部类的实例