1 为何使用RNN(Recurrent Neural Network)
传统神经网络,如卷积,全连接神经网络,同样的输入只能输出相同的输出。但在如语义识别的时候我们想要相同的输入对应不同的输出。如购票系统中,去‘’北京‘’,中的北京是目的地,而离开’北京‘,’中的北京是出发地。通过上下文来跟当前的输入来决定输出就需要使用RNN。
2 简单RNN
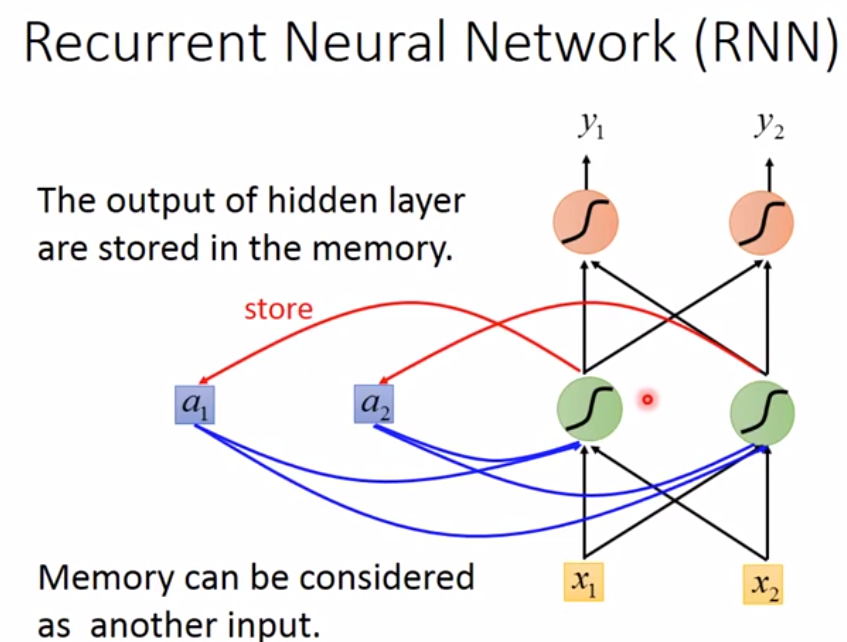
如下图是一个简单的RNN模型,输入层有两个神经元((x_1,x_2)),隐藏层有两个神经元,输出层有两个神经元((y_1,y_2))。若没有记忆单元((a_1,a_2)),相同的输入((x_1,x_2))一定会输出相同的((y_1,y_2))。若加上记忆单元((a_1,a_2)),在计算隐藏层的时候为,记忆单元乘以相应的权重(+)输入层乘以相应的权重,得到隐藏层,再把隐藏层的值存入记忆单元((a_1,a_2))中,下次在计算隐藏层的值的时候,((a_1,a_2))的值已经改变,所以算出的隐藏层的值不同,因此输出也不同。这是简单的RNN,至少实现了记忆功能。
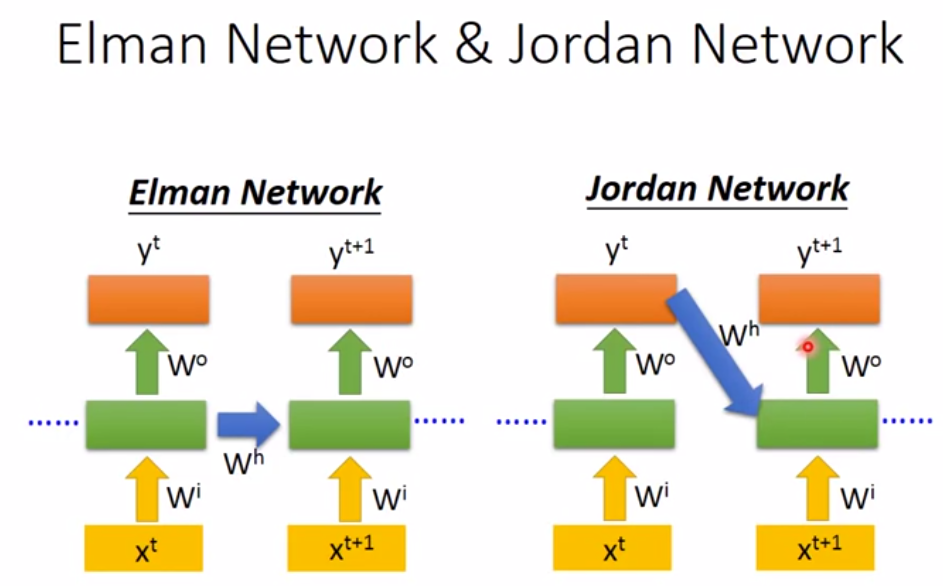
出来上面的结构形式,还有如下图的简单RNN,区别就是一个把隐藏层的值传给记忆单元,一个把输出值传给记忆单元。
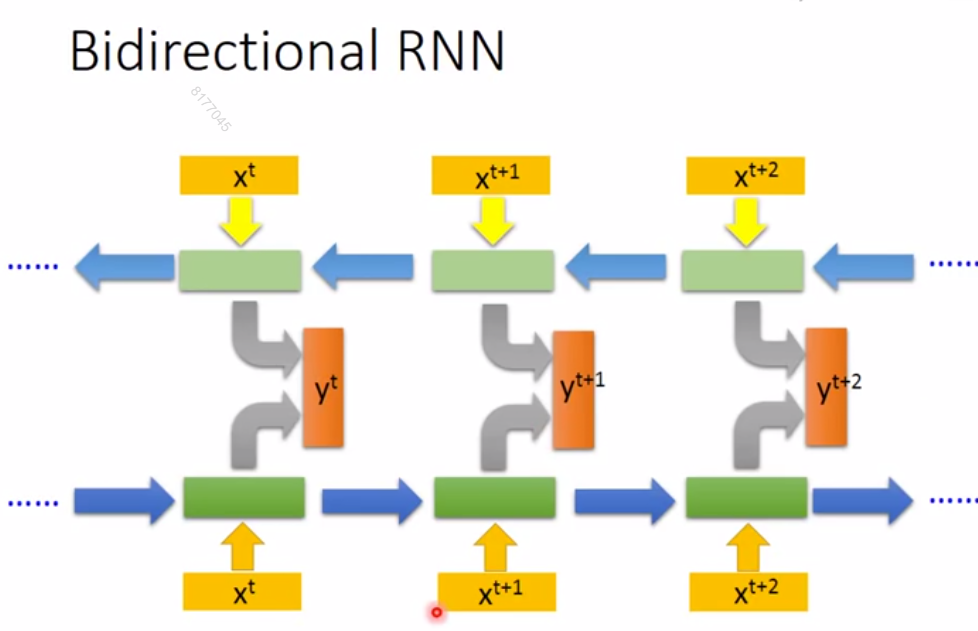
还有双向循环神经网络,通过把正向RNN跟反向RNN的隐藏层结合起来输出,来训练网络
3 LSTM(Long Short-Term Memory)
现在LSTM已经成了RNN的标准,与简单RNN不同的是,LSTM的记忆单元,由三个门控制,分别为
- 输入门(是否隐藏层的值要写入到记忆单元中)
- 遗忘门(当前记忆单元内的值是否需要洗掉)
- 输出门(是否输出新的记忆单元的值)
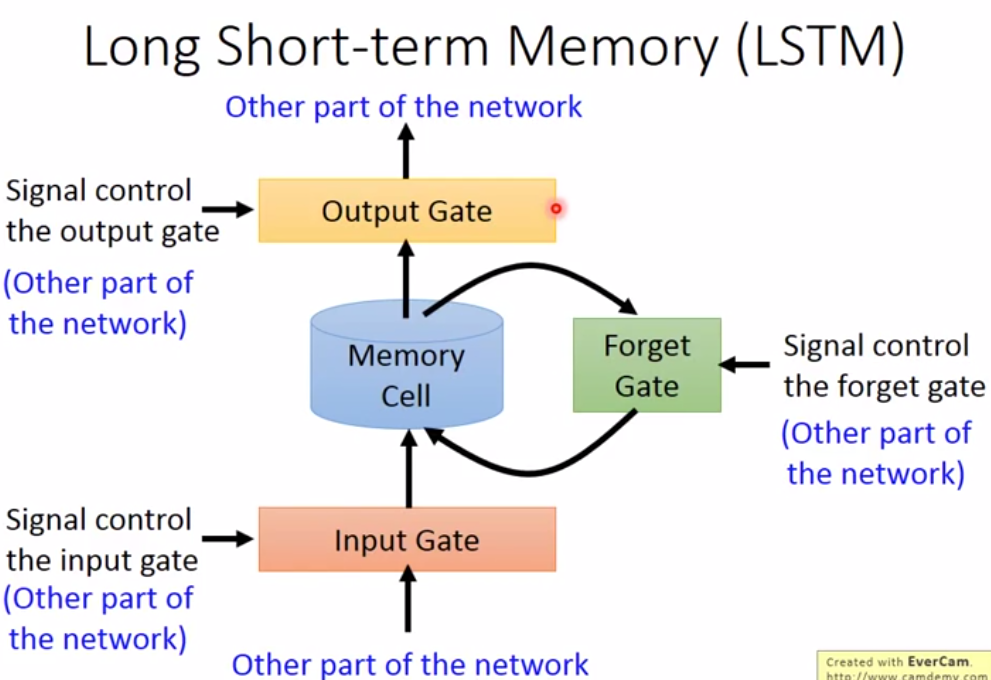
每个门都是一个向量,与对应需要控制的向量做元素之间的乘法,得到一个向量。基本运算如下图,即:
新的记忆单元=输入门×输入+遗忘门×记忆单元
输出向量 = 输出门×新记忆单元
这里省去了激活函数
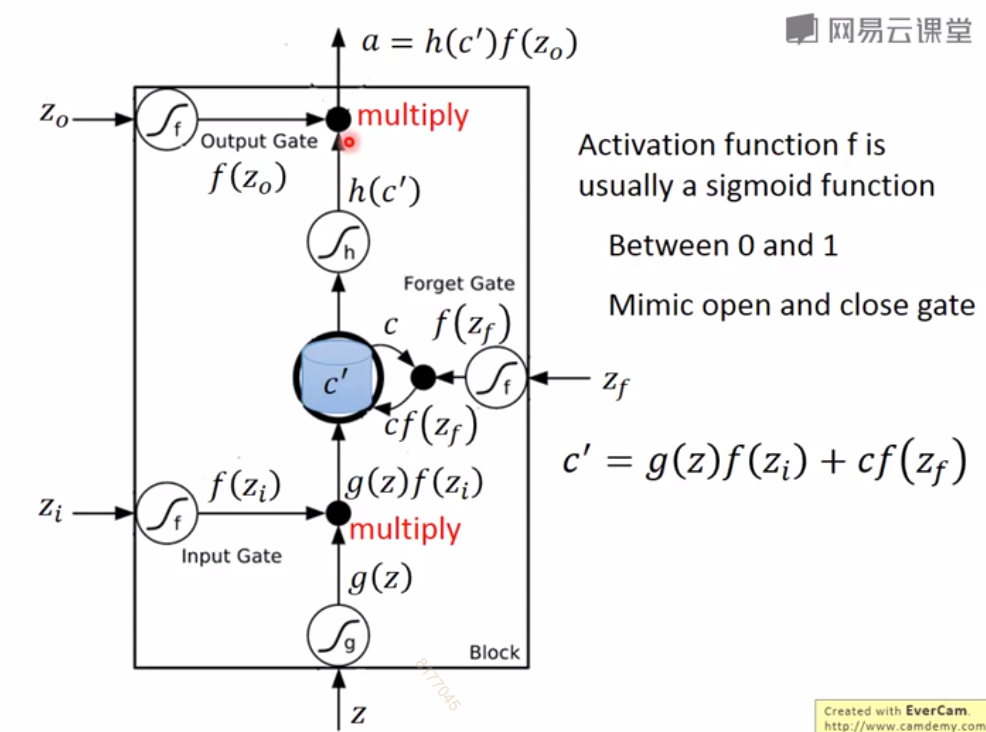
这里的三个门的计算都为:
输入门=输入向量x×转换矩阵
遗忘门门=输入向量x×转换矩阵
输入门=输入向量x×转换矩阵
其中x可以被认为对应隐藏层的值,因为是通过隐藏层的值来更新存储单元
最终形式为
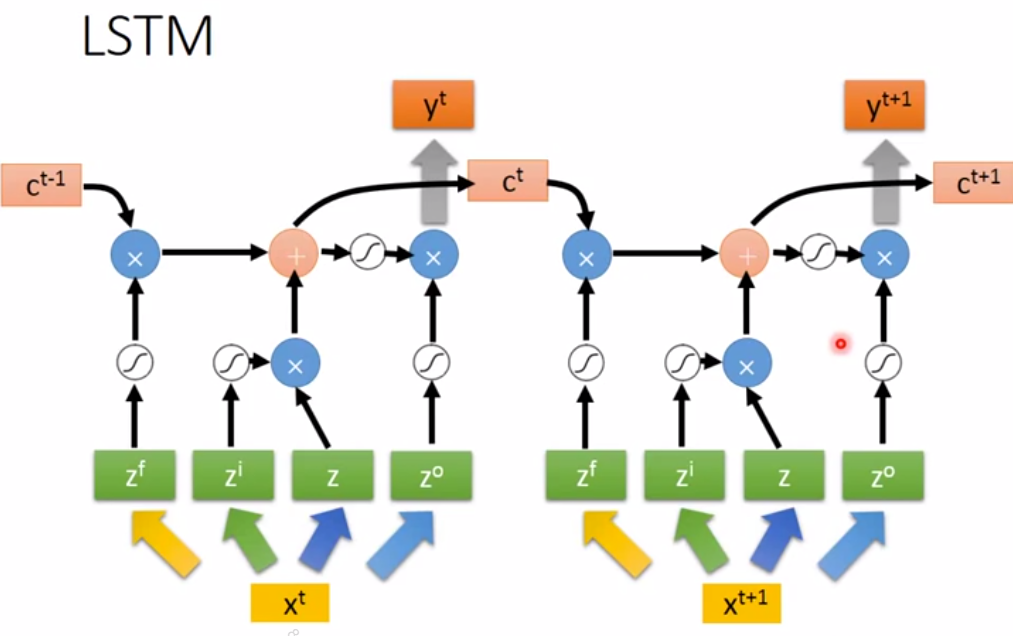
注意,上图的(x^t,x^{t+1})用的是同一个网络,即求(z^f,z^i,z,z^o)时的参数矩阵相同
4 RNN 的梯度爆炸与梯度消失
4.1 RNN的问题
在对RNN进行训练的时候,对于总损失值我们会发现,它不会平缓下降

这是因为如果我们观察参数对损失值的图片,就会发现,总损失值的图像是十分崎岖不平的。如下图可以看出,在部分地方,参数十分微小的变化变化就会使总损失值变得十分大,因而求得的梯度值就十分大。导致参数一下更新十分大的值。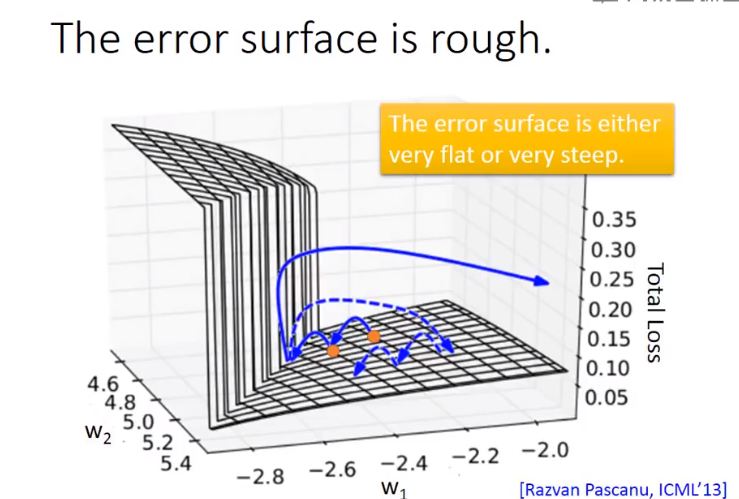
4.2 产生的原因:
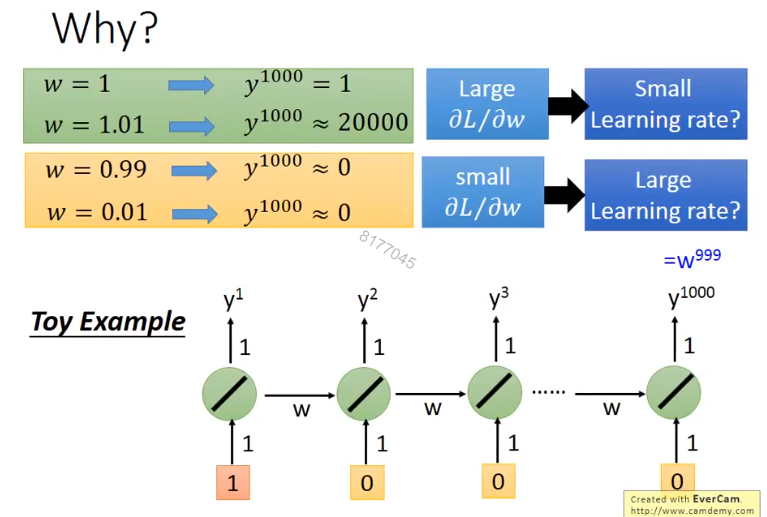
前面说了,在每一个时间点,RNN使用的权重都是相同的。因而权重哪怕变化很小的值,也会对RNN的最后结果,产生很大的影响。如下图,是一个非常简单RNN,当权重w变化很小的值,最后输出会产生很大的影响。
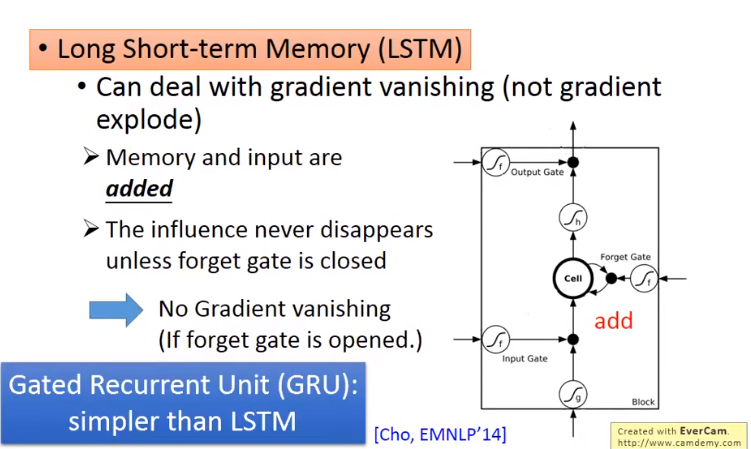
4.3 LSTM解决梯度消失的问题
因为LSTM中新的Memory中的值为旧的Memory中的值加上输入值。所以若遗忘门不为0那么Memory中总会有值,因此总会对LSTM结果产生影响,所以不会产生梯度消失的问题。
GRU 会将输入门与遗忘门结合起来
5 RNN的应用
5.1 Many to one
情感分析,如根据一段话来分析这段话的情感
5.2 Many to Many
5.21 语音识别
输入和输出都是序列, 但是输出更短。
这也会产生一问题是,输出会有很多重复的词汇,如“你你好好好好”。一种解决方法是将重复词汇删除,但是有时候需要保留重复的词汇,如“哈哈”。
5.22 CTC(Connectionist Temporal Classification)
可以解决这个问题。就是在输出中添加符号(varnothing)只把(varnothing)叠加起来。训练就是将所有含(varnothing)的情况都看为正确然后训练。

5.23 机器翻译
输入和输出都是序列,但是都没有固定的长度

将一种语言语音输入RNN输出另一种语言翻译,也可以。如输入英文语音直接输出中文翻译,中间没有先翻译成英文。
5.24文法解析
输入一段话,输入文法结构树

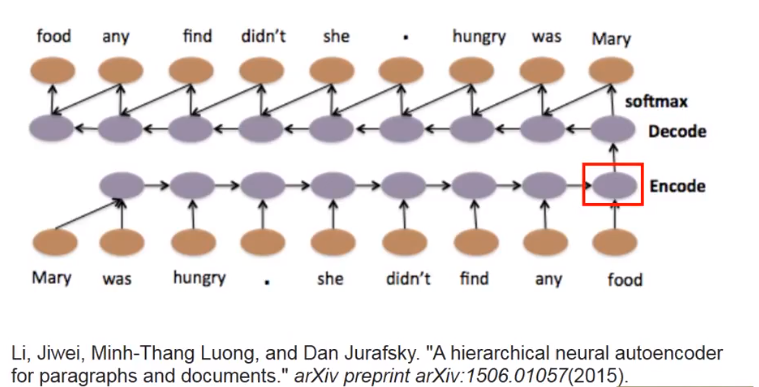
5.25 文本自动编码器
输入一段话,输出一个向量,这个向量里包含了,这段话的所有信息。
bag-of-words可以实现,不过会丢失单词的顺序信息,如下面话,bag-of-word会认为两段话一摸一样,因为单词内容一样,但是两段话是完全不同的意思。 一个积极一个消极。

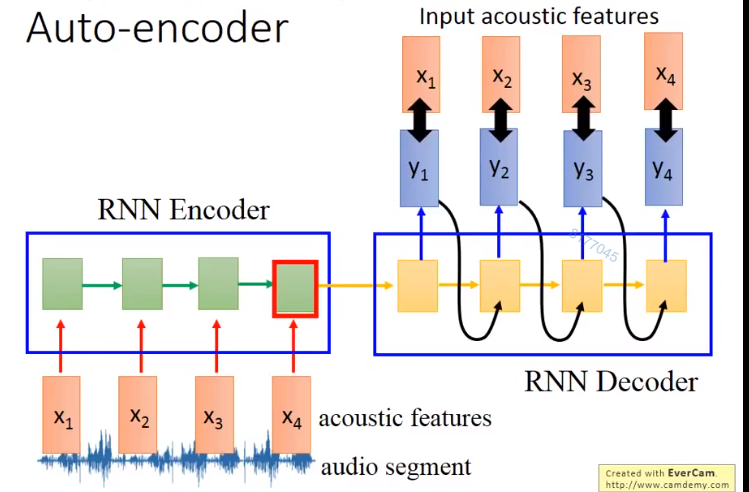
做法就是,将一段话输入RNN,输出一个向量,在将这个向量放入一个RNN,输出这段话。
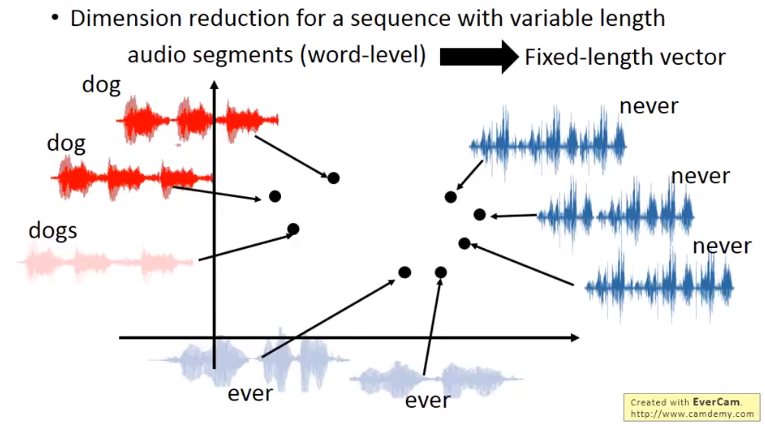
5.26 语音自动编码
将一段段语音讯号转化为一个个向量。这时可以看到,类似的语音转化成的向量就比较接近
训练方法如下,encoder跟decoder是一同训练的。